1. EASE
Embarrassingly Shallow Autoencoders for Sparse Data: EASE 모델이 희소 데이터에 강한 이유
Embarrassingly Shallow AutoEncoders for Sparse Data
- Embarrassingly Shallow : hidden layer가 존재하지 않는 선형 모델
- Autoencoders : input 데이터를 encoded layer에 통과시켜서 latent space로 보내고, 이를 다시 decoded layer에 통과시켜서 재생성된 output이 얼마나 input과 유사한지 비교하면서 학습 진행
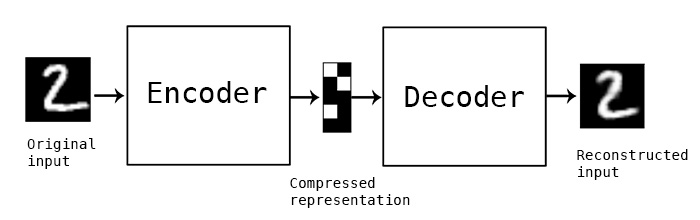
- 3가지 특징
- Hidden layer가 없다
- Convex한 목적함수가 closed form solution이다.
- 학습 파라미터의 대각 성분이 0이다
학습 과정
입력 데이터 행렬 X
아이템과 유저에 대한 implicit feedback인 interaction matrix
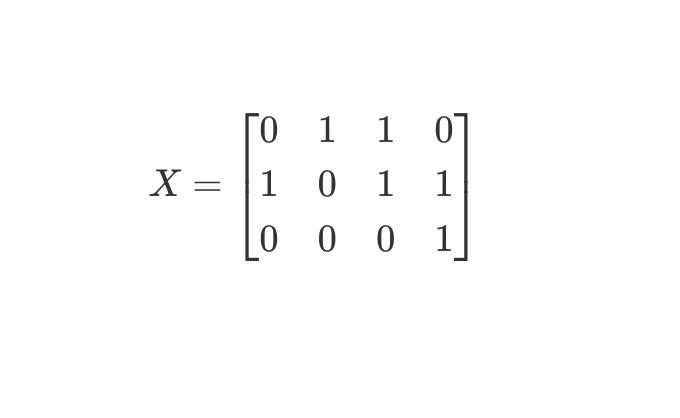
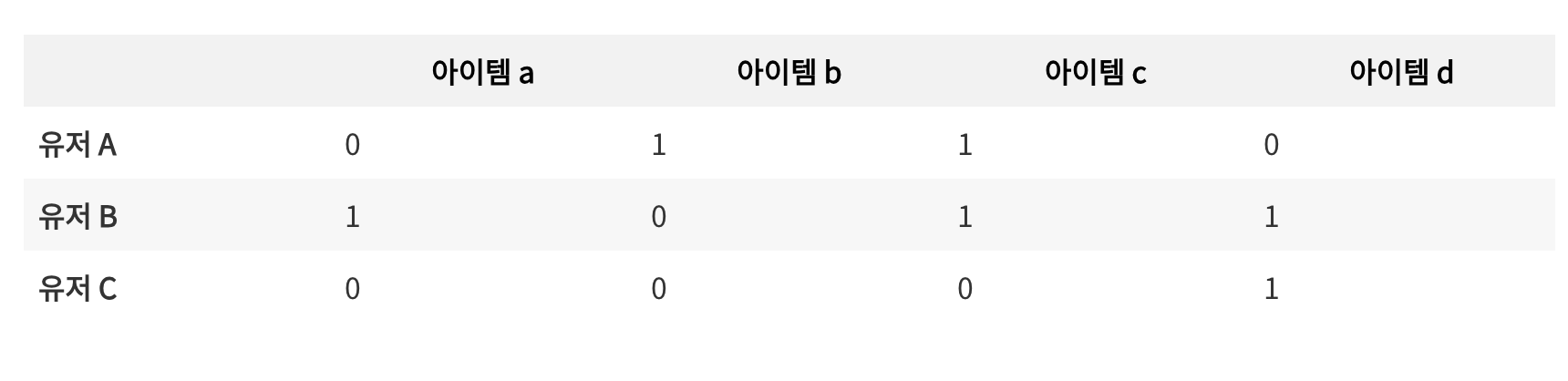
학습 파라미터 B
- 딱 1 개 → 아이템 간 아이템의 가중치 행렬 → 입력(X)과 행렬 곱 계산해서 구한 output을 입력(X)와 비교
- 이때 B의 대각성분이 0이어야 한다. (← 그렇지 않으면 B가 단위행렬이 되어버리기 때문)
출력 데이터 S
- 출력 S = 입력 X * 학습 파라미터 B
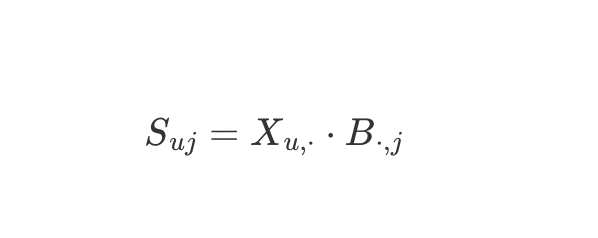
