개념
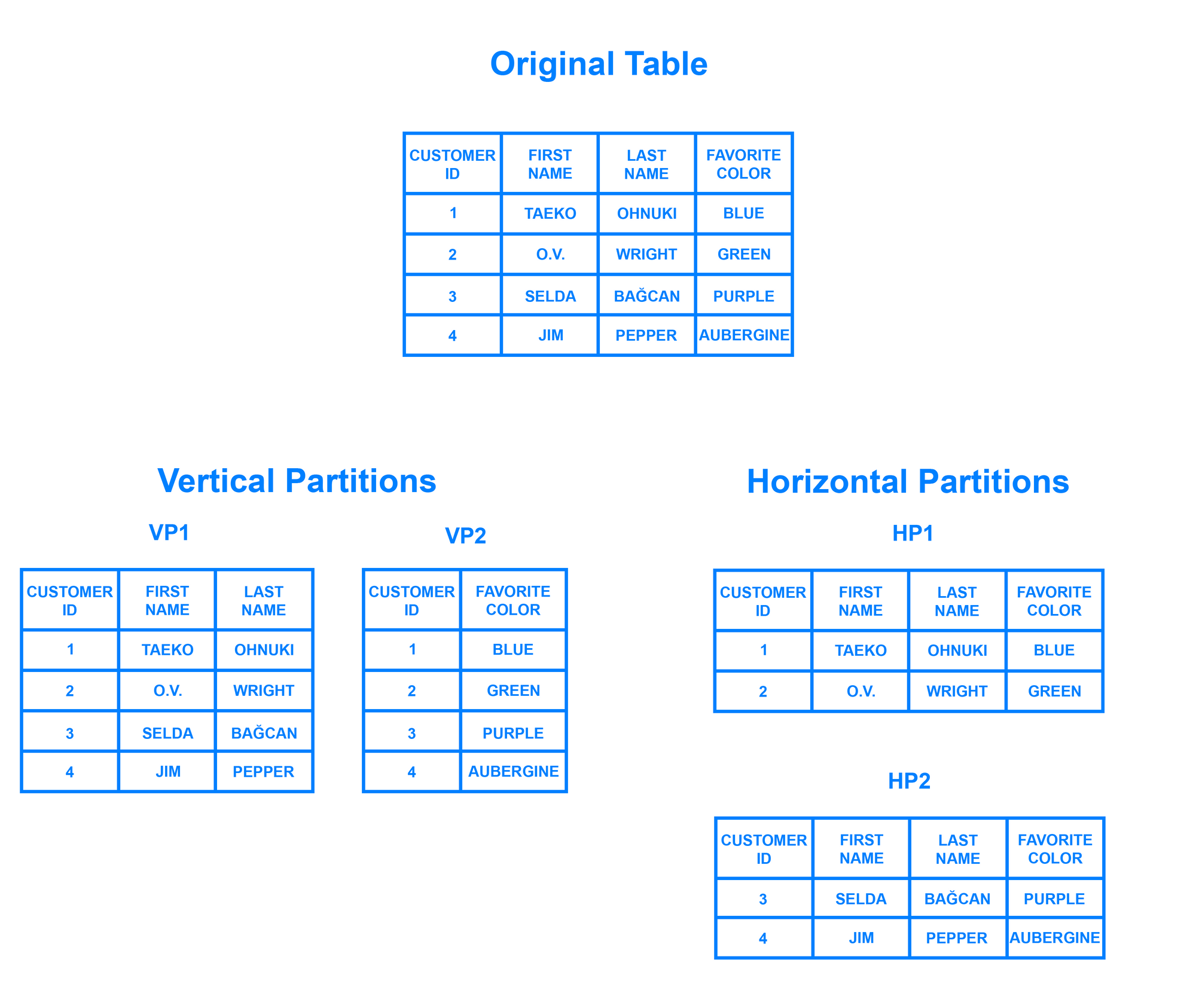
horizontal partitioning과 관련된 데이터 베이스 설계 패턴- 한 테이블의 row를 여러개의 서로 다른 테이블, 즉 파티션으로 분리
💡 vertical partitioning이라는 것도 있는데, 열 전체가 새로운 테이블로 분리되는 것을 말한다.
