Hadoop을 배우게 되면, MapReduce 다음으로 Yarn의 개념을 가장 많이 접하게 되는데, 대부분은 단순히 리소스 매니저라는 단어 정도로만 머릿속에 넣고, 지나간다. 하지만, 문제 해결을 하는 데 있어서, 문제의 본질과 핵심에 대해 깊이 알지 못하면 결국 그것을 해결하지 못한다는 믿음에 근거하여, 정리를 남기고자 한다.
먼저 Yarn이 Hadoop 2.0 부터 나오게 된 배경부터 살펴보자.
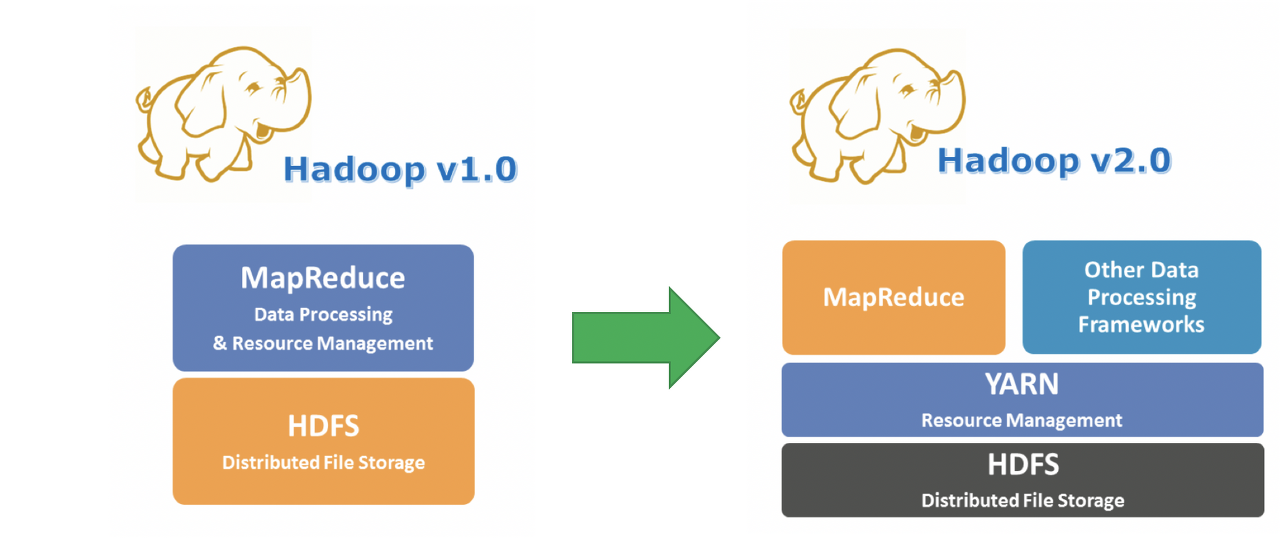
Hadoop 1.0
Hadoop 1.0에서는 Data Processing 부분과 Resource Management 부분을 하나의 Layer로 관리해왔음을 알 수 있는데, 이를 좀 더 자세히 말하자면
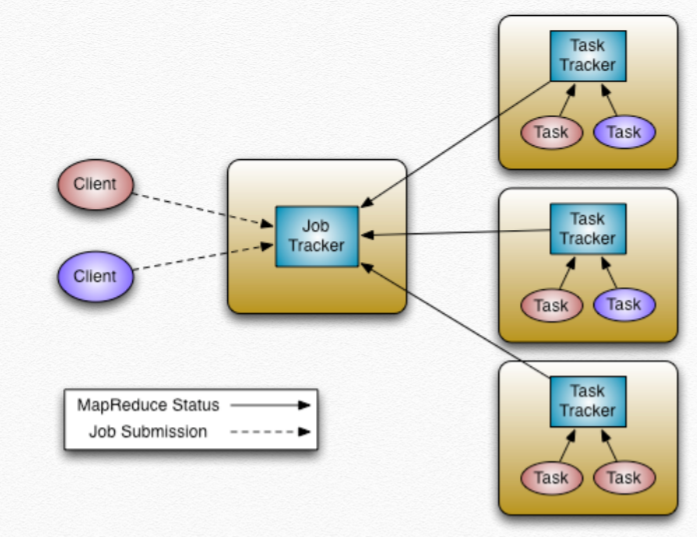
Job Tracker와 Task Tracker라는 두 개의 구성 요소를 생각하면 되겠다.
