E. 행과 열 추출하기
28. 특정 행과 열을 지정해 가져오기
# df.loc[가져올 행, 가져올 열]
df.loc[:,'a':'c'] # 모든 인덱스에서 a열부터 c열까지 가져오라는 의미29. 인덱스로 특정 행과 열 가져오기
# df.iloc[인덱스, 가져올 열]
df.iloc[0:3,[0,2]] # 0 인덱스부터 2 인덱스까자 0번째 열과 2번쨰 열 가져오라는 의미30. 특정 열에서 조건을 만족하는 행과 열 가져오기
# df.iloc[조건을 만족하는 특정 df, 가져올 행과 열]
df.loc[df['a']>5,['a','c']] # a열의 값이 5보다 큰 경우 a열과 c열을 출력하라는 의미31. 인덱스를 이용해 특정 조건을 만족하는 값 불러오기
- df.iat[row_number,colum_number] : 고유하게 정해지는 row_number, column_number로 위치를 지정해 가져올 수 있다.
#df.iat[가져올 값의 행, 가져올 값의 열]
df.iat[1,2] # 1번쨰 인덱스에서 2번째 열 값을 가져온다.cf. loc, iloc, at, iat 비교 정리
: iloc와 iat 앞에 붙은 i는 integer에서 따온 것, 즉 인덱스와 컬렴명을 사용하지 않고 대신 행과 컬럼의 위치에 대하여 정수를 사용하고 싶을 때 사용하면 된다.
- loc : 특정 범위의 데이터를 인덱싱
df.loc[['A', 'B', 'C'], 'english']- iloc
df.iloc[1:3, 0:2]- at : 딱 하나의 데이터를 인덱싱
df.at['C', 'english']- iat
df.iat[4, 0]F. 중복 데이터 다루기
사용할 데이터 프레임

32. 특정 열에 어떤 값이 몇 개 들어 있는지 알아보기
# values_counts() : 특정 열에 대하여 어떤 값이 몇 개 들어있는지
# 디폴트는 내림차순, 오름차순으로 하려면 ascending=True 옵션
df['a'].value_counts()33. 데이터 프레임의 행이 몇 개인지 세어 보기
len(df)34. 데이터 프레임의 행과 열이 몇 개인지 세어 보기
# (행, 열) 개수가 출력된다.
df.shape35. 특정 열에 유니크한 값이 몇 개인지 세어 보기
# 데이터에 고유값들의 '수'를 출력해주는 함수
# unique() 함수는 데이터의 고윳값들의 '종류'를 출력해주는 함수
df['a'].nunique()36. 데이터 프레임의 형태 한눈에 보기
# DataFrame 형태인 경우 열에 대한 요약, NaN값은 제외된다.
# 열 별 총 데이터 수, 평균, 표준편차, 최솟값, 백분위수 25%/50%/75%, 최댓값
df.describe()37. 중복된 값 제거하기
-
duplicated(subset=None, keep='first') : 중복데이터가 있는 행에 True로 마크하여 boolean 형태의 Series를 반환
-keep : {'first'/'last'/False} 어떤 데이터를 제외하고 나머지 중복 데이터를 True로 마킹할지. first면 첫번쨰로 발견된 중복 데이터를 제외하고, last면 마지막으로 발견된 중복 데이터를 제외한다. False면 모든 중복 데이터를 True로 마킹한다. -
drop_duplicates(subset=None, keep='first', inplace=False,ignore_index=False) : 중복 데이터를 제거한 DataFrame을 반환
-keep : {'first'/'last'/False} 중복 제거를 할 때 남길 행. first면 첫 값을 남기고, last면 마지막 값을 남긴다. False면 모든 중복데이터를 삭제한다.
-inplace : 원본 데이터를 변경할 것인지, 수정된 복사본을 반환할 것인지 여부
-ignore_index : 원래 index를 무시할 지 여부. True면 0~n으로 부여
df=df.drop_duplicates()G. 데이터 파악하기
38. 각 열의 합 보기
df.sum()39. 각 열의 값이 모두 몇 개인지 보기
df.count()40. 각 열의 중간 값 보기
df.median()41. 특정 열의 평균값 보기
df['b'].mean()42. 각 열의 25%, 75%에 해당하는 수 보기
df.quantile([0.25,0.75])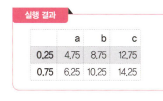
43. 각 열의 최솟값 보기
df.min()44. 각 열의 최댓값 보기
df.max()45. 각 열의 표준편차 보기
df.std()46. 데이터 프레임 각 값에 일괄 함수 적용하기
- DataFrame.apply(func, axis=0, raw=False, result_type=None, args=()
-axis : 0이면 행(row), 1이면 열(column)에 함수를 적용한다.
-raw : True면 ndarray, False면 Series
-result_type : 반환 값의 형태
import numpy as np
df.apply(np.sqrt) # 제곱근 구하기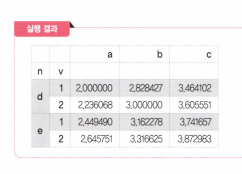
H. 결측치 다루기
사용할 데이터 프레임( NaN 값은 np.nan으로 하면 된다)
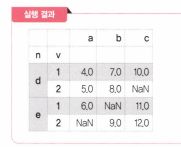
47. null 값인지 확인하기
# NaN값이면 True, NaN값이 아니면 False인 boolean을 반환
pd.isnull(df)
48. null 값이 아닌지 확인하기
# NaN값이 아니면 True, NaN값이면 False인 boolean을 반환
pd.notnull(df)
49. null 값이 있는 행 삭제하기
- DataFrame.dropna(axis=0/1, how='any'/'all', subset=[col1, col2, ...], inplace=True/False)
-axis : 0이면 row(행)를, 1이면 column(열)을 제거한다.
-how : any면 NaN값이 1갬나 있어도 drop한다. all이면 모두 NaN이어야 drop한다.
-inplace : True면 DataFrame 자체에 적용. False면 DataFrame은 그대로 두고 적용한 DataFrame을 return
-subset : 명시한 subset에 적힌 column 값이 대해서만 dropna를 진행한다.
df_notnull=df.dropna()50. null 값을 특정 값으로 대체하기

df_fillna=df.fillna(13)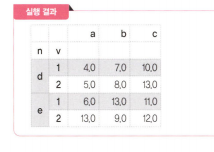
51. null 값을 특정 계산 결과로 대체하기
# a열의 평균값으로 대체
df_fillna_mean=df.fillna(df['a'].mean())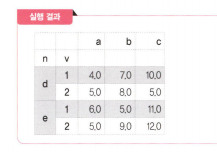

가볍게 재밌던 거 기록해요