개념
-
두개 이상의 DBMS 시스템을 Master/Slave로 나눠서 동일한 데이터를 저장하는 방식
-
Master
- 데이터 수정사항만 반영(Insert, Update, Delete) - 쓰기 담당
-
Slave
- master db를 복사
- Select(Read 할 때) 쿼리는 Slave에 요청하게 됨 - 읽기 담당
-
방식
-
비동기 방식으로 노드들 간의 데이터 동기화 (master- slave 간 데이터 무결성 검사를 하지 않음)
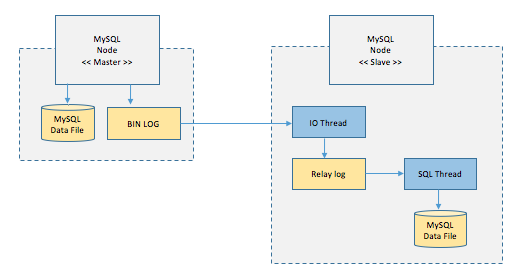
- master 노드에 쓰기 트랜잭션이 수행
- master 노드는 데이터를 저장하고 트랜잭션에 대한 로그를 파일에 기록 (BIN LOG)
- slave 노드의 IO Thread는 Master 노드의 로그파일(BIN LOG)를 파일(Replay Log)에 복사
- slave 노드의 SQL Thread는 파일(Replay Log)를 한줄 씩 읽으며 데이터를 저장
-
장점
- 서비스 운영시 DB Query의 절반 이상이 Select 문이 차지하고 있음. 이 경우 많은 Slave DB에 분산해서 요청하면 부하를 낮추고 빠른 Read를 할 수 있음
- 비동기 방식으로 운영되어 지연 시간이 거의 없음
- Master DB의 관여 없이 Slave의 DB를 통해 로그 읽을 수 있음
단점
- 노드들 간의 데이터 동기화가 보장되지 않아 일관성 있는 데이터를 얻지 못할 수 있다
- Master 노드가 다운되면 복구 및 대처가 까다롭다
[참고] 클러스터링(Clustering)
개념
- 여러개의 DB를 수평적인 구조로 구축 (master-slave구조의 수직적인 replication과 반대)
- 분산환경을 구성
- 동기방식으로 노드들 간의 데이터를 동기화
- Single point of Failure 문제를 해결하기 위해 등장
방식
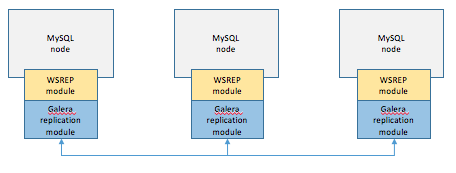
- 1개의 노드에 쓰기 트랜잭션이 수행한 후 commit 한다
- 실제 디스크에 쓰기 전에 다른 노드로 데이터의 복제 요청한다
- 다른 노드에서 복제 요청 수락했다는 신호(OK)를 받으면 디스크에 저장한다
장점
- 노드들 간의 데이터 동기화 하여 항상 일관성 있는 데이터를 얻을 수 있다
- SPOF 문제 대응 가능(한개 죽어도 장애 X)
단점
- 여러 노드들간의 데이터 동기화 하는 시간이 필요하므로 오래걸림(성능 떨어짐)
- 장애가 전파된 경우 처리가 까다로우며, 데이터 동기화를 하기 위해 스케일링의 한계가 있음
참고 자료
https://nesoy.github.io/articles/2018-02/Database-Replication
https://mangkyu.tistory.com/97

LLM Application을 개발중인 BackEnd 개발자