Kafka 트랜잭션은 왜 필요할까
시스템이 복잡해지면서 여러 이벤트가 함께 처리된다. 이때 이벤트들의 일관성을 보장하기위해 카프카 트랜잭션이 필요하다. 우리가 잘 알고있는 데이터베이스에서의 트랜잭션 처럼 이벤트 모두 함께 처리 혹은 이벤트 모두 처리하지 않는 원자성이 보장되야한다.
트랜잭션이 없는 이벤트 처리
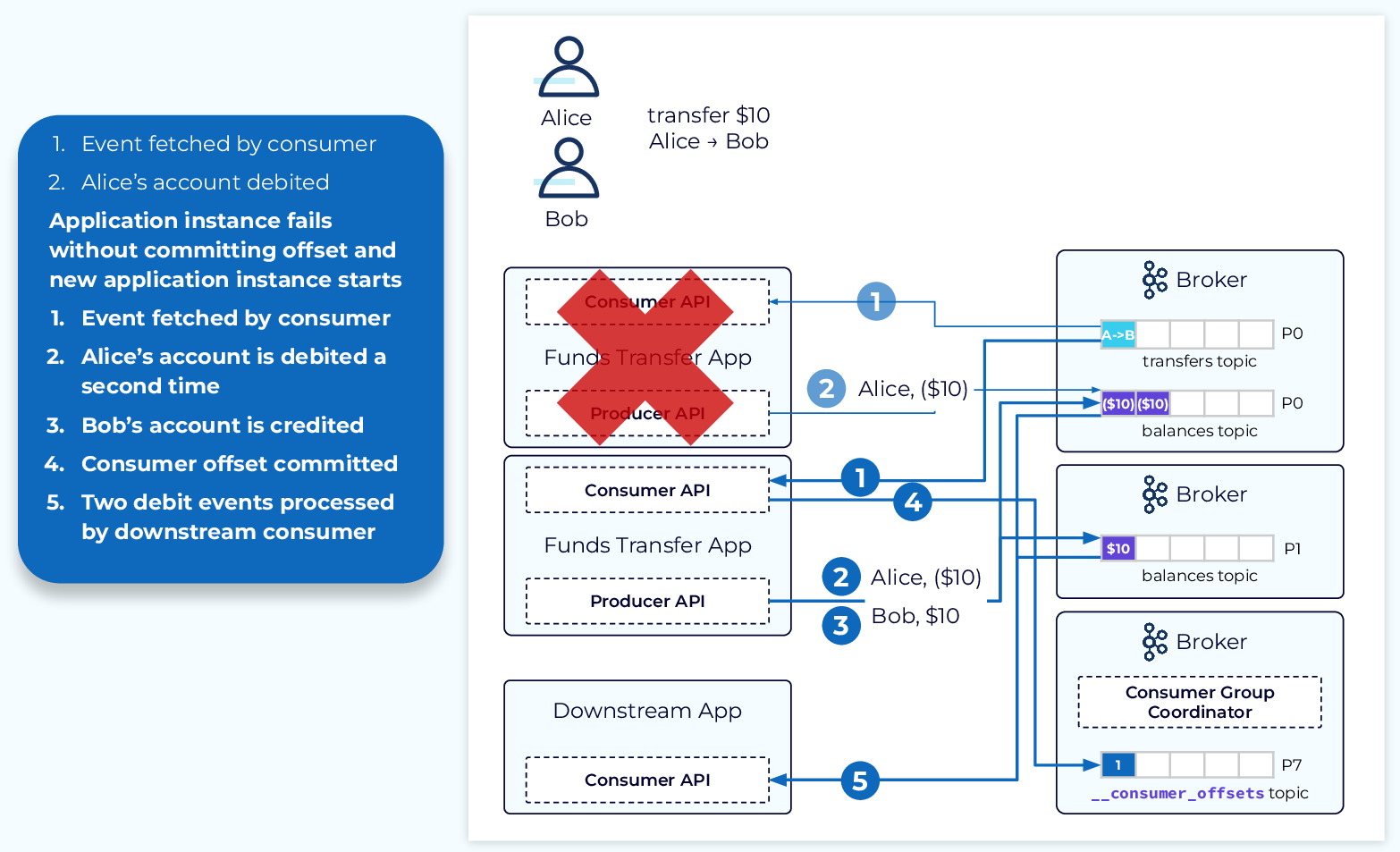
다음 그림은 트랜잭션이 없는 카프카 이벤트 시스템이다. 해당 상황은 앨리스가 밥에게 10달러를 전송하는 상황이다.
