오늘 학습한 내용
- 캐싱 전략
- 캐시 읽기 전략
- 캐시 쓰기 전략
- 결론
캐싱 전략
Cache는 본래 CPU 내부의 작은 영역으로, 자주 접근하게 되는 데이터를 저장해두는 임시 기억 장치입니다. 기본적으로 영속성을 위해 파일시스템(디스크)에 저장하고, 빠른 활용을 위해 메모리(RAM)에 저장한다면, 자주 사용되는 휘발성 데이터가 캐시에 저장된다.
이러한 캐시의 목적과 방식을 웹 개발에 적용해, 자주 접근하게 되는 데이터베이스의 데이터를 Redis 등의 인메모리 데이터베이스에 저장을 함으로서 데이터를 조회하는데 걸리는 시간과 자원을 감소시키는 기술을 캐싱이라고 한다.
웹 브라우저에서는 자주 바뀌지 않는 이미지 등을 브라우저 캐시에 저장해 페이지 로드를 줄이는 것도 캐싱의 일종이며, 이는 RESTful 설계 원칙 중에서 응답이 캐싱이 가능한지 명시해야 한다는 제약사항으로도 나타난다.
캐싱 전략으로 들어가기 전에 미리 알아야 할 용어들이 있다.
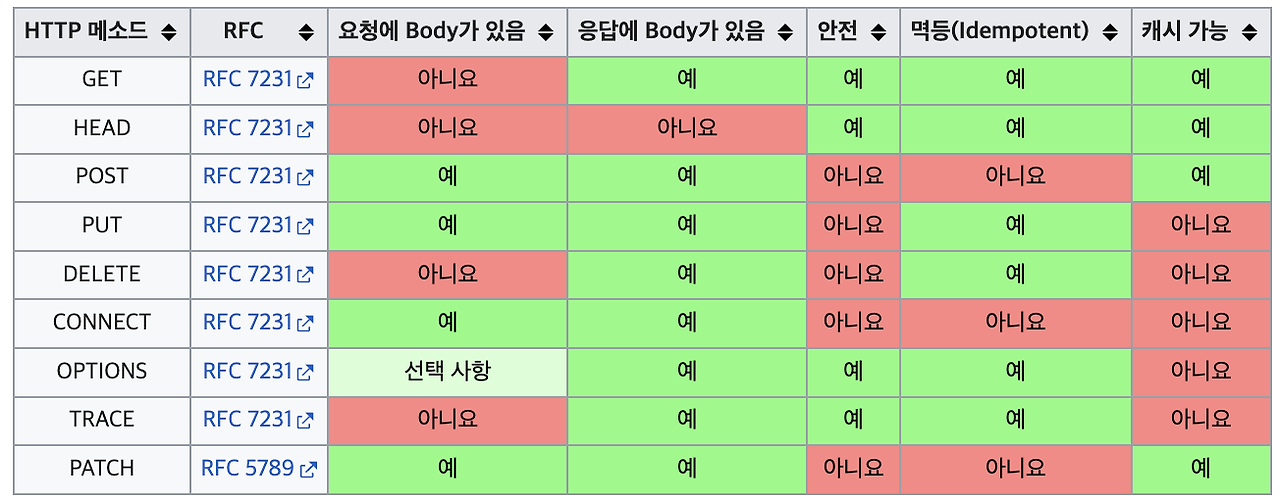
- 캐시 적중(Cache Hit): 캐시에 접근했을 때 찾고 있는 데이터가 있는 경우
- 캐시 누락(Cache Miss): 캐시에 접근했을 때 찾고 있는 데이터가 없는 경우
- 삭제 정책(Eviction Policy): 캐시에 공간이 부족할때 어떻게 공간을 확보하는지에 대한 정책
캐시 읽기 전략
Look Aside(Cache Aside)
Lazy Loading이라고도 하며, 데이터를 조회할 때 항상 캐시를 먼저 확인하는 전략이다. 캐시에 데이터가 있으면 캐시에서 데이터를, 없으면 원본(DB)에서 데이터를 가져온 뒤 캐시에 저장한다.
