스파크는 현시점에서 빅 데이터 처리의 표준으로 인식된다. Scala, Java, Python 등 여러 언어를 지원하며 SQL부터 Streaming 처리 뿐 아니라 ML 라이브러리까지 자체적으로 포함되어 있다.
스파크 어플리케이션의 아키텍처
스파크란?
스파크의 정확한 정의를 보자. 스파크는 통합 컴퓨팅 엔진이며, 데이터를 병렬로 처리하는 라이브러리 집합이다. MapReduce 엔진으로만 데이터 처리 (특히 머신러닝 알고리즘)를 하는 데, 단계별로 맵리듀스 잡을 개발해야 하고, 단계마다 디스크에 결과를 저장하게 되는데, 이는 실행 속도 또한 다소 느리게 만들었다.
Spark 주요 개념
스파크를 이해하기 위해 두 가지 필수 용어를 알고가자.
-
Resilient Distributed Datasets (RDD):
스파크가 다루는 데이터의 최소 단위이며, 스파크 내에서 데이터 처리할 때, 실패에 대한 내결함성을 보장해준다. (실패 지점에서부터 태스크 재실행) RDD는 Transformation과 Action이라는 두 가지 연산으로만 변경된다. -
Directed Actclic Graph(DAG):
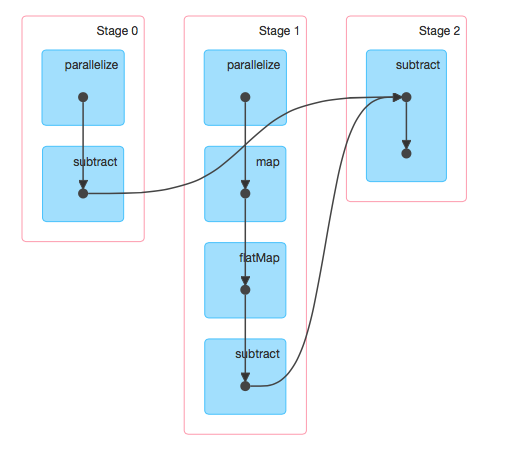 "물리적 실행계획"이라고 하며, 쉽게 말하면, 어플리케이션을 처리할 때, 어떤 순서로 처리할까 계획을 스파크 드라이버가 세우는 것이다.
"물리적 실행계획"이라고 하며, 쉽게 말하면, 어플리케이션을 처리할 때, 어떤 순서로 처리할까 계획을 스파크 드라이버가 세우는 것이다.
구성요소
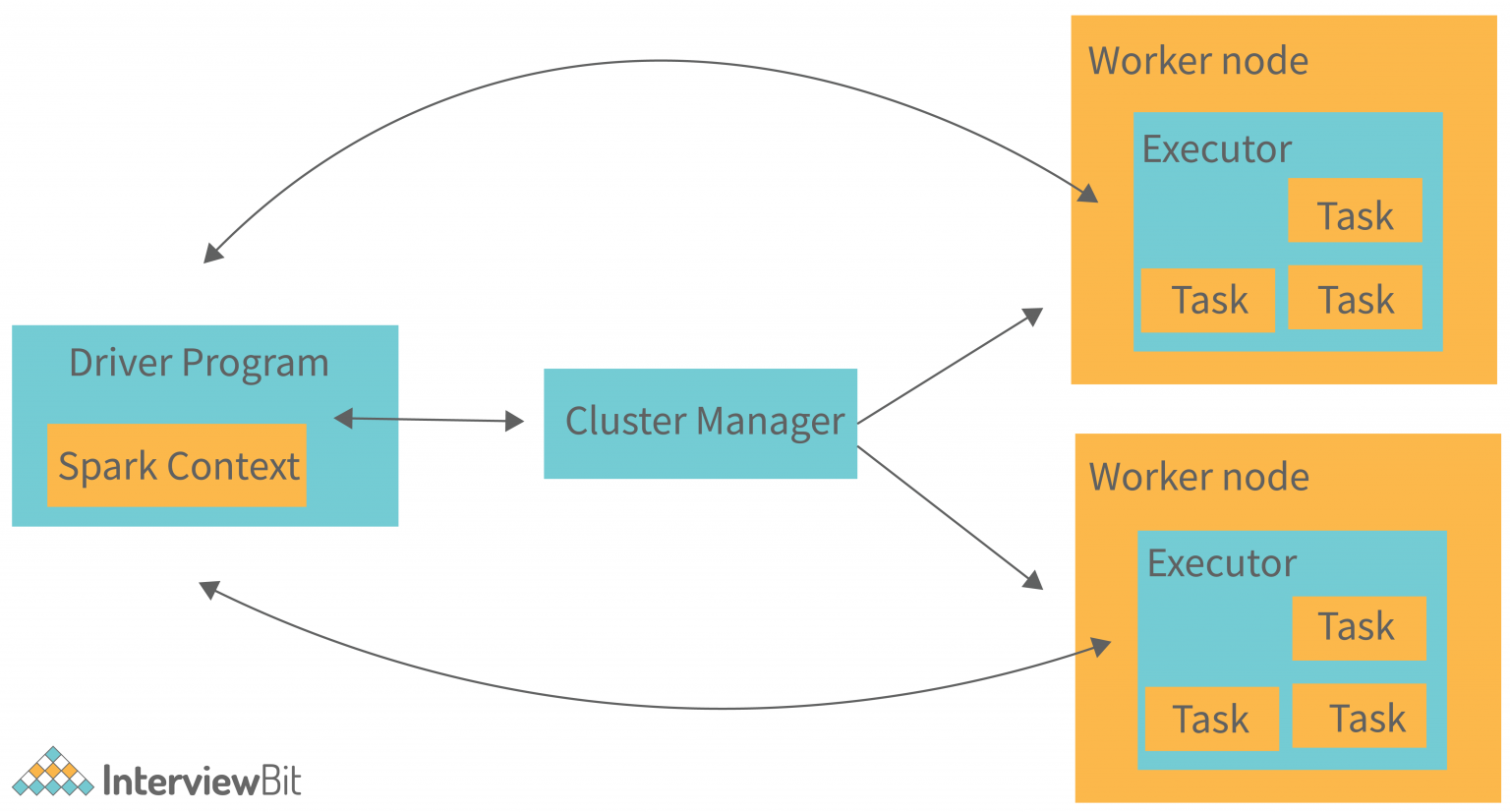
그림을 보면, 뭔가 비슷한 것이 떠오른다. 바로 Resource Manager 중 하나인 YARN의 아키텍쳐이다. 자세한 것은 여기를 보자.
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 4g \
--executor-memory 2g \
--executor-cores 1 \
--queue thequeue \
examples/jars/spark-examples*.jar \