- sharding은 이처럼 데이터 베이스를 조각으로 나누는 것을 말하는데, 나누어진 블록들을 shards라고 한다.
- 나눠진 데이터를 logical shards라고 부르고, 이걸 나눠진 데이터 베이스 노드인 physical shards에 뿌려진다
💡 database node: 데이터 베이스의 인스턴스. main node는 쓰기, 그 외의 노드는 읽기 전용으로 사용
구현
- applcation level(어떤 shards에 읽기 쓰기를 전송하지 코드 단에서 정의) 에서 실행
- mongoDB나 MySQL과 같은 데이터베이스는 내장된 sharding 능력이 있어서 database level에서 바로 사용할수도 있다.
필요한 이유
- 하나의 DB 데이터가 늘어나면 용량 이슈도 생기고, 느려지는 CRUD는 서비스 성능에 영향을 줌
- DB 트래픽을 분산할 목적으로 Sharding을 고려해볼 수 있음
장점
- 수평적 확장(scale out)이 가능하다.
- 더 좋고 비싼 CPU, RAM으로 업그레이드 하는 수직적 상승이 아니라 여러 machine을 추가하는 방식으로 능력을 향상시킬 수 있다
- 쿼리 반응 속도를 빠르게 한다(여러 database node가 분산처리 가능)
- DB 장애가 전면 장애로 이어지지 않음(장애 발생시 단일 shard에만 영향을 줄 확률 높음, 나머지는 돌아감)
단점
- 잘못 사용했을 때 Risk가 있다(데이터 손상, 유실 등)
- 데이터가 한쪽 shards에 쏠려 sharding이 무의미해질 수 있다
- 한번 쪼개게 되면 다시 un-sharded 구조로 돌리기 어렵다.
- 모든 데이터 베이스 엔진에서 natively support 되지 않는다
구조
💡 라우팅을 위해 구분할 수 있는 유일한 키값(PK, shard key)이 있고, 올바른 DB를 찾을 수 있도록 라우팅이 되어야하고, 설정으로 쉽게 증설이 가능한 구조라는 전제 하에 구현 가능
1. Key Based Sharding (Modular sharding)
