
지난번 포스팅에서 전처리 및 EDA를 수행한 내용을 바탕으로 모델링을 진행했습니다.
3가지 모델을 후보로 실험 및 검증을 진행했습니다. 전처리 및 EDA 과정은 이전 글을 참고 바랍니다.
모델 선정
- XGBoost
- RNN
- LinearSVC
세 가지로 후보를 둔 이유는 다음과 같습니다.
XGBoost (eXtreme Gradient Boosting)
- XGBoost는 부스팅 알고리즘으로 앙상블 기법을 사용하며, 다양한 데이터 유형과 복잡한 패턴에 대해 강력한 성능을 보일 수 있다.
- 클래스 불균형 문제를 다룰 수 있는 가중치 조정과 샘플링 기법을 제공하여 불균형 데이터셋에도 잘 대응할 수 있다.
- Feature Importance를 제공하여 모델의 예측에 어떤 특성이 중요한지를 해석하기 쉽게 도와줍니다.
+) XGBoost는 하이퍼 파라미터 튜닝이 중요하기 때문에, 추가적으로 GridSearchCV를 이용하여 최적의 파라미터를 찾고 학습을 진행하였습니다.
RNN (Recurrent Neural Network)
- RNN은 장기 의존성을 학습하는데 우수하며, 시계열 데이터나 텍스트와 같은 도메인에서 강력한 성능을 발휘할 수 있다.
+) 클래스 불균형 문제를 해결하기 위해서 불균형한 클래스의 샘플 비율에 따라서 자동으로 가중치 조정을 하는 'compute_class_weight'를 이용하였습니다.
LinearSVC (Support Vector Machine with Linear Kernel)
-LinearSVC는 선형 결정 경계를 통해 클래스를 분리하기 때문에, 비교적 간단하면서도 높은 성능을 발휘할 수 있다.
- 고차원 데이터에서도 잘 동작하며, 특히 텍스트 분류와 같은 자연어 처리 작업에서 효과적일 수 있다.
- 클래스 불균형 문제에도 상대적으로 덜 민감할 수 있다.
+) LinearSVC도 XGBoost와 마찬가지로 최적의 C값을 찾기 위해서 GridSearchCV를 사용했습니다.
모델링: XGBoost (eXtreme Gradient Boosting)
전처리
XGBoost를 사용하기 위해서 TF-IDF를 통한 벡터화와 label을 숫자로 매핑하기 위해 Label Encoder로 전처리를 한번 더 수행했습니다.
posts = data['posts'] # 설명변수
MBTItype = data['type'] # 예측변수
# numpy배열로 변환
posts_list = posts.to_numpy()
type_list = MBTItype.to_numpy()type_listarray(['INTJ', 'INTJ', 'INTJ', ..., 'INTP', 'INFP', 'INFP'], dtype=object)
posts_listarray(['know tool use interaction people excuse antisocial truly enlighten mastermind know would count pet peeze something time matter people either whether group people mall never see best friend sit outside conversation jsut listen want interject sit formulate say wait inject argument thought find fascinate sit watch people talk people fascinate sit class watch different people find intrigue dad stand look like line safeway watch people home talk people like think military job people ...(생략)
import sklearn
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
# posts_list를 모델에 사용할 토큰 개수 행렬로 벡터화
cntizer = CountVectorizer(analyzer="word",
max_features=1000,
max_df=0.7,
min_df=0.1)
# analyzer="word": 텍스트를 단어 단위로 분석
# max_features=1000: 최대 1000개의 단어 피처를 선택
# max_df=0.7: 문서 빈도가 70% 이상인 단어는 무시
# min_df=0.1: 문서 빈도가 최소 10% 이상
print("Using CountVectorizer :")
# posts_list를 토큰 개수 행렬로 변환
X_cnt = cntizer.fit_transform(posts_list)
feature_names = list(enumerate(cntizer.get_feature_names_out()))
print("10 feature names can be seen below")
print(feature_names[0:10])
tfizer = TfidfTransformer()
print("\nUsing Tf-idf :")
print("Now the dataset size is as below")
# 카운트 행렬 X_cnt를 tf-idf 표현으로 변환
X_tfidf = tfizer.fit_transform(X_cnt).toarray()
print(X_tfidf.shape)
Using CountVectorizer :
10 feature names can be seen below
[(0, 'ability'), (1, 'able'), (2, 'absolutely'), (3, 'accept'), (4, 'accurate'), (5, 'across'), (6, 'act'), (7, 'action'), (8, 'actual'), (9, 'actually')]
Using Tf-idf :
Now the dataset size is as below
(114742, 672)
#counting top 10 words
reverse_dic = {}
for key in cntizer.vocabulary_:
reverse_dic[cntizer.vocabulary_[key]] = key
top_10 = np.asarray(np.argsort(np.sum(X_cnt, axis=0))[0,-10:][0, ::-1]).flatten()
[reverse_dic[v] for v in top_10]XGBoost를 사용하기 위해 LabelEncoder를 사용했습니다. XGBoost는 기본적으로 숫자형 데이터를 다루는데 특화되어 있기 때문에 범주형 변수를 사용하려면 이를 숫자로 변환해야 합니다.
