> 문제
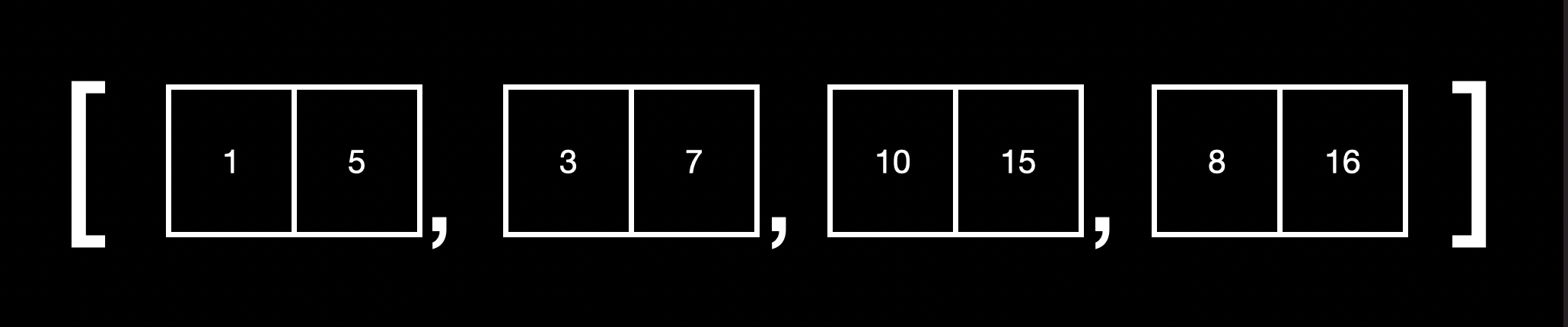
위와 같이 시작점과 끝점이 있는 인터벌들이 들어있는 배열이 있습니다.
1~5까지의 인터벌이 있고 3~7까지의 인터벌이 있다면 1~5에 3이 포함되므로 둘은 [1, 7]로 merge가 됩니다.
1~7은 10~15를 포함하지 않으므로 둘은 merge되지 않습니다.
10~15과 8~16의 경우 10~15에 8이 포함되므로 merge됩니다.