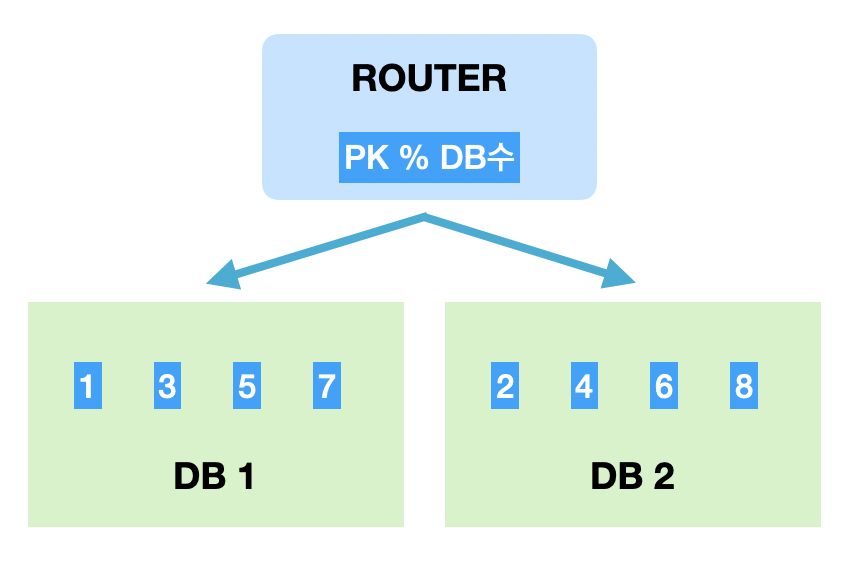
- PK를 모듈러 연산(PK % DB수)한 결과로 DB를 특정하는 방식
- 장점
- 데이터가 균일하게 분산된다
- 단점
- DB를 추가 증설하는 과정에서 이미 적재된 데이터의 재정렬이 필요. (DB서버수 늘어남 → hash 크기 변함→ hash key 변함 → 기존에 분배된 Data 분산 Rule 어긋남 → reSharding 필요)
- 활용
- 데이터의 양이 일정 수준에서 유지될 것으로 예상되는 데이터 성격을 가진 곳에 쓰자
- 데이터가 꾸준이 늘어날 수 있는 경우에도 적재속도가 빠르지 않다면 균일하게 분산되며 안정적으로 트래픽을 소화하는 모듈러 샤딩 가능
2. Range Sharding
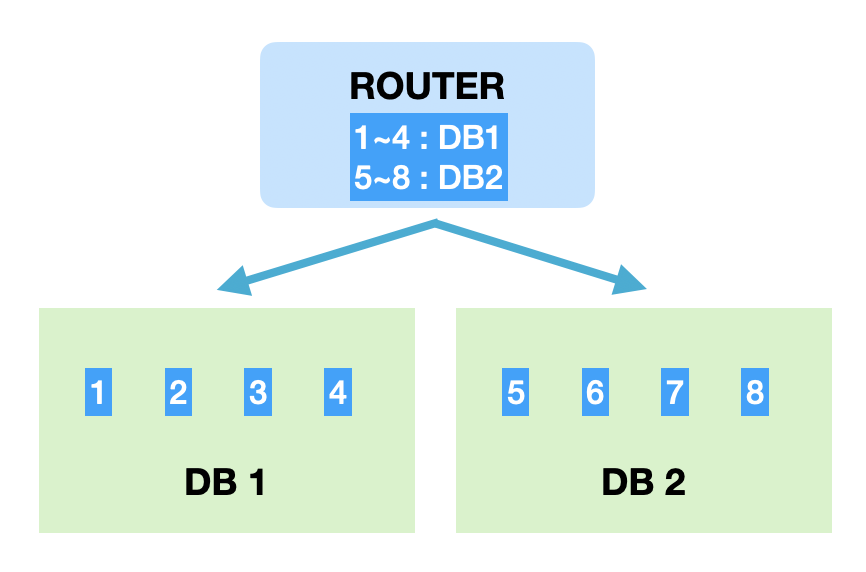
- PK 범위를 기준으로 DB를 특정하는 방식
- 장점
- 모듈러 샤딩에 비해 기본적으로 증설시 재정렬 비용이 들지 않음
- 일부 DB에 데이터가 몰릴 수 있음
- 활용
- 데이터가 급격하게 증가할 여지가 있는 경우(증설시 재정렬 안해도 되기 때문)
- 다만 활성유저가 몰린 DB로 트래픽이나 데이터가 몰릴 경우 부하가 심해지게 됨
- 이를 해결하기 위해 DB를 쪼개 재정렬 하는 작업이 필요하고, 반대로 트래픽이 저조한 DB는 통합 작업을 통해 유지비용을 아끼도록 관리해야한다는 점 유의
Router
- 모듈러와 레인지 방식이 어떤 기준으로 데이터를 분산시킬지에 대한 명세를 정의한 것이라면, 실제 분산된 DB에 접근하기 위한 논리적인 작업은 라우터가 담당
- 정확한 데이터 소스를 찾아 분산하도록 판단하는 클래스
참고 자료
https://techblog.woowahan.com/2687/
https://nesoy.github.io/articles/2018-05/Database-Shard
https://velog.io/@matisse/Database-sharding%EC%97%90-%EB%8C%80%ED%95%B4

LLM Application을 개발중인 BackEnd 개발자