🐒 문제
https://programmers.co.kr/learn/courses/30/lessons/72412#qna
✍ 나의 풀이 (시간초과)
def solution(info, query):
answer = []
info = [i.split() for i in info]
# 점수 정수화 필요
query = [i.replace('and','').split() for i in query]
for conditions in query:
hired = []
for applicant,spec in enumerate(info):
if int(conditions[4]) <= int(spec[4]):
for i in range(4):
if conditions[i] == '-': # 질문 넘어감
continue
if conditions[i] != spec[i]: # 질문 불충족시
break
else:
hired.append(applicant)
answer.append(len(hired))
return answer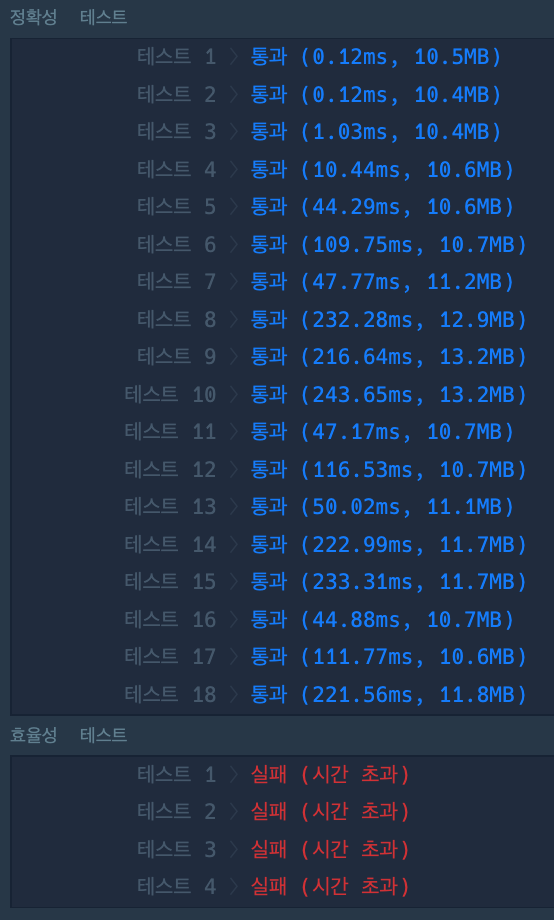
정확성 테스트는 통과했지만,
효율성 테스트에서 시간초과가 발생했다.
어떻게 시간초과를 줄여야할지 모르겠어서 검색을 했다.
참고한 블로그
카카오 - 순위검색 해설 에 따르면
정답률 : 정확성 44.07%, 효율성 4.49% 이라고 한다
효율성까지 통과해야하면 레벨2 문제가 아닌거 같은데..😂
🧠 문제 이해
info 배열의 크기는 1 이상 50,000 이하입니다.
query 배열의 크기는 1 이상 100,000 이하입니다.위 조건에 따라서
이중for문을 사용해 모든 요소를 탐색하려면
으로, 50억번 탐색해야하기 때문에 시간초과가 발생한다.
시간초과를 해결하는 방법
1. '-'을 포함해 면접 질문에서 나올 수 있는 경우의 수를 모두 만들고, 경우의 수를 key 값으로 하는 딕셔너리를 만든다.
