✅ KHUDA 판다스 기초 스터디 4주차 : M~0 챕터 정리
M. 데이터 병합하기
- 왼쪽 열을 축으로 병합하기
- 오른쪽 열을 축으로 병합하기
- 공통 값만 병합하기
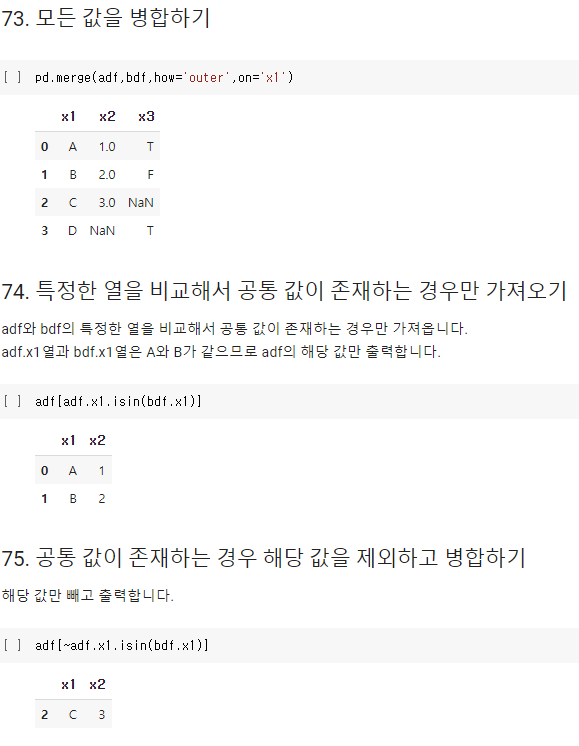
- 모든 값을 병합하기
: pandas.merge() 메서드를 활용한다.
- left, right 에 해당하는 DataFrame을 param으로 입력받는다.
- how 옵션 : {'left','right','outer',inner','cross'} 존재. default는 inner
- left는 기존객체, right는 병합할 객체, inner는 index의 교집합, outer는 index의 합집합, cross는 행렬곱
- on 옵션 : join을 적용할 column이나 index 종류를 명시.
- 특정한 열을 비교해서 공통 값이 존재하는 경우만 가져오기
- 공통 값이 존재하는 경우 해당 값을 제외하고 병합하기
: pandas.DataFrame.isin() 메서드를 사용한다.
- 각각의 요소가 DataFrame 혹은 Series에 존재하는지(True), 존재하지 않는지(False) 반환하여 Boolean 배열을 출력한다.
- '~'를 사용하면 True를 False로, False를 True로 뒤집어준다.
- 공통 값이 있는 것만 병합하기
- 모두 병합하기
- 어디서 병합되었는지 표시하기
: pandas.DataFrame.merge() 추가 옵션
- indicator 옵션 : True로 할 경우 병합이 완료된 객체에 추가로 열(_merge)을 하나 생성하여 병합 정보를 출력
- 원하는 병합만 남기기
- merge 칼럼 없애기
: pandas.DataFrame.query(expr, *, inplace=False) 메서드를 사용한다.
조건에 부합하는 데이터를 추출할 때 사용하는 query 함수는 6가지 기능을 포함하고 있다.
-비교 연산자(==, >,>=,<,<=,!=)
-in연산자(in,==,not in, !=)
-논리 연산자(and,or,not)
-외부 변수(또는 함수) 참조 연산 : 외부 변수명 또는 함수명 앞에 @를 붙여 사용
-인덱스 검색 : index로 검색하거나 인덱스 이름이 있다면 index.{name}으로 기입
-문자열 부분 검색(str.contains : 포함 , str.startwith : 특정 문자열로 시작, str.endswith : 특정 문자열로 끝)




N. 데이터 가공하기
- 행 전체를 한 칸 아래로 이동하기
- 행 전체를 한 칸 위로 이동하기
: DataFrame.shift(periods=1, freq=None, axis=0, fill_value)를 사용한다.
-periods 옵션 : 아래로 이동할 칸. 음수로 설정하면 위로 이동
-freq : 입력할 경우 인덱스가 freq 값만큼 이동
-axis : 열 또는 행 축 설정.