1. 앨리스가 밥에게 10달러를 송금하는 이벤트를 컨슈머가 읽는다.
2. Funds Transfer App에서 balances topic으로 앨리스의 10달러를 출금 이벤트를 전송한다.
그런데, 이때 Funds Transfer App에서 장애가 발생했고 컨슈머 그룹은 커밋되지 못했다. 그리고 서버를 새로 시작했다고 하자.
1. 새로 시작은 Funds Transfer App 서버는 다시 엘리스가 밥에게 10달러를 전송한 이벤트를 읽는다.
2. 다시 한 번 balances topic으로 앨리스의 10달러를 출금 이벤트를 전송한다.
3. 밥이 10달러 받은 이벤트를 입금 브로커의 balances topic으로 전송한다.
4. 컨슈머 오프셋이 커밋된다.
5. 컨슈머가 앨리스와 밥의 이벤트를 처리한다.
앨리스는 총 20달러를 송금하게 되었다.
트랜잭션의 부재로 일관성이 지켜지지 못했다.
Kafka 트랜잭션의 동작
트랜잭션 아이디와 트랜잭션 코디네이터
- 트랜잭션 아이디:
transactional.id는 프로듀서에서 설정되며 애플리케이션을 다시 시작할 때 트랜잭션 프로듀서를 식별할 수 있다. - 트랜잭션 코디네이터: 트랜잭션 메타데이터를 추적하고 전체 트랜잭션 프로세스를 감독하는 브로커 프로세스다.
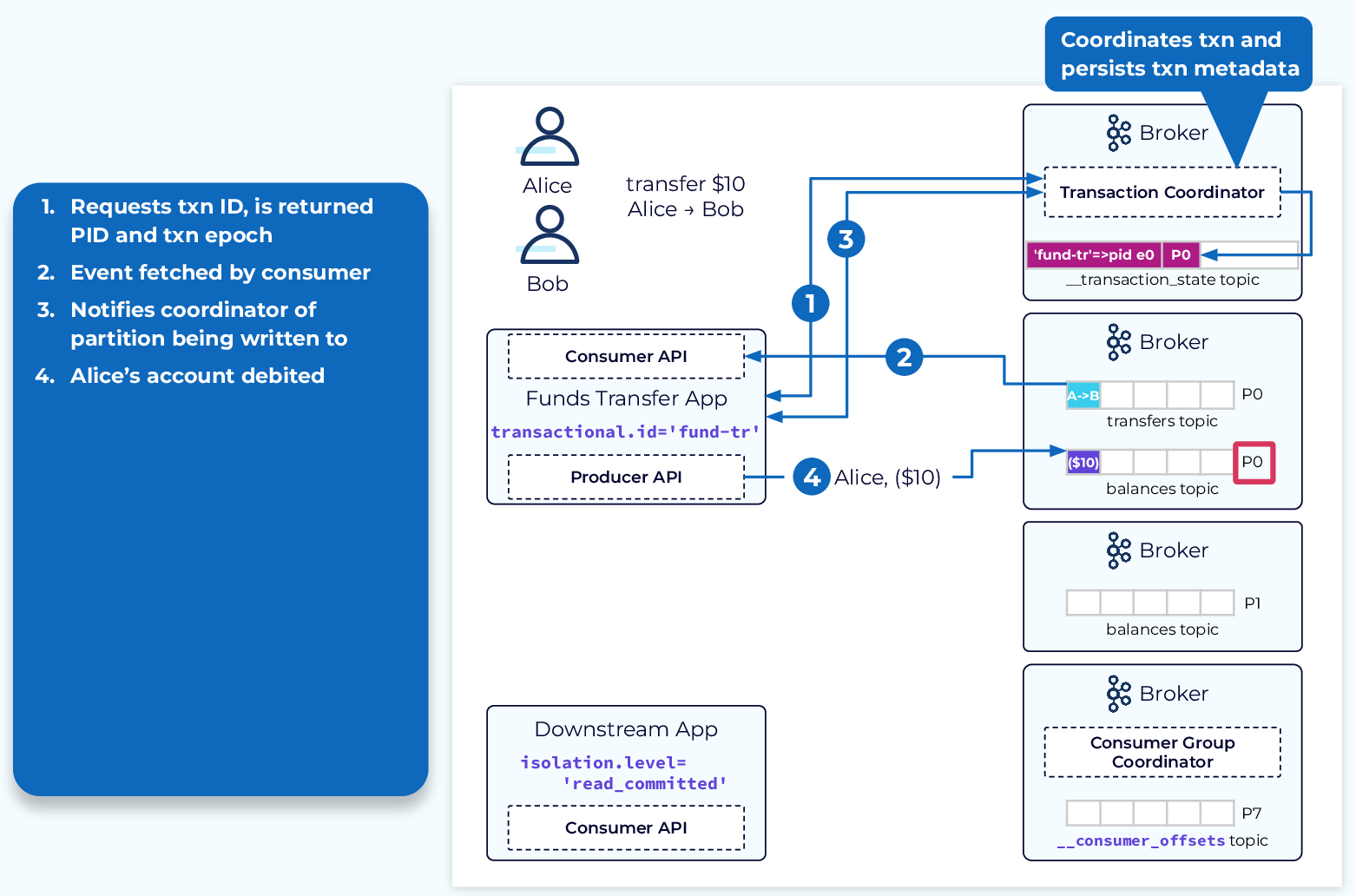
트랜잭션으로 인해 추가되는 4단계를 살펴보자.
