
✍ What is Index
인덱스(Index)는 데이터베이스 테이블의 컬럼 값을 색인화하여 검색 속도를 향상시키기 위해 사용되는 데이터 구조입니다. 인덱스를 생성하면 검색 시 해당 컬럼 값을 순서대로 정렬하여 저장하게 되므로, 검색 시에 전체 데이터를 스캔하는 것이 아니라 인덱스에 저장된 값만을 참조하여 빠른 검색이 가능합니다. 인덱스는 데이터베이스의 성능을 향상시키는 데 중요한 역할을 합니다.
=> 인덱스는 책에서의 목차 혹은 색인이라고 생각하면 된다.
📝 Index의 필요성
-
검색 속도 향상: 인덱스를 사용하면 데이터베이스 검색 속도가 향상됩니다. 인덱스는 특정 열에 대한 값을 미리 정렬하여 검색을 빠르게 수행할 수 있도록 합니다.
-
쿼리 성능 개선: 인덱스를 사용하면 쿼리 실행 속도가 향상됩니다. 인덱스를 사용하면 데이터베이스에서 데이터를 검색할 때, 테이블의 모든 행을 검색하는 대신 인덱스를 검색하여 효율적으로 데이터를 찾을 수 있습니다.
-
공간 절약: 인덱스를 사용하면 테이블의 데이터를 저장하는 데 필요한 공간을 절약할 수 있습니다. 인덱스는 데이터의 일부를 미리 정렬하여 저장하므로, 테이블의 전체 데이터를 저장하는 데 필요한 공간보다 적은 공간을 차지합니다.
-
정렬 기능: 인덱스는 데이터를 정렬하는 데 사용됩니다. 데이터를 정렬하면 쿼리의 실행 속도가 향상됩니다. 인덱스를 사용하여 데이터를 정렬하면 쿼리에서 ORDER BY 절을 사용하지 않고도 데이터를 정렬할 수 있습니다.
-
유니크 제약 조건: 인덱스를 사용하여 유니크 제약 조건을 설정할 수 있습니다. 유니크 제약 조건을 설정하면 테이블에 중복 데이터가 입력되는 것을 방지할 수 있습니다.
📝 Index가 가지고 있는 특징
-
검색 속도 향상: 인덱스를 사용하면 데이터베이스에서 레코드를 검색하는 속도가 빨라집니다. 인덱스는 미리 정렬된 데이터 구조로써, 검색 시 필요한 레코드의 위치를 빠르게 찾아줍니다.
-
고유성(unique): 인덱스는 유일한 값을 갖는 컬럼을 지정할 수 있으며, 이를 통해 중복된 레코드를 방지할 수 있습니다.
-
성능 저하: 인덱스를 많이 생성하면 데이터 삽입, 수정, 삭제 등의 작업 시에 성능이 저하될 수 있습니다. 인덱스는 레코드의 추가, 삭제, 수정 시에도 함께 변경되어야 하기 때문입니다.
-
용량 증가: 인덱스를 생성하면 데이터베이스 용량이 증가합니다. 인덱스는 데이터를 복제하는 형태로 생성되기 때문입니다.
-
적절한 선택 필요: 어떤 컬럼에 대해 인덱스를 생성할지 선택하는 것은 중요한 문제입니다. 적절한 인덱스를 선택하지 않으면 성능 저하, 용량 증가 등의 문제가 발생할 수 있습니다.
📝 Index의 장/단점
✏️ 장점
-
데이터베이스에서 데이터를 검색할 때 더 빠른 속도로 결과를 찾을 수 있습니다.
-
데이터베이스 성능을 향상시킬 수 있습니다.
-
데이터 중복을 줄이고 데이터 무결성을 유지할 수 있습니다.
-
데이터베이스에서 효율적인 쿼리 실행을 가능하게 합니다.
✏️ 단점
-
인덱스는 데이터베이스의 크기를 증가시킵니다.
-
인덱스를 만들기 위해 추가적인 디스크 공간이 필요합니다.
-
데이터베이스에서 인덱스를 유지하는 데 필요한 리소스와 처리 시간이 추가로 필요합니다.
