일배치, 주배치, 월배치와 같은 배치 수집 이 실시간 수집이 필요한 경우는 대표적으로 람다(Lamda)아키텍처와 카파(Kappa)아키텍처를 참조하면 좋다.
람다 아키텍처
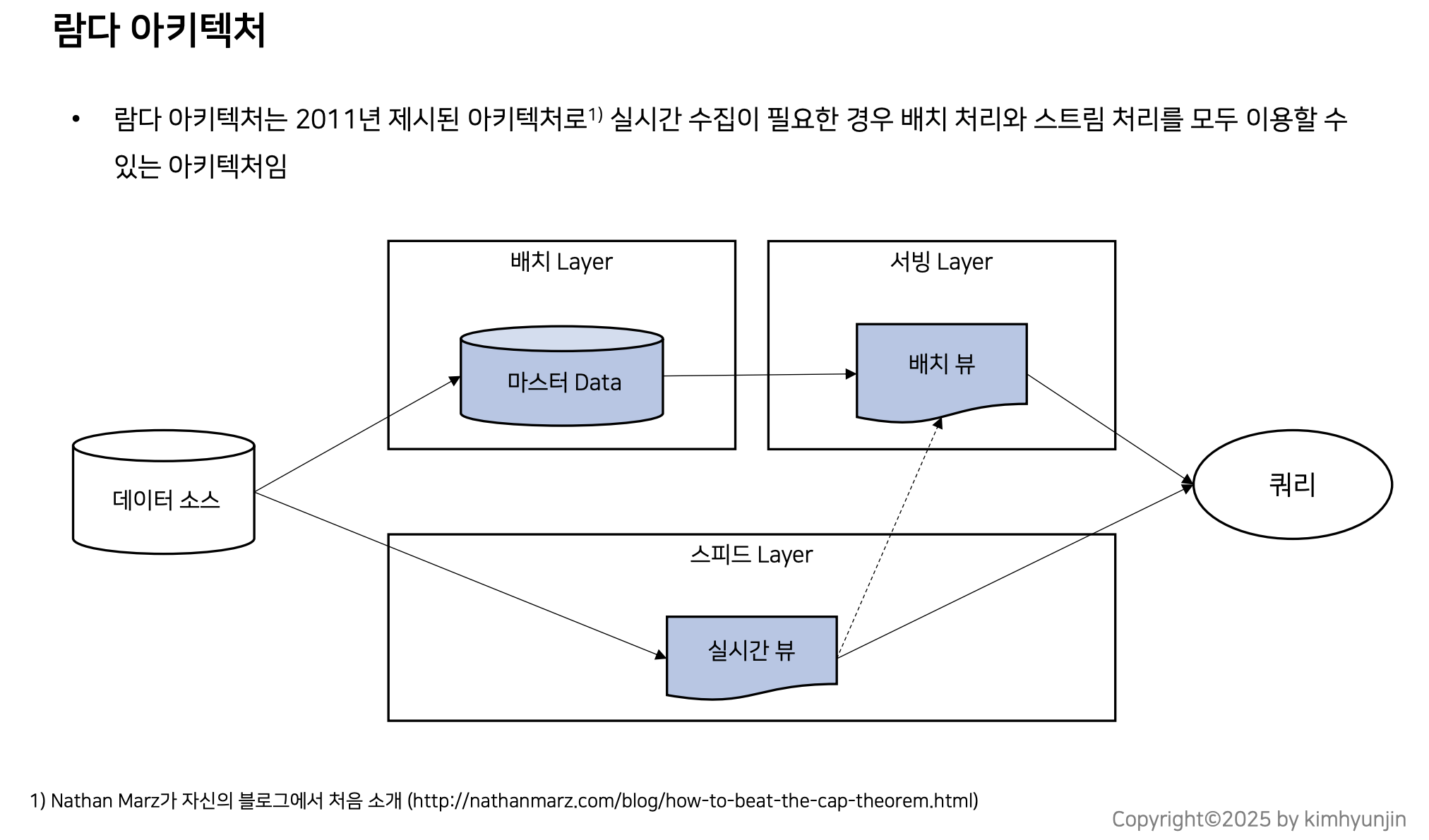
1)배치 Layer
마스터 정보를 배치 뷰에 제공하기 위해 데이터 전처리 수행 및 정제 데이터 보관하는 영역
ex)고객 마스터 테이블,제품 마스터 테이블, 고객/기간별 주문금액을 집계해놓은 테이블 등
• 하루에 1~2회 테이블 갱신
2)서빙 Layer
배치 Layer에 저장된 데이터를 빠르게 보여주기 위한 서비스 계층으로 사용자가 쿼리할 수 있도록 하며, 필요 시 스피드 Layer에 있는 데이터를 결합하기도 함
3)스피드 Layer
배치 Layer에 저장된 데이터는 과거(가장 최신 D-1기준) 데이터에 비해 스피드 Layer에는 당일 데이터가 저장,정제하여 저장하는 공간
ex) 오늘 고객별 주문금액을 집계해놓은 데이터
• 람다 아키텍처는 컨셉만 제공할 뿐 각 Layer 에 어떤 도구를 활용해야 하는지는 명시하지 않음
람다 아키텍처는 언제 사용하면 좋을까?
