[Spring Boot] spring data JPA
ORM이란?
Object Relational Mapping의 약자로, 객체와 relational(테이블)을 mapping 할 때 발생하는 개념적인 불일치를 해결하는 프레임워크이다.
객체는 크기가 다양한 여러 프로퍼티를 가지고있지만, 테이블은 한정되어 있기 때문에, 어떻게 객체를 테이블에 매핑할 수 있을까라는 고민에 대한 해결책이다.
JPA란?
여러가지 ORM 해결책들이 있는데, 거기에 대한 자바 표준을 정한 것이다.
대부분의 자바 표준은 하이버네이트 기반으로 만들어져 있다.(그러나 하이버네이트의 모든 기능을 jpa가 커버하지는 못한다.)
스프링 데이터 JPA는, JPA 표준 스펙을 아주 쉽게 사용할 수 있게 스프링데이터로 추상화 시켜놓은 것이다.
구현체로 하이버네이트를 사용해서, jpa, orm을 아주 쉽게 사용할 수 있다.(하이버네이트 밑단에는 jdbc가 있다. 즉, Spring Data JPA -> JPA -> Hibernate -> Datasource 이다.)
예제
pom.xml에 jpa 의존성을 추가해준다.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>의존성을 추가해주면, 모든 자동설정이 설정된 상태이다.
account라는 패키지를 만들어 Account 클래스를 만들어 @Entity 어노테이션을 붙여준다.
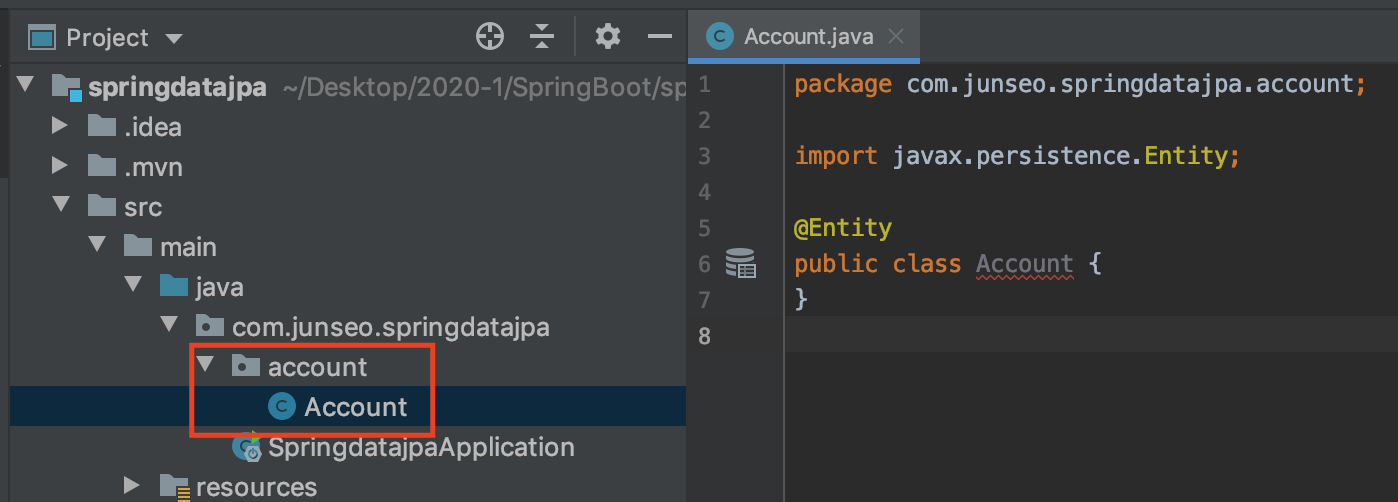
Id 값과, username, password를 만들어준다.(getter setter와 equals, hashCode도 만들어준다.)
@GeneratedValue 어노테이션은 repository를 통해 저장할 때, 자동으로 값을 주겠다는 뜻이다.
@Entity
public class Account {
@Id @GeneratedValue
private Long id;
private String username;
private String password;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Account account = (Account) o;
return Objects.equals(id, account.id) &&
Objects.equals(username, account.username) &&
Objects.equals(password, account.password);
}
@Override
public int hashCode() {
return Objects.hash(id, username, password);
}
}그다음에 Repository interface를 만들어준다.
