🐒 문제
https://programmers.co.kr/learn/courses/30/lessons/64065
✍ 나의 풀이 (리팩토링 전)
def solution(s):
answer = []
s = s[:-2].replace('{','').replace(',',' ').split('}')
for i,v in enumerate(s):
s[i] = v.split()
s.sort(key=lambda x:len(x))
for tup in s:
for i in answer:
tup.remove(i)
answer.append(tup[0])
answer = [int(i) for i in answer]
return answer풀이시간은 30분 안되게 들었다.
처음에 문제를 보고 순서도 없고 중복도 있는 튜플들을 처리해서
어떻게 순서있는 리스트로 리턴해야할지 감이 안왔지만,
테스트케이스의 예시를 종이에 끄적여보면서 이해할 수 있었다. 필기의 힘
🧠 문제 이해
풀이를 위해 두단계로 문제에 접근하였다.
- 문자열 입력을 처리에 용이하도록 리스트 자료형으로 변환하기
- 리스트의 요소들을 처리하여 결과 리턴하기
1. 문자열 입력을 iterable 자료형 (리스트)으로 변환하기
입력받은 데이터를 특정 패턴이나 순서로 추출해 원하는 형태로 가공하는 것을 파싱(Parsing)이라고 한다.
s = "{{4,2,3},{3},{2,3,4,1},{2,3}}"입력은 위와 같은 문자열 형태로 주어진다.
중괄호로 묶여진 '튜플'들의 관계를 훼손하지 않고 리스트 자료형으로 변환이 필요했다.
s = s[:-2].replace('{','').replace(',',' ').split('}')
for i,v in enumerate(s):
s[i] = v.split()나는 위 코드를 통해 변환해주었다.
처리 과정을 차례대로 설명하면
s = "{{4,2,3},{3},{2,3,4,1},{2,3}}"
s[:-2] 으로 마지막 중괄호 두개를 지우면
s = "{{4,2,3},{3},{2,3,4,1},{2,3"
s.replace('{', '') 을 통해 문자열 중 '{'을 지우면
s = "4,2,3},3},2,3,4,1},2,3"
s.replace(',', ' ') 을 통해 문자열 중 ','을 공백으로 치환하면
s = "4 2 3} 3} 2 3 4 1} 2 3"
s.split('}') 을 통해 문자열 중 '}'을 기준으로 문자열을 갈라내어 리스트로 변환하면
s = [["4 2 3"], ["3"], ["2 3 4 1"], ["2 3"]]
하지만 이 상태에서는 리스트 s의 요소들 속에
문자열 형태로 저장된 숫자들이 분리가 되지 않았음을 볼 수 있다.
for i,v in enumerate(s): 리스트 s를 돌면서
s[i] = v.split() 요소 v를 공백문자를 기준으로 문자열을 갈라내어 리스트로 변환하면
s = [['4', '2', '3'], ['3'], ['2', '3', '4', '1'], ['2', '3']]
문자열 입력을 리스트로 변환하였다.
2. 리스트의 요소들을 처리하여 결과 리턴하기
처음엔 문제가 요구하는 것을 이해하지 못했다.
그러나 예시를 살펴보면서 이해하였는데,
s result "{{2},{2,1},{2,1,3},{2,1,3,4}}" [2, 1, 3, 4] "{{1,2,3},{2,1},{1,2,4,3},{2}}" [2, 1, 3, 4] "{{20,111},{111}}" [111, 20] "{{123}}" [123] "{{4,2,3},{3},{2,3,4,1},{2,3}}" [3, 2, 4, 1]
s = "{{4,2,3},{3},{2,3,4,1},{2,3}}" 예시로 하면,
일단 result = []으로 초기화를 시켜주고
s에서 가장 길이가 짧은 튜플인 {3}에서 3을 result에 append한다.
s에서 다음으로 길이가 짧은 {2,3}을 보면
이전 튜플에서 2가 추가되었음을 볼 수 있다.
2를 result 에 append 한다.
s에서 다음으로 길이가 짧은 {4,2,3}을 보면
이전 튜플에서 4가 추가되었음을 볼 수 있다.
4를 result 에 append 한다.
s에서 다음으로 길이가 짧은 {2,3,4,1}을 보면
이전 튜플에서 1이 추가되었음을 볼 수 있다.