제가 사용한 데이터셋은 16개의 범주형 변수가 사용되었기 때문에 이를 0~15의 숫자로 매핑하여 모델이 이해할 수 있는 형태로 변환해주었습니다.
#XGBoost를 사용하기 위해 LabelEncoder 사용
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(type_list)
type_list = le.transform(type_list)from sklearn.model_selection import train_test_split
X_data = X_tfidf
y_data = type_list
X, X_test, y, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=1)
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.2, random_state=1)모델 학습
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import numpy as np
xgb_model = XGBClassifier(n_estimators=100)
params = {'learning_rate': [0.1, 0.06, 0.02], 'max_depth':[3, 5, 7], 'colsample_bytree':[0.3, 0.5,0.75]} # 'n_estimators': [100, 300, 500],'min_child_weight':[1,3], // 'scale_pos_weight': [1, 5, 10] 를 작성해도 사용되지 않아 경고가 뜸.
# GridSearchCV 객체 생성
gridcv = GridSearchCV(xgb_model, param_grid=params, cv=3, scoring='f1_weighted')
# 파라미터 튜닝 시작
gridcv.fit(X_train, y_train, early_stopping_rounds=30, eval_metric='mlogloss', eval_set=[(X_valid, y_valid)])
# 튜닝된 파라미터 출력
print(gridcv.best_params_)
print(gridcv.best_score_)클래스 불균형 문제 해소를 위해서 하이퍼 파라미터 튜닝을 할때, scoring='f1_weighted'와 같이 설정하여 가중치를 적용한 평균 F1-score를 통해 최적의 하이퍼 파라미터를 구했습니다.
