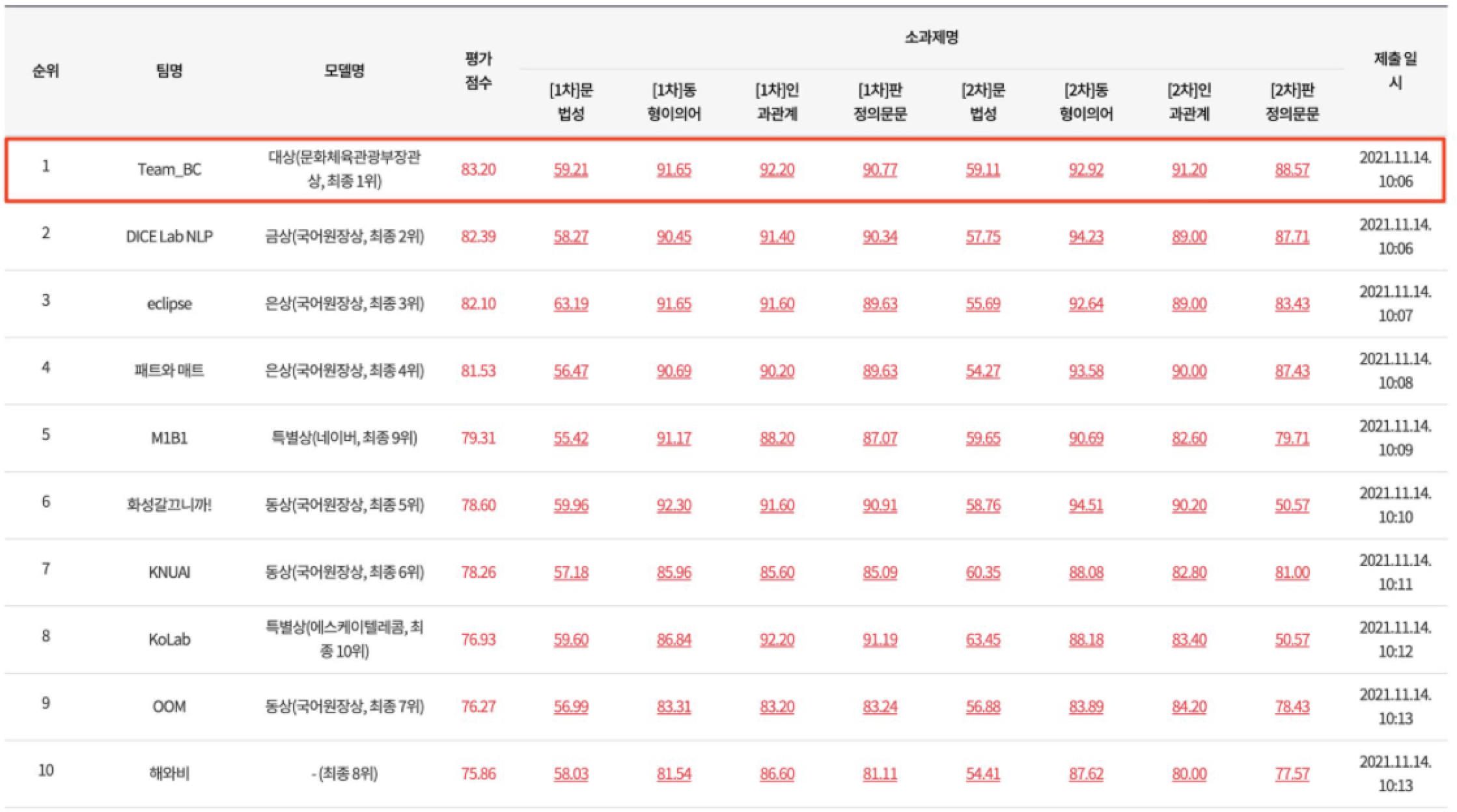
문화체육관광부와 국립국어원이 9월 1일(수)부터 두 달간 ‘2021 국립국어원 인공 지능 언어 능력 평가’ 대회를 개최하였고, Upstage Boost Camp에 함께 하였던 동료들(이동빈, 김현우, 김강민, 임도훈, 신문종) 6명과 TEAM_BC라는 팀명으로 참가하게되었다.
최종 순위에서 1등을 하여 문화체육부 장관상을 수상할 수 있었고, 그 과정을 정리하려한다.
- Github https://github.com/NIKL-Team-BC/NIKL-KLUE
- 최종 10등까지 리더보드
1. 과제 내용
개발한 인공 지능 모델로 모두 4개의 과제를 해결해야했다. (COPA, BoolQ, COLA, WIC)
- TASK1 COPA (인과관계 추론)
- 주어진 문장의 원인 또는 결과로 적절한 문장을 2지 선다로 선택하는 TASK
- DATA 예시
- Sentence : 덜 익은 송편을 먹었다.