10Yarn 아키텍쳐를 알고 있다면, Application Master가 어떤 것인지 알고 있을 것이다. 위에 Spark Job을 제출하는 코드를 보면, "--master" 코드가 눈에 보인다. 스파크는 "데이터 처리 엔진"이므로 데이터를 처리할 때, 필요한 자원을 돌아가는 시스템에서 할당해줄 파트너가 필요하다. 그래서 어떤 리소스 매니저를 파트너로 삼을 것인가 하는 옵션이 필요한데, 그것이 바로 저 --master 옵션이다. 그래서 스파크의 구성 요소를 말할 때, 클러스터 매니저(리소스 매니저)도 보통 포함시켜서 말한다.
-
스파크 드라이버
: 스파크 드라이버는 스파크 어플리케이션의 실행을 제어하고, 익스큐터의 상태와 태스크에 대한 상태 정보를 유지하는 프로세스이다. 클러스터 매니저와 통신할 수 있어야 한다. -
스파크 익스큐터
: 할당한 태스크를 수행하는 프로세스이다. 잡을 수행하고, 결과를 캐시에 보관한다. 결과는 드라이버에 보고한다.
-
클러스터 매니저
: 스파크는 드라이버 프로세스와 익스큐터 프로세스로 나뉘어 실행이 되는데, 이 프로세스들을 어디에 띄울 것인가를 결정하고, 어플리케이션 마스터의 요청을 받아, 리소스를 할당해주는 역할을 한다. Resource Manager 프로세스가 띄워진 드라이버 노드와 Node Manager 프로세스가 띄워진 워커 노드(태스크를 실행하는 노드)의 개념으로 나누어져있다.- 종류로는 메소스, 하둡 YARN, Kubernetes 등이 있다.
이 구성요소들을 통해, 어떻게 Spark가 실행되는지 살펴보자.
Spark의 실행 모드
스파크는 여러가지 모드로 실행된다. 클러스터와 같은 거대한 자원으로 돌리는 경우 일반적으로 Cluster Mode, Client Mode로 돌리고, 로컬이나 기타 테스트 환경에서 스파크를 실행시키는 경우 Local Mode로 실행시킨다.
스파크 실행 시, 실행 프로세스는 두 가지가 있는데,
- 드라이버: 코드의 main() 부분을 실행하는 프로세스이다.
- 익스큐터: 드라이버가 요청한 태스크를 실행하는 프로세스이다.
이를 기억하고 다음을 보자.
