QuickSort
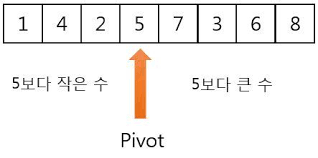
퀵정렬이란 하나의 리스트에서 기준인 피벗(Pivot)을 정해서 피벗보다 작은 값과 큰 값을 나누어 재귀함수 호출 방식을 통해 결과를 합치면 정렬된 리스트를 얻을 수 있다.
QuickSort 구현 함수
def quicksort(lst, start, end):
def partition(part, ps, pe):
pivot = part[pe]
i = ps - 1
for j in range(ps, pe):
if part[j] <= pivot:
i += 1
part[i], part[j] = part[j], part[i]
part[i + 1], part[pe] = part[pe], part[i + 1]
return i + 1
if start >= end:
return None
p = partition(lst, start, end)
quicksort(lst, start, p - 1)
quicksort(lst, p + 1, end)
return lstMergeSort
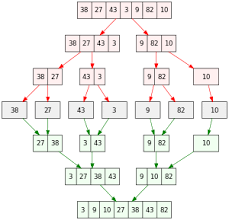
MergeSort란 길이가 균등하게 분할된 리스트 2개를 합하여 하나의 정렬된 리스트로 만드는 알고리즘
MergeSort 구현 코드
def merge(arr1, arr2):
result = []
i = j = 0
while i < len(arr1) and j < len(arr2):
if arr1[i] < arr2[j]:
result.append(arr1[i])
i += 1
else:
result.append(arr2[j])
j += 1
while i < len(arr1):
result.append(arr1[i])
i += 1
while j < len(arr2):
result.append(arr2[j])
j += 1
return resultHeapSort
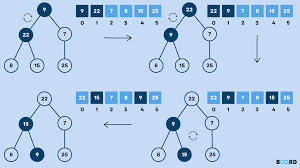
힙은 최댓값과 최솟값을 구하는 이진트리이다. 내림차순 정렬을 하면 최대 힙이 구현되며 오름차순 정렬을 하면 최소 힙이 구현된다.
HeapSort 구현 코드
class BinaryMinHeap:
def __init__(self):
# 계산 편의를 위해 0이 아닌 1번째 인덱스부터 사용한다.
self.items = [None]
def __len__(self):
# len() 연산을 가능하게 하는 매직 메서드 덮어쓰기(Override).
return len(self.items) - 1
def _percolate_up(self):
# percolate: 스며들다.
cur = len(self)
# left 라면 2*cur, right 라면 2*cur + 1 이므로 parent 는 항상 cur // 2
parent = cur // 2
while parent > 0:
if self.items[cur] < self.items[parent]:
self.items[cur], self.items[parent] = self.items[parent], self.items[cur]
cur = parent
parent = cur // 2
def _percolate_down(self, cur):
smallest = cur
left = 2 * cur
right = 2 * cur + 1
if left <= len(self) and self.items[left] < self.items[smallest]:
smallest = left
if right <= len(self) and self.items[right] < self.items[smallest]:
smallest = right
if smallest != cur:
self.items[cur], self.items[smallest] = self.items[smallest], self.items[cur]
self._percolate_down(smallest)
def insert(self, k):
self.items.append(k)
self._percolate_up()
def extract(self):
if len(self) < 1:
return None
root = self.items[1]
self.items[1] = self.items[-1]
self.items.pop()
self._percolate_down(1)
return rootsort()에서 lambda 사용
알고리즘 문제를 풀면서 sort()에서 lambda를 이용해 정렬 할 수 있다는 것을 알게되었다.
예시
data_list = ['but','i','wont','hesitate','no','more','no','more','it','cannot','wait','im','yours']
data_list = list(set(data_list)) #set은 리스트에 중복되어있는 값을 제거
data_list.sort()
data_list.sort(key=lambda x : len(x)) #list에 있는 값을 길이 순으로 정렬
print(data_list)예시
data_list = [[1,2],[1,3],[2,4],[3,6]]
data_list.sort(key=lambda x : x[0]) # 2차원 배열 인덱스의 첫번째 값 순으로 정렬
data_list.sort(key=lambda x : x[1]) # 2차원 배열 인덱스의 두번째 값 순으로 정렬
print(data_list)
개발자 성장일기