✅ KHUDA 판다스 기초 스터디 2주차 : I~L 챕터 정리
I. 새로운 열 만들기
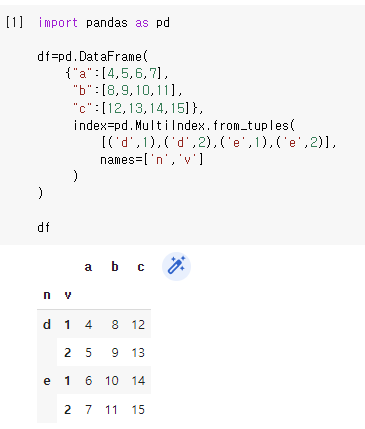
- DataFrame의 열끼리 더한 것을 df['열이름']에 할당하면 각 값들을 더한 결과로 이뤄진 새 열을 만들 수 있다.
# 52. 조건에 맞는 새로운 열 만들기
df['sum']=df['a']+df['b']+df['c']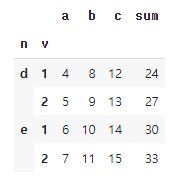
- assign 메서드는 DataFrame에 새 열을 할당하는 메서드. 이름이 같을 경우 덮어씌운다. lambda를 사용할 수도 있고, 그냥 수식을 넣어도 된다. 쉼표로 구분하면서 여러 개를 할당할 수도 있다.
# 53. assign()을 이용해 조건에 맞는 새 열 만들기
# a열, b열, c열의 값을 모두 더해 d열을 만들어 줍니다.
df=df.assign(multiply=lambda df: df['a']*df['b']*df['c'])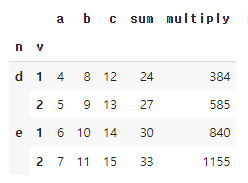
- qcut 메서드는 같은 크기의 그룹으로 만든다. 표본 변위치를 기반으로 데이터를 나누어, 적당한 같은 '크기'의 그룹으로 나눌 수 있다.
# 54. 숫자형 데이터를 구간으로 나누기
# a열을 두 개로 나누어 각각 새롭게 레이블을 만들라는 의미입니다.
df['qcut']=pd.qcut(df['a'],2,labels=["600이하","600이상"])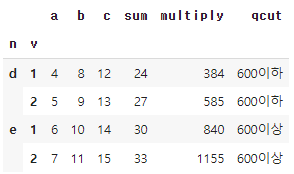
- clip 메서드는 Series나 DataFrame에 대해서 요소들의 범위를 제한하는 메서드. 상한선과 하한선을 임계값으로 정해서 임계값 밖의 값을 임계값으로 변경한다. axis 옵션으로 기준을 정할 수 있다.
# 55. 기준 값 이하와 이상을 모두 통일시키기
# a열에서 5 이하는 모두 5로, 6 이상은 모두 6으로 변환합니다.
df['clip']=df['a'].clip(lower=5,upper=6)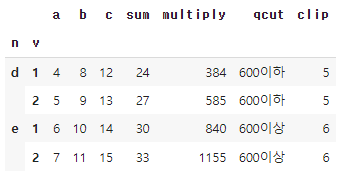
# 56. 최댓값 불러오기
df.max(axis=0) # axis=0은 행과 행 비교, axis=1은 열과 열 비교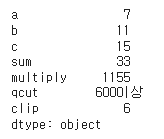
# 57. 최솟값 불러오기
df.min(axis=0)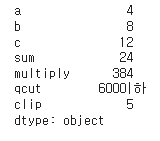
J. 행과 열 변환하기
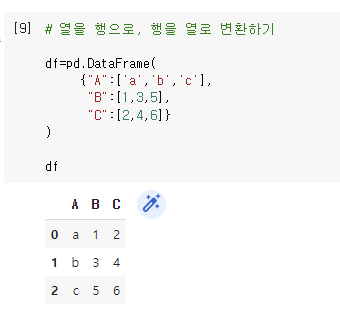
- melt 메서드는 데이터를 재구조화(reshaping)한다. ID 변수를 기준으로 원래 데이터셋에 있던 여러 개의 칼럼 이름을 variable 칼럼에 위에서 아래로 길게 쌓아놓고, value 칼럼에 ID와 variable에 해당하는 값을 넣어준다.
# 58. 모든 열을 행으로 변환하기
pd.melt(df)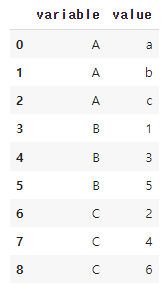
# 59. 하나의 열만 행으로 이동시키기
pd.melt(df,id_vars=['A'],value_vars=['B'] ) # A열만 그대로, B열은 행으로 이동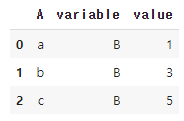
# 60. 여러 개의 열을 행으로 이동시키기
# A열만 그대로, B열과 C열은 행으로 이동시킵니다.
df_melt=pd.melt(df,id_vars=['A'],value_vars=['B','C'])
df_melt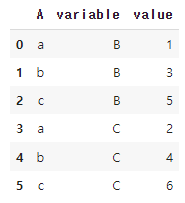
- pivot 메서드는 데이터의 열을 기준으로 피벗테이블로 변환시키는 메서드다.
# 61. 특정 열의 값을 기준으로 새로운 열 만들기
# A열을 새로운 인덱스로 만들고, B열과 C열은 이에 따라 정리합니다.
df_pivot=df_melt.pivot(index='A',columns='variable',values='value')
df_pivot
# 62. 원래 데이터 형태로 되돌리기
df_origin=df_pivot.reset_index() # 인덱스를 리셋합니다.
df_origin.columns.name=None # 인덱스 열의 이름을 초기화합니다.
df_origin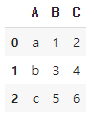
K. 시리즈 데이터 연결하기