하루 1~2회 업데이트되는 마스터 테이블을 참조하면서 실시간으로 입력되는 데이터와 결합하여 쿼리/분석하고자하는 경우
람다 아키텍처의 단점
배치 뷰,실시간 뷰 라는 2개의 파이프라인을 각각 유지해야하므로, 관리 부담,복잡도 증가한다. 이에 카파 아키텍처가 등장하는 계기가 된다.
카파 아키텍처
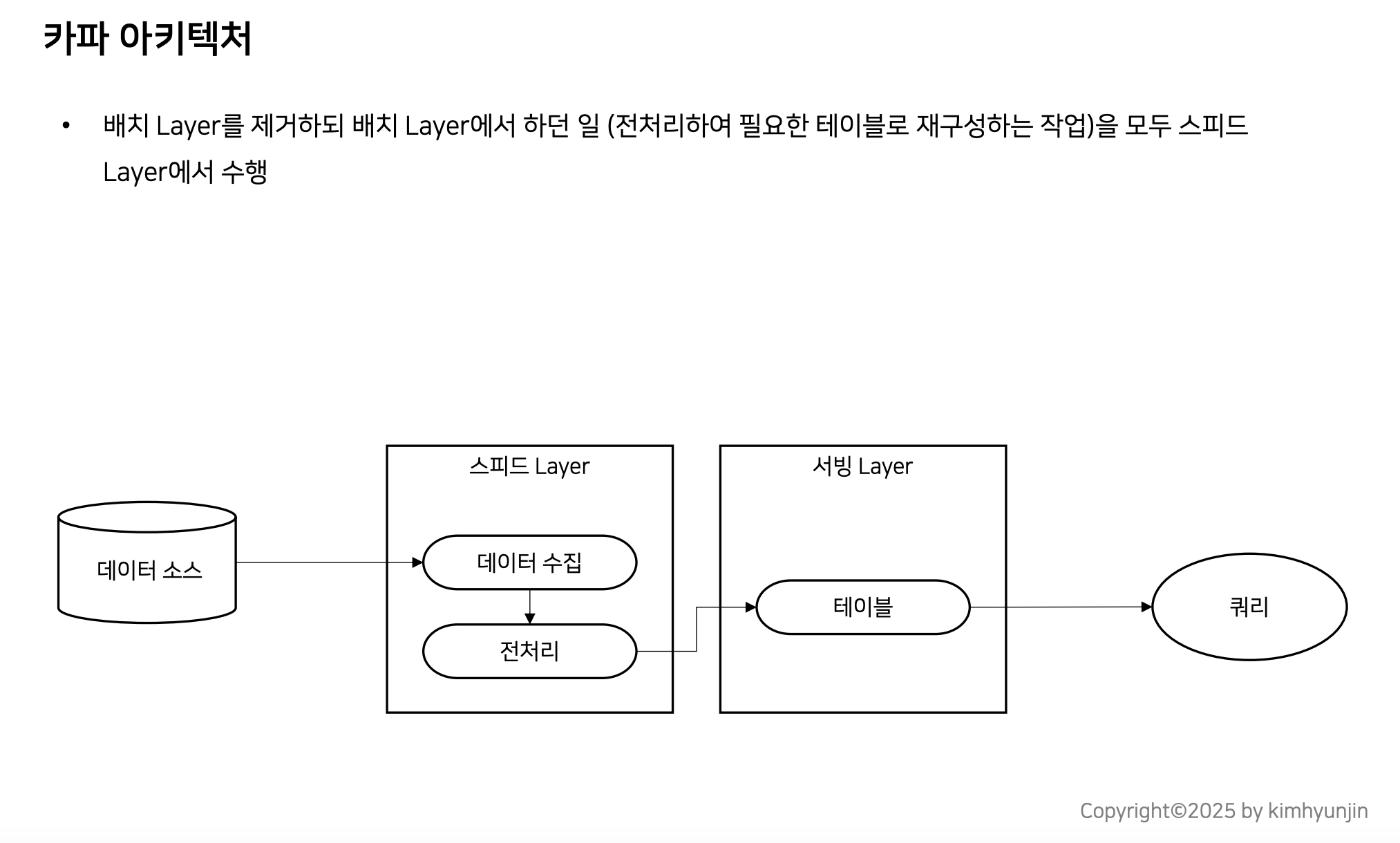 위 이미지처럼 배치 Layer가 스피드 Layer으로 흡수 통합되어, 관리 포인트인 Layer 하나가 줄었다.