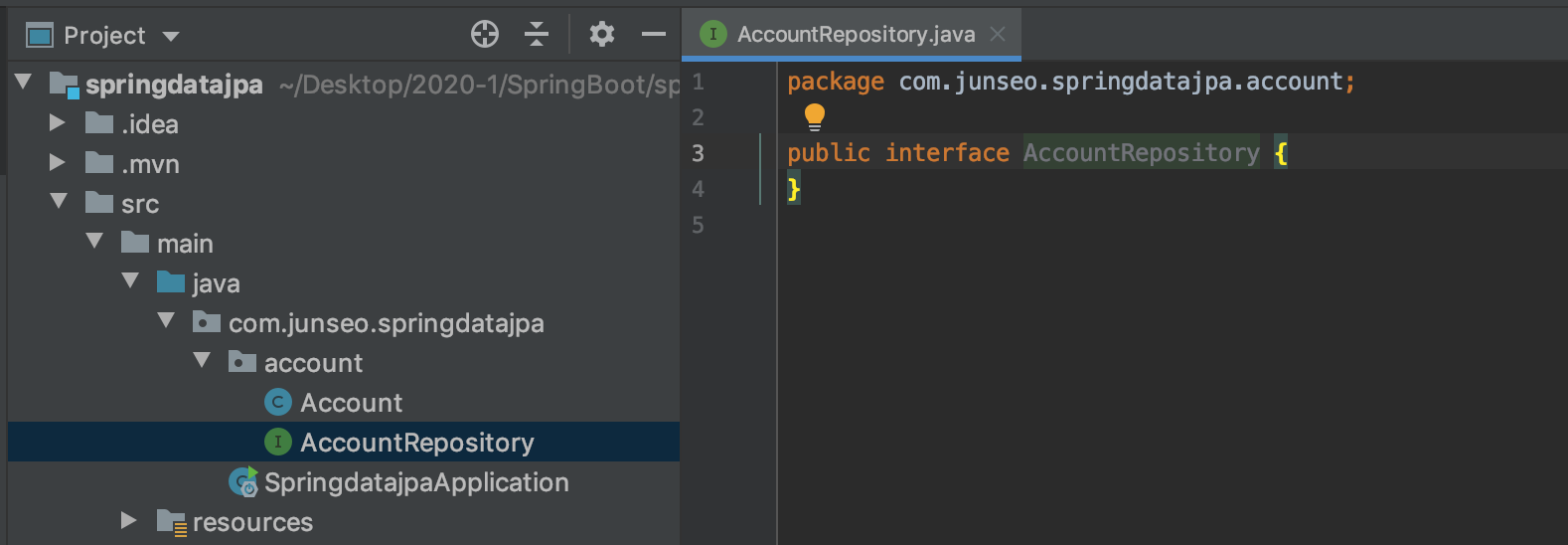
JpaRepository를 extends한다.
JpaRepository<'entity 타입', 'id 타입'>
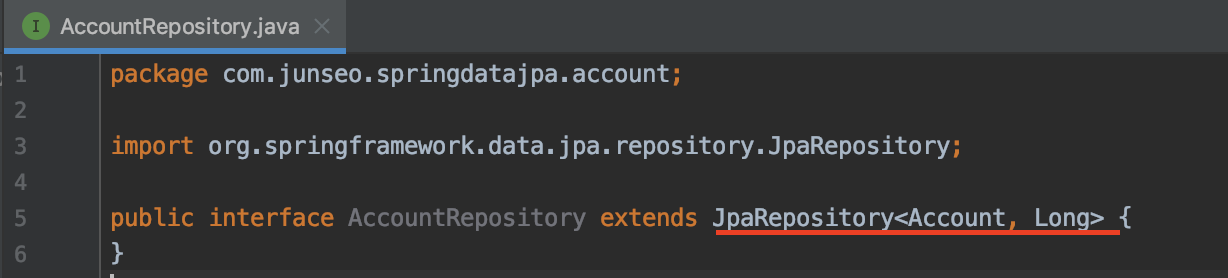
이러면 repository 생성이 끝난 것이다.