다음과 같이 하이퍼 파라미터 튜닝 결과가 나왔으며, 이를 바탕으로 학습을 진행하였습니다.하이퍼 파라미터 튜닝 결과:
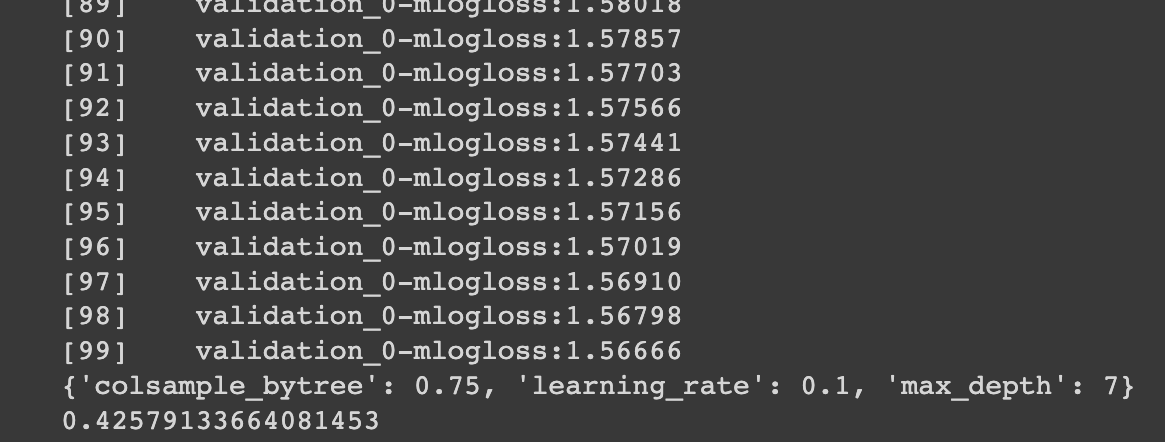
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
# 1차적으로 튜닝된 파라미터를 가지고 객체 생성
xgb_model = XGBClassifier(n_estimators=500, learning_rate=0.1, max_depth=7, min_child_weight=3, colsample_bytree=0.75, reg_alpha=0.03)
# 학습
xgb_model.fit(X, y, early_stopping_rounds=200, eval_metric='mlogloss', eval_set=[(X_test, y_test)])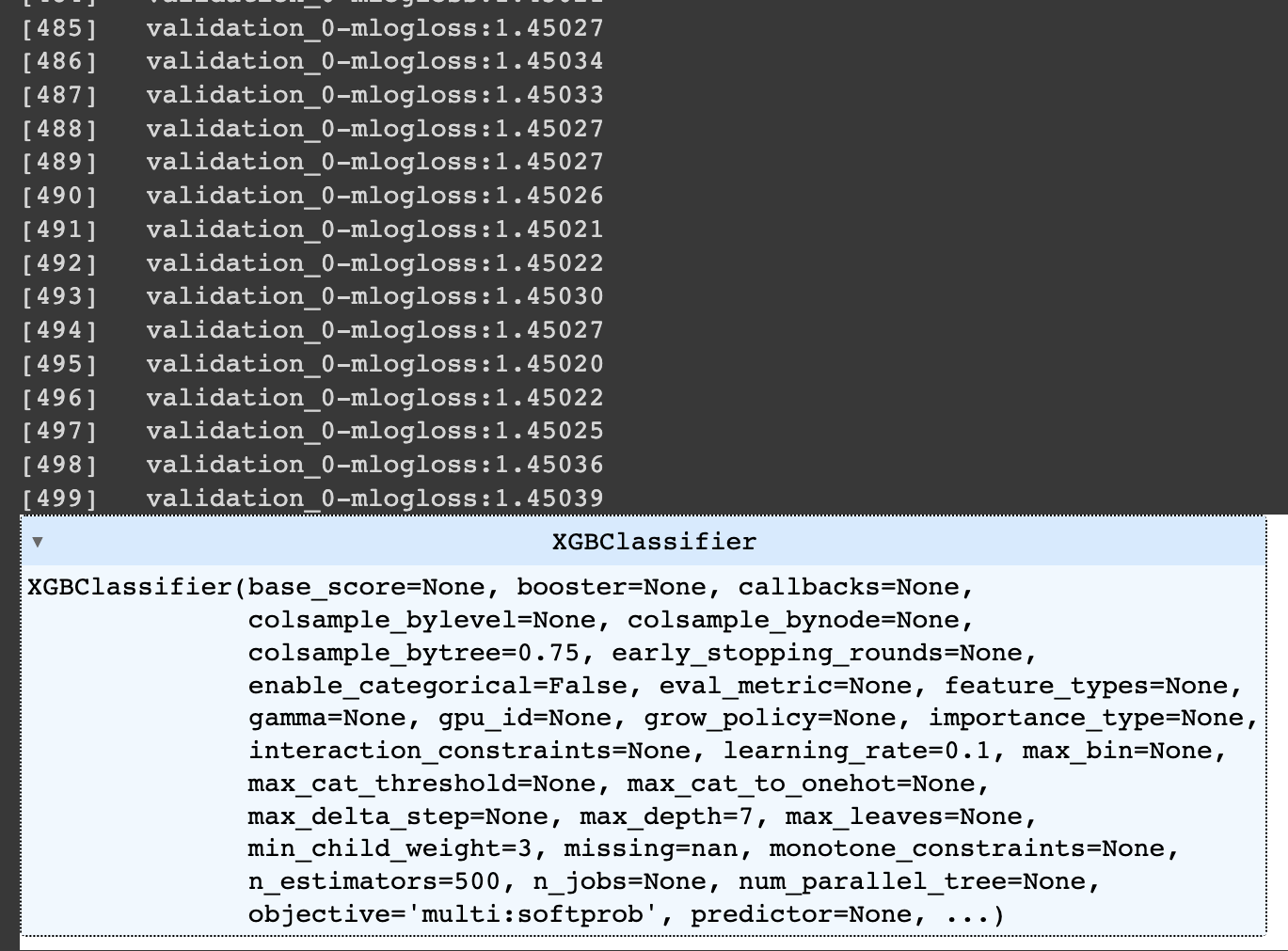
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix, f1_score
xgb_pred = xgb_model.predict(X_test)
accuracy = accuracy_score(y_test, xgb_pred)
precision = precision_score(y_test, xgb_pred, average='weighted')
recall = recall_score(y_test, xgb_pred, average='weighted')
f1 = f1_score(y_test, xgb_pred, average = 'weighted')
print(accuracy)
print(precision)
print(recall)
print(f1)
print('정확도 : {:.4f}\n정밀도 : {:.4f}\n재현율 : {:.4f}\nf1-score : {:.4f}'.format(accuracy, precision, recall, f1))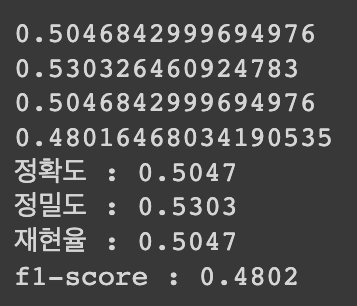
📌 초기 모델링과의 차이점
프로젝트 시작의 목적은 University of Southern California에서 주최한 2023년도 한미 해커톤을 위한 개발이었기 때문에 시간 부족으로 인해 전처리 및 EDA 작업이 부족했습니다. 클래스 불균형 문제의 심각성을 알고 있었지만, 이를 고려하여 모델링을 진행하기 어려웠습니다.