-fill_value : shift로 인해 생긴 결측치를 대체할 값
- 첫 행부터 누적해서 더하기
- 새 행과 이전 행을 비교하면서 최댓값 출력하기
- 새 행과 이전 행을 비교하면서 최솟값 출력하기
- 첫 행부터 누적해서 곱하기
: DataFrame.cumsum(axis=None, skipna=True, args,kwargs) : 누적합
DataFrame.cumprod(axis=None, skipna=True, args, kwargs) : 누적곱
DataFrame.cummax(axis=None, skipna=True, args, kwargs) : 누적 최대값
DataFrame.cummin(axis=None, skipna=True, args, kwargs) : 누적 최소값
-axis : 누적 값을 구할 축을 지정
-skipna : 결측치를 무시할지 여부


O. 그룹별로 집계하기
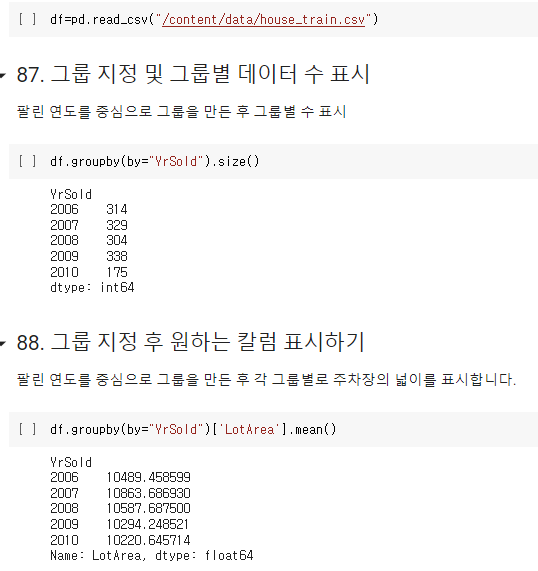
- 그룹 지정 및 그룹별 데이터 수 표시
- 그룹 지정 후 원하는 칼럼 표시하기
: pandas.DataFrame.groupby()
데이터를 그룹별로 분할하여 독립된 그룹에 대하여 별도로 데이터를 처리하거나 그룹별 통계량을 확인
-DataFrame.groupby(column).통계함수(mean, var 등) 형태로 그룹별 통계량을 확인할 수 있다
-df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=NoDefault.no_default, observed=False, dropna=True)
by : 그룹화할 내용
axis : 그룹화를 적용할 축
level : 멀티 인덱스의 경우 레벨을 지정
as_index : 그룹화할 내용을 인덱스로 할지 여부. False이면 기존 인덱스가 유지
dropna : 결측값을 계산에서 제외할지 여부
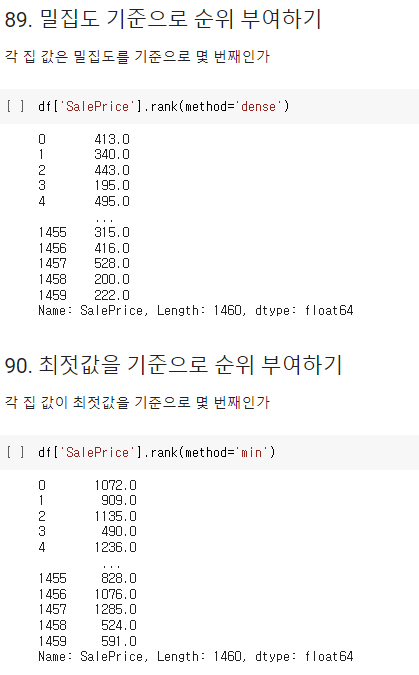
- 밀집도 기준으로 순위 부여하기
- 최젓값을 기준으로 순위 부여하기
- 순위를 비율로 표시하기
- 동일 순위에 대한 처리 방법 정하기
: pandas.DataFrame.rank()
-axis : 축 설정. 0은 index, 1은 column 기준
-method : 동점을 가진 데이터들의 순위를 매기는 방법.
'average' - 그룹의 평균 순위 부여
'min' - 그룹에서 가장 낮은 순위 부여
'max' - 그룹에서 가장 높은 순위 부여
'first' - 그룹에서 표시되는 순서대로 순위 부여
'dense' - min과 동일하지만 순위가 1씩 증가
-numeric_only = None : True로 설정할 경우 숫자 열만 순위를 매긴다.
-na_oprtion : NaN값 순위를 매기는 방법
'keep' - 기본 값으로 NaN의 순위에 NaN 부여
'top' - 그룹에서 가장 높은 순위 부여
'bottom' - 그룹에서 가장 낮은 순위 부여
-ascending : True면 오름차순, False는 내림차순
-pct : 반환 된 순위를 백분위 수 형식으로 표시할지 여부