-
데이터베이스에서 인덱스를 생성하거나 변경하는 데 시간이 걸릴 수 있습니다.
✍ Data Structure in Index
인덱스는 위에서도 언급했다시피 DB에서 검색 속도를 높이기 위해 사용되는 자료구조입니다. 대부분의 DBMS에서는 B-Tree나 B+Tree라는 자료구조를 이용하여 인덱스를 구현합니다.
📝 B-Tree
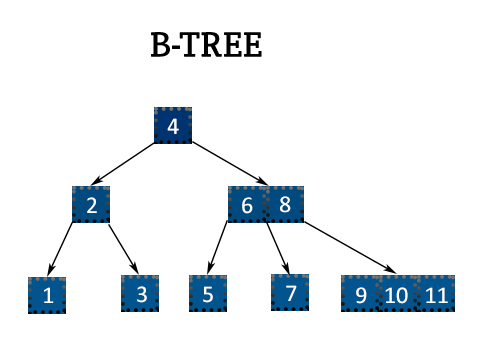
B-Tree는 자료를 탐색하거나 정렬하기 위한 자료구조 중 하나입니다. 주로 데이터베이스와 파일 시스템에서 인덱스를 구현하는 데 사용됩니다. B-Tree는 균형 이진 트리의 일종으로, 모든 leaf 노드가 같은 깊이에 위치하도록 설계되어 있습니다
✏️ B-Tree의 특징
-
균형 트리(Balanced Tree): B-Tree는 트리의 균형을 유지합니다. 이는 트리의 높이가 균등하게 유지되어 데이터 검색 속도를 일정하게 유지할 수 있도록 합니다.
-
다단계 인덱스(Multi-Level Index): B-Tree는 다단계 인덱스를 지원합니다. 이는 많은 양의 데이터를 효율적으로 검색하기 위해서 필요합니다.
-
분할 구조(Split Structure): B-Tree는 트리 노드를 분할하는 방식으로 인덱스를 구성합니다. 이는 인덱스의 크기가 동적으로 조절될 수 있도록 합니다.
-
순차 접근(Sequential Access): B-Tree는 데이터를 순차적으로 접근하는 경우에도 높은 성능을 유지합니다. 이는 B-Tree가 디스크에서 읽어오는 데이터를 최소화하기 때문입니다.
-
인덱스 클러스터링(Index Clustering): B-Tree는 인덱스 클러스터링을 지원합니다. 이는 인덱스와 함께 데이터를 클러스터링하여 검색 속도를 높이는 것을 의미합니다.
📝 B+Tree
B+Tree는 B-Tree와 유사하기 때문에 차이점만 파악하고 넘어갈 것입니다.
B+Tree는 B-Tree와 유사하지만, 리프 노드에만 키 값과 데이터가 저장되는 점이 다릅니다. 이를 통해 리프 노드 간 연결 리스트를 이용하여 범위 검색에 용이하도록 설계되어 있습니다. B+Tree는 범위 검색과 같은 연속적인 값을 가진 쿼리에서 뛰어난 성능을 보이는데, 이는 노드 당 저장할 수 있는 키 값의 개수가 많기 때문입니다. 또한, B+Tree에서는 리프 노드만 디스크에 저장되며, 다른 노드들은 캐시에 저장됩니다. 이는 디스크 접근 횟수를 줄여 성능을 향상시키는데 큰 역할을 합니다.
✍ 인덱스 만드는 방법 (MySQL 기준 작성)
📝 Cluster Type
-
데이터를 저장하는 물리적인 순서와 인덱스 순서가 같은 인덱스입니다.
-
인덱스의 리프 노드에는 데이터가 저장되어 있으므로, 리프 노드를 통해 데이터를 바로 가져올 수 있습니다.
-
하나의 테이블에 대해서는 하나의 클러스터 인덱스만 생성할 수 있습니다.
-
데이터의 물리적인 순서가 자주 변경되는 경우에는 인덱스를 다시 생성해야 하기 때문에 오버헤드가 큽니다.
📝 Secondary Type
-
데이터를 저장하는 물리적인 순서와 인덱스 순서가 다른 인덱스입니다.