이러한 방식을 반복하며 [[1, 7], [8, 16]]을 최종 리턴하면 됩니다.
> solution1
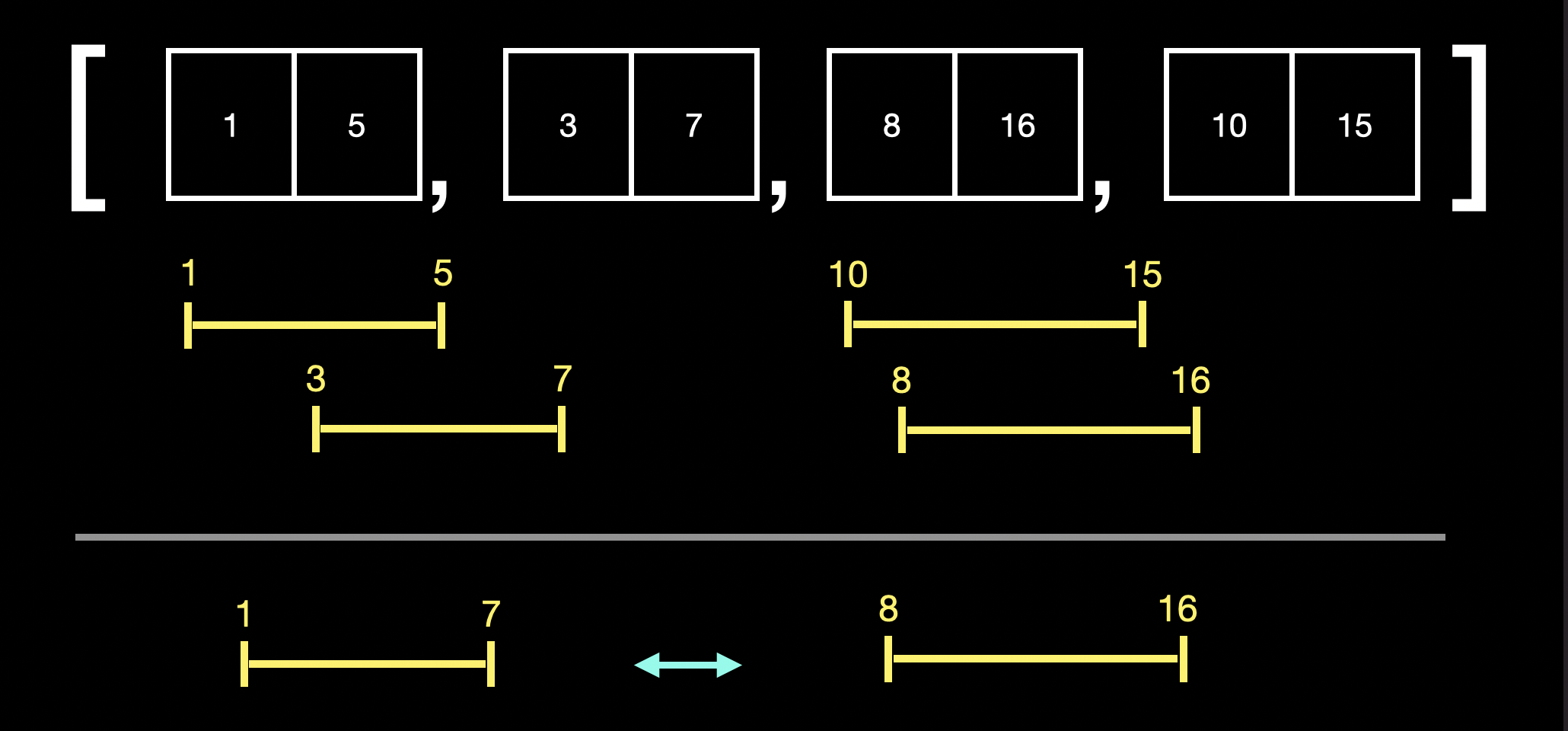
우선 merge를 할 때마다 이전에 merge된 배열과 비교를 반복하는 경우 O(n²)가 되게 됩니다.
더 좋은 방법을 찾아야 합니다.
> solution2

배열 요소들의 index 0을 기준으로 sorting해줍니다.