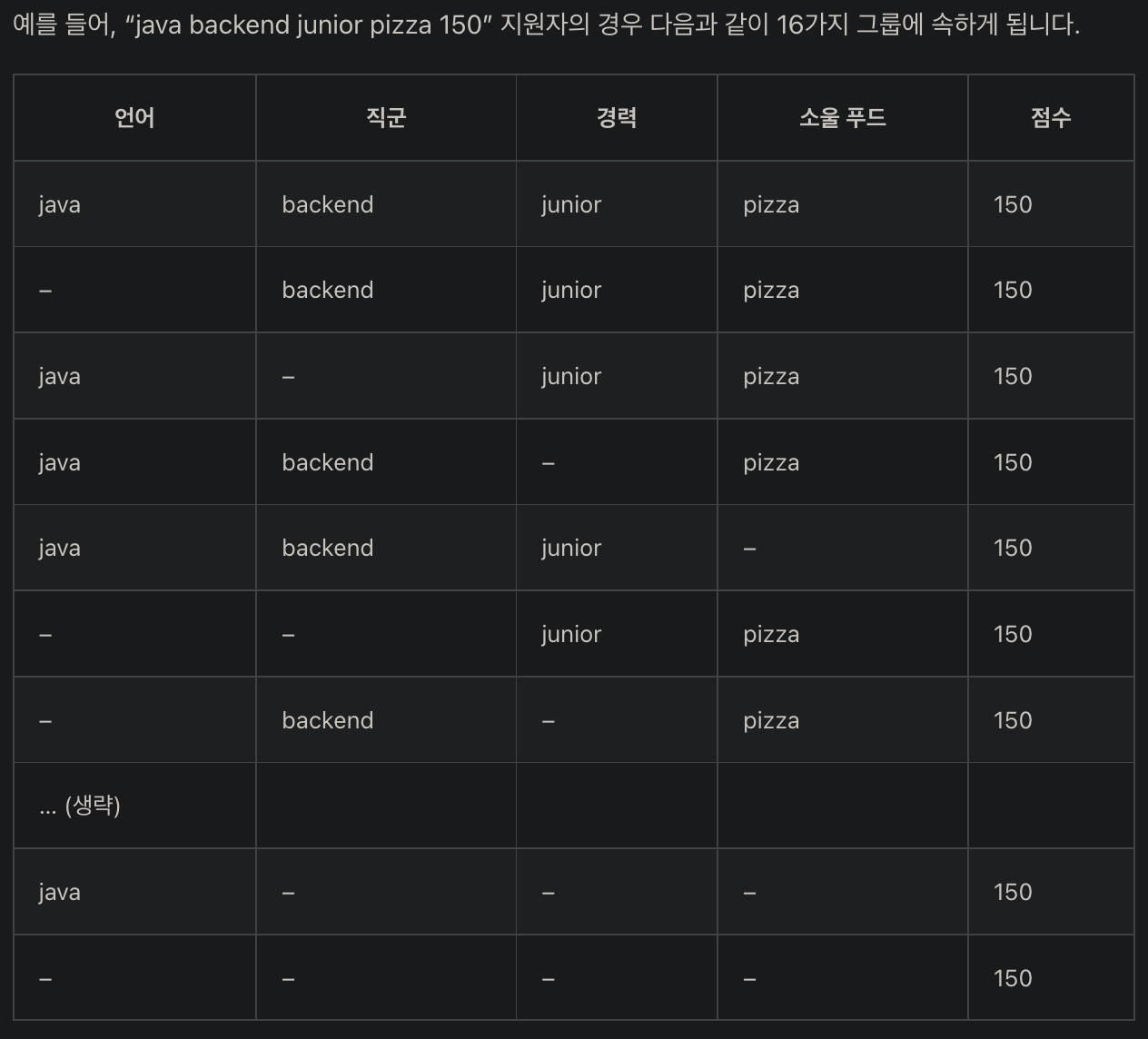
위 사진처럼 한명당 16가지의 경우의 수가 발생한다.
지원자 중에 자격조건(key)가 겹치면
value에 지원자 번호를 append 해준다
2. 이분탐색을 이용해, 점수 기준에 못미치는 인원수를 파악한다.
🔍 풀이
from itertools import combinations
from collections import defaultdict
from bisect import bisect_left
def solution(information, queries):
answer = []
# Hasing
dic = defaultdict(list)
for info in information:
info = info.split()
condition = info[:-1]
score = int(info[-1])
for i in range(5):
case = list(combinations([0,1,2,3], i))
for c in case:
tmp = condition[:]
for idx in c:
tmp[idx] = "-"
key = ''.join(tmp)
print(key)
dic[key].append(score)
# 이분탐색
for value in dic.values():
value.sort()
for query in queries:
query = query.replace('and ', '').split()
target_key = ''.join(query[:-1])
target_score = int(query[-1])
count = 0
if target_key in dic:
target_list = dic[target_key]
idx = bisect_left(target_list, target_score)
count = len(target_list) - idx
answer.append(count)
return answer참고한 블로그 분은
딕셔너리를 사용할때 collcetions 라이브러리의 defaultdict를 사용했다.
defaultdict는 아직 할당되지 않은 key값을 호출하면 value로 0을 뱉는 딕셔너리이다.

쥐구멍에 볕드는 날