Job Tracker:
클러스터에서 현재 얼마의 resource가 가용한지 등을 모니터링하는 리소스 관리 기능 을 수행하고, MapReduce 잡을 스케줄링 하고 배포하고 모니터링하는 실행 관리 기능 을 수행한다.
Task Tracker:
Job Tracker에게 수행될 Task의 ID를 받아와, 그 Task의 Processing 현황을 Job Tracker에게 보고하는 제한적인 기능만을 수행한다.
또한 Job Tracker는 Name Node(NN) 상에서 수행이 되는 데, 클러스터에서 단 하나의 name node가 hadoop 1.0의 구조상 모든 클러스터의 노드를 관리하는 구조로 되어있어, single point of failure 의 문제점이 있다. 클러스터 관리자가 자체적으로 stand by node를 활성화하도록 해야한다.
그래서 Hadoop 1.0의 경우에는 Job Tracker 가 약 4000개의 노드, 40000개의 태스크까지만 관리할 수 있다고, 알려져있다.
예를 들자면, 한 나라(Cluster)의 왕(Job Tracker)이 모든 마을들(Job)을
관리하는 것이다. 그러면 어떻게 되겠는가, 왕은 마을이 하나 둘 늘어
나다 어느 순간 패닉상태가 와서 뻗어버릴 것이다.Hadoop 2.0
하둡 2.0부터는 1.0의 많은 부족한 부분들이 보완되었다.
크게 3가지로 보면되는데,
- Job Tracker가 담당했던 클러스터 리소스 관리, 실행 관리 부분 등을 여러개의 컴포넌트로 나누어, 하나의 클러스터에 더 많은 노드와 태스크를 관리할 수 있도록 하였다.
- MapReduce 모델 뿐 아니라, Spark, HBase, Storm등의 데이터 처리 모델을 지원하게 되었다. Application Master에 특정한 어플리케이션 처리 라이브러리를 올림으로써, 하나의 하둡 클러스터에서 다양한 어플리케이션이 돌아가는 것이 가능해졌다.
- Zookeeper를 이용한 리소스 매니저의 이중화로 SPOF문제를 해결함.
Hadoop 2.0을 이해하기 위해, 그림에서 나온 컴포넌트들을 이해해야 하는데, 먼제 다음 그림을 보자.
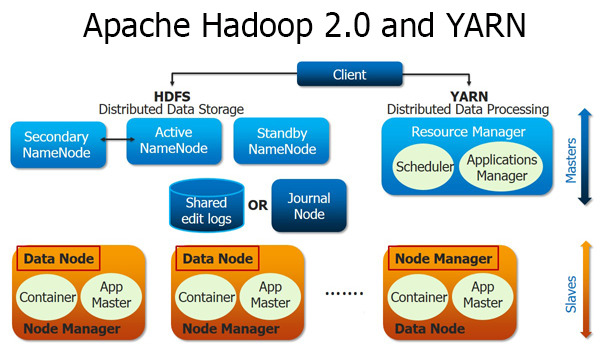
Resource Manager:
리소스 할당과 관리, 스케줄링을 책임진다. Node Manager 로부터 노드의 상태와 노드의 리소스 가용량을 전달 받고, Application Manager에게는 job을 실행하는데 필요한 리소스를 요청받고, 이에 응하여 할당해준다. Resource Manager는 크게 Scheduler와 Application Master 두가지로 나눠진다.
- Scheduler : 가용한 리소스와 할당해야할 어플리케이션의 상태를 판단해 오직 스케줄링만 하는 역할을 한다.