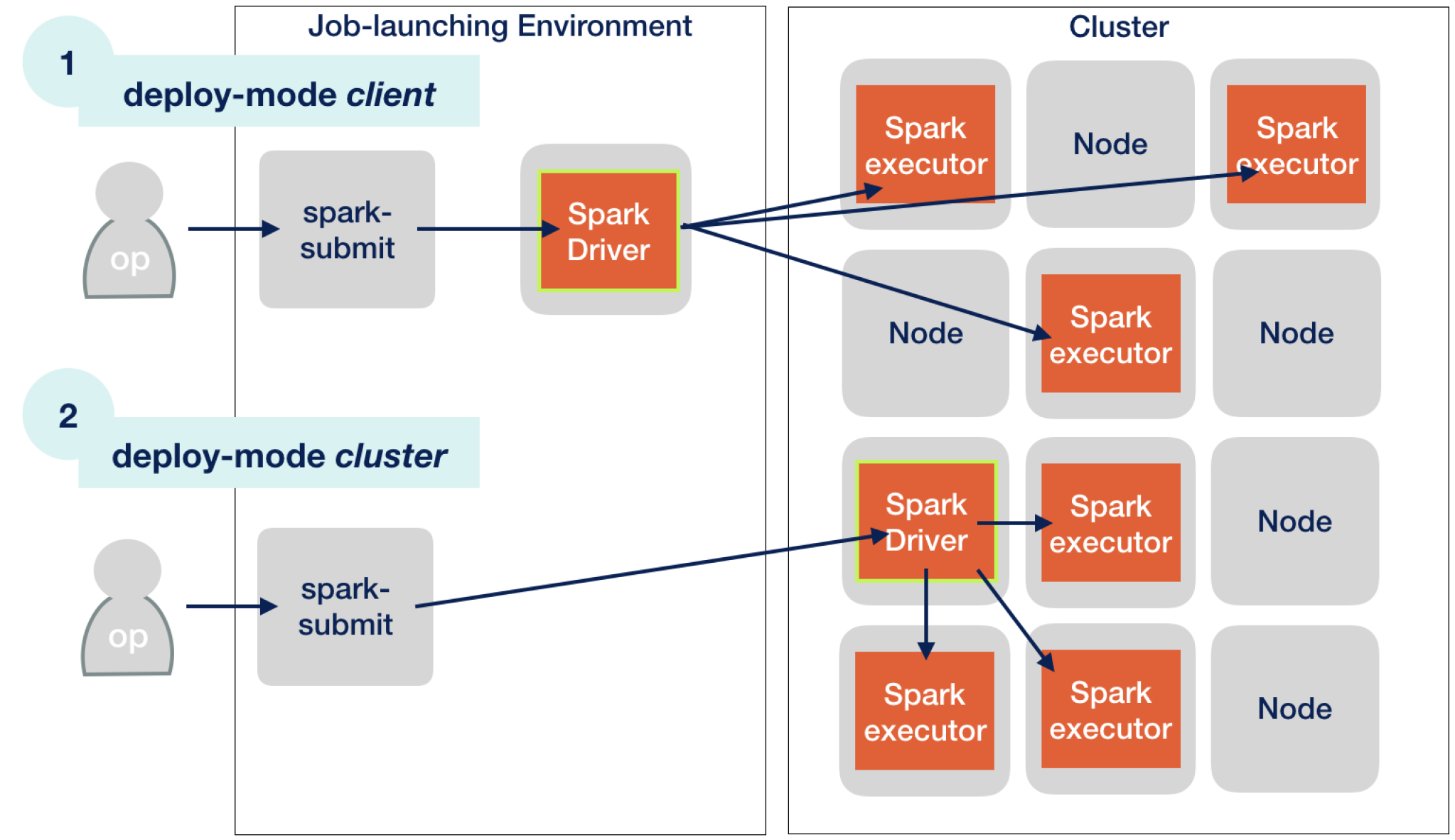
Cluster Mode
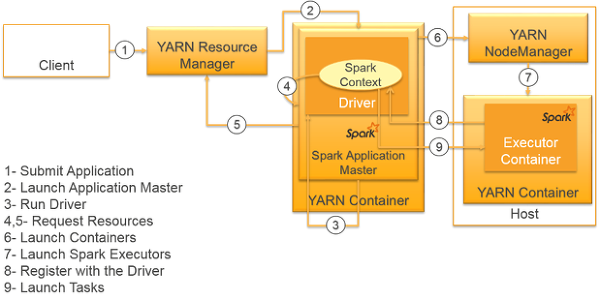
가장 흔하게 사용되는 실행방식으로서, (그림의 번호는 무시하길 바란다)
- Client가 Jar 파일이나 스크립트를 클러스터 매니저에게 전달
- 클러스터 매니저는 파일 혹은 스크립트를 받고, 어플리케이션 마스터를 워커 노드에 실행시킴.
- Application Master 위에서 Spark 앱이 실행됨.
