통계
데이터를 추출하다보면 통계를 내야할때가 있습니다. 하지만 1주차에서 배웠던 방법으로 통계를 내기에는 한계가 있는데요.
max(최대),min(최소),avg(평균),count(개수), Group by(동일한 데이터의 범주를 묶음), Order by(정렬)
Group by를 사용하는 이유
Group by는 동일한 데이터의 범주를 묶는 역할을 합니다.
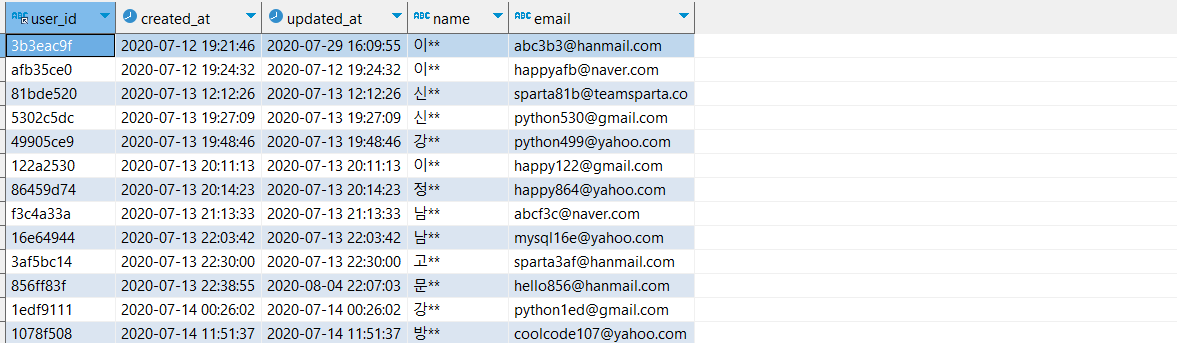
users 테이블에는 위와 같은 정보가 있습니다. name 필드에는 같은 성을 가진 데이터가 여러개 있는데 성씨별로 몇개의 데이터가 있는지 궁금할 때 Group by를 사용하면 편리합니다.
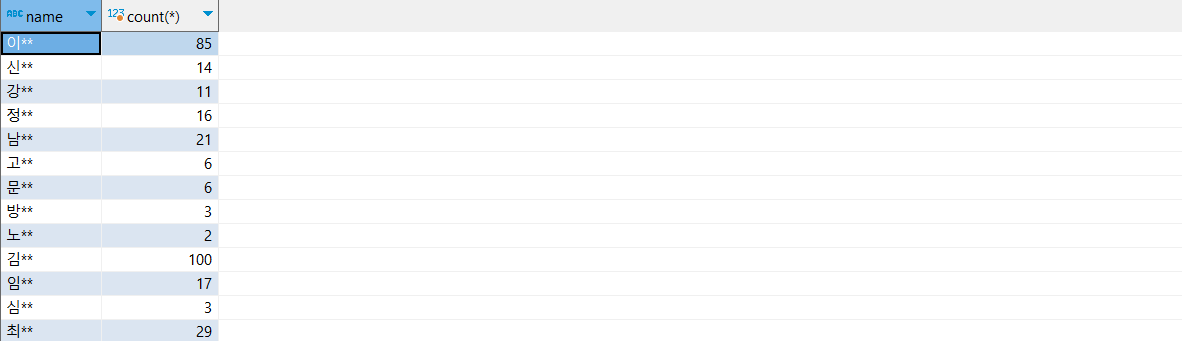
select name, count(*) from users group by name
group by절 뒤에는 필드가 들어가야하며 select절에서 group by에 들어가는 필드명이 들어가야합니다.
Order by를 사용하는 이유
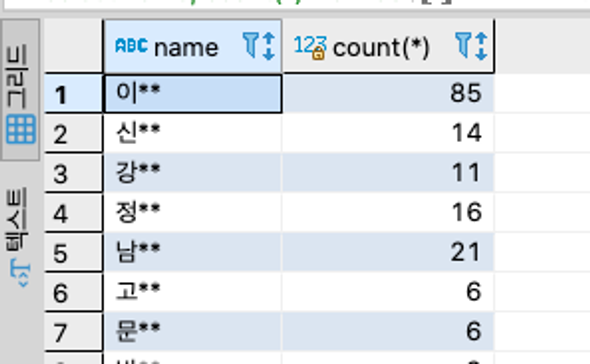
위와 같이 count(*) 필드에서 값이 큰 데이터 순으로 정렬을 하고 싶을 때
Order by절을 사용합니다.
큰 값 -> 작은 값 : desc(내림차순)
select name, count() from users group by name order by count() desc
작은 값 -> 큰 값 : asc(오름차순)
select name, count() from users group by name order by count() asc
여기서 오름차순은 asc를 꼭 넣지않고 생략해도 오름차순으로 정렬해줍니다.
쿼리가 실행되는 순서
쿼리가 실행되는 순서로는 from → group by → select 인데요.
예를 들어 쉽게 설명하자면
select name, count(*) from users group by name
from절에서 테이블 전체에 데이터를 가져온 후 group by절에서 users테이블에 있는 name필드에서 같은 데이터끼리 합쳐주고 select절에서 합쳐진 데이터와 합쳐진 데이터의 개수를 보여줍니다.
