#77. Accuracy구하기
#정확도: 모델의 예측값이 얼마나 잘 맞는지 볼 수 있음
#예측치를 설정합니다
predictions = [0 , 1, 0, 2, 1, 2, 0]
#실제 모델
labels = [1, 1, 0, 0, 1, 2, 1]
n_correct = 0
for pred_idx in range(len(predictions)):
if predictions[pred_idx] == labels[pred_idx]:
n_correct += 1
accuracy = n_correct / len(predictions)
print("Accuracy[%] :",accuracy*100, '%')Confusion Matrix
정의: model 성능 평가 지표
이를 알기 위해선 예측값과 실제값이 발생할 때를 정리해두어야 한다.

predictive values
actual values
| P | N | |
|---|---|---|
| P | True Positive | False Negative |
| N | False Positive | True Negative |
- Accuracy(정확도): 전체 중 모델이 맞게 예측한 비율
- Prevision(정밀도): 모델이 Postive로 분류한 것 중 실제 Positive
#78. 0~77까지 배운 내용을 이용해 confusion vector를 만들어보기
#confusion vector: 얼만큼 일치가 되었는지 표기하는 방법
predictions = [0 , 1, 0, 2, 1, 2, 0]
labels = [1, 1, 0, 0, 1, 2, 1]
n_classes = None
for label in labels:
if n_classes == None or label > n_classes:
n_classes = label
n_classes += 1
class_cnts, correct_cnts, confusion_vec = [], [], []
for _ in range(n_classes):
class_cnts.append(0)
correct_cnts.append(0)
confusion_vec.append(None)
for pred_idx in range(len(predictions)):
pred = predictions[pred_idx]
label = labels[pred_idx]
class_cnts[label] += 1
if pred == label:
correct_cnts[label] += 1
for class_idx in range(n_classes):
c
confusion_vec[class_idx] = correct_cnts[class_idx] / class_cnts[class_idx]
print("confusion vector: ", confusion_vec)
# 0 , 1, 2 의 실제 정답인 비율**#79. Histogram 구하기**
#For loop와 if statement를 이용해 histogram을 구하는 방법을 배운다
scores = [50, 20, 30, 40, 10, 50, 70, 80, 90, 20, 30]
cutoffs = [0, 20, 40, 60, 80]
histogram = [0,0,0,0,0]
for score in scores:
if score > cutoffs[4]:
histogram[4] += 1
elif score > cutoffs[3]:
histogram[3] += 1
elif score > cutoffs[2]:
histogram[2] += 1
elif score > cutoffs[1]:
histogram[1] += 1
elif score > cutoffs[0]:
histogram[0] += 1
else:
pass
print("histogram of the score: ", histogram)#80. 절댓값 구하기
#for loop & if statement를 이용해 원소들의 절댓값을 가진 list를 만드는 방법을 익힌다
numbers = [-2, 2, -1, 3, -4, 9]
#절대값으로 바꿔줄 빈 리스트 생성
abs_numbers = []
for num in numbers:
#numbers의 원소가 0보다 작으면 -num 으로 변환해 절대값으로 출력
if num < 0:
abs_numbers.append(-num)
else:
abs_numbers.append(num)
print(abs_numbers)Manhatan Distance

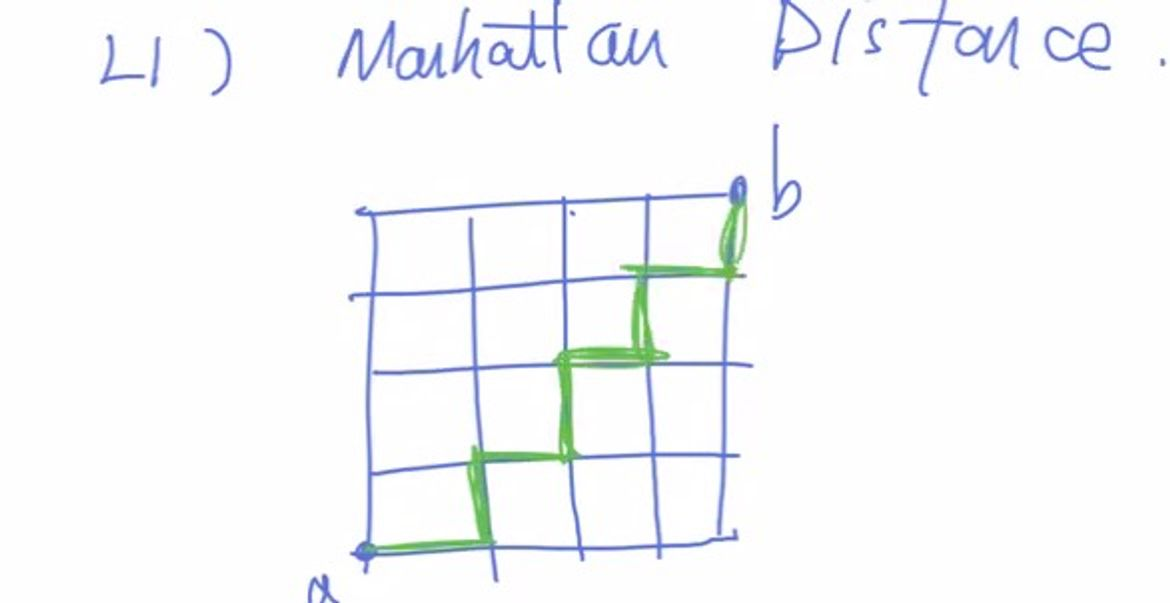
대각선으로 이동하지 못한다고 했을 때 이런 경로가 가장 빠른 것을 알 수 있다.
가장 짧은 길이는 무엇일까? 바로 가로, 세로의 길이의 합이다.
#81. Manhattan Distance
#원소들의 절대값을 가진 list를 만드는 방법을 이용해 Manhattan distance를 구한다
v1 = [1, 3, 5, 2, 1, 5, 2]
v2 = [2, 3, 1, 5, 2, 1, 3]
m_distance = 0
for dim_idx in range(len(v1)):
#for문을 통해 substraction을 구하기
sub = v1[dim_idx] - v2[dim_idx]
#차가 -라면 빼주어 더해주기
if sub < 0:
m_distance += -sub
else:
m_distance += sub
print("Manhattan distance: ", m_distance)
---
Manhattan distance: 14Nested List
Nested List? 리스트 안의 리스트
(중요)즉, 행렬의 형태를 지니고 있다는 사실을 인지하고 있어야 한다
**#82. Nested List 만들기 & 원소 접근하기**
#82. Nested List 만들기 & 원소 접근하기
#2차원 정보를 List로 만드는 방법과 각 원소에 접근하면 나오는 결과를 연습
scores = [[10, 20, 30],[50, 60, 70]]
print(scores)
print(scores[0])
print(scores[1])
print(scores[0][0], scores[0][1], scores[0][2])
print(scores[1][0], scores[1][1], scores[1][2])
[[10, 20, 30], [50, 60, 70]]
[10, 20, 30]
[50, 60, 70]
10 20 30
50 60 70#83. Nested List 원소 접근하기(2)
#for loop을 통해 2차원 List의 원소에 접근하는 방법을 연습한다.