만들어준 repository를 테스트 해보려고 한다.
슬라이스 테스트로 만든다.(repository를 포함해, repository와 관련된 Bean들만 등록해서 테스트하는 것)
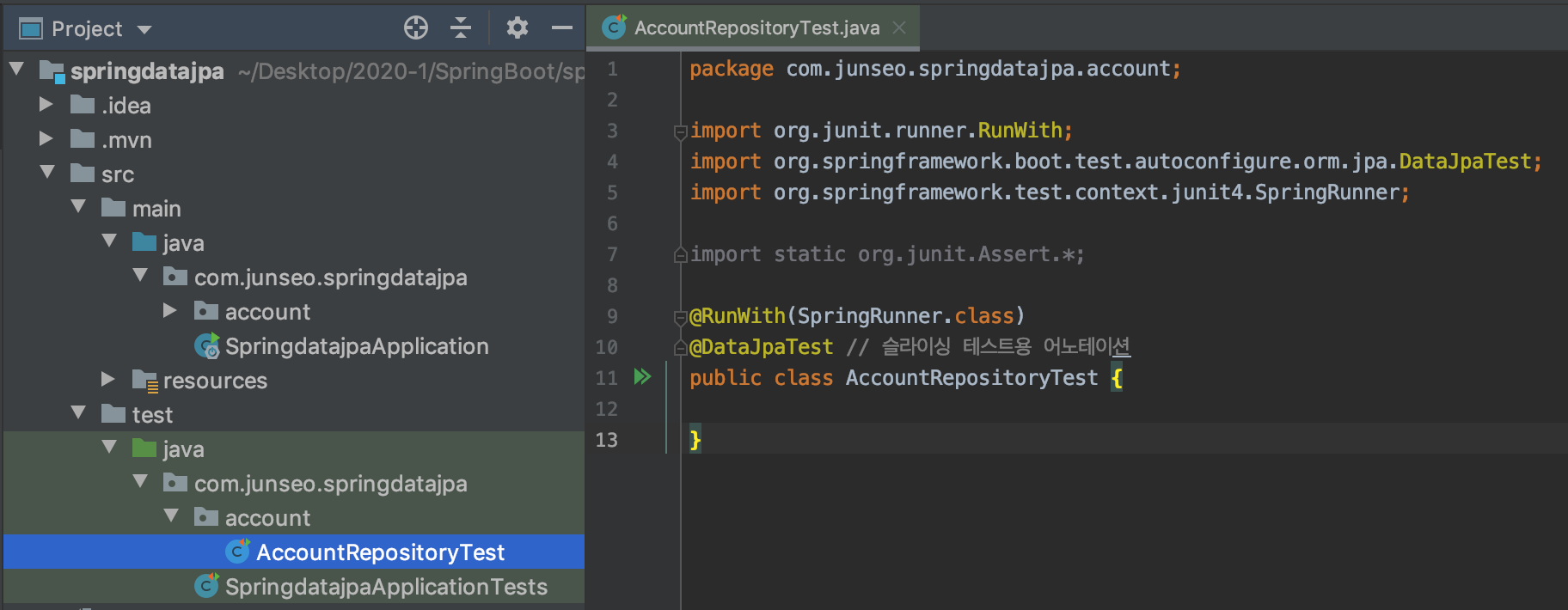
슬라이스 테스트를 하려면 인메모리 데이터베이스가 필요하다.
따라서, h2 의존성을 추가해준다.
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>test</scope>
</dependency>@DataJpaTest 어노테이션에 의해, DataSource, JdbcTemplate, AccountRepository를 주입받을 수 있다.
빈 테스트를 만들어 테스트를 실행해보면 테스트가 잘 돌아감을 볼 수 있다.

테스트와 마찬가지로, 실제 애플리케이션을 실행할때도, DB는 필요하다.
예제에서 DB는 postgresql을 사용하겠다.(참고: https://velog.io/@max9106/Spring-Boot-PostgreSQL)
의존성을 추가해주고, 터미널로 실행해준다. application.properties도 설정해준다.
그 후, 애플리케이션을 실행시키면, 잘 실행됨을 볼 수 있다.