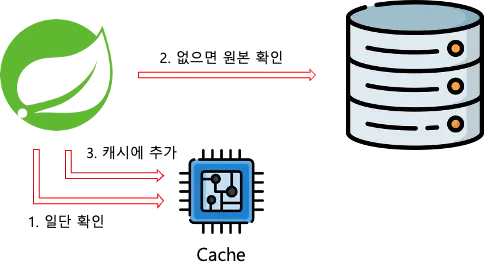
- 필요한 데이터만 캐시에 보관된다.
- 최초로 조회할 때 캐시를 확인하기 때문에 최초의 요청은 상대적으로 오래 걸린다.
- 반드시 원본을 확인하지 않기 때문에, 데이터가 최신이라는 보장이 없다.
redis가 다운 되더라도 DB에서 데이터를 가져올 수 있어 서비스 자체는 유지되지만, 만약 캐시에 붙어있던 connection이 많았다면 이 connection들이 한꺼번에 DB로 몰려 문제가 될 수 있다.
Cache Store와 Data Store(DB)간 정합성 유지 문제가 발생할 수 있으며, 초기 조회 시 무조건 Data Store를 호출 해야 하므로 단건 호출 빈도가 높은 서비스에 적합하지 않다. 대신 반복적으로 동일 쿼리를 수행하는 서비스에 적합한 아키텍처이다.
초기 조회 시의 문제를 해결하기 위해 DB에서 캐시로 데이터를 미리 넣어주는 Cache Warming 작업을 하기도 한다.
캐시 쓰기 전략
Write Through
데이터를 작성할때 항상 캐시에 작성하고, 원본에도 작성하는 전략이다.
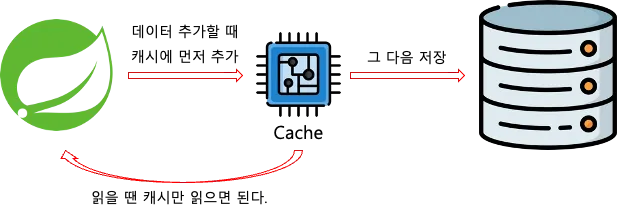
- 캐시의 데이터 상태는 항상 최신 데이터임이 보장된다.
- 자주 사용하지 않는 데이터도 캐시에 중복해서 작성하기 때문에, 시간이 오래 걸린다.
캐시와 백업 저장소에 업데이트를 같이 하여 데이터 일관성을 유지할 수 있어서 안정적이며, 데이터 유실이 발생하면 안 되는 상황에 적합하다.
매 요청마다 두번의 쓰기가 발생하게 됨으로써 빈번한 생성, 수정이 발생하는 서비스에서는 성능 저하가 두드러진다.
또한 캐시에 추가한 데이터를 읽지 않을 가능성도 있기 때문에 이 경우 리소스 낭비가 된다.
Write Behind
캐시에만 데이터를 작성하고, 일정 주기로 원본을 갱신하는 방식이다.

- 쓰기가 잦은 상황에 데이터베이스의 부하를 줄일 수 있습니다.
- 캐시의 데이터가 원본에 적용되기 전 문제가 발생하면 데이터 소실의 위험성이 존재합니다.
쓰기가 빈번하면서 읽기를 하는데 많은 양의 리소스가 소모되는 서비스에 적합하며, 데이터 정합성 확보된다.
캐시가 일종의 Queue 역할을 겸하게 되며, DB 쓰기 횟수 비용과 부하를 줄일 수 있지만, 데이터를 옮기기 전에 캐시 장애가 발생하면 데이터 소실이 발생할 수 있다는 단점이 존재한다. 하지만 오히려 반대로 데이터베이스에 장애가 발생하더라도 지속적인 서비스를 제공할 수 있도록 보장하기도 한다.
결론
캐싱을 사용해 성능 향상을 확실하게 이뤄내기 위해서는 적절한 전략의 선택이 중요하다. 캐시를 저장하는 시점은 자주 사용되며 자주 변경되지 않는 데이터를 기준으로 하는 것이 좋으며, 데이터의 소실 또는 정합성이 일정 부분 깨질 수 있으므로 중요한 정보, 민감 정보 등은 저장하지 않는 것이 좋다.