목적함수
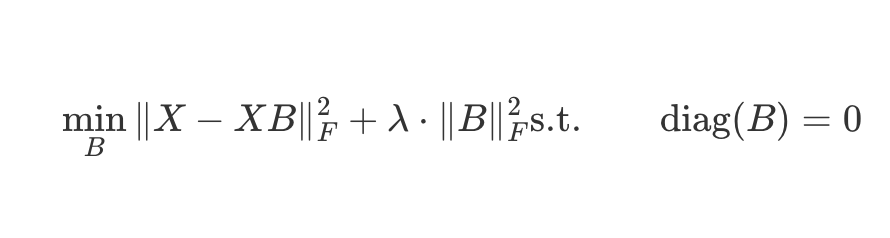
- 입력 X와 출력 XB의 차이를 가장 작게 하는 B를 구한다.
- 차이를 구할 때 행렬 버전의 L2-norm, 유클리드 거리인 Frobenius norm 사용
- 이때 과적합을 예방하기 이해 L2-norm 정규화 항을 더해준다. → 하이퍼파라미터는 람다만 생김
목적함수 최적화
- closed form(닫힌 형태)
- 유한개의 방정식을 사용하여 어떠한 해를 해석적으로 표현할 수 있는 종류의 문제
- x를 해라고 할 때 “x = … “ 꼴로 나타낼 수 있는 문제
- 등식 제약사항을 지닌 convex한 목적함수를 최적화하는 B → 라그랑주 승수법 기계학습 복습

- L의 도함수를 0으로 만드는 B를 찾는다 (→ 우변을 B로 미분했을 때 0이 되게 하는 B)
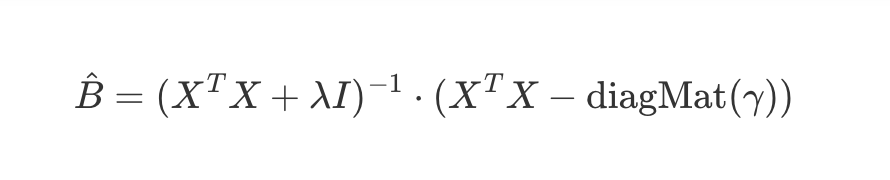
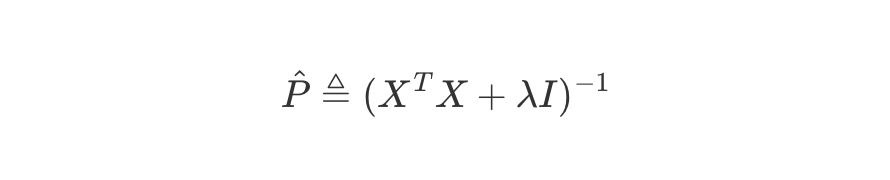
- 정리
- 식 정리하기 위해 충분히 큰 람다에 대해서 P_hat을 새로 정의
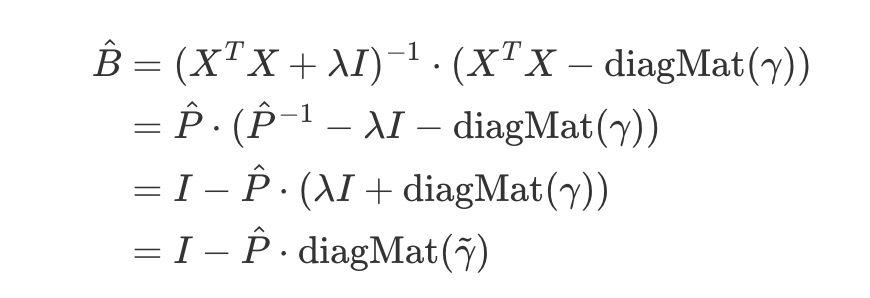
- P_hat을 치환해서 다시 위의 B_hat에 대한 식 정리
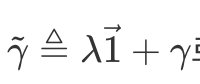
- 위에서 라그랑주 승수의 근사값을 정의해서 정리했음
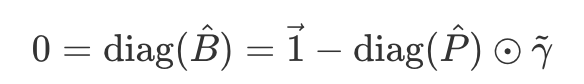
- 이 라그랑즈 승수 근사값은 **제약조건을 통해 결정 가능**
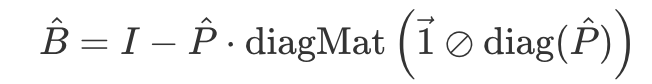