프로젝트 초기에 LinearSVC를 이용하여 개발했던 알고리즘은 accuracy만을 고려하여 모델 성능 평가를 진행했는데 84%라는 정확도만 보고 성능이 좋다고 판단했습니다. 이는 클래스 불균형을 전혀 고려하지 않은 성능 평가입니다.
클래스 불균형 문제가 있을 때, accuracy만을 사용하여 모델 평가를 하면 안되는 이유:
- 데이터 불균형으로 인한 왜곡: 클래스 간 샘플 수가 많이 차이나면, 모델이 샘플 수가 많은 클래스를 더 잘 분류하도록 학습되기 쉽다.
- 이로 인해, 샘플 수가 적은 클래스를 정확하게 예측하지 못할 수 있으며, 데이터 불균형으로 인해 정확도가 높아지는 현상이 발생할 수 있다.
F1-score를 사용해야 하는 이유:
- 데이터 불균형으로 인한 편향을 상쇄하여, 클래스 간 예측 성능을 균형있게 평가한다.
- F1-score는 정밀도와 재현율을 모두 고려하기 때문에, 클래스 간 불균형에 민감하게 반응한다.
- 모델이 작은 클래스의 예측을 얼마나 잘 수행하는지를 보다 정확하게 평가할 수 있다.
따라서, 성능 평가에 F1-score 또한 포함하기로 결정하였습니다.
이번에는 시계열 데이터나 텍스트와 같은 도메인에서 강력한 성능을 발휘하는 RNN(Recurrent Neural Network) 모델링 과정에 대해서 다뤄보겠습니다.
모델링: RNN (Recurrent Neural Network)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
from sklearn.metrics import classification_reportdata = pd.read_csv('/content/drive/MyDrive/spp_project/data_result.csv', index_col='type') #type열을 인덱스로 설정.X = data['posts'] #설명변수
y = data.index #예측변수# Train/test split
X_train, X_test, y_train, y_test = train_test_split(X_padded, y, test_size=0.2, random_state=42)# numpy배열로 변환
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)모델링은 총 2가지로 학습을 진행했습니다. 2안은 lstm layer를 한 층 더 추가하고 drop out 비율을 늘렸습니다.
