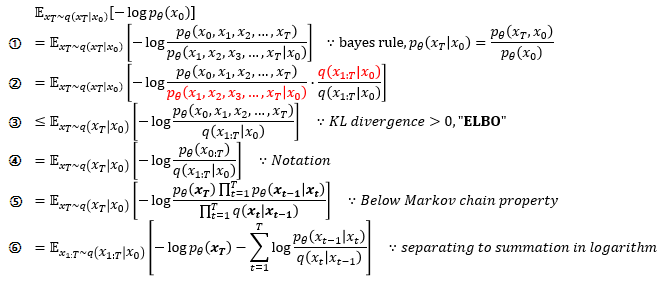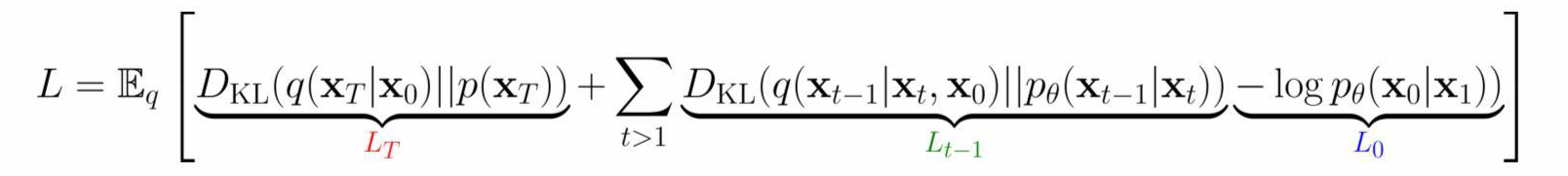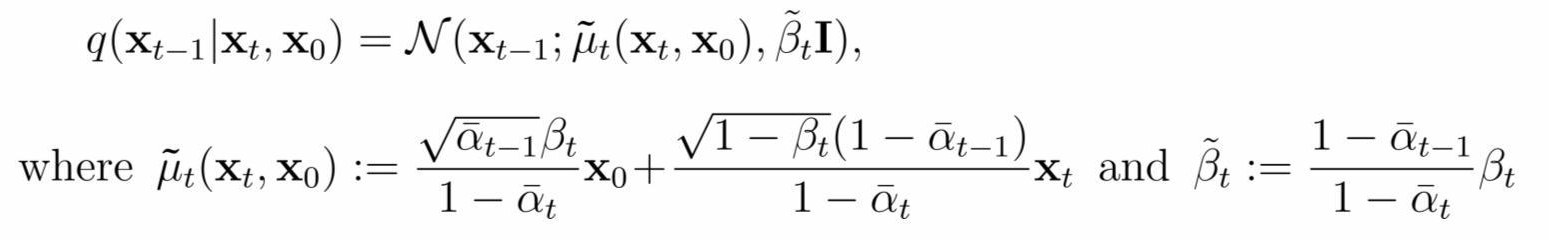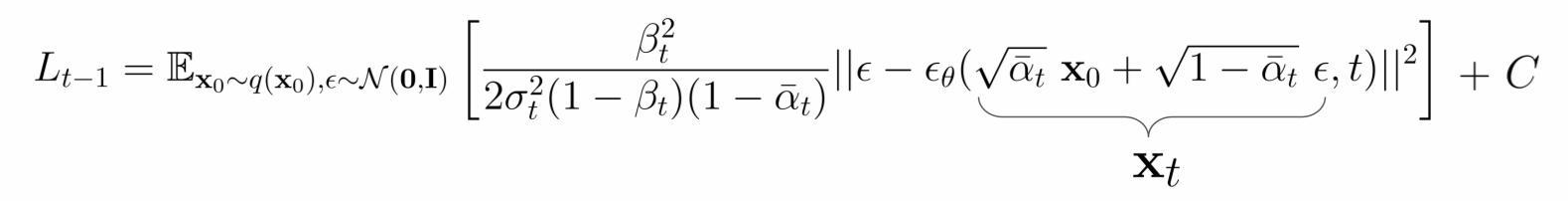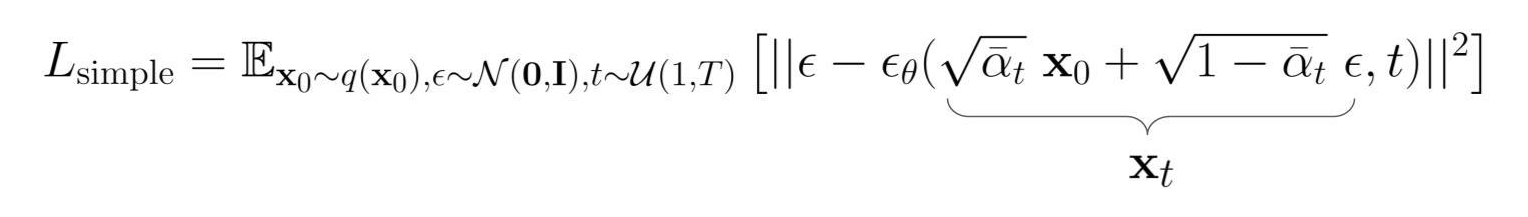Diffusion Probabilistic Model은 정의와 학습에 대해서 명확하지만 완성도가 높은 이미지를 생성할 수 있다는 것은 보이지 못했다.
