대응 표본 검정 (Dependent or Paired Sample t-test)
동일한 개체나 관련된 개체에서 두 가지 조건을 비교할 때 사용하는 통계 분석 방법
두 표본이 독립적이지 않고 서로 연관되어 있을 때, 즉 짝을 이루는 데이터를 다루는 데 적합
대응표본검정은 주로 두 시점 또는 두 조건에서 측정된 동일한 대상들 간의 차이를 분석할 때 사용
대응표본검정의 특징
-
연관된 표본:
- 두 표본이 독립적이지 않고, 같은 대상에서 다른 시간대나 조건에서 데이터를 수집했을 때 적용
-
차이값에 대한 분석:
- 대응표본검정은 두 표본의 차이값(각 짝의 차이)을 구해 그 차이가 통계적으로 유의미한지 여부 분석
즉, 검정은 두 표본 간의 평균 차이가 0인지 아닌지를 판단
- 대응표본검정은 두 표본의 차이값(각 짝의 차이)을 구해 그 차이가 통계적으로 유의미한지 여부 분석
-
가정:
- 정규성 가정: 두 표본의 차이값이 정규분포를 따른다고 가정
만약 차이값이 정규분포를 따르지 않는다면, 비모수 검정인 윌콕슨 부호 순위 검정(Wilcoxon signed-rank test)을 사용 - 연속형 데이터: 대응표본 t-검정은 일반적으로 연속형 데이터에 사용
- 정규성 가정: 두 표본의 차이값이 정규분포를 따른다고 가정
대응표본검정의 과정
-
귀무가설(H₀): 두 조건 또는 시점 간에 차이가 없다. 즉, 평균 차이가 0이다.
- (여기서 는 차이값의 평균)
-
대립가설(H₁): 두 조건 또는 시점 간에 차이가 있다. 즉, 평균 차이가 0이 아니다.
-
검정통계량 계산: 대응표본의 각 쌍의 차이를 계산한 후, 이 차이값들의 평균을 기준으로 t-값을 계산
여기서,
- 는 차이값들의 평균
- 는 차이값들의 표준편차
- 은 표본의 크기
-
p-값 계산 및 가설 검정: t-값을 통해 대응하는 p-값을 계산하여 귀무가설을 기각할지 여부를 결정
일반적으로 유의수준 은 0.05로 설정
p-값이 유의수준보다 작으면, 두 조건 간에 유의미한 차이가 있다고 결론
대응표본검정의 예시
- 시험 전후 성적 변화
- 의료 연구
- 고객 만족도 조사
대응표본검정의 장점과 단점
장점:
- 같은 개체에서 데이터를 수집하므로, 개체 간의 변동을 최소화하여 더 정확한 결과를 얻을 수 있음
- 집단 간의 차이를 비교할 때 보다 더 신뢰할 수 있는 통계 결과를 제공
단점:
- 대응 표본이 반드시 동일한 개체에서 수집된 것이어야 하므로, 실험 설계에 제약
- 정규성 가정이 충족되지 않으면 결과의 신뢰도가 낮아질 수 있으며, 정규성 검정 및 대체 검정 방법이 필요
이 검정은 주로 실험 전후 데이터를 분석하거나 같은 대상에 대해 두 가지 조건을 비교할 때 유용
문제 풀기 1
문제
10명의 학생들을 대상으로 기존의 교육과 새로운 교육 방법을 적용한 결과에 대해 유의수준 5%에서 새로운 교육 방법이 교육 시간을 단축 시켰는가 (단 모집단은 정규 분포를 가정함)
- = (새로운 방법 - 기존 방법)의 평균
- 귀무가설(): = 0
- 대립가설(): < 0
- 의 표본 평균을 구하시오.
- 위의 가설을 검정하기 위한 검정 통계량을 구하시오.
- 위의 통계량에 대한 p-value를 구하시오.
- 유의수준 0.05하에서 귀무가설을 기준으로 검정의 결과 채택
1. 데이터 불러오기
import pandas as pd
df = pd.DataFrame({
'User': list(range(1,11)),
'기존방법': [60.4, 60.7, 60.5, 60.3, 60.8, 60.6, 60.2, 60.5, 60.7, 60.4],
'새로운방법':[59.8, 60.2, 60.1, 59.9, 59.7, 58.4, 57.0, 60.3, 59.6, 59.8]
})
df.head(2)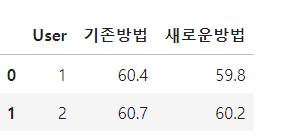
2. 평균 구하기
method 1
from scipy import stats
m = df['새로운방법'].mean() - df['기존방법'].mean()
m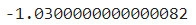
method 2
df['diff'] = df['새로운방법'] - df['기존방법']
print(df['diff'].mean())대응 표본 t-검정
t, p = stats.ttest_rel(df['새로운방법'], df['기존방법'], alternative = 'less')
print(t,p)- 귀무가설 기각, 효과가 있다.
정답
- -1.0300000000000082
- -3.407973078114844
- 0.0038872633380070652
- 기각
문제풀기 2
문제
주어진 데이터는 고혈압 환자 치료 전후의 혈압이다. 해당 치료가 효과가 있는지 대응(쌍체)표본 t-검정을 진행하시오
- 귀무가설(H0): >= 0
- 대립가설(H1): < 0
- = (치료 후 혈압 - 치료 전 혈압)의 평균
- 유의수준: 0.05
- 의 표본평균은?(소수 둘째자리까지 반올림)
- 검정통계량 값은?(소수 넷째자리까지 반올림)
- p-값은?(소수 넷째자리까지 반올림)
- 가설검정의 결과는? (유의수준 5%)
import pandas as pd
df = pd.read_csv("/kaggle/input/bigdatacertificationkr/high_blood_pressure.csv")
df.head() # 데이터 확인하기
# 1. 표본평균 구하기(반올림)
m = round((df['bp_post'] - df['bp_pre']).mean(),2)
m
#2,3검정통계량 구하기
from scipy import stats
t,p = stats.ttest_rel(df['bp_post'], df['bp_pre'], alternative = 'less')
print(round(t,4)) # 검정 통계량
print(round(p,4)) # p-value
#4. 가설 검정 결과
#귀무가설 기각 대립가설 채택 -> 효과 있다출처: https://www.kaggle.com/code/agileteam/t3-example
업로드한 수식은 대응표본 t-검정에서 사용하는 수식으로 보입니다. 아래와 같이 설명드리겠습니다:
- : 대응된 두 데이터 간의 평균 차이
- (s_d): 차이의 표준편차
- (n): 데이터 쌍의 개수
이 수식은 대응표본의 평균 차이가 통계적으로 유의미한지 검정하기 위해 사용됩니다. 추가 설명이 필요하시면 말씀해주세요! 😊