모델링 1안
# 모델 정의
model = Sequential()
model.add(Embedding(input_dim=max_words, output_dim=256, input_length=max_len))
model.add(LSTM(64, dropout=0.2))
model.add(Dense(len(label_to_int), activation='softmax')) # Use len(label_to_int) as the number of units
# 모델 컴파일
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
# Early stopping callback 설정
early_stopping = EarlyStopping(monitor='val_loss', patience=2, verbose=1)
# Learning rate reduction callback 설정
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=1, verbose=1)
# 모델 학습
batch_size = 64
epochs = 20
model.fit(X_train, y_train_int, batch_size=batch_size, epochs=epochs,
validation_split=0.2, callbacks=[early_stopping, reduce_lr])early stopping: 검증 데이터(validation data)의 성능을 모니터링하여 학습을 조기중단 시키는 역할을 합니다. 성능이 개선되지 않을 때 학습을 중단하여 과적합을 방지하거나 학습 시간을 단축할 수 있습니다.
- monitor: 모니터링할 지표 ex) 'val_loss', 'val_accuracy'
- patience: 성능이 개선되지 않아도 몇 번까지 기다릴지 지정
- verbose: 출력 여부 ex) 0: 출력o, 1: 출력x
- resotre_best_weights: 최상의 모델 가중치로 복원할 지 여부