- concat 메서드는 데이터의 속성 형태가 동일한 데이터셋끼리 합칠 때 사용한다.
# 63. 시리즈 데이터 합치기
pd.concat([s1,s2])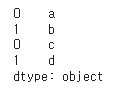
# 64. 데이터를 병합할 때 새로운 인덱스 만들기
pd.concat([s1,s2],ignore_index=True)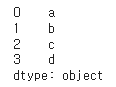
# 65. 계층적 인덱스를 추가하고 열 이름 지정하기
pd.concat([s1,s2],
keys=['s1','s2'],
names=['Series name','Row ID'])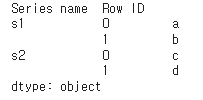
L. 데이터 프레임 연결하기

# 66. 데이터 프레임 합치기
pd.concat([df1,df2])
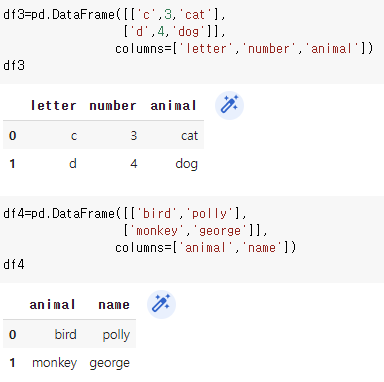
# 67. 열의 수가 다른 두 데이터 프레임 합치기
pd.concat([df1,df3])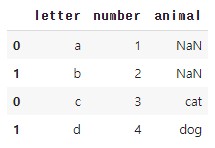
- join 옵션에는 outer(합집합), inner(교집합)이 있다.
# 68. 함께 공유하는 열만 합치기
pd.concat([df1,df3],join="inner")
- axis는 0은 위+아래로 합치기, 1은 왼쪽+오른쪽으로 합치기
# 69. 열 이름이 서로 다른 데이터 합치기
pd.concat([df1,df4],axis=1)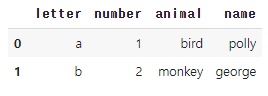

가볍게 재밌던 거 기록해요