오늘 학습한 내용
- @Transactional(readOnly = true)
- readOnly = true 옵션을 사용하는 이유는?
- 영속성 컨텍스트의 변경 감지와 @Transactional(readOnly = true)에서의 동작
- readOnly = true 옵션을 사용할 때 생길 수 있는 문제점
- PUT과 PATCH
- PUT과 PATCH의 비교
- 멱등성
@Transactional(readOnly = true)
일반적으로, 조회 메서드에 @Transactional(readOnly = true) 옵션을 추가하면 조회 성능이 좋아지는 것으로 알려져 있다. 그 외에 @Transactional(readOnly = true)를 사용하는 이유와, @Transactional(readOnly = true)의 동작 원리에 대해 알아보았다.
readOnly = true 옵션을 사용하는 이유는?
성능 최적화
앞서 언급했지만 첫째, 성능 최적화이다. 자세한 원리는 다음 소주제에서 다룰 것이다.
데이터 일관성 유지
둘째, 데이터 일관성의 유지에 기여한다. readOnly = true 옵션이 설정되어 있다면, 그럴 일은 드물겠지만 실수로 데이터를 수정해 일관성을 깨트리는 위험을 피할 수 있다.
가독성 향상
셋째, 가독성을 향상시킬 수 있다. 조회 메서드에 @Transactional(readOnly=true) 어노테이션이 있다면, 굳이 메서드의 로직을 확인하지 않더라도 이것이 조회 메서드라는 것을 쉽게 알 수 있다.
영속성 컨텍스트의 변경 감지와 @Transactional(readOnly = true)에서의 동작
JPA는 영속성 컨텍스트를 통해 변경 감지(dirty checking)을 수행한다. 영속성 컨텍스트는 처음 Entity를 조회할 때 스냅샷을 생성해 초기 상태를 저장한다.
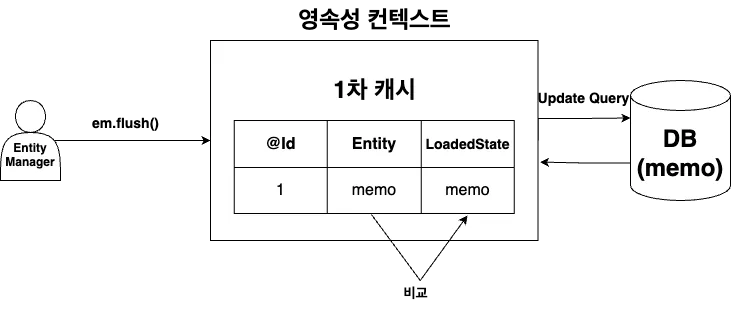
트랜잭션이 commit되고 em.flush(); 가 호출되면 Entity의 현재 상태와 저장한 최초 상태를 비교하며, 변경 내용이 있다면 Update SQL을 생성하여 쓰기 지연 저장소에 저장하고 모든 쓰기 지연 저장소의 SQL을 DB에 요청한다.
readOnly = true 옵션을 사용할 경우, JPA의 세션 플러시 모드를 NEVER로 설정하게 된다. NEVER 모드는 JPA가 영속성 컨텍스트에 있는 변경 내용을 데이터베이스에 반영하지 않도록 설정한다. 또한, 영속성 컨텍스트에서 변경 감지를 위한 스냅샷 자체를 생성하지 않는다. 그리고, DB 드라이버에 따라 읽기 전용 트랜잭션임을 알려줘서 DB 레벨의 최적화가 가능해진다.
즉, 단순 조회를 위해 필요 없는 기능들을 모두 비활성화시키기 때문에 성능이 향상되는 것이다.
readOnly = true 옵션을 사용할 때 생길 수 있는 문제점
Lazy Loading 시 예외 발생 가능성
영속성 컨텍스트를 View Layer까지 유지하는 OSIV 속성이 있다. 클라이언트의 요청 시점부터 영속성 컨텍스트를 생성하여 Filter / Interceptor - Controller에서 부터 영속성 컨텍스트가 생성되어 유지됨으로써 View Layer에서도 Entity의 Lazy Loading이 가능하도록 한다. 즉 트랜잭션 종료 후에도 영속성 컨텍스트가 유지되고, 뷰 렌더링 시점까지 지연 로딩 가능해진다.
