Cirqular Queue
배열을 사용한 Queue의 단점
지난번 글에서 구현한 동적 배열을 사용한 큐에 단점이 있었다.
그것은 QueDequeue 함수에서 자료를 꺼내올 때 배열의 가장 앞에 있는 데이터를 꺼내오기 때문에 그 다음 인덱스의 데이터들을 한 칸씩 모두 이동해야 하는 점이었다.
이 과정은 반복문으로 수행되며 자료 하나를 꺼낼 때마다 O(n)만큼의 시간 복잡도를 요구하므로 상당히 비효율적이다. 백준 문제를 풀 때 입력 받는 데이터가 매우 커지면 대부분 이런 알고리즘으로는 '시간 초과'가 출력되었다.
따라서 이번 글에서는 이러한 단점을 보완한 원형 큐(Circular Queue)를 구현할 것이다.
원형 큐는 영어로 'Ring Buffer'라고도 부른다.
원형 큐(Circular Queue)란
원형 큐 역시 큐의 일종이다. 또한 여기서 구현하는 원형 큐 역시 배열에 데이터를 저장하는 방식이다. 다른 점은 이전의 큐는 데이터를 가리키는 인덱스가 하나였지만 이번에 구현하는 원형 큐는 front, rear 두 개의 인덱스 변수가 존재한다.
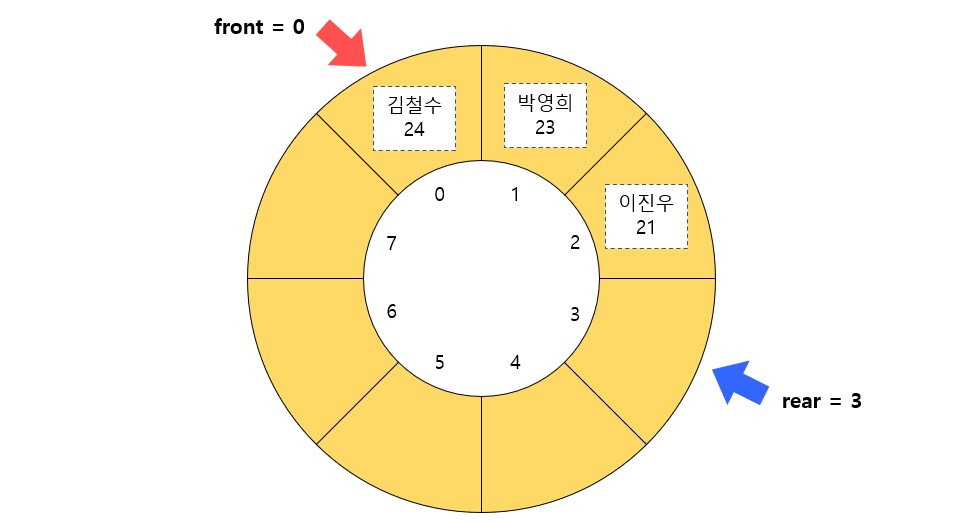
아래의 그림을 보자.
위처럼 원형 큐는 배열을 원 모양으로 둥글게 말은 형태를 상상하면 이해하기 쉽다. 변수 front는 첫 번째 데이터를 가리키고 변수 rear는 마지막 데이터를 가리키는 변수이다.
이렇게 두 개의 변수로 위치를 기억하는 이유는 무엇일까? 데이터를 처음부터 채운다고 가정하면 front의 값은 계속 0이고 rear의 값은 증가한다. rear가 배열의 마지막까지 도달했는데 만약 배열의 맨 앞에 데이터가 빠져서 빈 공간이 생기면 rear는 다시 처음으로 돌아와 0을 가리키며 그 위치에 데이터를 저장할 수 있다. 이렇게 되면 rear의 값은 front 값보다 작아진다.
원형 큐의 장점은 여기서 온다. 데이터의 맨 앞과 맨 뒤 위치를 기억하기 때문에 기존의 큐처럼 데이터를 매번 한 칸씩 당겨오지 않아도 공간이 허락하는 한 데이터를 빠르게 처리할 수 있다.