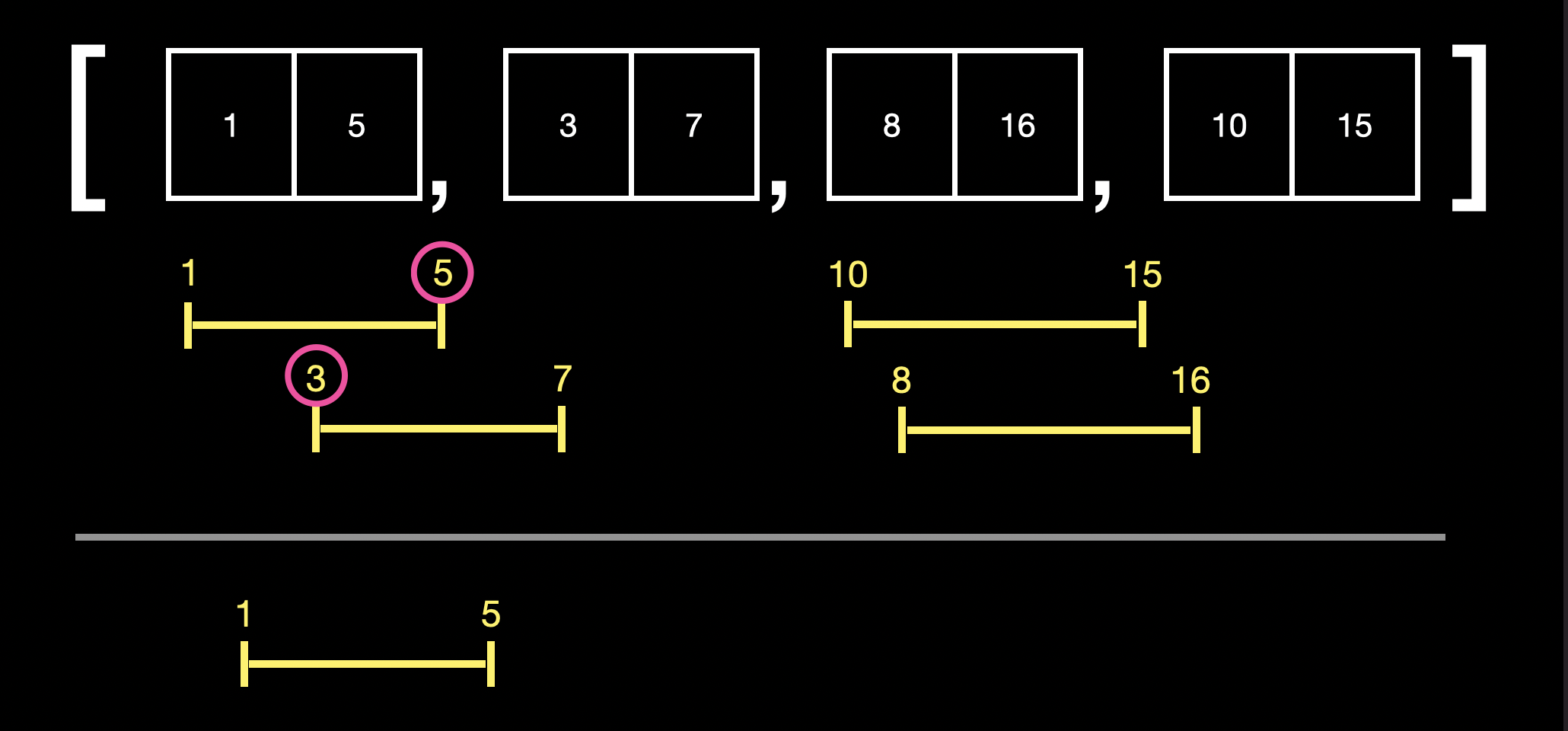
대조하는 요소들 중 n번째 요소의 index 1이 n+1번째 요소의 index0보다 크다는 것은 n번째 요소에 n+1번째 요소가 포함된다는 의미이므로 merge 대상임을 알 수 있습니다.
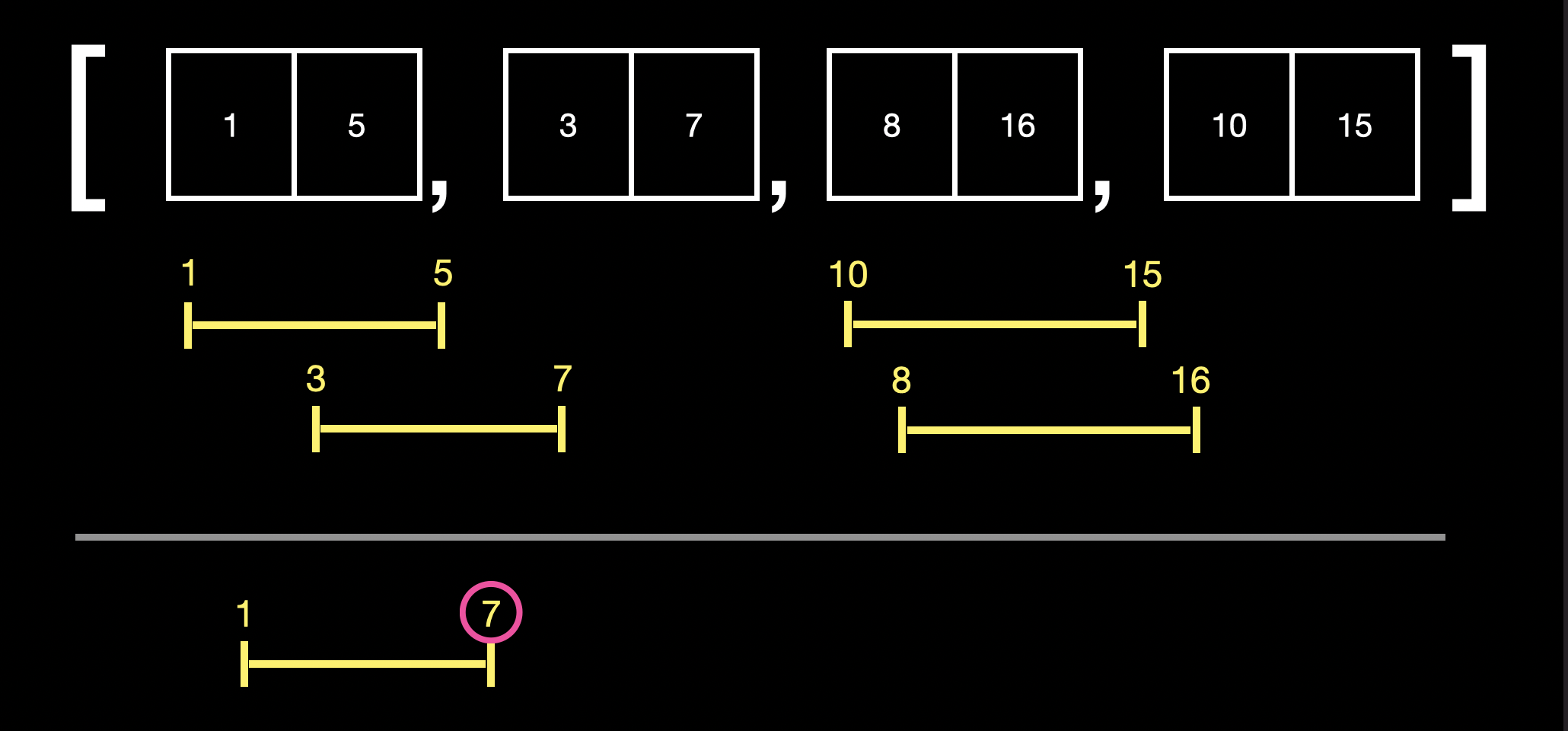
두 대상 중 index 1이 더 큰 쪽의 값을 index 1로 넣으면 merge가 완료됩니다.