위 이미지처럼 배치 Layer가 스피드 Layer으로 흡수 통합되어, 관리 포인트인 Layer 하나가 줄었다.
카파 아키텍처에서 데이터 소스란?
데이터 소스는 메시지 큐를 의미함.메시지 큐에는 여러 솔루션이 존재하지만 카파 아키텍처에서 데이터 소스는 곧 KafkaCluster를 의미함.
• 카파 아키텍처에서 모든 데이터는 Kafka로 수집함을 의미
• 그러나 데이터레이크 구성시 모든 소스를 kafka Cluster만으로 수집하는 경우는 많지 않으며 일반적으로 배치 파이프라인도 많이 활용
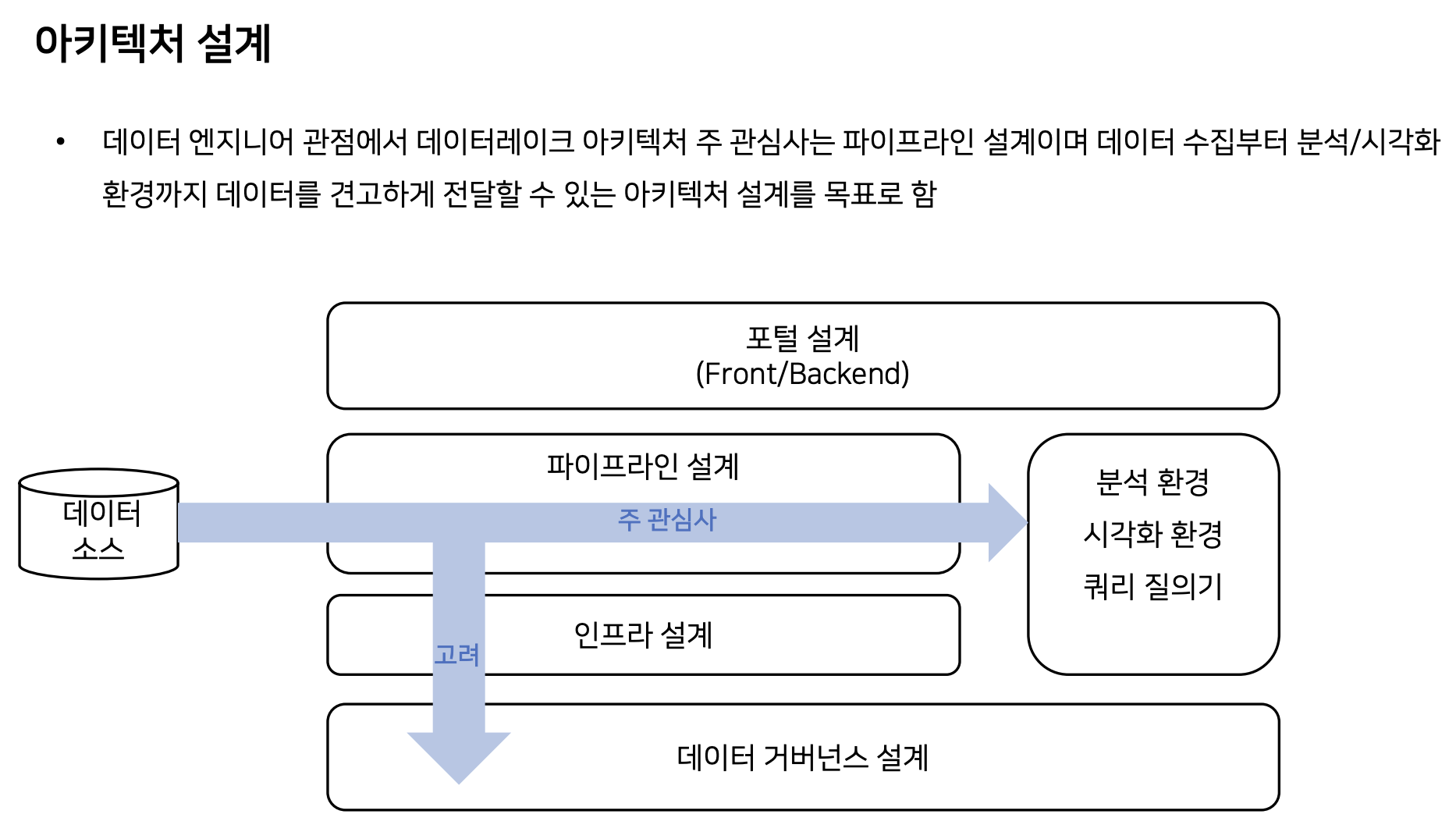
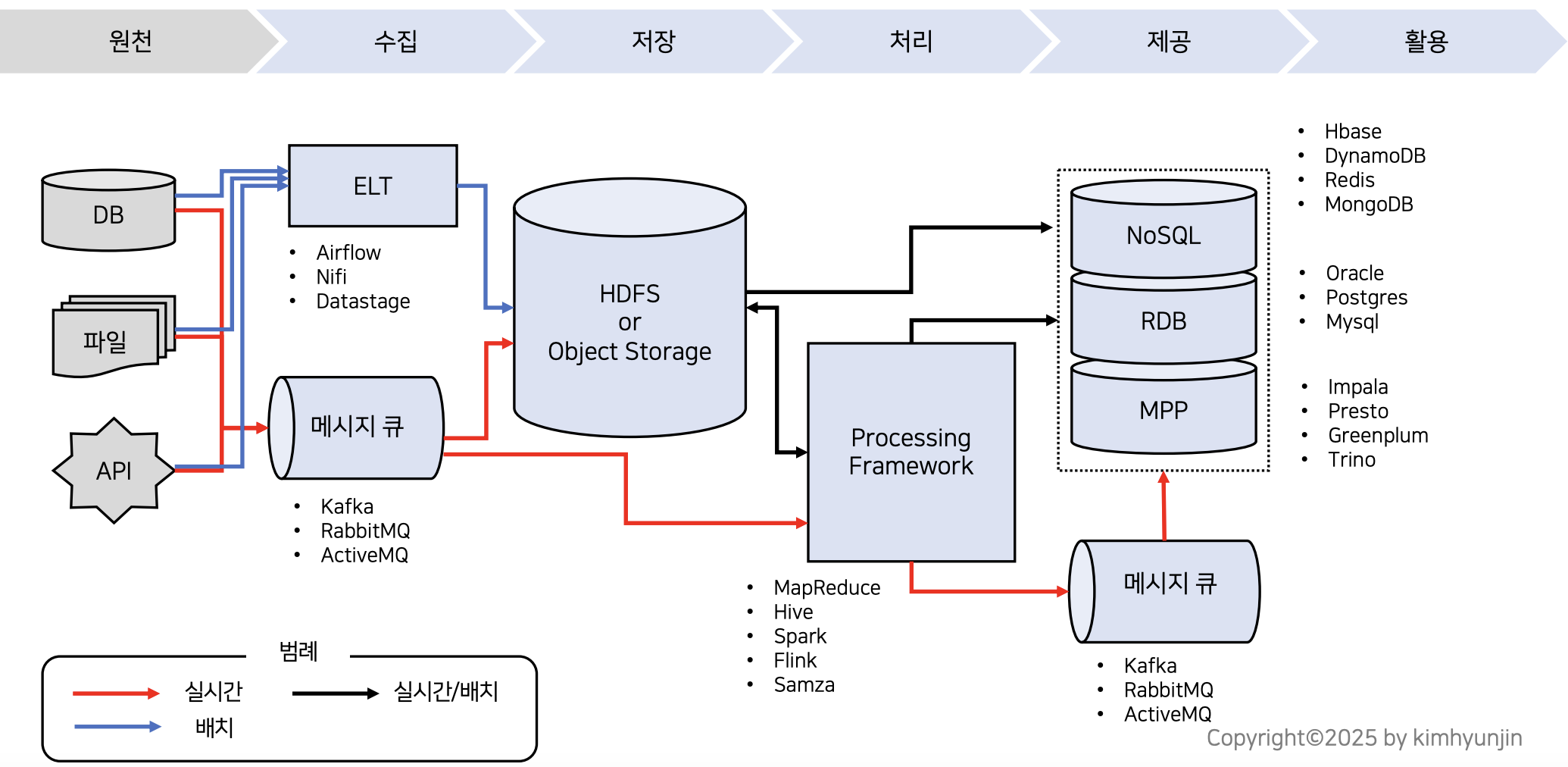
General Architecture
ELT에서는 배치성 수집을, 메시지 큐에서는 실시간성 수집을 한다.
