빅데이터분석
1.빅데이터 분석
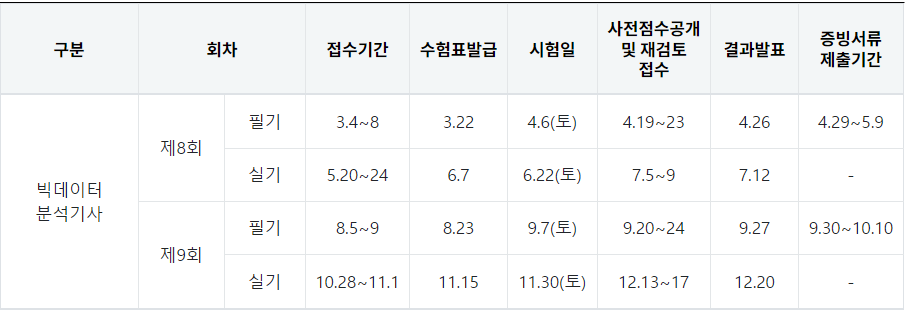
빅데이터 분석 기사 시험을 준비하고자 한다.2024년도는 지났고, 2025년도 시험을 응시해야 한다.퇴근후딴짓 유튜버를 통해, 빅데이터 분석 기사 시험에 대해 공부하고 있다.유튜브 강의와 케글 그리고 책으로 다양한 자료와 강의를 제공하고 있으며, 디스코드를 통해 스터디
2.이상치 IQR
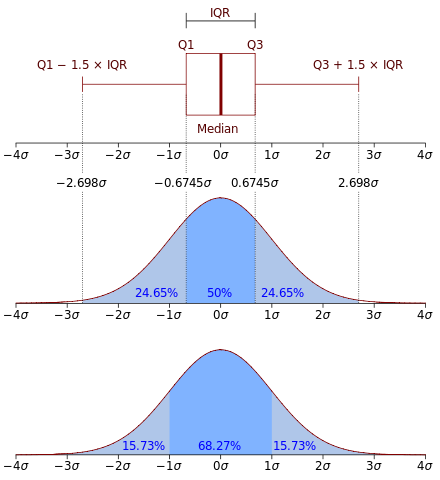
IQR은 데이터 세트를 사분위수로 나누어 표시 여부를 정한 것위 그림과 같이 IQR은 Q1~Q3의 값이다.Q3는 전체 데이터의 75% 값을 의미하고, Q1은 전체 데이터의 25% 값을 의미한다.즉IQR = Q3 - Q1일반적인 데이터 분포를 따르지 않는 값으로, 다른
3.컬럼 replace, 조건, 최대값
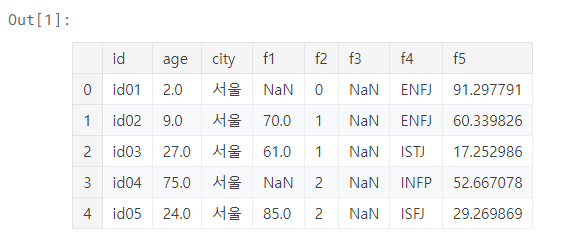
'f4'컬럼의 값이 'ESFJ'인 데이터를 'ISFJ'로 대체하고, 'city'가 '경기'이면서 'f4'가 'ISFJ'인 데이터 중 'age'컬럼의 최대값을 출력하시오!df에서 .replace를 통해 ESFJ 값을 --> ISFJ로 바꾼다여기는 특정 칼럼을 지칭하여 특
4.단일표본 t검정
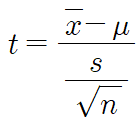
두 집단의 평균을 비교하거나 하나의 집단의 평균을 특정 값과 비교하여 유의미한 차이가 있는지 확인표본의 크기가 작거나, 모집단의 분산을 모를 때 사용한 집단의 평균이 특정 값과 유의미하게 다른지를 확인할 때 사용두 독립적인 집단의 평균이 유의미하게 다른지 비교할 때 사
5.EDA

EDA (탐색적 데이터 분석)EDA는 데이터 분석의 초기 단계에서 데이터를 이해, 그 속성을 탐구하는 과정EDA는 주로 통계적 요약과 시각화를 통해 데이터의 특징을 파악데이터에 숨어 있는 패턴, 이상치(outliers), 관계성 등을 발견하는 데 중점데이터 분석이나 모