1을 result 에 append 한다.
result 는 [3, 2, 4, 1] 이 되었고, 이는 문제에서 요구하는 정답이다.다시말해서 s에서 가장 길이가 작은 '튜플'부터 확인해, 이전 튜플에서 추가된 숫자를 result에 append 하는 방법을 통해 답을 구했다.
이를 코드로 구현하면
s에서 가장 길이가 작은 튜플부터 확인하기 위해서
s.sort(key=lambda x:len(x))
을 통해 s의 각 요소의 길이를 기준으로 리스트 s를 오름차순으로 정렬하였다.이전 튜플에서 추가된 숫자를 result에 append 하기 위해서는
이전 튜플과 현재튜플을 비교하여야 하는데,
result에 이전 튜플까지의 기록이 계속 저장되고 있으므로
result에 저장된 숫자 와 현재튜플의 숫자의 차집합은 추가된 숫자이다.
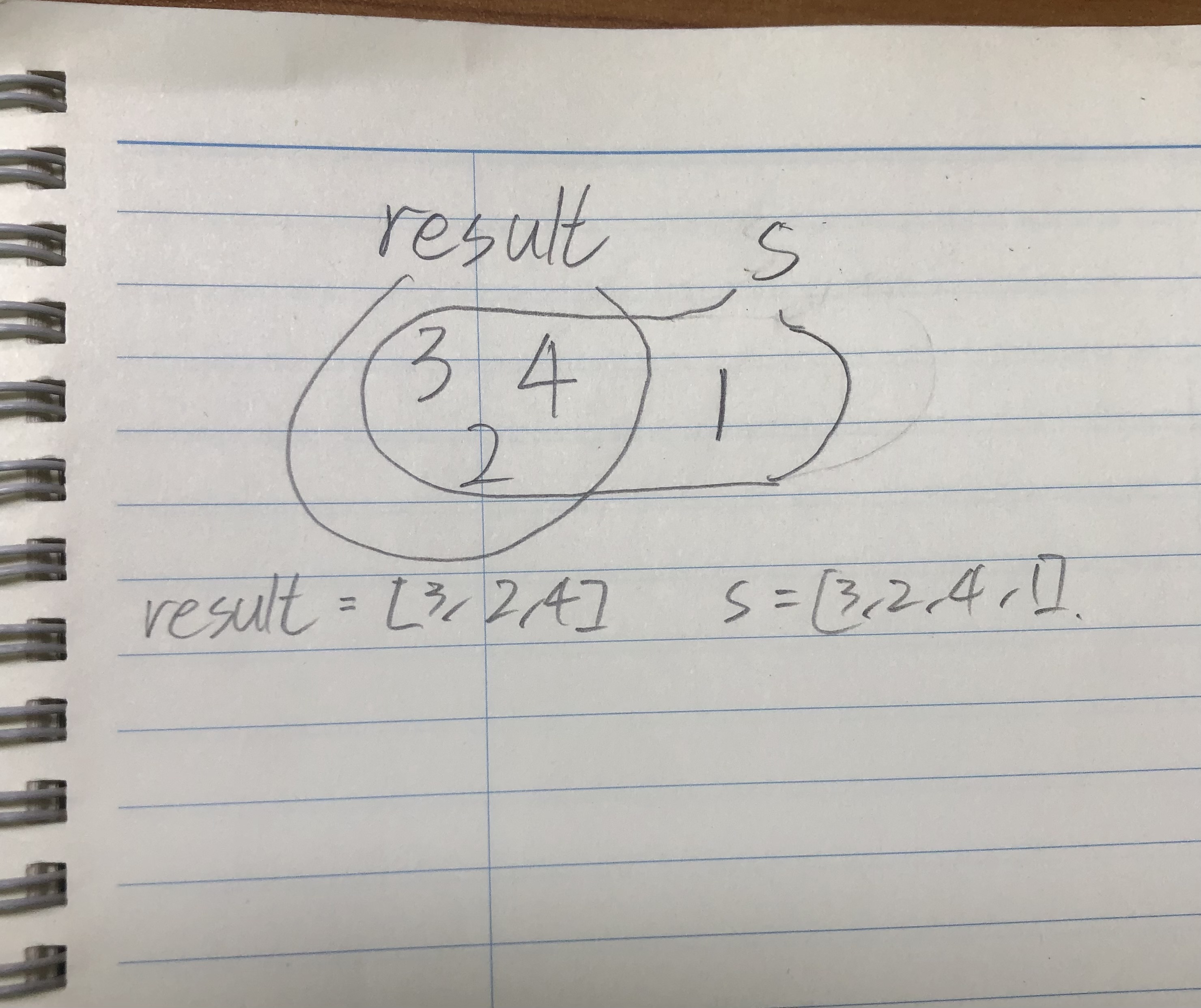
s.sort(key=lambda x:len(x))
for tup in s: 리스트 s에서 길이가 작은 요소부터 꺼내서
for i in answer: answer에 저장 된 숫자들을 tup에서 제거함
tup.remove(i)
answer.append(tup[0]) tup에 하나의 숫자가 남는데, 그 숫자를 answer 에 추가해주면 된다.현재 answer 의 요소들은 문자열 형태이므로 정수형으로 바꿔준다.