TIP
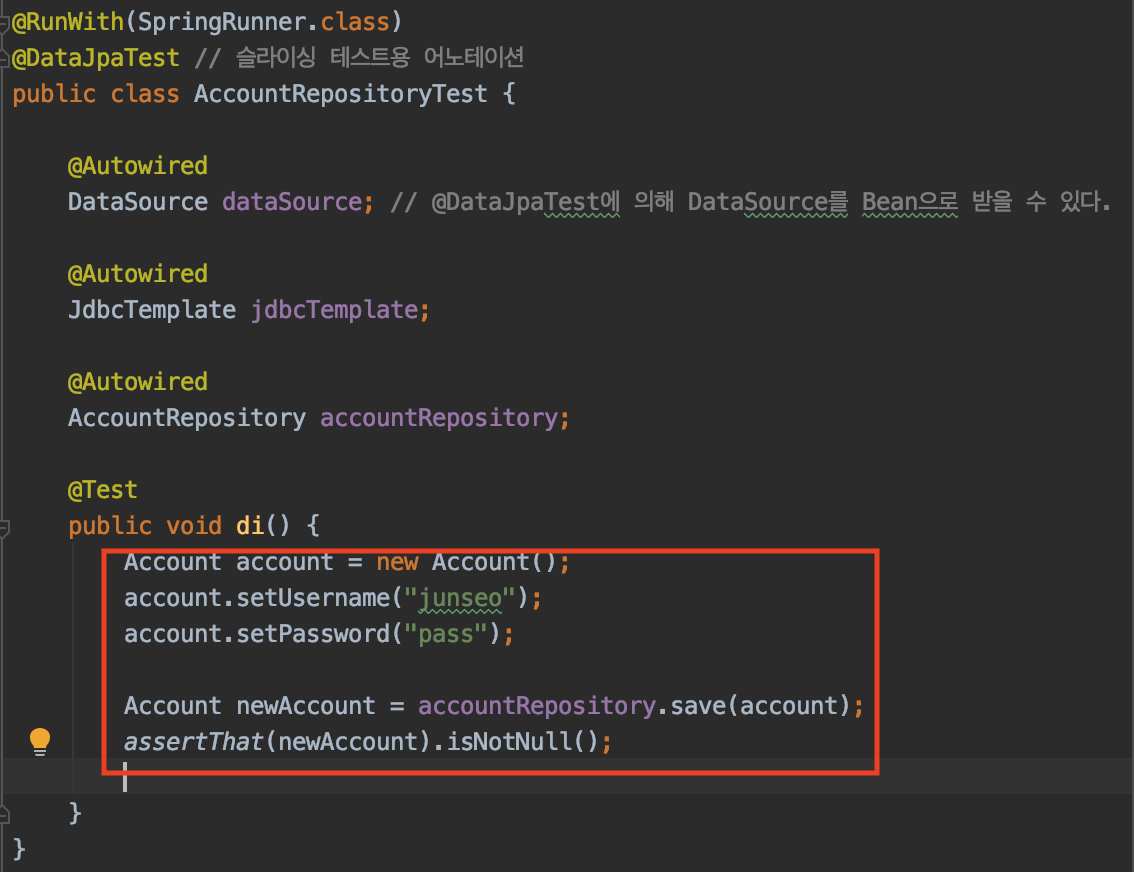
테스트에서, Account를 실제로 만들어 값을 준 후, AccountRepository를 이용해서 저장해볼 수 있다.
특정 프로퍼티로 조회를 해줄 수도 있다. username으로 조회를 해보겠다.