6.소수점 찾기
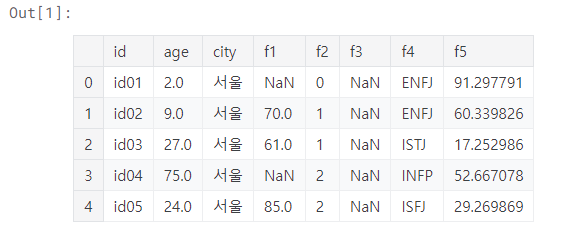
주어진 데이터에서 이상치(소수점 나이)를 찾고 올림, 내림, 버림(절사)했을때 3가지 모두 이상치 'age' 평균을 구한 다음 모두 더하여 출력하시오out:method1df의 age 항목을 1로 나눈 나머지가 0이 아닌 집합method2df age - df age의 내
7.결측치 처리 (map 활용)
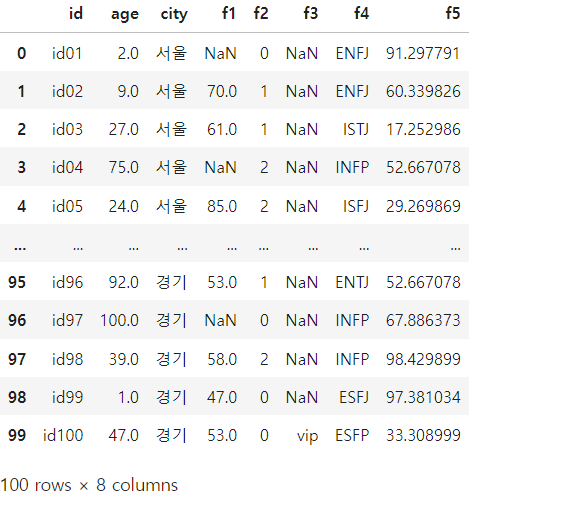
Pandas의 .map() 함수는 주로 Series 객체에 있는 데이터의 각 요소를 변환할 때 사용되는 매우 유용한 메서드입니다. 이 함수는 각 요소를 주어진 규칙에 따라 다른 값으로 매핑하거나 변환할 수 있습니다. map()은 데이터 변환 작업에서 빈번하게 사용되며,
8.독립표본 T-검정
독립표본 t-검정 주요 개념 1. 독립된 두 표본 독립표본 t-검정에서 가장 중요한 가정은 두 표본이 서로 독립적 2. 정규성 가정 두 그룹의 데이터가 정규분포를 따른다는 가정 3. 등분산성 가정 두 그룹의 분산이 동일 하다는 가정 4. 귀무가설, 대립가설 귀무
9.[python] 상관관계
상관관계 이론 상관관계란? 두 변수 간의 선형적 관계를 타나태는 통계적 개념 한 변수가 변할 때 다른 변수가 어떻게 변하는지 설명 상관관계는 상관계수를 가지며 -1에서 1사이의 값을 가짐 상관관계의 해석 1. 양의 상관관계 상관계수가 양수일 때, 두 변수는 같은
10.대응표본검정
대응 표본 검정 (Dependent or Paired Sample t-test) 동일한 개체나 관련된 개체에서 두 가지 조건을 비교할 때 사용하는 통계 분석 방법 두 표본이 독립적이지 않고 서로 연관되어 있을 때, 즉 짝을 이루는 데이터를 다루는 데 적합 대응표본검정은 주로 두 시점 또는 두 조건에서 측정된 동일한 대상들 간의 차이를 분석할 때 사용 대...