만약 front와 rear의 값이 같다면 원형 큐는 비어 있다고 볼 수 있다.
C언어로 나타낸 원형 큐
C언어의 구조체로 나타내면 아래와 같이 정의된다.
typedef struct {
Element* arr;
int front;
int rear;
} CircularQueue;앞서 서술한 것처럼 이번에 구현하는 원형 큐는 배열에 데이터를 저장한다. 다른 방법으로는 리스트를 사용하는 것이 있겠다.
원형 큐에 데이터 추가하기
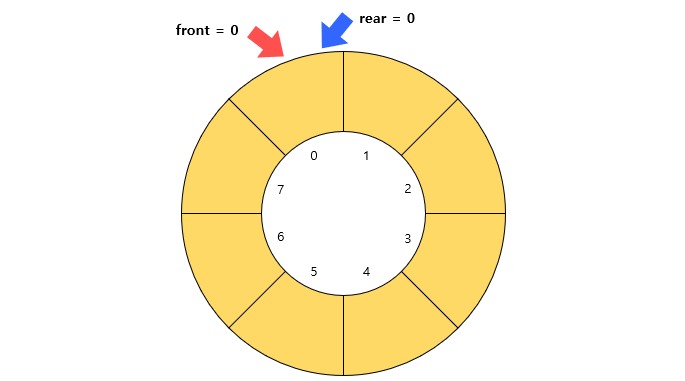
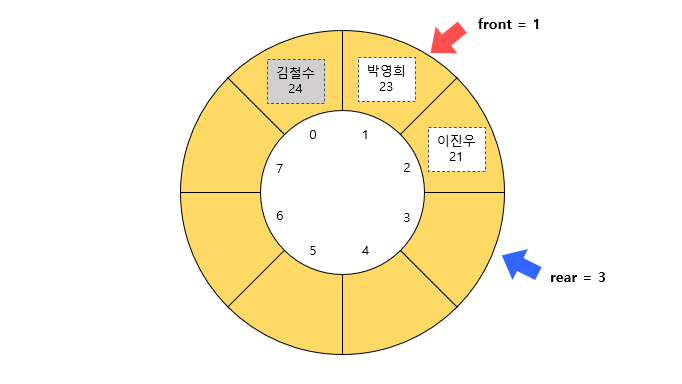
아래는 원형 큐에 최초로 데이터를 추가한 후의 모습이다.
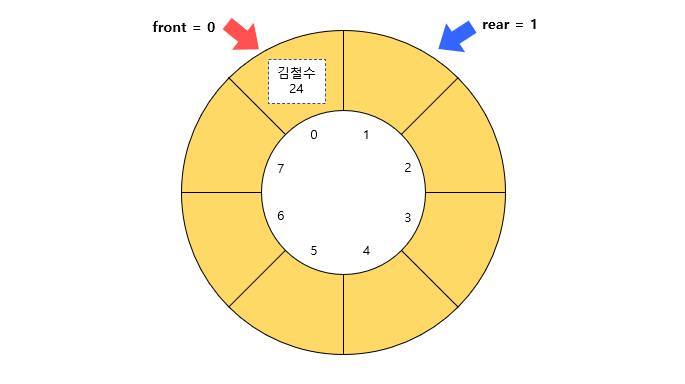
front의 값은 변함 없고 rear의 값이 1 증가했다. 따라서 실제로 마지막 데이터는 rear가 가리키는 위치보다 1칸 적은 곳이다.
이런 식으로 front의 값은 변하지 않고 rear의 값만 증가하면서 원형 큐에 데이터가 추가된다.