- Question : 결과
- 보기1 : 소화가 잘 됐다.
- 보기2 : 배탈이 났다.
- Answer : 1 (0 : "1번 보기 정답", 1 : "2번 보기 정답")
- TASK2 BoolQ (판정의문문)
- 지문이 주어지고, 이어지는 질문 문장이 참인지 거짓인지 분류하는 TASK
- DATA 예시
- TEXT : 힐리스는 인라인 스케이트처럼 양쪽 밑창에 바퀴가 달려 있는 운동화이다. 이름은 발뒤꿈치를 뜻하는 영어 단어(heel)에서 유래되었다.
- Question : 힐리스는 신발인가요?
- Answer : 1 (0 False,1 True)
- TASK3 COLA (문장 문법성 판단)
- 주어진 문장이 문법적으로 옳은지 옳지 않은지 판단하는 TASK
- DATA 예시
- TEXT : 돈을 다 쓰고 한 푼도 남아 없다.
- Answer : 0 (0 False,1 True)
- TASK4 WIC (동형이의어 구별)
- 한 단어가 2가지 문장에서 등장하고, 그 단어의 의미가 같은지 다른지를 구분하는 TASK
- DATA 예시
- 단어 : 양식
- 문장1 : 내일은 양식을 먹으러 가자.
- 문장2 : 이번 보고서는 보내 드린 문서 양식에 맞추어 작성해 주시기 바랍니다.
- Answer : False
2. 과제 진행을 위한 Team Resource 활용 전략
우리 팀은 각자 아이디어가 있는 TASK를 진행하고 주 1~2회 정도 미팅을 통해 진행 사항을 공유하기로 하였다.
회의를 통해 나눈 아이디어 중 적용 가능한 부분을 적용해 가며 개별 Model을 개발하고, 마지막에 앙상블을 통해 최종 모델을 제출하기로 하였다.
나는 COPA와 BoolQ 두가지 TASK에 집중하였고, 최종적으로 두 가지 테스크 모두 리더보드 1등을 달성하였다. 이 두 가지 테스크에서 진행한 사항을 정리해 보겠다.
3. 모델 개발을 위한 핵심 Idea 및 실험한 사항들
- COPA
-
핵심 Idea
-
입력 생성 방식 (Multiple Choice → Two Sentence)
언어 모델은 문장이 자연스럽게 이어졌는지?를 잘 판단하도록 Pretrain 되어있다. 그래서 각 보기를 이어 붙여 2개의 새로운 문장으로 만들면 그 문장이 참인지 거짓인지 모델이 더 잘 알 수 있을 것이라 생각했다. 그래서 S1, S2 새로운 문장을 만들었다.
기존 Multiple Choice
[cls] + 문장 + [sep] + [결과,원인] + [sep] + [질문1] + [sep] + [질문2]
변경 Two Sentence
[cls] + [결과(원인)] + 문장(질문1) + [sep] + 질문1(문장)
[cls] + [결과(원인)] + 문장(질문2) + [sep] + 질문2(문장)


-
Model (제출 ACC 점수 86.5 → 90.8)
forward 진행시 입력받은 S1, S2 문장을 각각 Pretrained model에 forward 해서 나온 결과를 Concat 하였다.
결국 loss를 통해 부자연스러운 문장은 0의 결과를 갖도록, 자연스러운 문장은 1의 결과를 갖도록 fine tuning이 되게 하였다.


-
외부 추가 데이터
추가 데이터 사용이 대회에 허용되어 있었기 때문에 추가 데이터 생성을 고민하였다. 두 가지 방식을 떠올렸고, 첫번째는 데이터 생성, 두번째는 Super Glue Copa 데이터를 번역해서 사용하는 것이었다.
데이터 생성 (Valid ACC : 92.6 → 89.2)
인과관계 추론 특성상 wiki 데이터를 활용하여 많은 추가 데이터를 확보 할 수 있다고 생각했다. 그래서, 그 결과, 그러므로, 따라서, 왜냐하면 등의 접속사로 이어진 앞뒤 문장은 앞이 원인 뒤가 결과가 되기 때문에 model output이 1이 되어야하는 데이터를 많이 생성시킬 수 있었다. 주의 해야할 사항은 길이가 너무 긴 문장은 대회에서 나온 문장들과 특징이 너무 다르기 때문에 제거해 주었고, 너무 짧은 문장 또한 제거해 주었다. negative smaple은 문장의 순서를 뒤집어서 만들어 주었다. 전혀 관계 없는 두 문장을 이어주는 방식도 써볼 수 있을 것 같다. 이렇게 생성된 데이터는463,886개로 기존 대회에서 주어진 train data 3080개에 비하면 어마어마하게 많은 데이터를 확보할 수 있었다. 이 많은 데이터는 주어진 task 문장과는 차이가 있었기 때문에 작은 Lr로 pretrain 하고, 주어진 데이터로 fine tuning 하는 방식으로 학습을 진행하였다. 성능은 향상시키지 못했다. 데이터의 형태가 많이 달라서 그런것으로 판단된다.