11.일원 분산 분석
일원 분산 분석(One-Way ANOVA, Analysis of Variance)은 한 개의 독립 변수가 여러 그룹 간의 차이를 비교할 때 사용하는 통계 기법각 그룹의 평균이 동일한지 여부를 평가하기 위해 사용분산 분석은 데이터를 여러 그룹으로 나누고, 각 그룹 간의
12.이원 분산 분석
이원 분산 분석(이원 ANOVA)은 두 개의 독립 변수가 종속 변수에 미치는 영향을 동시에 분석하는 통계 방법주효과와 상호작용 효과를 평가하여 각 요인이 개별적으로 또는 상호작용하여 종속 변수에 영향을 미치는지를 분석두 개의 독립 변수 $A$와 $B$가 종속 변수 $Y
13.min-max & 상하위 값
Min-Max 스케일링은 데이터의 값을 일정한 범위로 변환하는 정규화 기법 데이터의 분포를 0과 1 사이의 범위로 축소하여 각 특성의 값을 상대적으- 로 비교할 수 있게 보여줌이는 머신러닝 알고리즘의 성능을 향상시키기 위해 자주 사용$$X{\\text{scaled}}
14.결측 데이터 찾기, 필터링
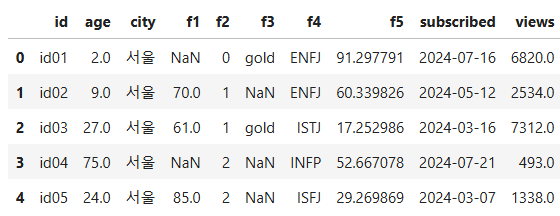
cond를 통해, df의 'f1'에 NaN값을 가진 행만 선택 df = df\[cond]로 하면, df\['f1'] 값이 다 NaN이 됨out:method1과 마찬가지로 isnull을 이용하지만, 한번에 진행NaN 값은 자기 자신과 같지 않는 특성을 가지므로, f1 !
15.중복데이터 제거, 값 변경
drop_duplicates를 활용하여 중복 데이터 제거하기replace와 np.nan을 이용해서 replace(바꾸고 싶은 값, 바꿀 값)nan은 0이라 계산 제외하고, 각각 해당하는 값의 sum은 갯수기 때문에, 해당하는 가중치를 곱해서 더함map()을 사용해 값을
16.이진분류
이진분류는 두 개의 범주 또는 클래스로 데이터를 분류하는 작업주로 두 가지 클래스를 0과 1, 또는 True와 False로 나타내며, 이들 중 어느 한 쪽에 속할 가능성을 예측하는 것이 목표이직여부를 한번 예측해보자EDA 분석데이터 전처리머신러닝train, test데이
17.다중분류(약물 예측)
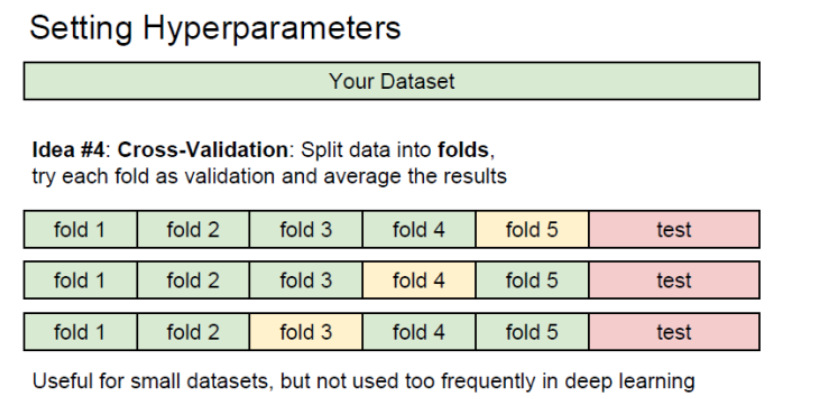
다중 분류(Multiclass Classification)는 입력 데이터를 세 개 이상의 클래스 중 하나로 분류하는 문제 이진 분류와 달리 다중 분류는 여러 개의 클래스가 존재하므로, 모델은 각 입력 데이터가 어떤 특정 클래스에 속하는지 예측 약물 예측을 통해 한
18.데이터 전처리 1
object을 모델에 사용하기 위해 숫자형으로 변환하는 기법object을 원-핫 인코딩하면, 각 범주가 서로 다른 독립적인 특성으로 표현표현 방식은 모델이 범주들 간의 순서나 크기를 가정하지 않음예를 들어, Color라는 열에 세 가지 색상이 있다고 가정원-핫 인코딩
19.주가 분석
양자컴퓨터 데이터 분석을 해보자 총 5개의 양자컴퓨터 주식 IONQ IBM Intel Alpha HON python 코드 라이브러리 및 데이터 불러오기 from pandas.plotting import scatter_matrix 는 2차원 산점도 분석을 위해 사용 yfinance로 주가 데이터를 쉽게 불러올 수 있다. start, end 보면 202...