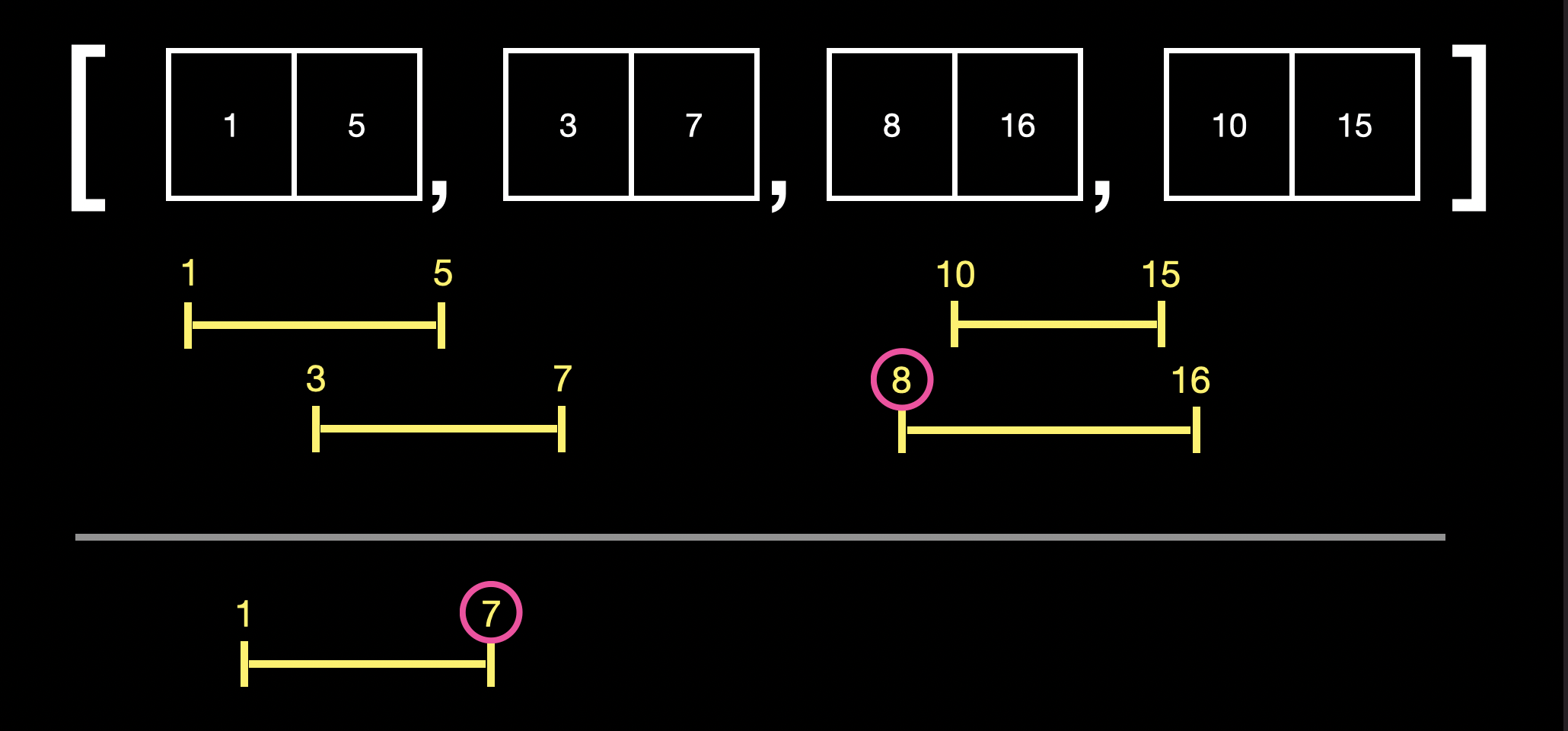
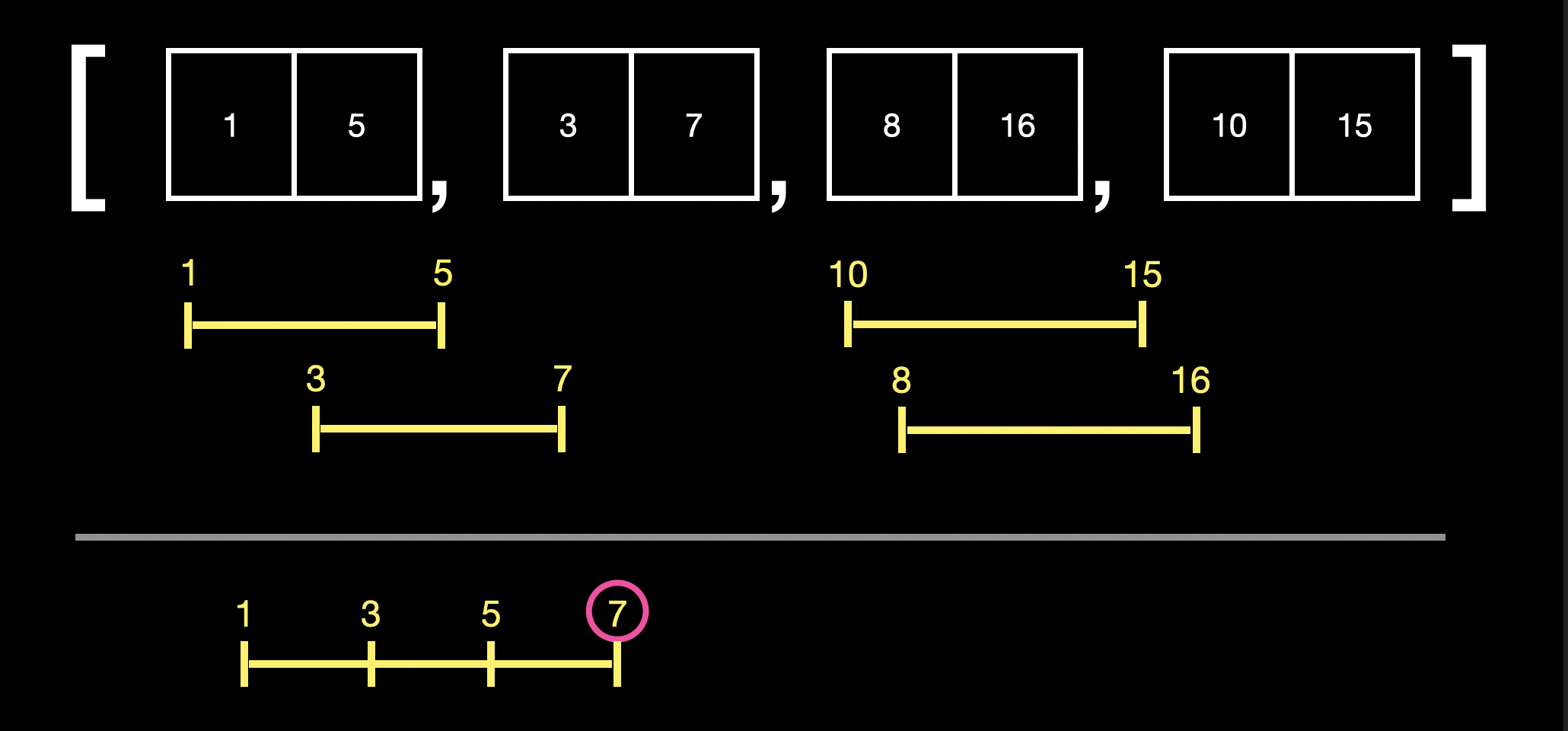
이후 1~7과 8~16을 비교했을 때 1~7에 8이 포함되지 않기 때문에 merge가 되지 않는다는 것을 알 수 있습니다.
