다중 분류(Multiclass Classification)는 입력 데이터를 세 개 이상의 클래스 중 하나로 분류하는 문제
이진 분류와 달리 다중 분류는 여러 개의 클래스가 존재하므로, 모델은 각 입력 데이터가 어떤 특정 클래스에 속하는지 예측
약물 예측을 통해 한번 살펴보자
문제
- 평가: f1-marco
- trarget: Drug
- 최종파일: result.csv(칼럼 1개 pred, 1 확률값)
라이브러리 및 데이터 불러오기
import pandas as pd
train = pd.read_csv(r"../bigdata_analyst_cert-main/bigdata_analyst_cert-main/part2/ch7/drug_train.csv")
test = pd.read_csv(r"../bigdata_analyst_cert-main/bigdata_analyst_cert-main/part2/ch7/drug_test.csv")train data와test data를 각각 불러온다
탐색적 데이터 분석 (EDA)
train 데이터의 정보
train.info()out:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 100 entries, 0 to 99
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Age 100 non-null int64
1 Sex 100 non-null object
2 BP 100 non-null object
3 Cholesterol 100 non-null object
4 Na_to_K 100 non-null float64
5 Drug 100 non-null object
dtypes: float64(1), int64(1), object(4)
memory usage: 4.8+ KBinfo()를 통해 확인train data를 살펴보면,Sex,BP,Cholesterol,Drug, 는Dtype이object임을 알 수 있다.
결측값 확인
print(train.isnull().sum(), "\n", test.isnull().sum())out:
Age 0
Sex 0
BP 0
Cholesterol 0
Na_to_K 0
Drug 0
dtype: int64
Age 0
Sex 0
BP 0
Cholesterol 0
Na_to_K 0
Drug 0
dtype: int64-isnull().sum()을 통해 null 값의 합 확인
- null 값이 없는 것을 확인할 수 있다.
카테고리별 수
print(train.nunique(), "\n", test.nunique())out:
Age 52
Sex 2
BP 3
Cholesterol 2
Na_to_K 100
Drug 5
dtype: int64
Age 48
Sex 2
BP 3
Cholesterol 2
Na_to_K 100
dtype: int64nunique()를 통해 카테고리별 수를 확인
target 빈도
train['Drug'].value_counts()out:
DrugY 41
drugX 34
drugA 13
drugB 8
drugC 4
Name: Drug, dtype: int64value_counts()를 통해 확인할 수 있다.
데이터 전처리
원-핫 인코딩
target = train.pop('Drug')
train = pd.get_dummies(train)
test = pd.get_dummies(test)out:
Age Na_to_K Sex_F Sex_M BP_HIGH BP_LOW BP_NORMAL Cholesterol_HIGH Cholesterol_NORMAL
0 70 9.849 0 1 1 0 0 1 0
...원-핫 인코딩은 범주형 데이터를 숫자 데이터로 만드는 과정으로 머신러닝에 사용
- 각 고유한 범주를 별도의 이진 벡터로 변환- ex) ['apple', 'banana', 'cherry'] -> [1, 0, 0], [0, 1, 0], [0, 0, 1]로 변환
get_dummies이용
스케일링
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
train['Age'] = scaler.fit_transform(train[['Age']])
test['Age'] = scaler.fit_transform(test[['Age']])Age out:
0 0.932203
1 0.355932
2 0.135593
3 0.423729
4 0.508475
...
95 0.220339
96 0.711864
97 0.355932
98 0.220339
99 0.915254MinMaxSclaer를 이용하여Age의 범위를 0~1 사이로 조정- 사용하는 이유는 머신러닝에서 큰 영향을 미치지 않기 위함
- 하지만 이번 학습에서는 영향을 미치지 않았음
라벨링
from sklearn.preprocessing import LabelEncoder
cols = train.select_dtypes(include='object').columns
for col in cols:
le = LabelEncoder()
train[col] = le.fit_transform(train[col])
test[col] = le.fit_transform(test[col])
train[]- 각 범주를 정수로 변환하여 고유한 번호를 부여
