데이터가 쏟아지는 요즘, “어떻게 다 모으고, 어떻게 잘 써먹을까?” 하는 고민이 많다.
이에, Kafka랑 Spark를 활용해서 실시간 데이터레이크(Realtime Datalake)를 어떻게 구성하는지 정리해본다.
데이터레이크란?
- 정형 데이터(엑셀, RDB 테이블)
- 반정형 데이터(JSON, 로그)
- 비정형 데이터(이미지, 텍스트, 음성)
이걸 원본 그대로 저장하고, 필요할 때 꺼내 쓰는 구조다.
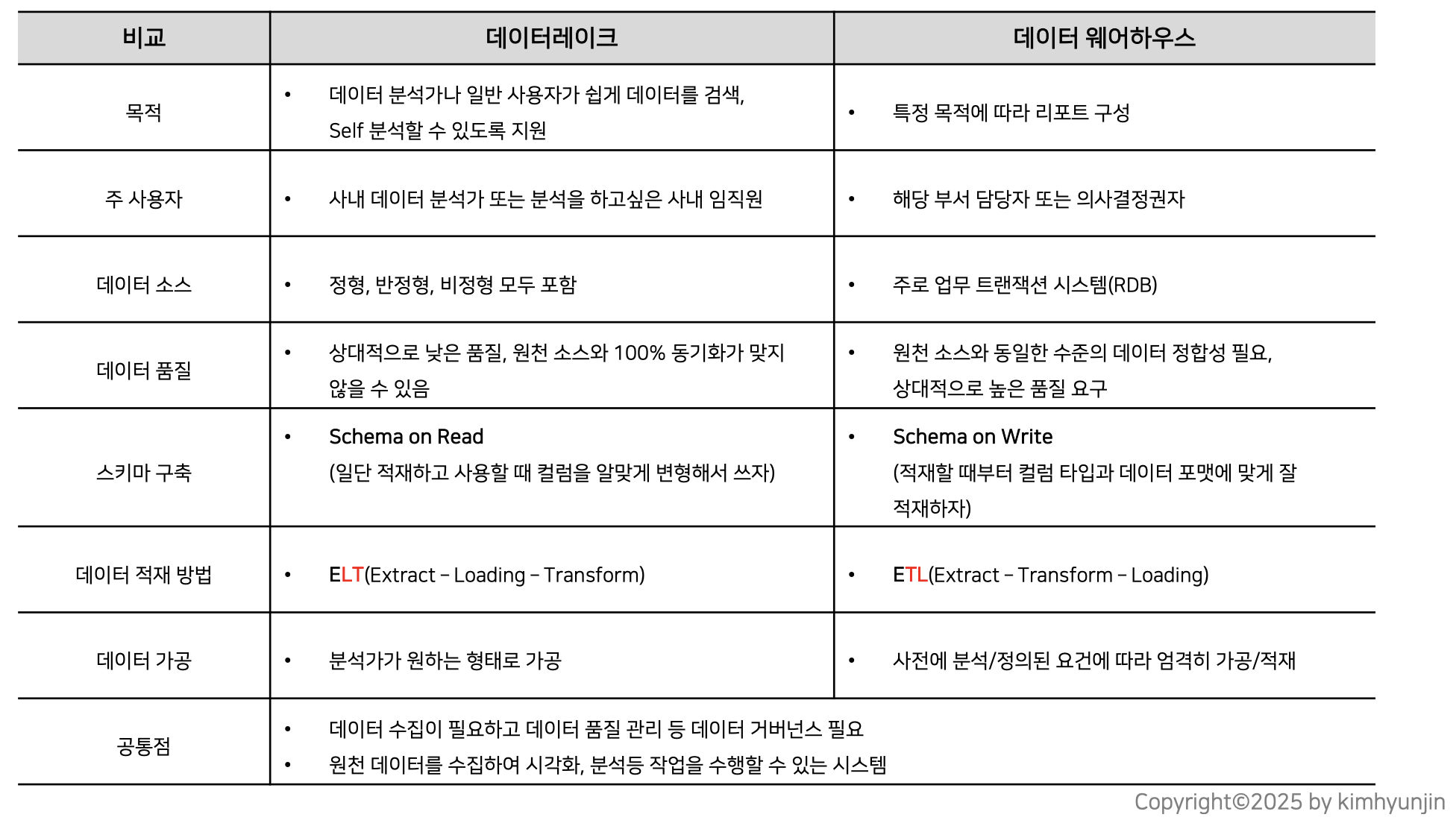
📌 차이점 한눈에 보기
- Data Warehouse(DW) → Schema on Write, 깔끔하고 품질 좋은 데이터만 적재, 보고용에 강함
- Data Lake → Schema on Read, 원본 데이터 다 적재, 유연하고 빠르게 분석 가능
최근엔 두 장점을 합친 Lakehouse라는 개념도 많이 언급된다.
왜 실시간 데이터레이크?
옛날 DW 기반 리포팅은 하루 단위로 데이터 뽑아도 충분했다.
근데 요즘은 다르다.
- 이커머스 → 고객 행동 로그 기반 실시간 추천
- 금융 → 거래 패턴을 바로 탐지해야 함 (사기 방지)
- 제조 → 설비 센서 데이터로 즉각적인 이상 징후 감지
실시간 분석 없이는 경쟁력이 떨어진다.
그래서 Kafka + Spark 조합이 나온다.
Kafka: 데이터 스트림 입구
Kafka는 분산 메시징 플랫폼이다.
수많은 데이터 소스(웹 로그, IoT 기기, DB 변경 로그 등)에서 데이터를 받아서, 브로커에 실시간으로 쌓는다.
- Producer → Kafka Topic → Consumer
- 높은 처리량 + 안정적인 내결함성 + 확장성
👉 데이터레이크로 들어오는 데이터 파이프라인의 관문 역할을 한다고 보면 된다.
Spark: 실시간 데이터 엔진
Spark는 원래 배치 처리용으로 유명했지만, Structured Streaming 덕분에 실시간 데이터 처리도 가능하다.
- Kafka에서 스트림 데이터 구독
- 필터링, 집계, 머신러닝 모델 적용
- 처리된 결과를 다시 DB, S3, 대시보드로 내보내기
👉 Spark는 단순히 “저장”이 아니라 “데이터에서 인사이트 뽑아내는 엔진”이다.
데이터레이크 기본 구성 요소
실시간이라고 해서 구조가 크게 달라지진 않는다. 데이터레이크는 보통 이렇게 구성된다:
저장소 (Storage)
- Schema on Read, 원본 그대로 저장
- AWS S3, GCP GCS, Azure Blob Storage
포털 (Portal)
- 분석가/사내 유저들이 데이터 검색하고 Self-Service BI 가능
쿼리 엔진 (Query Engine)
- Hive, Presto, Athena, BigQuery 등 SQL 기반 분석
BI / OLAP
- Tableau, Power BI, Qlik → 시각화 & 대시보드
데이터 거버넌스
- 데이터 품질 관리, 카탈로그, 리니지 추적, 보안
[데이터 소스]
↓ (로그/이벤트/센서)
Kafka (실시간 수집)
↓
Spark Structured Streaming (실시간 처리/분석)
↓
데이터레이크 저장소 (S3, GCS 등)
↓
쿼리 엔진 (Athena, BigQuery 등)
↓
BI & Dashboard (Tableau, Power BI)강의[Kafka & Spark 활용한 Realtime Datalake] 중에 작성한 글

Transitioning from UX to data science, I explore the intersection of service & data to unlock hidden value and make meaningful predictions.