이 논문에서 제안하는 Denoising Diffusion Probabilistic Model이 사용한 loss 함수에 대해 몇 가지 가정과 간소화를 통해서 다른 생성형 모델들에 견줄만한 성능을 보이고 더 나아가서 더 좋은 품질의 이미지를 생성할 수 있는 loss 함수를 제안한다.
Diffusion model
Loss 함수를 이야기하기 전에 diffusion의 기본 개념인 forward process와 backward process에 대해 소개하겠다.
Diffusion model의 forward, reverse process
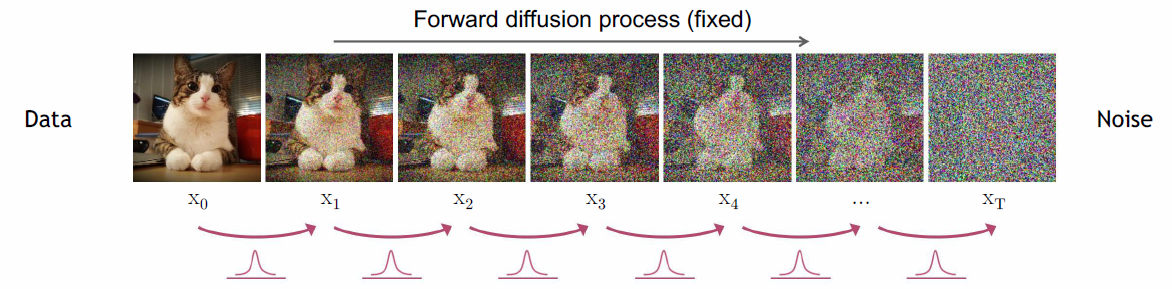
1. Forward diffusion process
Forward diffusion process
선명한 상태인 x0 이미지부터 노이즈를 조금씩 더해가는 과정이다. 이 과정은 학습하는 것이 아니라 주어진 하이퍼 파라미터에 의해서 계산하는 과정이다.
오직 이전 상태(xt−1)에 의해서 다음 상태(xt)가 결정되는 Markov chain이며, 모든 과정은 Gaussian distribution을 따른다. Markov chain을 수식으로 나타내면 다음과 같다.
여기서 βt는 timestep t에서 노이즈의 정도를 결정하는 계수이며 총 step의 수를 의미하는 T와 스케줄링 방법에 의해 결정되는 값이다. 평균과 분산을 βt를 이용하여 위와 같이 정의한 이유는 모든 시점에서 분산이 1이 되도록 만들기 위해서이다. 위 수식으로 분산을 구해보면 다음과 같이 전개가 된다.
식을 보면 총 3개의 항이 있는데, DDPM에서는 LT와 L0를 무시하고 Lt−1항 만을 loss 함수로 이용하게 된다. 두 항을 무시하는 이유는 다음과 같다.
L0: Denoising 과정의 가장 마지막 과정이기 때문에 거의 노이즈가 없는 상태로 상정하고 loss로써 영향이 거의 없을 것이라고 가정하여 무시한다.