원형 큐에서 데이터 삭제하기
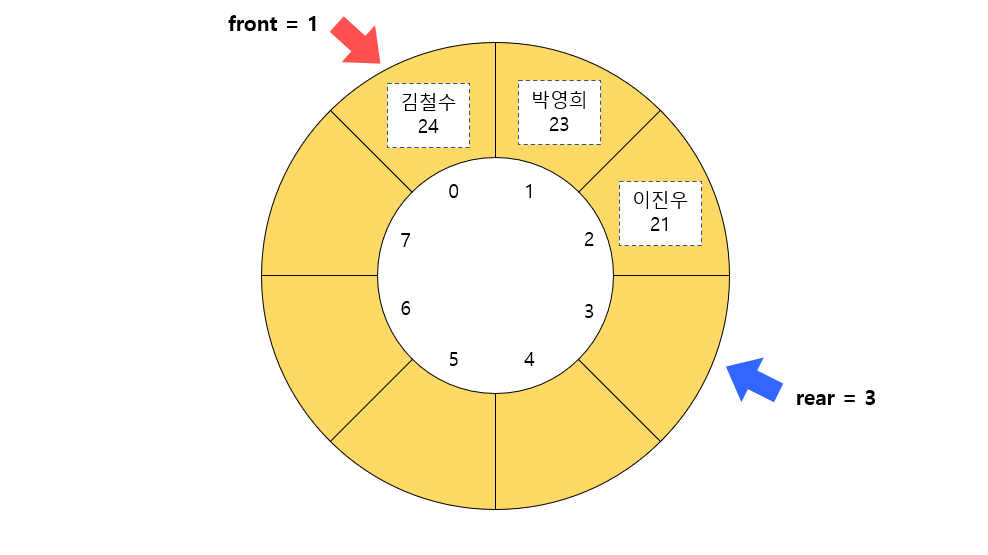
위의 상황에서 데이터를 삭제하면 어떻게 되는지 살펴보자.
데이터를 삭제하면 front가 가리키는 데이터가 반환되고 front의 값이 증가한다.
아래의 식으로 데이터의 개수를 구할 수 있다.
count = rear - front;하지만 항상 이 식이 성립하는 것은 아니다. 원형 큐는 rear가 front보다 작아질 수 있기 때문이다. 이 경우에 대한 식은 아래의 '나머지 연산자 활용하기'에서 살펴본다.
한편 front가 1번째 인덱스의 데이터를 가리켜서 0번째 인덱스의 데이터가 없다고 취급하는 것일 뿐 실제로 배열에는 여전히 { 24, "김철수" } 라는 데이터가 저장되어 있다.
원형 큐에 데이터가 최대로 저장된 경우
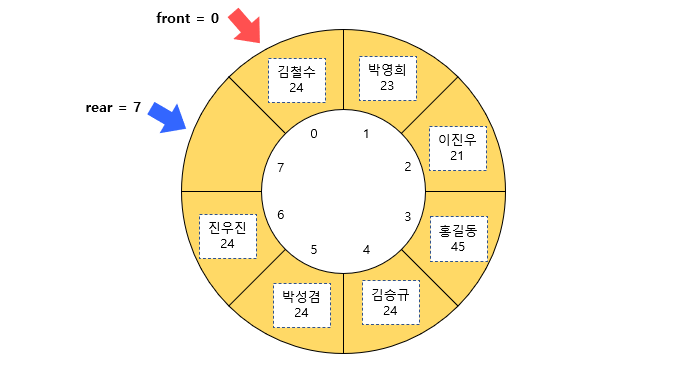
데이터가 꽉 찬 경우는 위처럼 front와 rear의 인덱스 차이가 한 칸 만큼 날 때이다.
하지만 한 칸만큼의 차이를 front와 rear의 값으로 어떻게 구할 수 있을까? 실제로 front = 0, rear = 7이므로 두 값의 차이는 7이다. 원형 큐를 구현할 때 이 부분을 잘 처리해야 한다. 이것 역시 '나머지 연산자 활용하기'에서 살펴본다.
한편 인덱스 7의 위치를 한 칸 비워둔 이유는, 만약 그 위치에 데이터를 저장하게 되면 rear의 값은 8 즉, 처음의 위치로 돌아와 0이 되므로 front과 rear의 값이 같아진다.
그런데 front와 rear의 값이 같은 경우에 원형 큐가 비어 있는 것으로 간주하기 때문에 이렇게 되면 원형 큐가 빈 것인지 모두 찬 것인지 구별할 수 없게 된다. 따라서 한 칸을 비워 두 상황을 구별할 수 있도록 하였다.