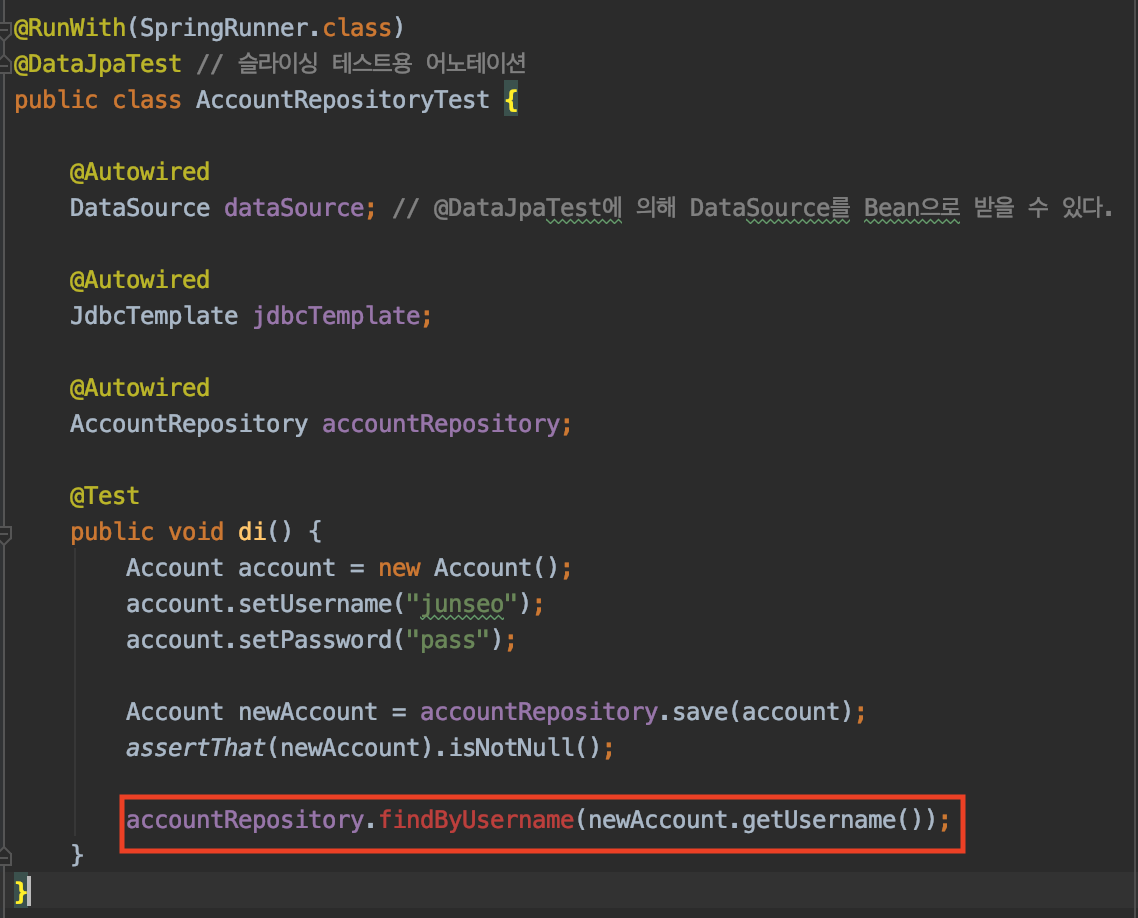
findByUsername이라는 메서드가 없기 때문에 만들어준다.
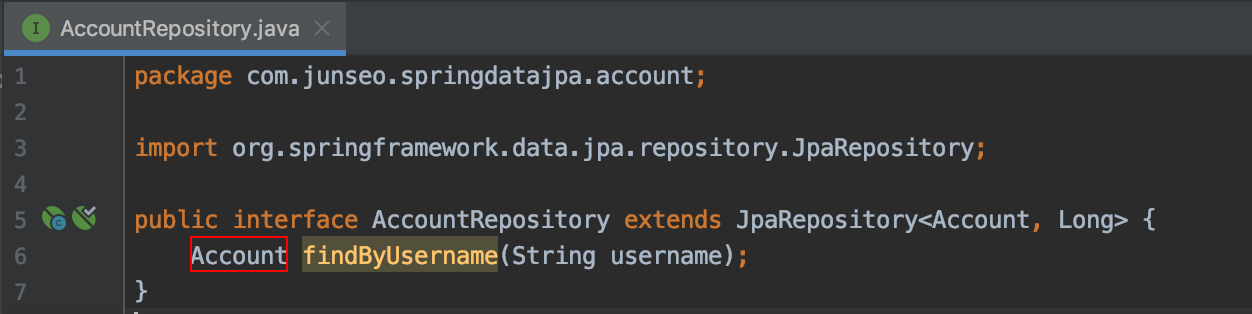
메서드만 추가해주면, 실제 구현체를 만들어 Bean으로 등록해주는 것 까지 spring data jpa가 알아서 해준다.