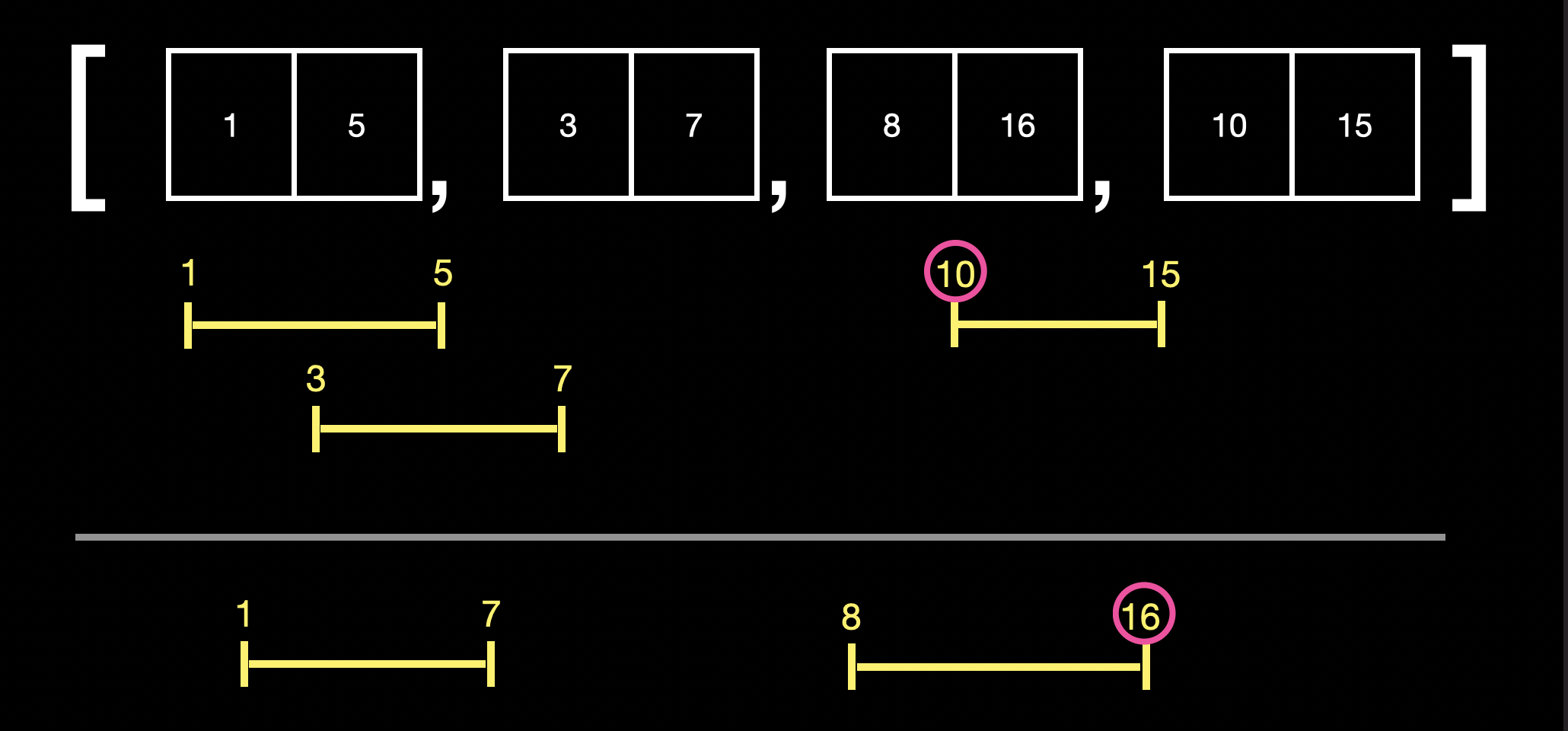
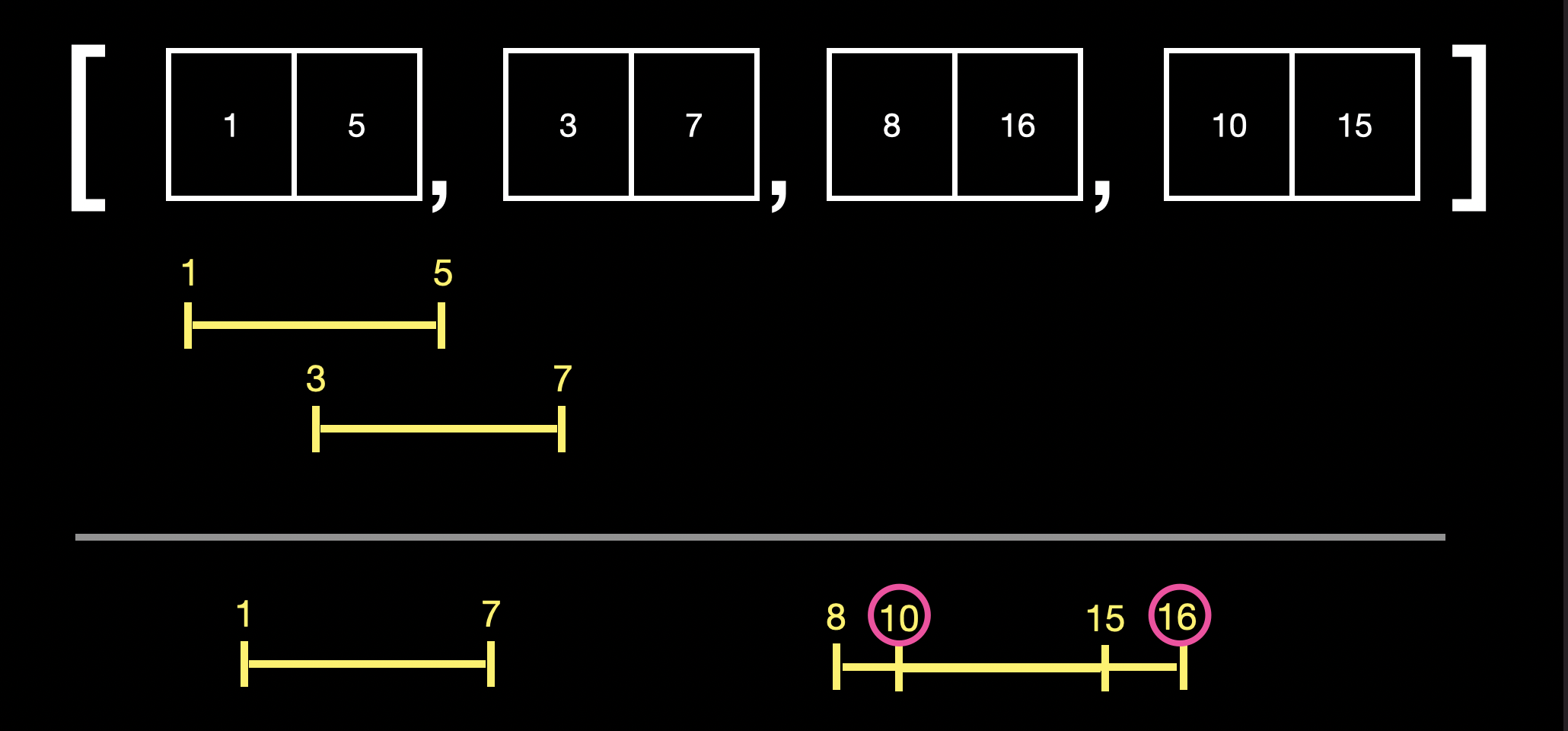
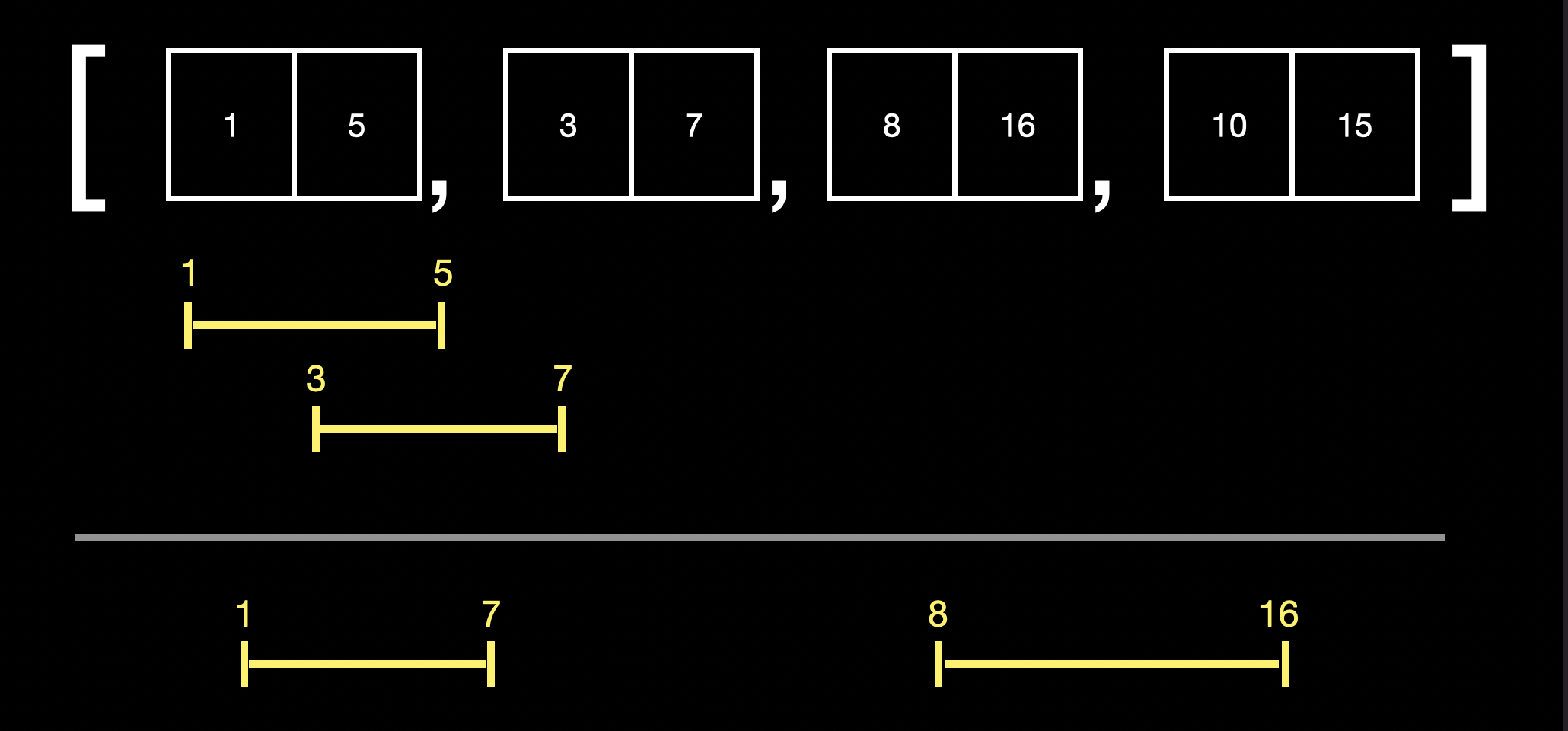
다시 n번째 요소의 index 1과 n+1번째 요소의 index 0을 비교하여 포함 관계이므로 merge를 합니다.
처음에 sorting을 통해 정렬을 해 놓으므로 이미 이전에 merge된 요소와 merge 대상이 아님을 알기 때문에 다시 비교할 필요 없이 operation이 종료됩니다.
시간복잡도는 sorting O(n log n) + merge O(n)이 됩니다.
▶︎ code
# 규칙: 2차원 배열 중 n번째 배열 안에 n+1번째 배열의 값이 포함되면 merge, 아니면 저장
arr = [[8, 16], [1, 5], [10, 15], [3, 7]]
def merge_intervals(values):