scores = [[10, 20, 30],[50, 60, 70]]
for student_scores in scores:
print(student_scores)
for score in student_scores:
print(score)
[10, 20, 30]
10
20
30
[50, 60, 70]
50
60
70**#84.(실습) 학생별 점수 평균 구하기**
scores = [[10, 15, 20], [20, 25, 30], [30, 35, 40], [40, 45, 50]]
n_class = len(scores[0])
student_score_mean = []
for student_scores in scores:
student_score_sum = 0
for score in student_scores:
student_score_sum += score
student_score_means.append(student_score_sum/n_class)
print("mean of students", student_score_means)**#85.과목별 평균 점수 구하기**
scores = [[10, 15, 20], [20, 25, 30], [30, 35, 40], [40, 45, 50]]
n_student = len(scores)
n_class = len(scores[0])
class_score_sums = list()
class_score_means = list()
#set the sum of class scores as 0
for _ in range(n_class):
class_score_sums.append(0)
#calculate the sum of class scores
for student_score in scores:
for class_idx in range(n_class):
class_score_sums[class_idx] += student_score[class_idx]
print("sum of classes' scores: ",class_score_sums)
#calculate the mean of class scores
for class_idx in range(n_class):
class_score_means.append(class_score_sums[class_idx]/n_student)
print("mean of classes' scores:", class_score_means)
#sum of classes’ scores : [100, 120, 140]
#mean of classes’ scores : [25.0, 30.0, 35.0]86. mean substraction - 과목별
#각 배열은 학생으로 나누어져 있고, 각 원소는 성적으로 나누어져 있다.
#mean substraction 후 평균을 뽑아내라.
scores = [
[10, 15, 20],
[20, 25, 30],
[30, 35, 40],
[40, 45, 50]
]
n_student = len(scores) #-> 4개
n_class = len(scores[0]) #-> 3개
class_score_sums = []
class_score_means = []
#---
#과목 총합을 0으로 초기화하라
for _ in range(n_class):
class_score_sums.append(0)
#과목의 총합을 계산하라
for student_score in scores:
for class_idx in range(n_class):
class_score_sums[class_idx] += student_score[class_idx]
print("과목의 총합은 ",class_score_sums)
#과목의 평균들을 구하라
for class_idx in range(n_class):
class_score_means.append(class_score_sums[class_idx]/n_student)
print("과목의 평균들은:", class_score_means)
#---
class_score_sums = []
#과목별 실제치에서 평균차를 구하라
for student_idx in range(n_student):
for class_idx in range(n_class):
scores[student_idx][class_idx] -= class_score_means[class_idx]
print(scores)
class_score_means = []
#과목 총합을 0으로 초기화하라
for _ in range(n_class):
class_score_sums.append(0)
#평균차된 값들의 과목별 합을 구하라
for student_score in scores:
for class_idx in range(n_class):
class_score_sums[class_idx] += student_score[class_idx]
for class_idx in range(n_class):
class_score_means.append(class_score_sums[class_idx]/n_student)
print(class_score_means)
print("mean of classes' scores: ", class_score_means)
---
과목의 총합은 [100, 120, 140]
과목의 평균들은: [25.0, 30.0, 35.0]
[[-15.0, -15.0, -15.0], [-5.0, -5.0, -5.0], [5.0, 5.0, 5.0], [15.0, 15.0, 15.0]]
[0.0, 0.0, 0.0]
mean of classes' scores: [0.0, 0.0, 0.0]#**87. 분산과 표준편차**
scores = [[10, 15, 20], [20, 25, 30], [30, 35, 40], [40, 45, 50]]
n_student = len(scores)
n_class = len(scores[0])
class_score_sums = list()
class_score_square_sums = list()
class_score_variance = []
class_score_std = []
#0으로 초기화 시켜주기
for _ in range(n_class):
class_score_sums.append(0)
class_score_square_sums.append(0)
#수업 별 총합과 제곱된 총합을 구합니다.
for student_score in scores:
for class_idx in range(n_class) :
class_score_sums[class_idx] += student_score[class_idx]
class_score_square_sums[class_idx] += student_score[class_idx]**2
#각 수업의 분산을 구합니다
for class_idx in range(n_class):
#제평
mos = class_score_square_sums[class_idx]/n_student
#평제
som = (class_score_sums[class_idx]/ n_student)**2
variance = mos - som
std = variance**0.5
class_score_variance.append(variance)
class_score_std.append(std)
print(variance)
print(std)
---
125.0
11.180339887498949
125.0
11.180339887498949
125.0
11.180339887498949