-
인덱스의 리프 노드에는 해당 레코드의 주소가 저장되어 있으므로, 리프 노드를 통해 데이터를 가져올 때는 먼저 해당 레코드의 주소를 찾은 후 데이터를 가져와야 합니다.
-
하나의 테이블에 대해서 여러 개의 보조 인덱스를 생성할 수 있습니다.
-
인덱스의 순서와 데이터의 물리적인 순서가 다르기 때문에, 데이터의 물리적인 순서가 자주 변경되더라도 인덱스를 다시 생성할 필요가 없습니다.
✍ Index 최적화
📝 최적화를 해야하는 이유
-
쿼리 성능 향상: 인덱스를 최적화하면 쿼리의 성능이 향상됩니다. 인덱스를 사용하면 데이터베이스 엔진이 데이터를 더 빠르게 찾을 수 있습니다. 따라서 인덱스를 최적화하여 쿼리의 실행 속도를 높일 수 있습니다.
-
저장 공간 최적화: 인덱스를 최적화하면 저장 공간을 최적화할 수 있습니다. 인덱스를 최적화하면 인덱스가 사용하는 저장 공간을 줄일 수 있습니다. 이는 디스크 공간을 절약할 수 있으며, 디스크 I/O 작업을 줄여 데이터베이스 성능을 향상시킵니다.
-
데이터 일관성 유지: 인덱스를 최적화하면 데이터 일관성을 유지할 수 있습니다. 인덱스를 최적화하면 인덱스가 참조하는 데이터의 일관성을 유지할 수 있습니다. 이는 데이터베이스에서 잘못된 결과를 반환하는 문제를 방지할 수 있습니다.
-
시스템 확장성 향상: 인덱스를 최적화하면 시스템의 확장성을 향상시킬 수 있습니다. 인덱스를 최적화하면 데이터베이스 성능이 향상되어 더 많은 데이터를 처리할 수 있습니다. 따라서 인덱스를 최적화하여 시스템의 확장성을 향상시킬 수 있습니다.
📝 MySQL에서 Index 최적화 하는 방법
-
적절한 열 선택: 인덱스는 데이터베이스의 검색 속도를 높이는 데 도움을 줍니다. 그러나 모든 열에 인덱스를 추가할 필요는 없습니다. 검색 또는 정렬에 자주 사용되는 열에 인덱스를 만드는 것이 좋습니다.
-
중복 인덱스 제거: 테이블에 중복 인덱스가 있으면 데이터베이스 성능에 부정적인 영향을 미칠 수 있습니다. 중복 인덱스를 제거하여 데이터베이스의 성능을 최적화할 수 있습니다.
-
인덱스의 크기 제한: 인덱스의 크기가 너무 크면 데이터베이스 성능이 떨어질 수 있습니다. 필요한 경우 인덱스의 크기를 최소화하고 데이터베이스 성능을 최적화해야 합니다.
-
정렬 순서 선택: 인덱스를 만들 때 정렬 순서를 선택할 수 있습니다. 인덱스의 정렬 순서가 검색 쿼리와 일치하지 않으면 데이터베이스 성능이 떨어질 수 있습니다.
-
NULL 값을 처리하는 방법 선택: NULL 값을 처리하는 방법에 따라 인덱스의 성능이 달라질 수 있습니다. NULL 값을 허용하지 않는 경우와 NULL 값을 허용하는 경우의 차이점을 이해하고 필요한 경우 NULL 값을 허용하는 방법을 선택해야 합니다.
-
인덱스 유형 선택: MySQL에서는 여러 종류의 인덱스를 지원합니다. 테이블의 크기와 특성에 따라 적절한 인덱스 유형을 선택해야 합니다. 예를 들어, 열의 값이 자주 변경되는 경우 클러스터형 인덱스보다 보조 인덱스를 사용하는 것이 더 효율적일 수 있습니다.
-
인덱스 선별: 모든 쿼리에 대해 인덱스를 생성하면 인덱스의 크기가 너무 커져 데이터베이스 성능이 떨어질 수 있습니다. 필요한 쿼리에 대해서만 인덱스를 생성하고 불필요한 인덱스를 제거하는 것이 좋습니다.