ReduceLROnPlateau: 학습률을 동적으로 조절하는 역할을 합니다. 검증 데이터(validation data)의 성능이 개선되지 않을 때, 학습률을 줄여서 모델이 더 나은 지점으로 수렴하도록 돕습니다.
- monitor: 모니터링할 지표
- factor: 학습률을 줄일 비율(새 학습률 = 현재 학습률*factor)
- verbose: 출력 여부
- min_lr: 학습률의 하한 값
아래의 결과를 보면, early stopping의 patience = 2로 설정했지 때문에 epoch 2개에서 연속으로 val_loss가 증가하면 성능이 개선되지 않는 것으로 학습이 조기 종료 되는 것을 확인할 수 있습니다.
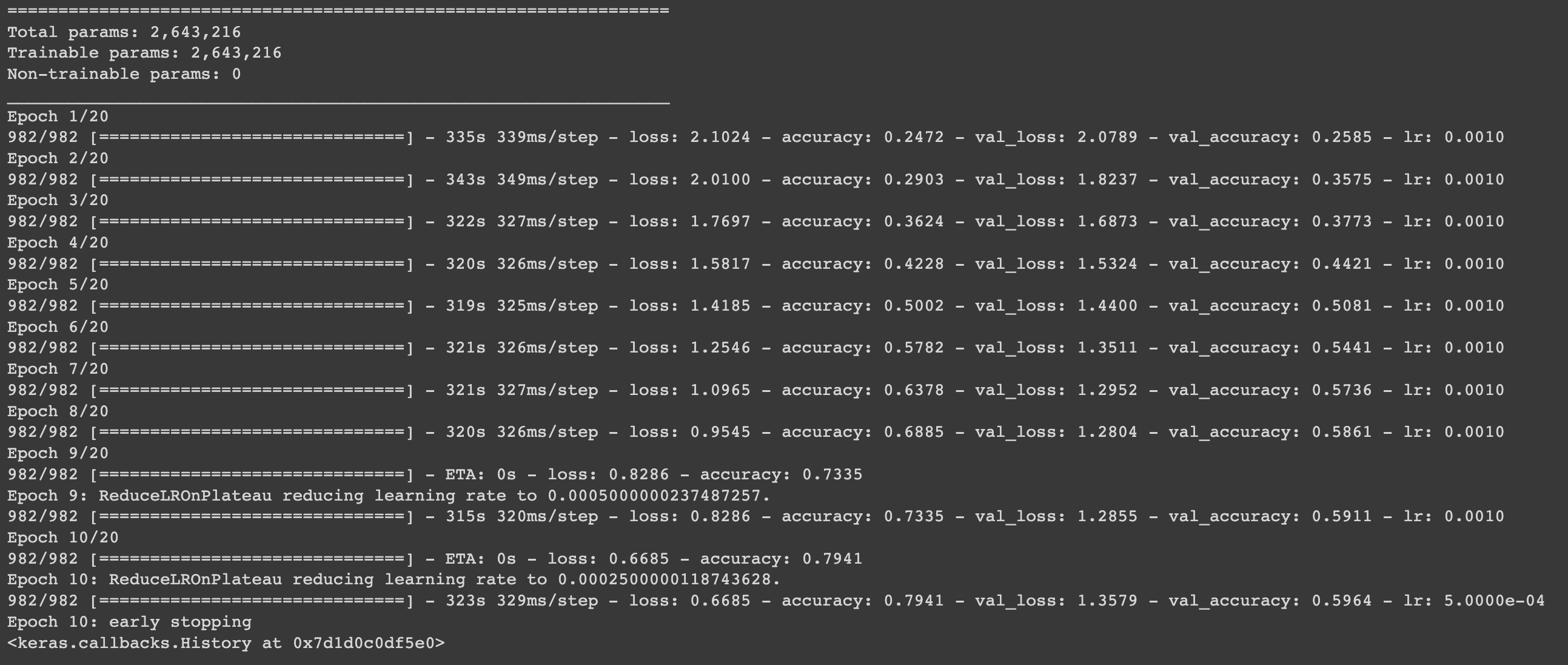
# 예측
pred_probs = model.predict(X_test)
pred_classes = np.argmax(pred_probs, axis=1)
# classification report 계산 및 출력
report = classification_report(y_test_int, pred_classes, target_names=label_to_int.keys())
print(report)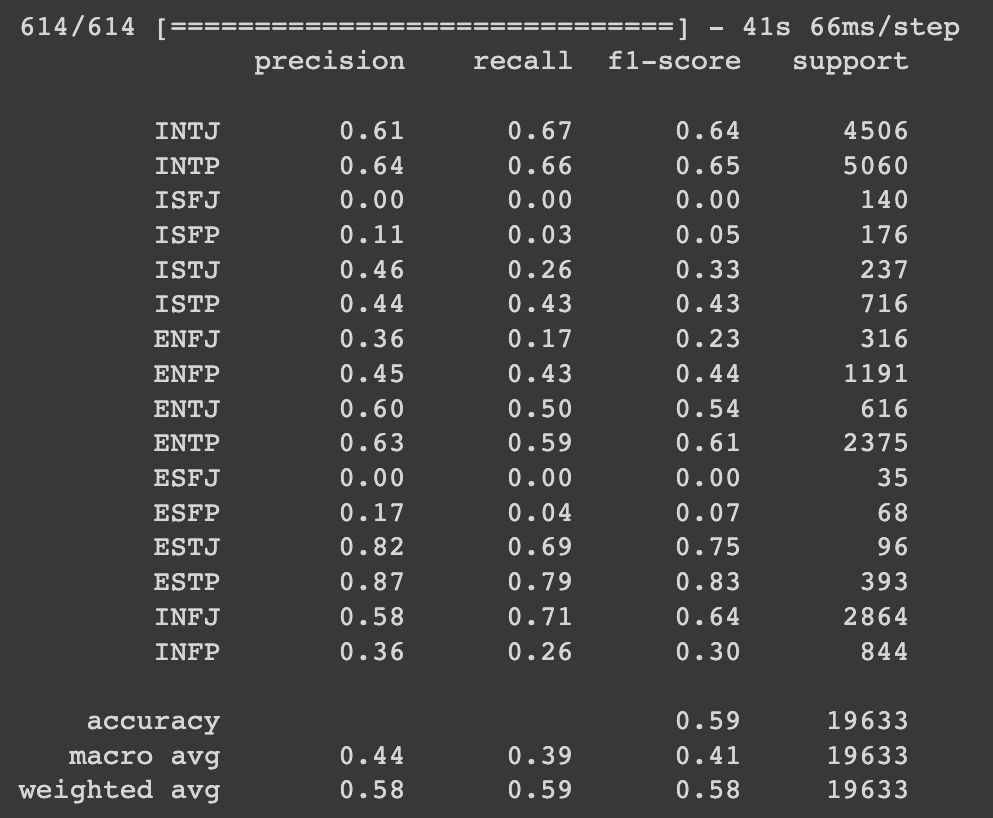 classification report를 보면, support(각 클래스에 속한 샘플의 수)가 적은 클래스는 대체적으로 precision, recall, f1-score가 모두 낮은 것을 볼 수 있습니다. 성능을 높이기 위해서는 파라미터 튜닝(모델의 layer 층 개수 조절 등), 클래스 불균형 해결, drop out 비율 조절 등의 방법이 있습니다.
classification report를 보면, support(각 클래스에 속한 샘플의 수)가 적은 클래스는 대체적으로 precision, recall, f1-score가 모두 낮은 것을 볼 수 있습니다. 성능을 높이기 위해서는 파라미터 튜닝(모델의 layer 층 개수 조절 등), 클래스 불균형 해결, drop out 비율 조절 등의 방법이 있습니다.