물론 이렇게 한 칸도 낭비하고 싶지 않다면 모든 공간을 사용할 수 있도록 구현할 수 있다. 하지만 조금 복잡해지는 것보다 그냥 한 칸 낭비하는 것을 선택했다. 모든 공간을 활용하여 구현하는 방법을 알고 싶다면 아래의 링크를 참고하자.
Circular Queue | Set 1 (Introduction and Array Implementation) (새 창)
나머지 연산자(%) 활용하기 1: 데이터 추가, 삭제
바로 위의 예시처럼 데이터가 꽉 찬 상태에서 Dequeue 함수를 호출하여 앞의 데이터를 3개 빼온 상황을 생각해보자.
이를 그림으로 나타내면 아래와 같다.
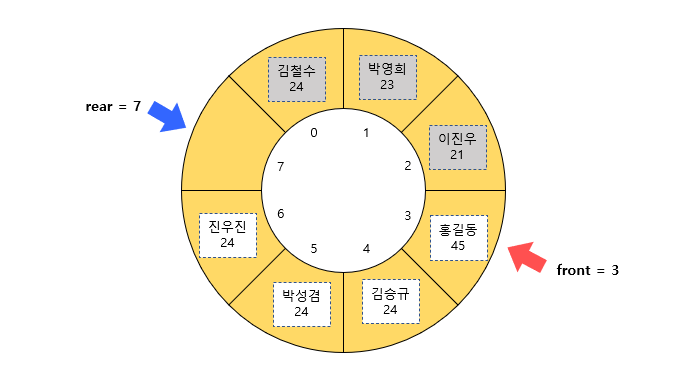
꽉 찬 상태에서 세 개의 데이터를 빼왔으므로 다시 최대 세 개의 데이터를 넣을 수 있다.
원형 큐에 새로운 데이터를 하나 추가해보자.

{ 24, "문도언" }이라는 새로운 데이터를 추가했다. 큐의 맨 마지막 데이터의 인덱스를 저장하는 변수 rear에는 어떤 값이 와야 할까? 당연히 0번째 인덱스이므로 '?'에 들어갈 값은 0이다. 즉 7이었던 rear의 값이 0으로 바뀐다.
rear의 값을 구하는 방법은 나머지 연산자를 이용하는 것이다. 배열의 최대 크기가 상수 MAX_LEN에 8로 선언되어 있다고 가정해보자. 그렇다면 7에서 1을 증가시킨 후 8로 나누어 줘야 0이 되므로 계산 방법은 아래와 같다.
rear = (rear + 1) % MAX_LEN;이 방법은 변수 front의 값을 수정할 때에도 사용된다. 이 방법으로 데이터가 추가되거나 삭제될 때 원형 큐의 인덱스를 구할 수 있다. 다시 말해 데이터를 삭제하는 Dequeue 함수나 데이터를 추가하는 Enqueue 함수에서 인덱스의 값을 수정할 때 사용한다.
나머지 연산자(%)로 연산 2: 저장된 데이터 개수 구하기
이 방법으로 데이터의 개수를 구할 수 있다. 아래의 상황을 가정해보자.