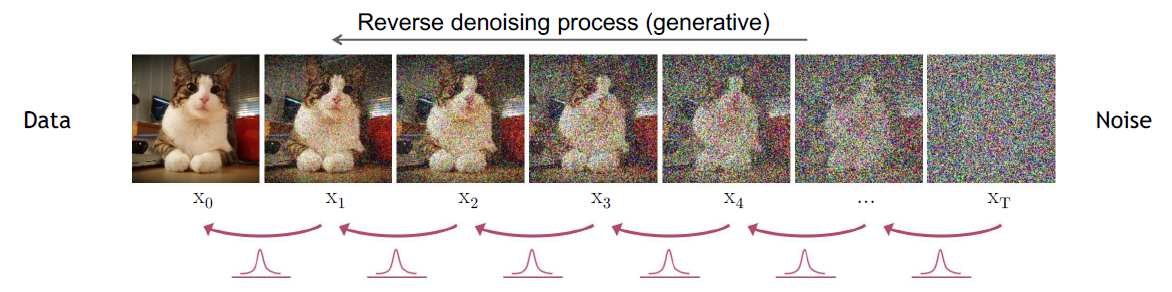
LT: Forward diffusion process에서 xT의 분포와 reverse denoising process에서의 xT의 분포는 모두 표준 정규 분포이기 때문에 분포 간의 거리가 거의 없다고 볼 수 있다. 또한 기존의 diffusion model은 이 항을 통해서 βt를 learnable하게 학습하였는데, DDPM에서는 T에 따라서 스케줄링하기 때문에 βt를 학습하지 않는다.
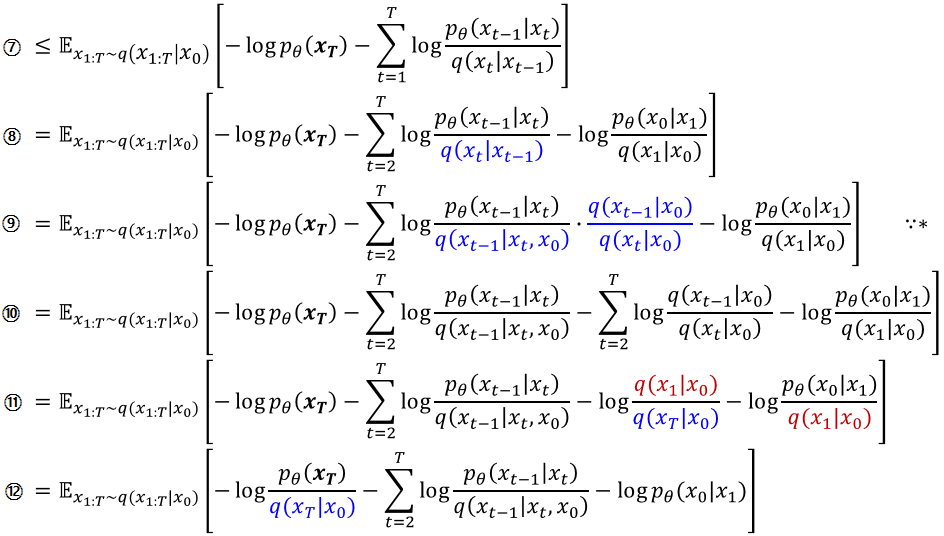
Lt−1의 q(xt−1∣xt,x0)의 의미
q(xt−1∣xt,x0)의 q는 forward process를 의미하는데, condition으로 들어간 값들과 구하려는 분포의 형태가 직관적으로 이해가 되지 않는다. q(xt−1∣xt,x0)는 tractable posterior라는 점에서 의미가 있다. 이어서 loss 함수를 구체화하는 과정에서 이 posterior를 풀어서 식을 구성하게 된다.
q(xt−1∣xt,x0)를 위와 같은 식으로 표현할 수 있는데, 이런 형태가 되는 이유는 posterior를 bayes’ rule로 분해해서 gaussian distribution의 식에 값을 대입하고 전개한 결과를 토대로 결정이 된다. 과정은 아래와 같다.
구체화된 loss 함수
Lt−1항은 위에서 전개한 forward process의 tractable posterior와 reverse process의 KL Divergence이다. 이 식을 KLD 식에 대입하여 전개하면 다음과 같다.
그리고 μ~,μθ를 xt,ϵ의 형태로 풀어서 전개하면 다음과 같은 식이 된다.
마지막으로 논문에서는 MSE 식 앞에 있는 계수가 1이고 하나의 이미지를 timestep T만큼 훈련시키는 것이 아닌 t를 [1,T] 사이의 값 중 하나로 골라서 학습을 시키는 것이 결과가 좋았다는 경험적인 이유로 다음과 같이 loss 함수를 단순화하였다.