처음으로 고려했던 방법은 가중치 조정을 통한 '클래스 불균형 해결'이었는데, 오히려 정확도가 심하게 낮아지고 검증 데이터에 대한 성능이 거의 개선되지 않고 학습이 조기 종료되어 다른 방법을 시도했습니다.
코드에는 사용하지 않았지만, 가중치 조정에 대해 궁금하신 분들은 참고 바랍니다.가중치 조정 방법은 다음과 같습니다.
클래스 불균형 문제를 해결하기 위해서는 class_weight 매개변수를 사용하면 됩니다.
class_weight는 손실 함수 계산 시 각 클래스에 적용할 가중치를 지정하는 매개변수로,
불균형한 클래스에 높은 가중치를 부여하여 모델이 불균형한 데이터를 더 잘 학습할 수 있도록 도와줍니다.# 필요한 모듈 임포트
from sklearn.utils.class_weight import compute_class_weight
# 클래스 가중치 계산
class_weights = compute_class_weight(class_weight = "balanced", classes = np.unique(y_train_int), y = y_train_int)
class_weight_dict = {i: w for i, w in enumerate(class_weights)}
.
.
(생략)
.
.
# 매개변수에 class_weight=class_weight_dict 추가
model.fit(X_train, y_train_int, batch_size=batch_size, epochs=epochs,
validation_split=0.2, callbacks=[early_stopping, reduce_lr], class_weight=class_weight_dict)모델링 2안
# Define the model
model = Sequential()
model.add(Embedding(input_dim=max_words, output_dim=256, input_length=max_len))
model.add(LSTM(128, dropout=0.3, return_sequences=True))
model.add(LSTM(128, dropout=0.3))
model.add(Dense(len(label_to_int), activation='softmax')) # Use len(label_to_int) as the number of units
# Compile the model
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Print model summary
model.summary()
# Early stopping callback
early_stopping = EarlyStopping(monitor='val_loss', patience=2, verbose=1)
# Learning rate reduction callback
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=1, verbose=1)
# Train the model
batch_size = 64
epochs = 30
model.fit(X_train, y_train_int, batch_size=batch_size, epochs=epochs,