- 애플리케이션은 PID 와 Transaction ID를 트랜잭션 코디네이터에게 보낸다. 트랜잭션 코디네이터는
트랜잭션 아이디,PID,에포크를 가지고 __transaction_state 토픽에 기록힌다.
*트랜잭션 에포크는 시간의 정보를 가지고 있는 유일한 값으로 트랜잭션 아이디 함께 카프카 트랜잭션을 구분한다. 트랜잭션을 관리하는 브로커에서 만들어진다. - tranfer 토픽에서 이벤트를 읽고 코디네이터에게 새 트랜잭션이 시작되었음을 알린다.
- 프로듀서는 balances 토픽은 앨리스의 10달러 출금 이벤트 전송 전 기록할
토픽과파티션을 코디네이터에게 알린다. - 앨리스의 10달러 출금 이벤트가 balances 토픽에 전송된다.
서버 장애와 트랜잭션
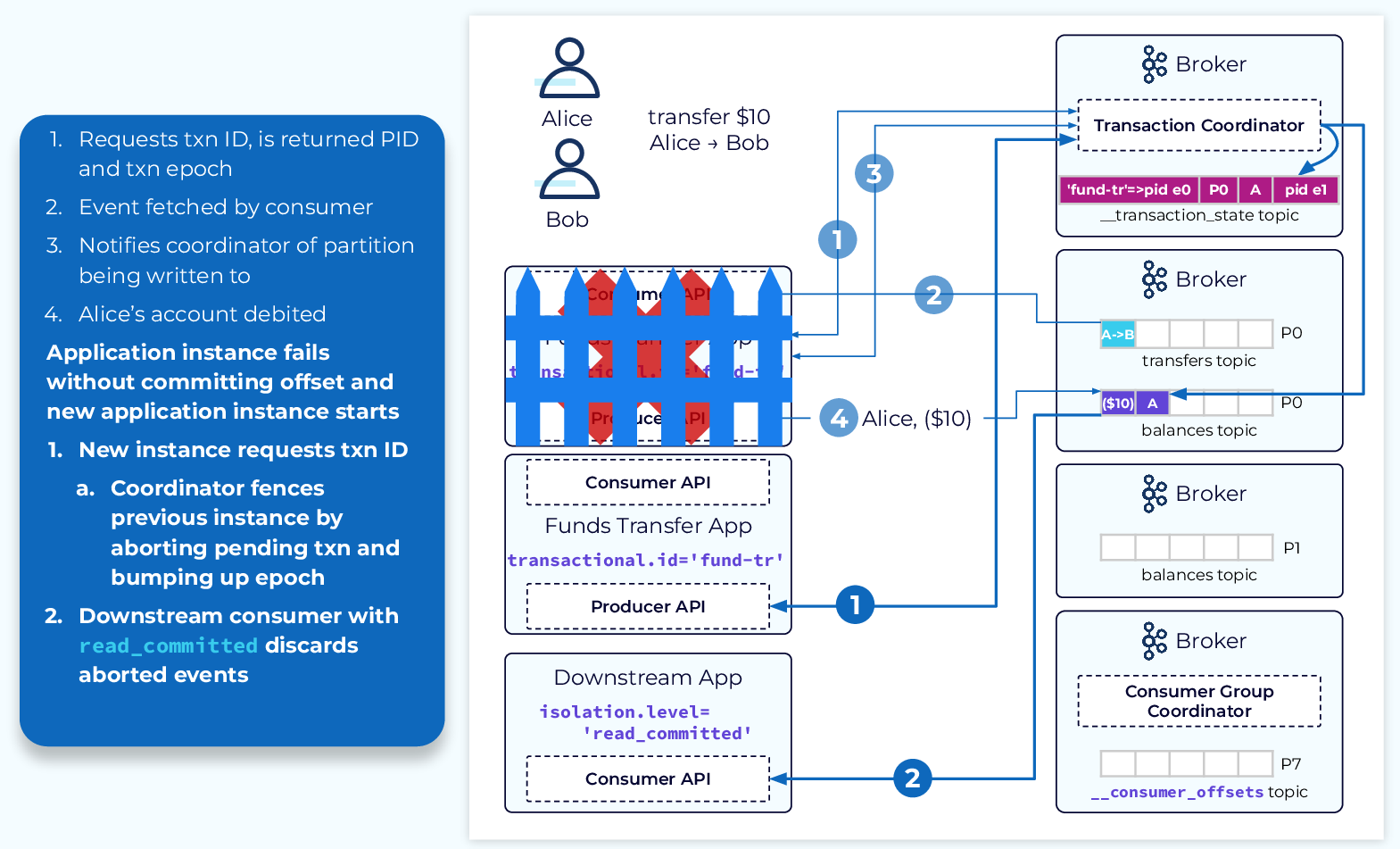
1. 새 인스턴스는 코디네이터로 PID에 대한 초기화 요청을 전송한다. 코디네이터는 보류 중인 트랜잭션이 있는 것을 확인하고 이전 트랜잭션의 영향을 받는 모든 파티션에 중단 마커를 추가한다. 또한 에포크도 생성힌다. 새 인스턴스는 PID와 새 에포크를 수신하고 정상적인 처리를 계속한다.
2. 컨슈머의 isolation.level을 read_committed로 설정하여 문제가 생긴 이벤트를 무시한다.
정상 처리와 트랜잭션
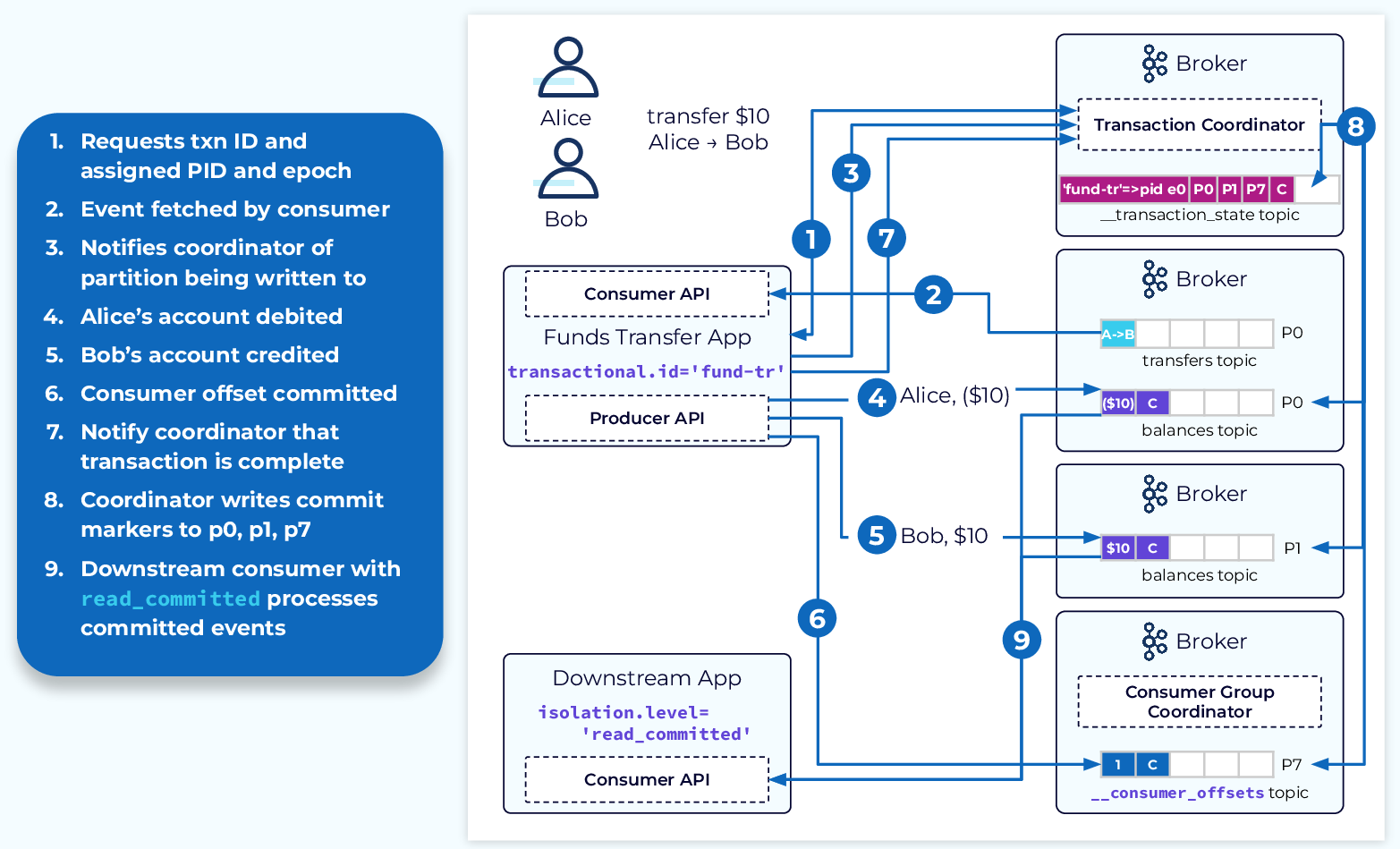