values.sort(key=lambda x:x[0]) # 0번째 index 기준 오름차순 정렬
last_idx_0 = values[0][0]
last_idx_1 = values[0][1]
merged = []
for idx_0, idx_1 in values[1:]:
if last_idx_1 >= idx_0: # n번째 배열값에 n+1번째 배열의 0번째 값이 포함되는 경우 merge
last_idx_1 = max(idx_1, last_idx_1) # index 1 중 가장 큰 값을 저장
else:
result = [last_idx_0, last_idx_1] # n번째 배열값에 n+1번째 배열의 0번째 값이 포함되지 않는 경우 not merge
merged.append(result) # 더이상 merge 대상이 아니므로 값 그대로 저장
last_idx_0 = idx_0 # n+1번째 배열의 값들이 새로운 기준이 됨
last_idx_1 = idx_1
result = [last_idx_0, last_idx_1] # 최종 값은 비교 대상이 없으므로 저장 후 operation 종료
merged.append(result)
return merged
print(merge_intervals(arr))▶︎ 번외
values.sort(key=lambda x:x[0]) 따라해보기
def sort_2d_arr(values):
pointer = 0
idx = 1
while pointer < len(values):
while idx < len(values):
if values[pointer][0] > values[idx][0]:
values[pointer], values[idx] = values[idx], values[pointer]
idx += 1
pointer += 1
idx = pointer + 1
print('values::', values)출처: 코드없는 프로그래밍