validation_split=0.2, callbacks=[early_stopping, reduce_lr])
# Predict classes
pred_probs = model.predict(X_test)
pred_classes = np.argmax(pred_probs, axis=1)
# Calculate classification report
report = classification_report(y_test_int, pred_classes, target_names=label_to_int.keys())
print(report)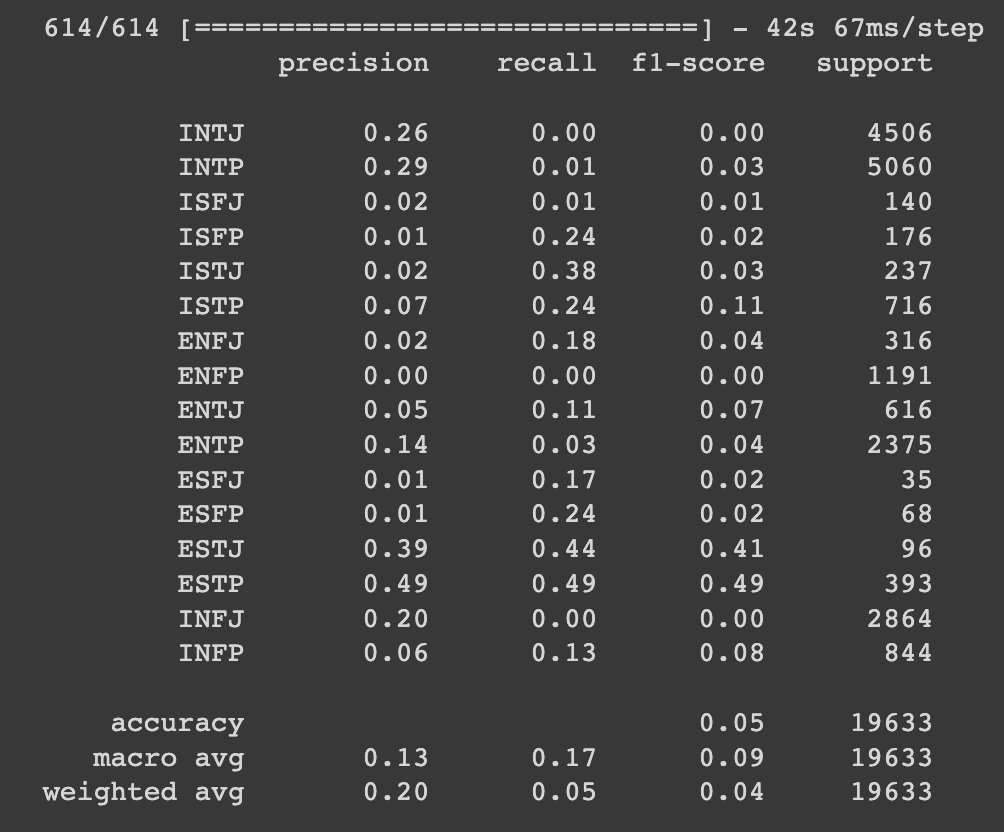 2안도 마찬가지로 support(각 클래스에 속한 샘플의 수)가 적은 클래스는 대체적으로 precision, recall, f1-score가 모두 낮은 것을 볼 수 있습니다. 클래스 불균형 해결이 가장 중요할 것 같다는 생각이 들었고, 가중치 조정으로 계속 시도를 해보았지만 해결이 안되었기 때문에 처음에 사용하던 LinearSVC 모델에 데이터 리샘플링을 추가해보기로 결정했습니다.
2안도 마찬가지로 support(각 클래스에 속한 샘플의 수)가 적은 클래스는 대체적으로 precision, recall, f1-score가 모두 낮은 것을 볼 수 있습니다. 클래스 불균형 해결이 가장 중요할 것 같다는 생각이 들었고, 가중치 조정으로 계속 시도를 해보았지만 해결이 안되었기 때문에 처음에 사용하던 LinearSVC 모델에 데이터 리샘플링을 추가해보기로 결정했습니다.
포스팅을 마치며..
결과적으로, 첫 모델은 accuracy는 높지만 f1-score가 아주 낮았기 때문에 현재의 모델도 성능이 좋다고 판단할 수는 없으나 개선이 되었다는 것을 알 수 있었습니다. 모델의 성능이 좋지 않은 이유는 XGBoost와 같은 gradient boosting 알고리즘은 주로 수치형 데이터에 대한 모델링에 뛰어난 성능을 보이지만, 텍스트와 같은 비정형 데이터에는 다소 한계가 있기 때문이라고 생각합니다. 불균형 클래스에 덜 민감하지만, 텍스트 데이터를 사용한 모델링이기 때문에 적합하지 않은 모델이라는 생각이 들었습니다.
또한, 딥러닝 모델링 경험이 많지 않아서 더욱 많은 시간을 투자했지만 좋은 결과는 얻지 못했던 것 같습니다. 이번에 딥러닝 모델링을 직접 해보면서 공부해야할 부분이 많다는 것을 느꼈습니다. 다양한 에러와 좋지 않은 성능을 마주하는 등 많은 시행착오를 겪으면서, 배울 수 있었고 부족함을 많이 느꼈습니다. 초반에 짰던 알고리즘부터 최종 결과물까지 비교를 하면 많이 성장한 것 같다는 생각도 들었습니다.
그동안 모델링을 할때, 불균형 클래스 문제가 있는 데이터셋을 다뤄본 적이 많이 없었기 때문에 accuracy만을 고려하여 모델 성능 평가를 했습니다. 불균형이 심각한 데이터를 사용하여 모델링을 진행해보면서, 다양한 지표를 활용하여 모델 성능 평가를 해야 한다는 점을 배울 수 있었던 것 같습니다.
다음 포스팅에서는 처음 짰던 LinearSVC 코드와 최종 모델로 완성된 LinearSVC 코드에 대한 설명을 모두 작성하겠습니다.
부족한 글이지만, 읽어주셔서 감사합니다.☺️