- 스파크 어플리케이션의 요청에 따라, 워커 노드들에 리소스 할당
- 할당된 리소스를 받은 NodeManager는 Executor 실행.
클러스터 매니저는 드라이버, 익스큐터를 모두 관리 한다.
Client Mode
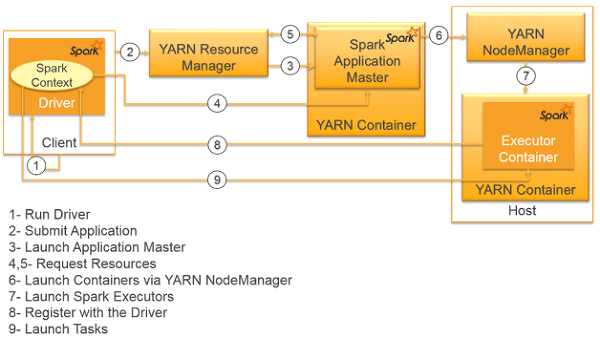
(그림의 번호는 무시하길 바란다)
- 드라이버 프로세스를 client 환경 안에서 실행.
- 클러스터 매니저에 어플리케이션 실행 정보 제출
- Application Master를 워커 노드에 실행.
- Application Master를 통해 필요한 자원을 Driver가 요청하고,
Application Master은 이를 클러스터 매니저에게 전달. - 워커 노드들에 Executor 실행.
스파크 드라이버가 AM에게 필요한 자원을 요청하고, 이를 RM에게 전달해주는 것을 주목하라.
클러스터 매니저는 익스큐터만을 관리한다.
Local Mode
모든 스파크 어플리케이션이 단일 머신에서 실행. 병렬 처리 시, 단일 머신의 스레드를 활용.
스파크 어플리케이션의 실행
다음과 같은 코드의 job이 실행된다고 가정해보자.
df1 = spark.range(2, 10000000, 2)
df2 = spark.range(2, 10000000, 4)
step1 = df1.repartition(5)
step12 = df2.repartition(6)
step2 = step1.selectExpr("id * 5 as id")
step3 = step2.join(step12, ["id"])
step4 = step3.selectExpr("sum(id)")
step4.collect()모든 스파크 어플리케이션은 먼저 SparkSession을 생성한다. (그림들에서 나온 Spark Context 와 같은 역할을 한다고 생각하자.)
액션 하나당 스파크 잡이 생성되며, 이는 스테이지와 태스크로 이루어져 있다.
예제의 스테이지당 태스크는 다음과 같다.
- 스테이지 1 : 태스크 8개
- 스테이지 2 : 태스크 8개
- 스테이지 3 : 태스크 5개
- 스테이지 4 : 태스크 6개
- 스테이지 5 : 태스크 200개
- 스테이지 6 : 태스크 1개스테이지는 다수의 머신에서 동일한 연산을 수행하는 태스크의 그룹이라 보면된다. 스파크는 가능한 한 많은 태스크를 동일한 스테이지로 묶으려 노력한다. 셔플 작업이 일어난 다음에는 반드시 새로운 스테이지를 시작한다.
여기서 중요한 점을 알 수 있는데
Transformation 함수는 Action이 호출되기 전, 실행되지 않고 실행계획만 스파
크가 세우는데, DAG를 통한 최적화를 위해서임을 이 부분에서 알 수 있다. 하나의
스테이지에서 여러개의 transformation들을 한데 묶어, 파이프라이닝 기법과
DAG 최적화를 통해 각 노드 안에 있는 데이터만을 가지고 할 수 있는 연산들을 모아
단일 스테이지로 만드는 것이다. 예를들어 map, filter, map 순서로 수행되는
RDD 기반의 프로그램이 있다면 중간에 디스크 결과를 저장하지 않고, 메모리에서
전부 다 처리하는 것이다.태스크는 파티션을 처리하는 작업 단위라고 볼 수 있으며, 스테이지는 태스크들로 구성된다.
파티션은 작업을 처리하는 데 가장 작은 데이터 단위라고 볼 수 있다.
따라서 여러 요인에 의해 영향을 받을 수 있지만, 클러스터의 익스큐터 수보다 파티션 수를 더 크게 지정하는 것이 좋다. 반대의 경우, 놀고 있는 익스큐터가 생기기 때문이다.
실행을 하면서 셔플 결과 저장 을 수행한다. 셔플 후, 셔플 파일을 로컬디스크에 저장을 한다. 이를 통해 job이 실패할 경우, 이미 기록되어 있는 셔플 파일을 다시 사용하여 해당 스테이지부터 처리할 수 있다.
출처:
https://1ambda.blog
https://spark.apache.org
https://www.interviewbit.com/
Spark : The definition Guide