기본적으로 스프링부트 3.x 버전에서는 OSIV는 true로 설정되어 있다. 하지만 2.x 버전에서는 기본 설정이 false이다.
@Transactional(readOnly = true)
public User getUserWithAddresses(Long userId) {
User user = userRepository.findById(userId).orElseThrow();
user.getAddresses().size(); // LazyInitializationException 발생 가능
return user;
}따라서 위와 같이 Lazy Loading을 사용하는 엔티티를 접근하려는 경우 LazyInitializationException이 발생 가능하다.
PUT과 PATCH
PUT과 PATCH의 비교
PUT
PUT은 전체 리소스에 대한 업데이트를 수행할 때 사용한다.
클라이언트가 요청을 보낼 때 리소스의 모든 속성을 포함해야 하며, 포함되지 않은 속성은 기본값 또는 null로 처리된다. 따라서 PUT은 업데이트를 수행할 때 클라이언트가 모든 필드를 보내야 한다.
PUT은 같은 요청을 여러 번 보내더라도 리소스 상태가 동일하게 유지된다.
// 초기 사용자 정보
{
"id": 123,
"username": "johndoe",
"email": "john@example.com",
"age": 30,
"address": "서울시 강남구",
"phoneNumber": "010-1234-5678"
}
// PUT 요청 - 이메일만 변경하려 해도 전체 데이터 필요
PUT /users/123
{
"username": "johndoe",
"email": "new_john@example.com",
"age": 30,
"address": "서울시 강남구",
"phoneNumber": "010-1234-5678"
}PATCH
PATCH는 리소스의 일부 속성만 수정하며, 변경이 필요한 속성만 요청 본문에 포함하면 된다.
PATCH는 구현 방식에 따라 다르지만, 같은 요청을 여러 번 보냈을 때 리소스 상태가 동일함을 보장할 수 없다.
// 이메일만 변경 가능
PATCH /users/123
{
"email": "new_john@example.com"
}멱등성
앞서 PUT은 같은 요청을 여러 번 보내도 리소스 상태가 동일하게 유지된다고 했고, PATCH는 리스소 상태가 동일함을 보장할 수 없다고 했다.
멱등성의 정의는 다음과 같다.
An HTTP method is idempotent if an identical request can be made once or several times in a row with the same effect while leaving the server in the same state.
동일한 요청을 한 번 보내는 것과 여러 번 연속으로 보내는 것이 같은 효과를 지니고, 서버의 상태도 동일하게 남을 때, 해당 HTTP 메서드가 멱등성을 가졌다고 말합니다.
따라서 PUT은 멱등성이 보장되고, PATCH는 멱등성이 보장되지 않는다.
멱등성 예시
아래는 김영한님이 인프런에 남겨주신 답변이다.
PUT은 해당 리소스를 완전히 교체해 버리기 때문에 멱등입니다.
PATCH는 멱등으로 설계할 수도 있지만, 멱등이 아니게도 설계할 수 있습니다.
예를들어서 다음과 같은 경우는 PATCH 이지만 멱등입니다.
{ name: "kim"}
반면에 다음과 같은 경우는 PATCH 이지만 멱등이 아닙니다.
예를 들어서 한번 호출할 때 마다 나이를 10 더하는 식으로 변경하고 싶다고 가정하겠습니다.
PATCH는 멱등이 아니기 때문에 다음과 같이 특정 부분을 추가로 더하거나 하는 식으로 설계해도 됩니다. 물론 이 경우 서버에서 operation add가 어떤 의미인지 알 수 있어야 합니다.
{ "operation": "add", "age": 10"}
이렇게 하면 2번 호출하면 +10 + 10이 되어 버려서 먹등이 아닙니다.
정리해드리면 PATCH는 리소스의 특정 부분을 변경하는데, 이 변경 방식이 멱등이어도 되고, 멱등이 아니어도 됩니다.
즉, age : 10으로 요청을 보냈지만, age는 실제로 10이 되는 것이 아니라 기존 age+10이 될 것이다. 여러 번 요청을 보낼 때 마다 리소스 상태는 달라진다. 멱등성이 보장되지 않는 것이다. PATCH는 이렇게 멱등성이 보장되지 않는 로직을 수행하는 경우에도 사용할 수 있다.