answer = [int(i) for i in answer] answer에서 순서대로 하나씩 꺼내서 정수형으로 바꿔줌이제 answer은 문제에서 요구하는 답이 된다.
테스트 1 〉 통과 (0.03ms, 10.4MB)
테스트 2 〉 통과 (0.02ms, 10.5MB)
테스트 3 〉 통과 (0.02ms, 10.3MB)
테스트 4 〉 통과 (0.04ms, 10.4MB)
테스트 5 〉 통과 (0.20ms, 10.5MB)
테스트 6 〉 통과 (0.53ms, 10.5MB)
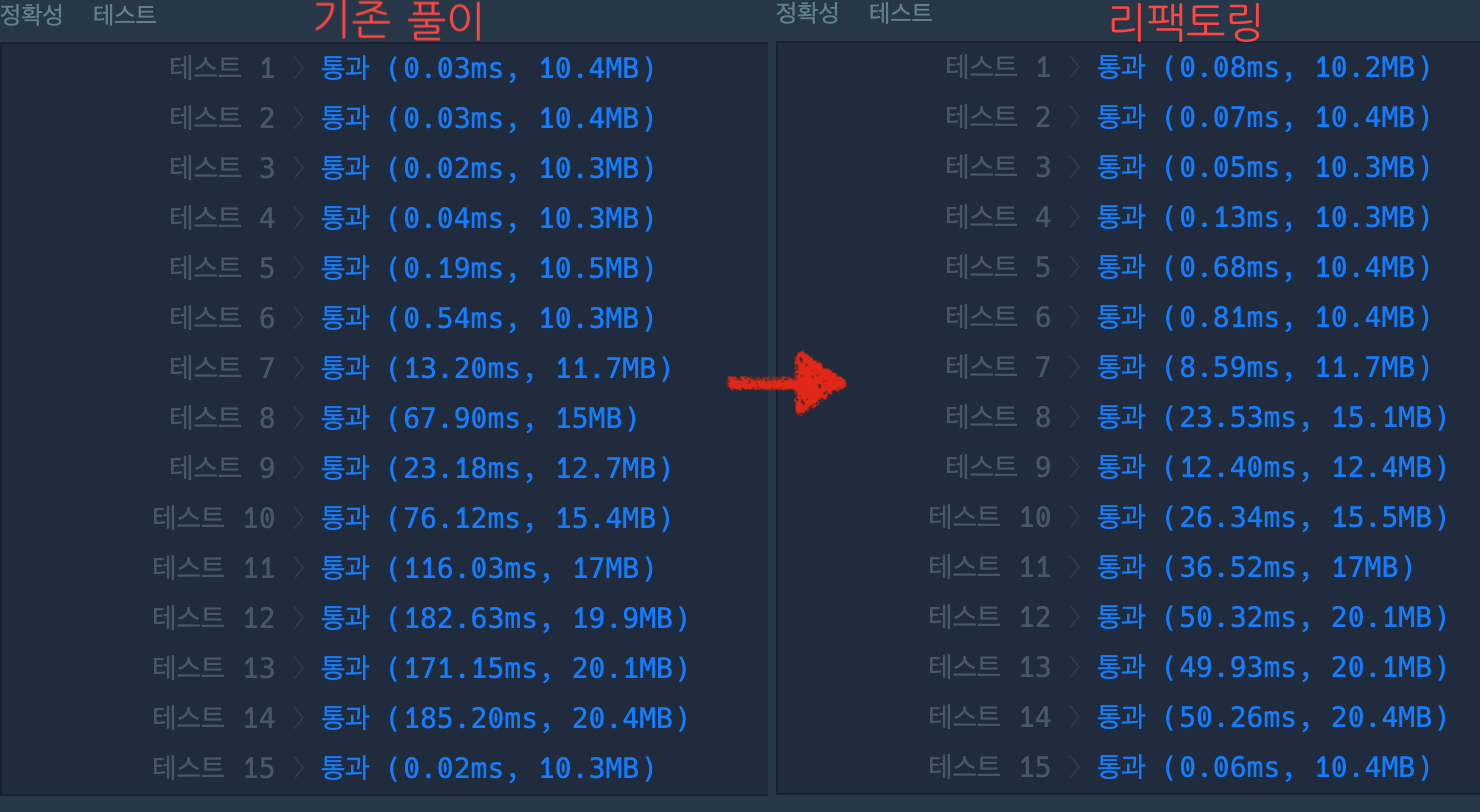
테스트 7 〉 통과 (13.22ms, 11.6MB)
테스트 8 〉 통과 (64.46ms, 14.7MB)
테스트 9 〉 통과 (22.99ms, 12.3MB)
테스트 10 〉 통과 (75.88ms, 15.1MB)
테스트 11 〉 통과 (109.99ms, 16.7MB)
테스트 12 〉 통과 (172.37ms, 19.8MB)
테스트 13 〉 통과 (182.52ms, 19.8MB)
테스트 14 〉 통과 (184.40ms, 20MB)
테스트 15 〉 통과 (0.02ms, 10.4MB)리팩토링1
for i,v in enumerate(s):
s[i] = v.split()
위 코드를 아래처럼 깔끔하게 나타낼 수 있다.