각 단계를 정상적으로 수행하면 트랜잭션 코디네이터 내부 _transaction_state 토픽과 _consumer_offsets 토픽에 커밋 마커를 추기한다. 소비자는 이 마커를 보고 이벤트를 처리한다.
스프링에서 Kafka 트랜잭션 처리는?
시나리오를 크게 두 가지로 나눌 수 있겠다.
- @Transactional 안에서 함께 처리
- 스프링 이벤트를 활용한 처리
@Transactional 안에서 함께 처리
이렇게 사용하기 위해서는 카프카 프로듀서에서 transaction-id-prefix를 설정하고 카프카 컨슈머에서 isolation.level을 read_committed로 변경해야한다.
@Transactional
public void process(List<Thing> things) {
things.forEach(thing -> this.kafkaTemplate.send("topic", thing));
updateDb(things);
}- @Transactional을 사용하게 되면 DataSourceTransactionManager, 예를 들면 jpa transaction manager,를 먼저 실행하고 이후 동기적으로 카프카 트랜잭션을 실행한다.
- 각각의 send 메시지는 하나의 트랜잭션 안에서 처리된다.
- DataSourceTransactionManager를 먼저 커밋하고 그 다음 카프카 트랜잭션을 커밋한다.(카프카 트랜잭션을 먼저 커밋하고 싶다면 참고)