하기와 같이 다양한 솔루션을 선정할 수 있다. 솔루션은 아래 이미지는 예시며, 예를 들어 trino가 활용단계에서만 사용할 수 있는 건 아니다.
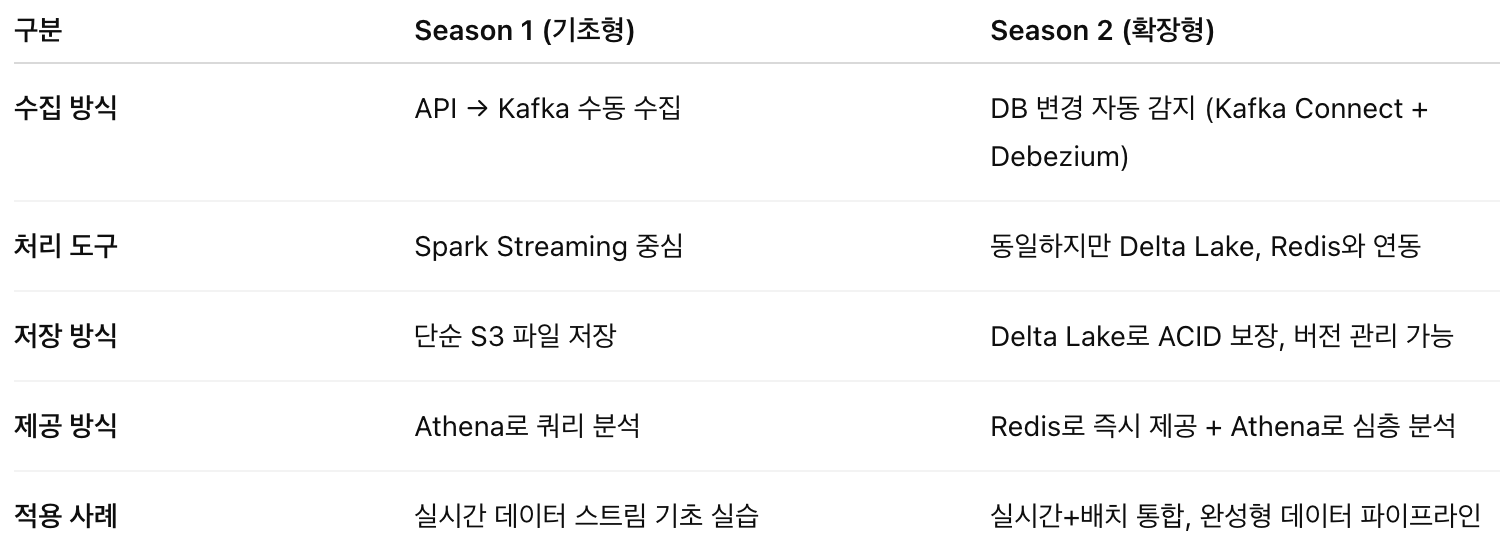
Kafka, Spark Streaming vs Kafka Connect & Redis & Deltalake 활용한 파이프라인 구축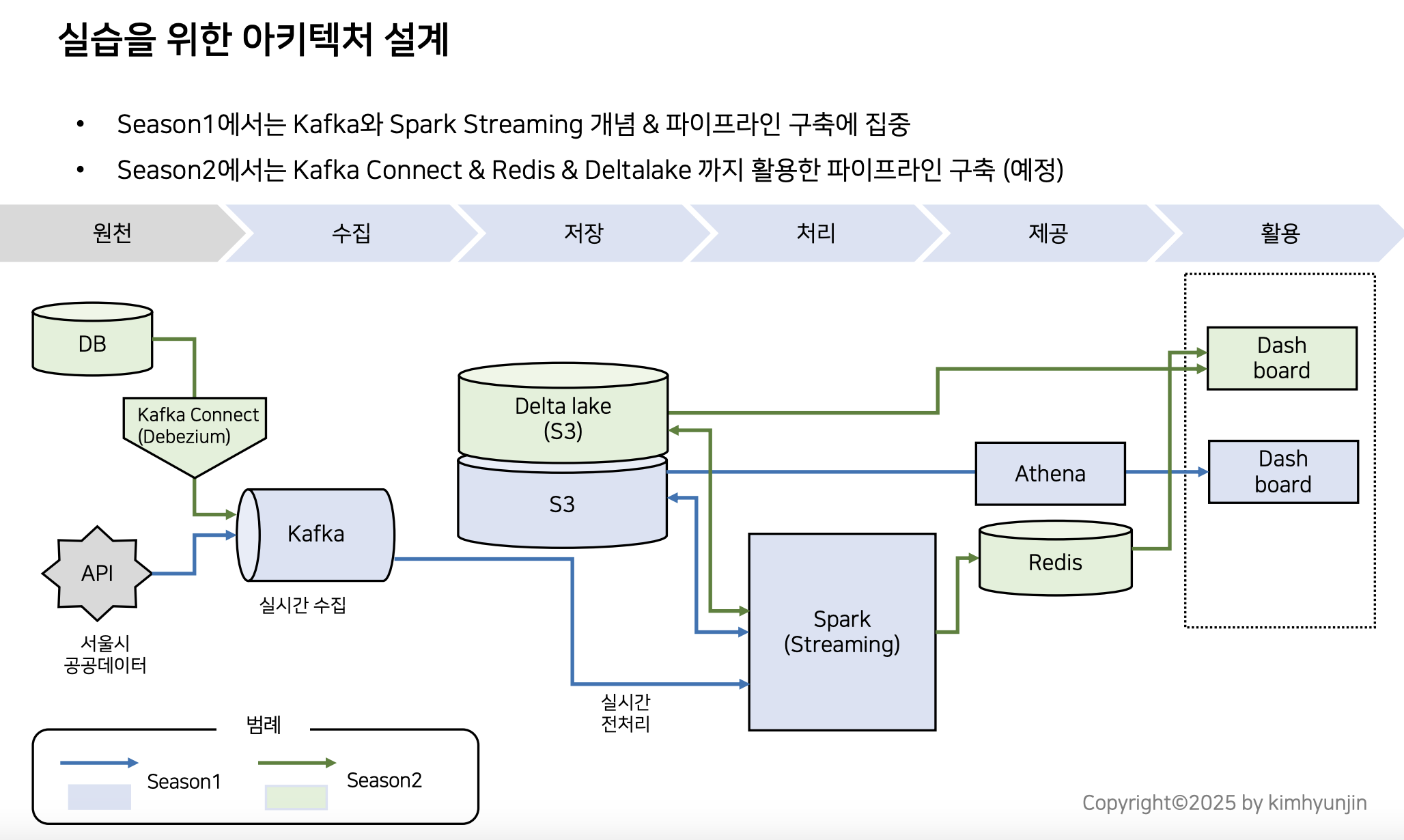

Season 1: Kafka + Spark Streaming 중심 구조
핵심 목표: 실시간 데이터 스트리밍의 개념 이해 + 기본 파이프라인 구축
1.구성 개요
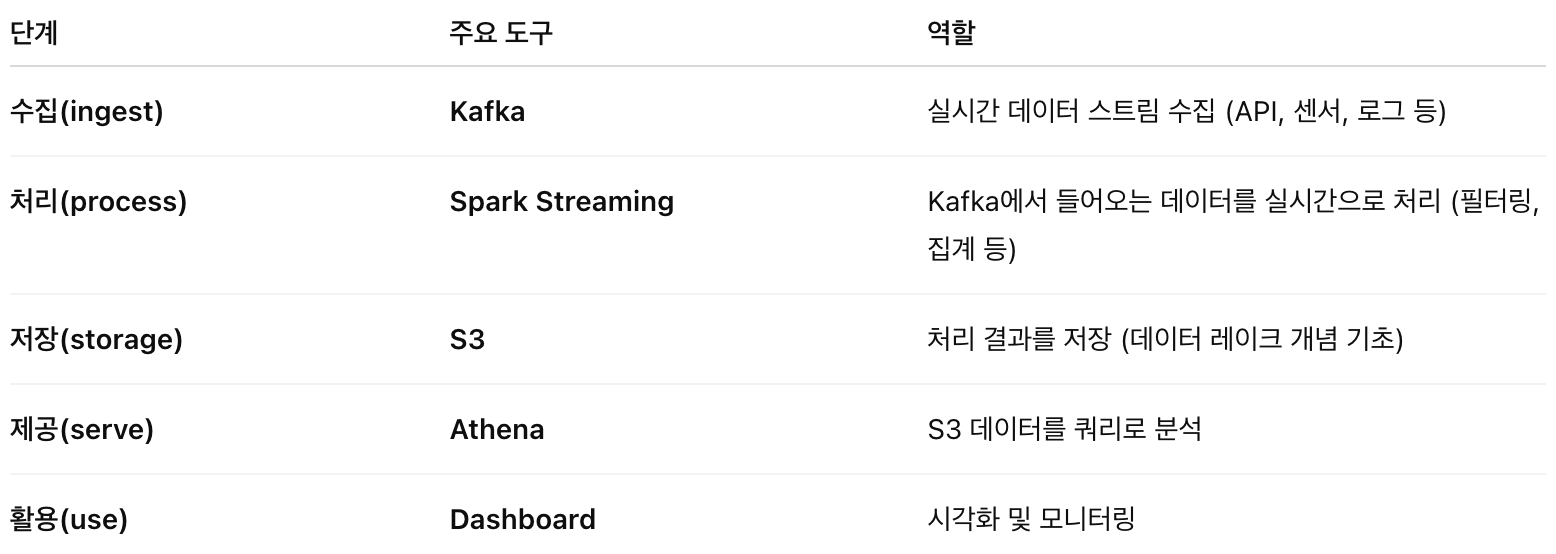
2.도구별 설명
Kafka
역할: “데이터 파이프라인의 혈관”
→ 외부 API나 DB에서 들어오는 데이터를 실시간으로 받아서 스트리밍 형태로 전달