- ['apple', 'banana', 'cherry'] -> [0, 1, 2]로 변환
크로스 밸리데이션
cs231n ppt
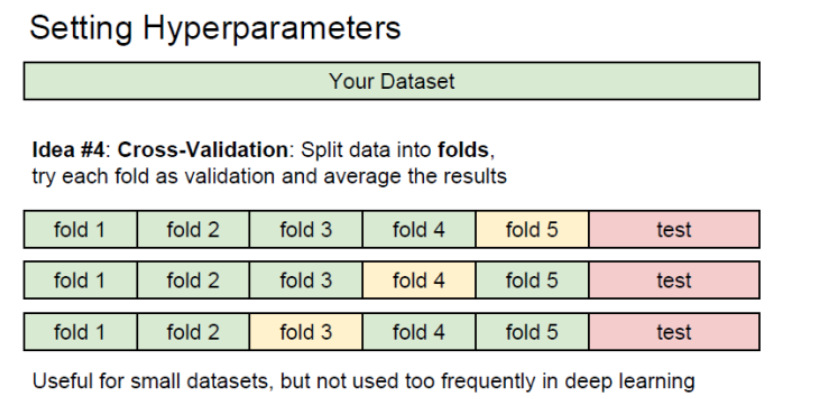
코드
from sklearn.metrics import f1_score
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=0)
f1_scores = cross_val_score(rf, train, target, cv=5, scoring='f1_macro')
f1_scores.mean()out: 0.9121904761904762
설명
-
라이브러리 임포트
f1_score: F1 점수를 계산하는 함수
F1 점수는 정밀도와 재현율을 결합한 지표로, 특히 불균형 데이터에서 모델의 성능을 평가할 때 유용함cross_val_score: 교차 검증을 통해 모델 성능을 평가하고, 각 폴드에서의 점수를 반환하는 함수RandomForestClassifier: 랜덤 포레스트 분류 모델을 생성하는 클래스
-
모델 초기화
rf = RandomForestClassifier(random_state=0)RandomForestClassifier를random_state=0으로 초기화하여, 동일한 데이터와 파라미터로 실행할 때마다 같은 결과를 얻을 수 있게 설정
-
5-겹 교차 검증을 통한 F1 점수 계산
f1_scores = cross_val_score(rf, train, target, cv=5, scoring='f1_macro')cv=5: 데이터셋을 5개의 폴드로 나누는 5-겹 교차 검증을 수행
데이터셋을 5개의 폴드로 나누고, 각 폴드를 테스트 세트로 한 번씩 사용하여 총 5번의 모델 학습 및 평가를 수행scoring='f1_macro': 매번 교차 검증 시, 각 폴드에서 F1 매크로 점수를 계산- F1 매크로(Macro) 점수는 각 클래스의 F1 점수를 독립적으로 계산한 후 평균을 내는 방식
cross_val_score는 각 폴드에서 계산된 F1 점수를 리스트로 반환
-
F1 점수의 평균 계산
f1_scores.mean()- 5번의 교차 검증에서 각각 계산된 F1 점수의 평균
- 이렇게 하면 전체 데이터에 대한 모델의 평균 F1 점수를 얻을 수 있으며, 이 값이 높을수록 모델이 모든 클래스에서 균형 잡힌 성능을 발휘하고 있음을 의미
학습
rf.fit(train, target)
pred=rf.predict(test)
predout:
array(['DrugY', 'DrugY', 'DrugY', 'DrugY', 'drugB', 'drugC', 'drugA',
'DrugY', 'drugX', 'DrugY', 'DrugY', 'DrugY', 'drugX', 'DrugY',
'drugC', 'DrugY', 'drugA', 'drugA', 'drugA', 'DrugY', 'DrugY',
'drugA', 'drugX', 'DrugY', 'DrugY', 'drugC', 'DrugY', 'drugC',
'drugA', 'DrugY', 'DrugY', 'DrugY', 'DrugY', 'drugA', 'drugC',
'DrugY', 'drugX', 'drugX', 'DrugY', 'DrugY', 'DrugY', 'drugB',
'drugA', 'drugA', 'drugA', 'drugA', 'DrugY', 'DrugY', 'DrugY',
'DrugY', 'DrugY', 'drugX', 'drugX', 'drugX', 'drugX', 'drugA',
'drugB', 'drugB', 'DrugY', 'drugX', 'DrugY', 'DrugY', 'DrugY',
'DrugY', 'drugC', 'drugX', 'drugX', 'DrugY', 'DrugY', 'DrugY',
'DrugY', 'drugX', 'drugC', 'drugC', 'drugC', 'drugC', 'DrugY',
'drugB', 'DrugY', 'DrugY', 'DrugY', 'drugB', 'DrugY', 'DrugY',
'DrugY', 'drugX', 'DrugY', 'drugX', 'DrugY', 'DrugY', 'drugC',
'drugX', 'DrugY', 'DrugY', 'drugX', 'drugX', 'drugC', 'DrugY',
'DrugY', 'drugX'], dtype=object)결론
다중 분류(Multiclass Classification) 문제로, 환자의 정보를 기반으로 특정 약물을 예측하는 모델을 구축
랜덤 포레스트(Random Forest) 알고리즘을 사용하여 모델을 학습하고 평가했으며, 주요 성능 지표로 F1 매크로(F1 Macro) 점수를 사용하여 모델의 성능을 평가
결과 요약:
-
평가 지표로 F1 매크로 점수를 사용하여 다중 클래스 간 예측의 균형을 평가했습니다. 교차 검증 결과 평균 F1 매크로 점수는 0.912로, 모델이 전반적으로 균형 잡힌 성능을 확인
-
데이터 전처리 과정에서 원-핫 인코딩(One-Hot Encoding)을 통해 범주형 변수를 수치형으로 변환
라벨링과MinMaxScaler등은 영향을 미치지 못함 -
5-겹 교차 검증(5-Fold Cross-Validation)을 사용하여 모델을 학습하고 평가
교차 검증을 통해 모델의 성능을 평가하고, 과적합을 방지

gpt로 다시 배우는 개발