- Application Manager : Application Master와 헷갈리기 쉬운 개념인데, job 제출 후, 어플리케이션이 실행될 때 어플리케이션의 Application Master를 할당하고 실행시키는 역할이라고 보면 되겠다. Application Master가 실패하면, 다시 재시작도 해준다.
Node Manager:
노드 마다 하나씩 있으며, 해당 노드에 돌아가는 Application Master의 요청에 따라 컨테이너의 생성, 삭제와 실행을 책임진다. 또한, Resource Manager 에게 지속적으로 Health Status를 보내며, 리소스 사용량 등을 보고하여, 클러스터의 현재 노드 상태를 알 수 있도록 한다.
Application Master:
어플리케이션 마스터는 말 그대로 제출된 job을 책임지는 역할을 한다. Resource Manager와 Job 실행에 필요한 자원을 지속적으로 요청하면서, 어플리케이션의 실행 상태에 대해 트래킹하고, 진행사항을 모니터링 한다.
Application Master의 정확한 정의는 특정 프레임워크 별로 Job을 실행시키기 위한 별도의 라이브러리이다.
MapReduce는 MapReduce Application Master
Storm은 Storm Application Master
Spark는 Spark Application Master
에 올리는 것이라 보면된다.
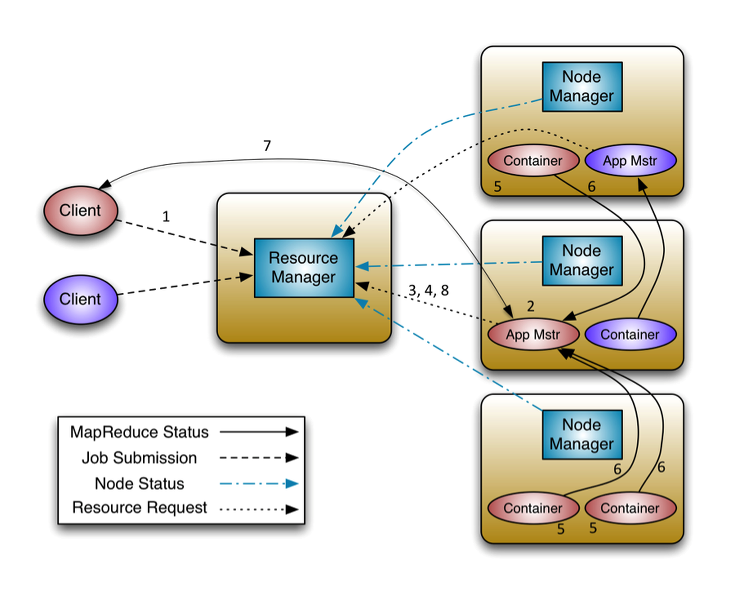
하둡 2.0은 크게 3가지 인터페이스로 통신한다.
- Client<-->ResourceManager
ApplicationClientProtocol
- ApplicationMaster<-->ResourceManager
ApplicationMasterProtocol
- ApplicationMaster<-->NodeManager
ContainerManagementProtocol
사용자는 Job을 ResourceManager에게
ApplicationClientProtocol을 통해 전달한다.
job을 제출한 후, Application Master는 ApplicationClientProtocol을 통해, job이 실행되는 데 필요한 리소스를 RM에게 요청하고,
태스크가 실행하는 동안, Application Master는 Node Manager와 ContainerManagementProtocol 을 통해 통신을 하며, 모든 컨테이너와 관련한 이벤트들은 이 프로토콜을 통해 이루어진다고 보면된다.
노드 매니저는 Container Launch Context(CLC)를 Application Master에게 받아, 태스크를 실행시킨다.
Container Launch Context(CLC) : 어플리케이션이 실행되는 데 있어 필요한 모든 것을 담은 객체.
ContainerLaunchContext container = ContainerLaunchContext.newInstance(
localResources, env, commands, null, null, null);
와 같이 사용하며, 태스크가 실행되는 데 필요한 변수, 메타데이터, 실행 명령어, 리소스 등등 이 포함되어있다.출처:
https://hadoop.apache.org/
https://blog.skcc.com/
https://www.geeksforgeeks.org
https://www.tutorialspoint.com