- 다시 B_hat에 치환하여 정리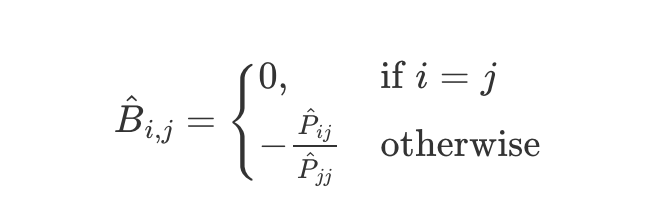
- 찐막 정리하면
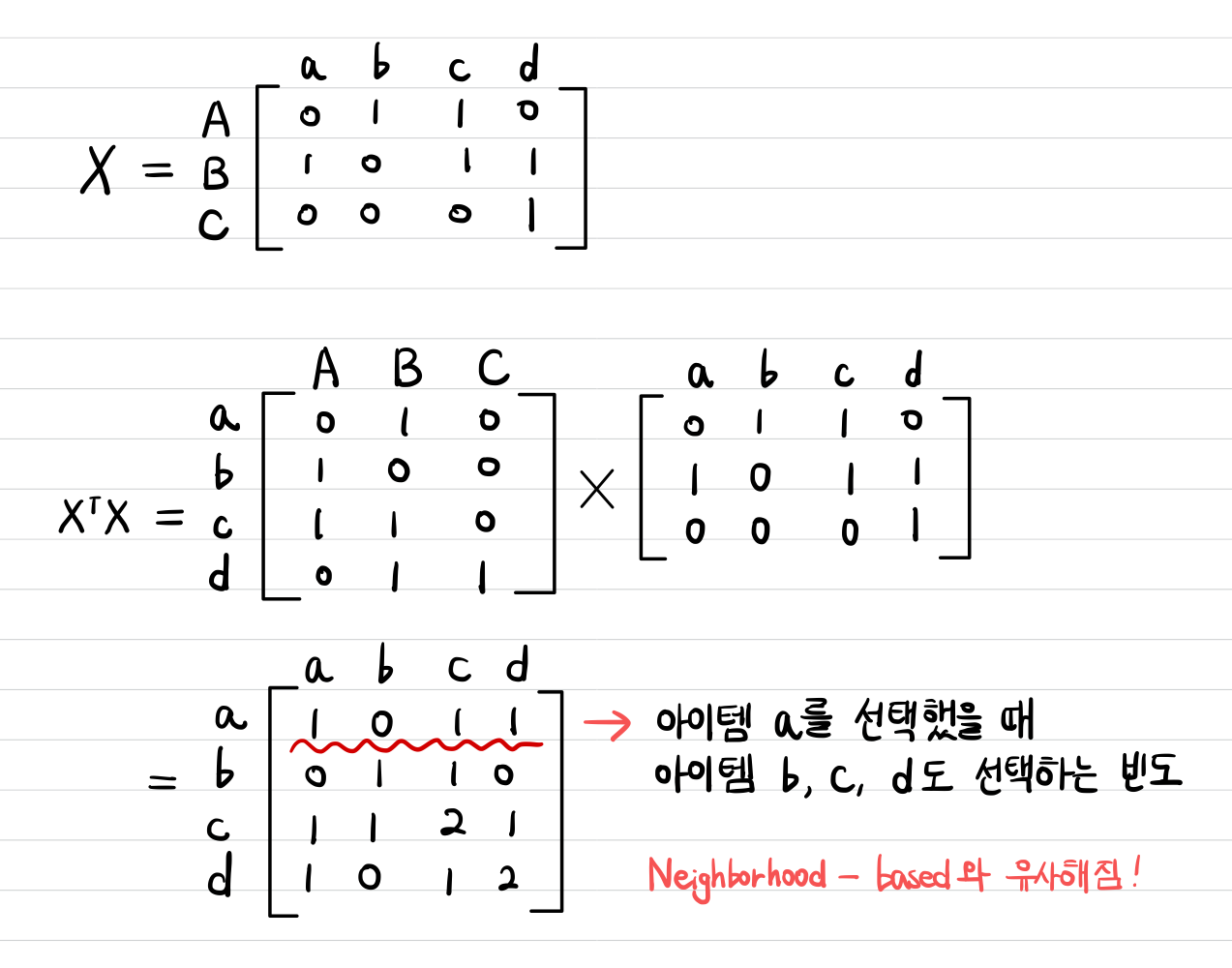
→ 즉 대각 원소가 아닌 원소들은 전부 P_hat에 의해 결정되므로, P_hat 수식을 살펴보면 람다는 하이퍼파라미터이므로 결국 G=X_T*X가 중요해진다.
→ 입력 데이터에 의해 B에 영향을 주는 것은 item-to-item matrix, gram matrix인 X_T*X
→ 이는 결국 co-occurence matrix가 되어서, **어떤 한 아이템이 유저에게 선택되었을 때, 다른 아이템도 같이 선택되었을 빈도가 어느 정도인지를 나타내는 행렬**
Gram matrix와 EASE의 관계
이 값이 두 가지 다른 요인에 의해 증가될 수 있다.
- 활동량이 증가한 유저로 인해 더 밀도가 높아진 데이터 X에 의해 G의 entry가 커진다.
- X의 유저 수가 증가함으로 인해서 G의 entry가 커진다.
→ 유저 수가 증가하면 데이터의 sparsity가 보완될 수 있다.
아이템이 유저보다 적을수록 연산 효율 증가
X의 크기는 |U| | I | 이지만, G의 크기는 | I | | I | 이기 때문
- 코드
### 학습 과정 import numpy as np # 딥 러닝 모델이 아니므로 nn.Module을 상속받을 필요가 없다. class EASE: def __init__(self, _lambda): self.B = None self._lambda = _lambda def train(self, X): G = X.T @ X # G = X'X diag_indices = list(range(G.shape[0])) G[diag_indices, diag_indices] += self._lambda # X'X + λI P = np.linalg.inv(G) # P = (X'X + λI)^(-1) self.B = P / -np.diag(P) # - P_{ij} / P_{jj} if i ≠ j min_dim = min(*self.B.shape) self.B[range(min_dim), range(min_dim)] = 0 # 대각행렬 원소만 0으로 만들어주기 위해 def forward(self, user_row): return user_row @ self.B### 입려 데이터에 대한 학습 과정 X = inputs # 학습 데이터 _lambda = 300 ease = EASE(_lambda) ease.train(X)### 입력 데이터에서 각 유저별로 활동 이력에 없는 아이템 중 어떠한 아이템을 보여주는 것이 좋을지 ### ranking을 구하는 inference 과정 result = ease.forward(X[:, :]) result[X.nonzero()] = -np.inf # 이미 어떤 한 유저가 클릭 또는 구매한 아이템 이력은 제외- 주의할 점) 입력 데이터 X에서 각 유저별로 feedback이 0인 아이템 중에서 유저가 원할 것 같은 아이템을 추천해야 하므로 이미 유저가 클릭 또는 구매한 아이템 원소 값은 제외해야 한다.
- RECJON에 쓰셨다던 코드
- 산타백준 레포 EASE 코드

가볍게 재밌던 거 기록해요

잘봤습니다.