따라서 아래 테스트를 실행해주면,
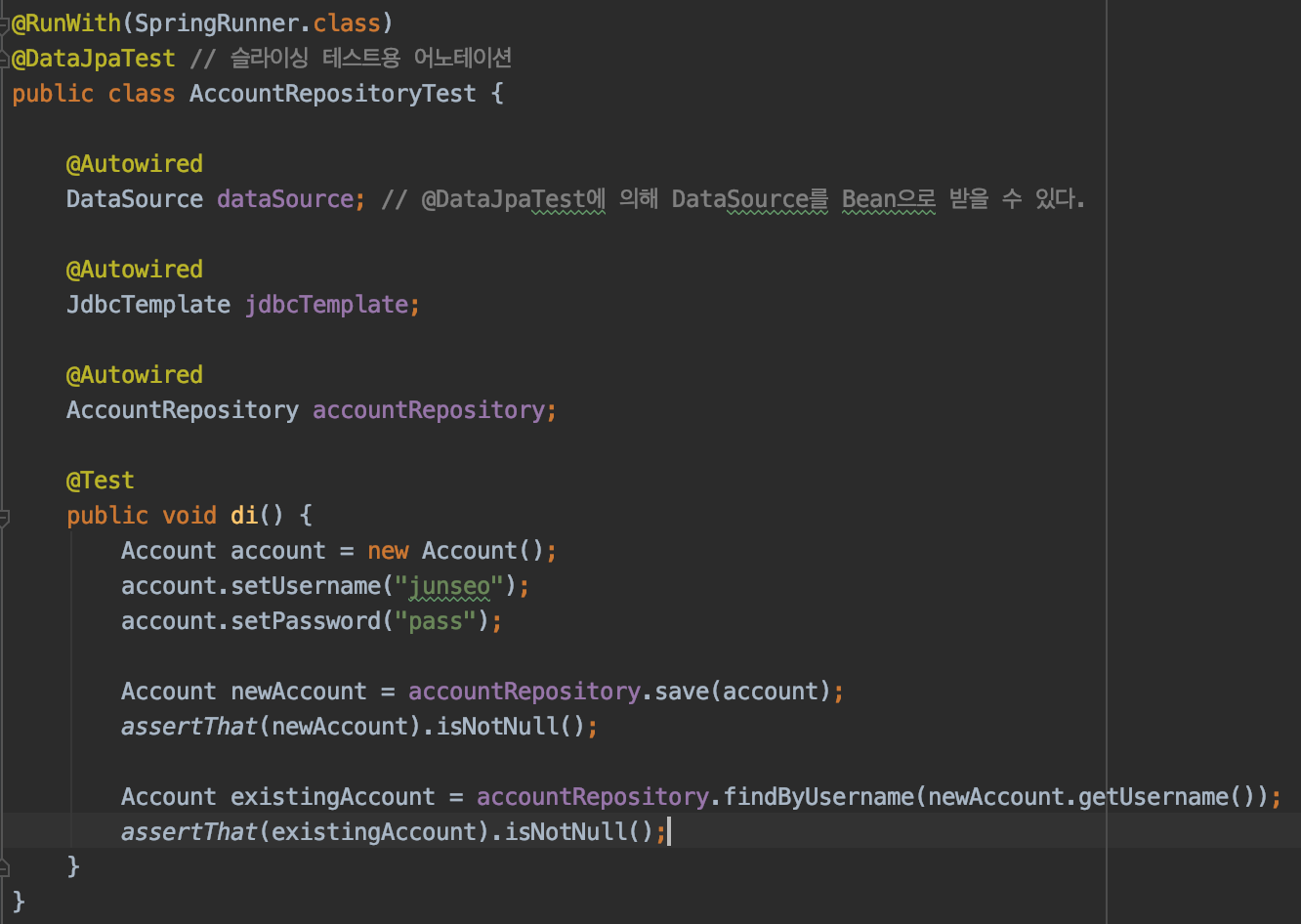
잘 실행됨을 볼 수 있다.