특징: Producer(생산자)와 Consumer(소비자) 구조로 동작
장점: 실시간 데이터 처리에 강함, 비동기 처리로 빠름
Spark Streaming
역할: Kafka에서 받은 데이터를 실시간 변환·처리
예) 서울시 공공데이터에서 들어오는 택시 위치정보를 시간대별로 집계
특징: 대규모 데이터를 분산 환경에서 병렬 처리 가능
장점: 배치(batch) + 스트리밍(streaming) 통합 가능 (Spark 구조의 유연성)
👉 Season 1의 핵심은 “데이터가 Kafka로 들어오고 Spark로 실시간 처리되는 흐름”을 익히는 것.
Season 2: Kafka Connect + Redis + Delta Lake 확장 구조
핵심 목표: 실시간 수집 + 처리 + 저장 + 빠른 제공까지 완성된 데이터 파이프라인 구축
1.구성 개요
2.새로 추가된 기술들의 역할
Kafka Connect (with Debezium)
역할: DB → Kafka 자동 연동
→ 예를 들어 MySQL에서 주문 테이블이 갱신되면 Kafka 토픽으로 자동 푸시
장점:
직접 API 작성 없이 “커넥터 플러그인”만으로 데이터 파이프라인 구성 가능
CDC(Change Data Capture) 기반 실시간 반영 (Debezium이 담당)
Redis
역할: 고속 캐싱 & 세션 저장소
장점:
메모리 기반이라 데이터 조회 속도 매우 빠름 (ms 단위)
대시보드, 실시간 랭킹, 알림 같은 “즉시 반응”이 필요한 기능에 적합
예: Spark에서 처리된 실시간 통계 데이터를 Redis에 저장 → 대시보드가 즉시 반영
Delta Lake
역할: S3 위에 구축된 ACID 데이터 레이크
특징:
기존 S3의 단점(트랜잭션, 업데이트 불가)을 보완
데이터 버전 관리, rollback 가능
Spark와 완벽 호환
장점:
실시간 + 배치 데이터 통합 관리
데이터 품질(정합성) 확보 가능
Season1 vs Season2 핵심 차이