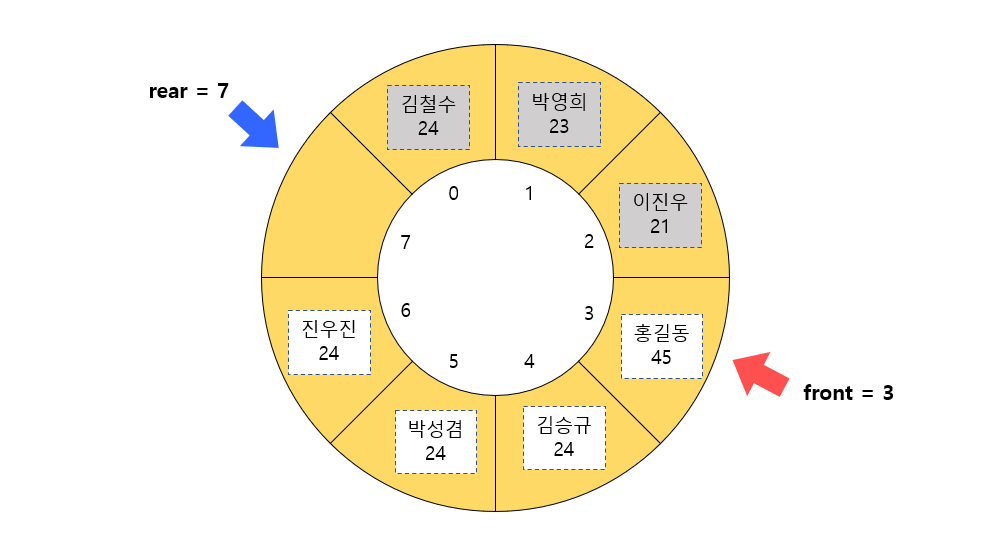
여기서 데이터의 개수를 눈으로 세보면 4개이다. 이 때 변수 front(3)와 rear(7)로 이 값을 구해보자. rear가 front보다 큰 경우엔 앞서 서술한 것처럼 두 값의 차이로 데이터의 개수를 구할 수 있다.
count = rear - front;데이터의 개수 4는 7(rear) - 3(front)이다.
그러나 만약 데이터가 하나 더 추가되어 rear의 값이 7에서 0으로 바뀌면 어떻게 구해야 할까?
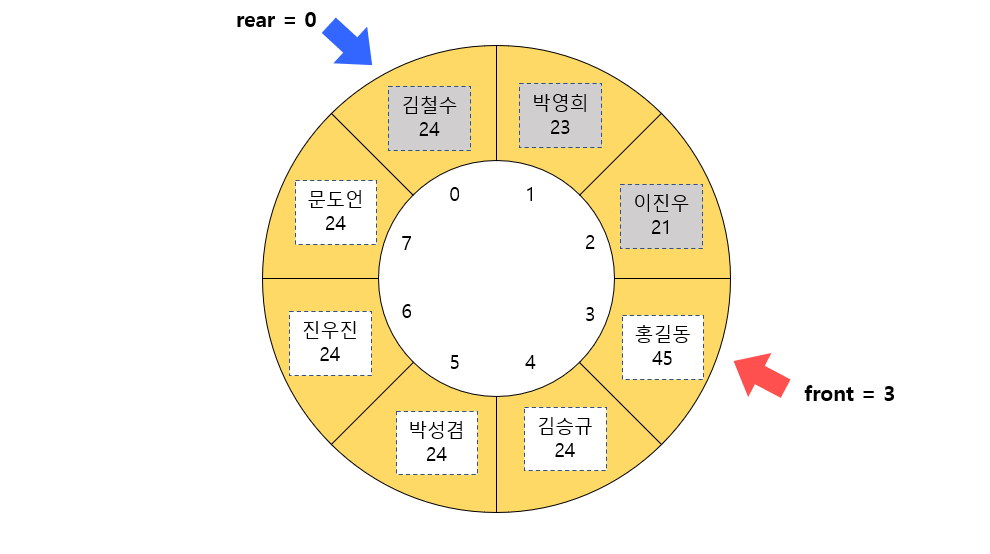
이 상황에서 데이터의 개수는 5개인데 rear(0) - front(3)의 값은 -3이다. 이 방법은 아래처럼 front가 rear보다 큰 상황에서는 적용되지 않는다. 이를 해결하는 방법은 MAX_LEN의 값인 8을 더하는 것이다. 배열의 크기를 더하면 데이터의 개수를 구할 수 있다.
데이터 개수 구하기 요약 정리
우리는 다음의 두 가지 상황에 대해 저장된 데이터의 개수를 구하는 방법을 알아봤다.
front < rear일 때
count = rear - front;front > rear일 때
count = (rear - front) + MAX_LEN;따라서 모든 상황에서 만족시킬 수 있는 수식은
count = ((rear - front + 1) + MAX_LEN) % MAX_LEN;이렇게 생각할 수 있다.
글이 길어지므로 구현하기는 다음 글에서 작성한다.