s = [i.split() for i in s]수정된 코드
def solution(s):
answer = []
s = s[:-2].replace('{','').replace(',',' ').split('}')
s = [i.split() for i in s]
s.sort(key=lambda x:len(x))
for tup in s:
for i in answer:
tup.remove(i)
answer.append(tup[0])
answer = [int(i) for i in answer]
return answer리팩토링2(Counter 클래스 차집합 구현)
from collections import Counter
def solution(s):
answer = []
s = s[:-2].replace('{','').replace(',',' ').split('}')
s = [i.split() for i in s]
s.sort(key=lambda x:len(x))
for tup in s:
counter1 = Counter(tup) - Counter(answer)
answer.append(list(counter1.elements())[0])
answer = [int(i) for i in answer]
return answer기존 풀이에서 차집합의 개념을 사용했었지만 정작 차집합을 풀이에 사용하지 않았다는 것이 떠올라,
전에 풀었던 문제에서 배운 Counter 클래스의 문자열 다중집합 으로 차집합을 구현하였다.
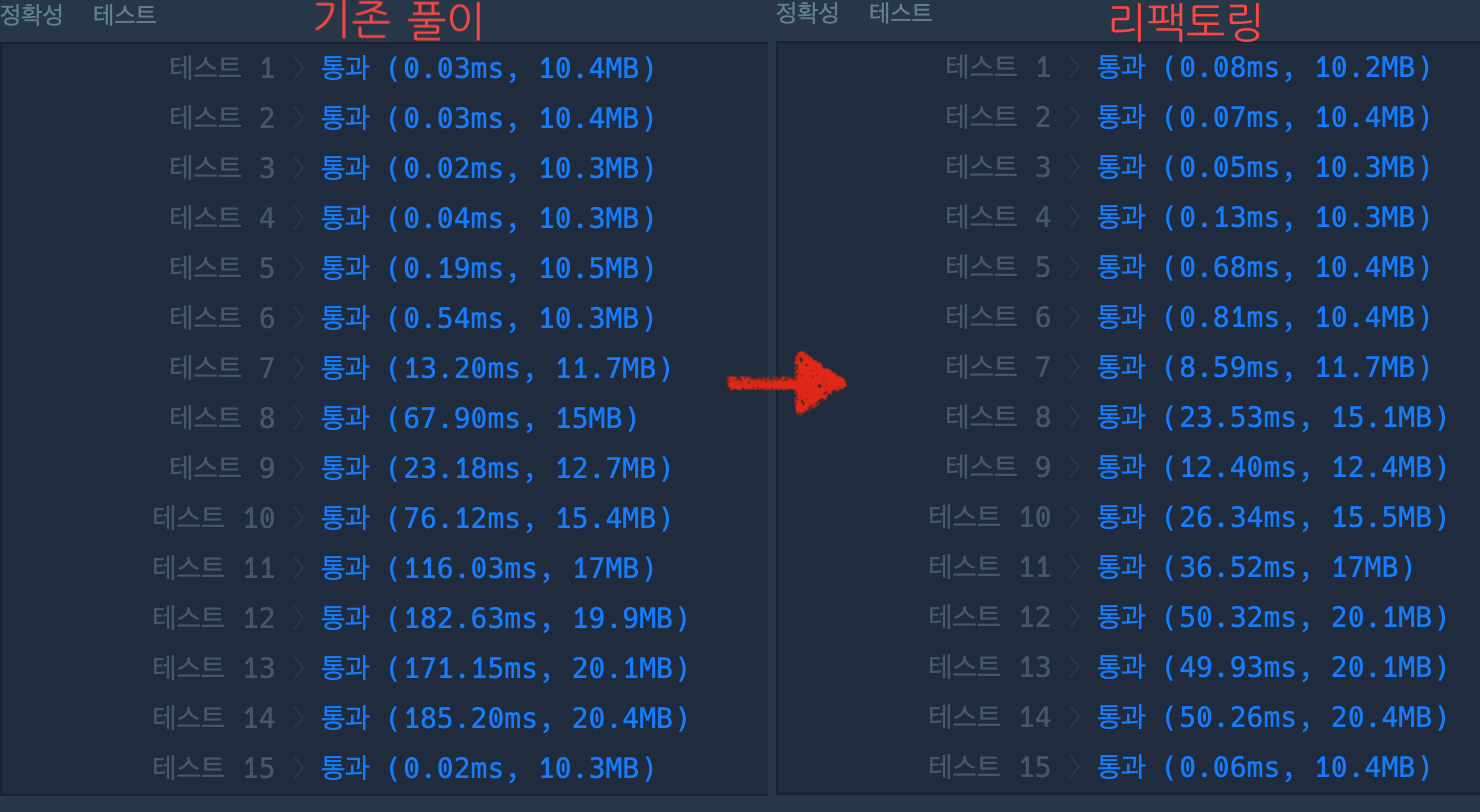
그 결과, 시간복잡도가 확실하게 줄어든 것이 확인되었다! 😚
리팩토링3 (set자료형으로 차집합 구현)
def solution(s):
answer = []
s = s[:-2].replace('{','').replace(',',' ').split('}')
s = [i.split() for i in s]
s.sort(key=lambda x:len(x))
for tup in s:
diff = set(tup) - set(answer)
answer.append(list(diff)[0])
answer = [int(i) for i in answer]
return answer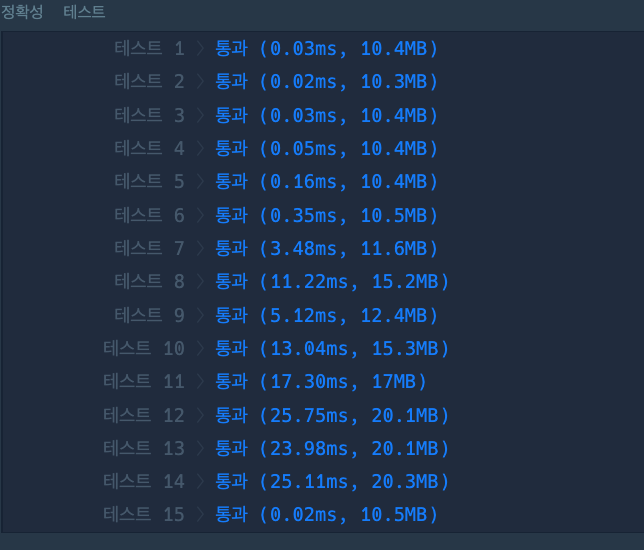
이번 글은 깔끔하게 정리가 잘 된것 같아서
도움이 필요한 사람들에게 참고해보라고 질문게시판에 글을 등록했다.

그런데 댓글로 set자료형으로 차집합을 구현할 수 있다고 하셔서 한번 구현 해봤더니 시간이 절반으로 줄었다~
당시에 set자료형 쓰면 중복제거가 발생할 것 같아서 일부러 Counter 클래스를 사용했던거같은데

문제를 왜 헷갈리게 써놓는겨..