- DataSourceTransactionManager가 먼저 커밋 되므로 카프카 메시지 샌딩 중 예외가 발생했다고 해도 디비의 커밋은 롤백이 안되므로 주의가 필요하다.(커밋 순서 변경하여 해결하고 싶다면 위에 참고)
- 디비 예외가 일어나면 디비는 롤백되고 당연히 카프카 메시지는 전송이 되지 않는다. 카프카 메시지 샌딩 중 예외가 발생하면 디비는 롤백이 되지 않고 카프카 메시지는 발송은 되지만 파티션에 에러가 발생했다는 마크가 붙는다. 컨슈머는 read_committed 모드이므로 이 메시지를 처리하지 않는다.
- 주 트랜잭션이 커밋이 되고 동기화된 트랜잭션 즉 카프카 트랜잭션이 실패할 경우 예외를 던지는데 이 예외를 적절하게 처리하면 되겠다.
스프링 이벤트를 활용한 처리
스프링 이벤트 기반으로 처리해 보겠다.
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)를 사용하여 커밋 후 카프카 메시지를 샌딩하는 방법- data source transaction과 kafka transaction을 분리할 수 있다.
- 이곳도 마찬가지로 이벤트를 실행한 곳은 커밋 되었으므로, 카프카 관련 이벤트에 예외가 발생한다해도 디비는 롤백되지 않고 카프카 메시지는 발송되지만 파티션에 에러가 발생했다는 마크가 붙는다.