Super Glue Copa 데이터 번역 (Valid ACC : 92.6 → 93.2)
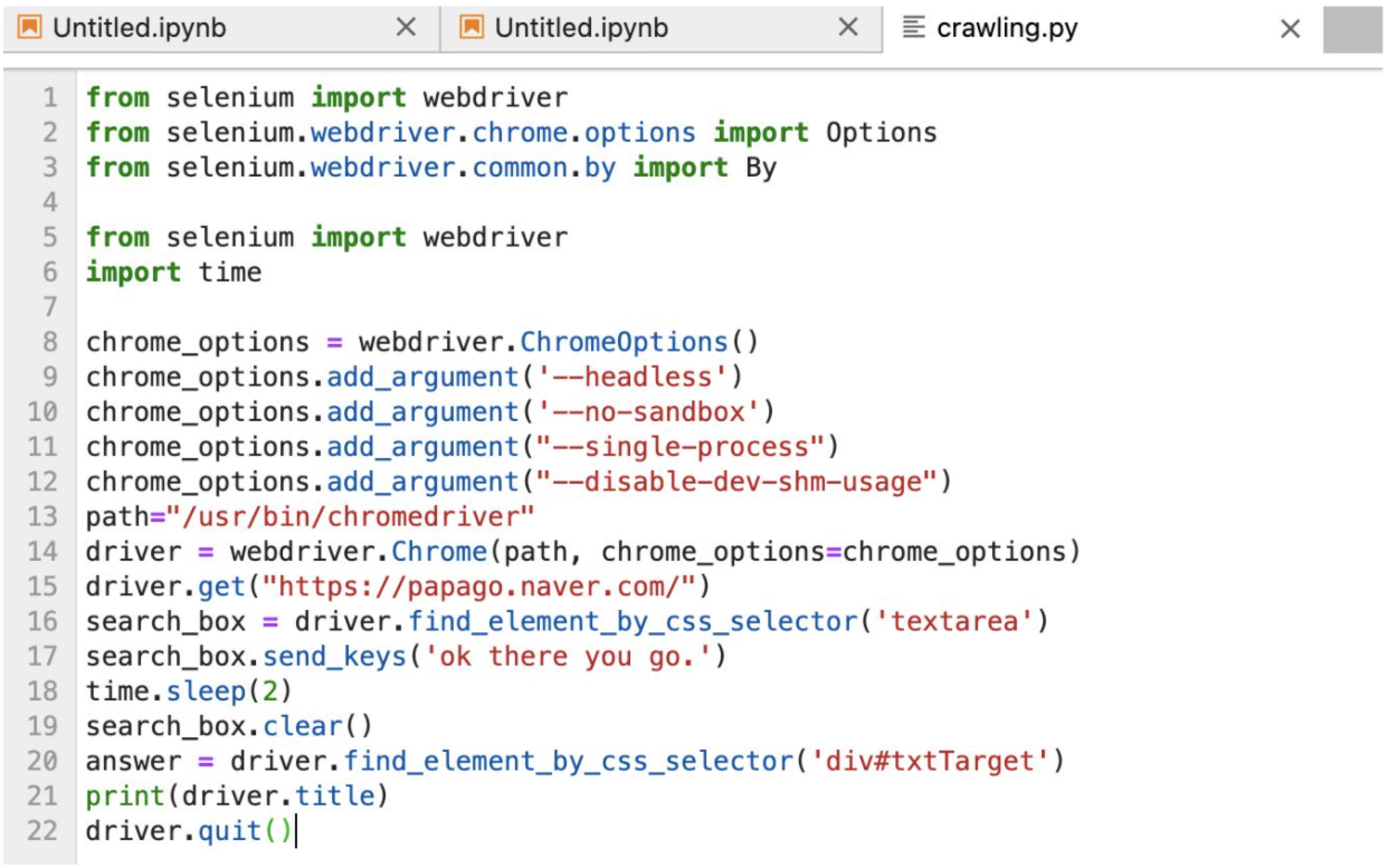
Super Glue Copa 데이터셋을 번역하기 위해 다양한 api를 활용하였다. pororo, googletrans, papago 세가지 번역 api를 사용해 보았으나, papago가 가장 번역 질이 높아 papago를 활용하여 번역하였다.
아래는 번역에 활용한 selenium이다.
-
그 밖의 다양한 실험들
Wandb를 사용하여 실험을 기록하였다.
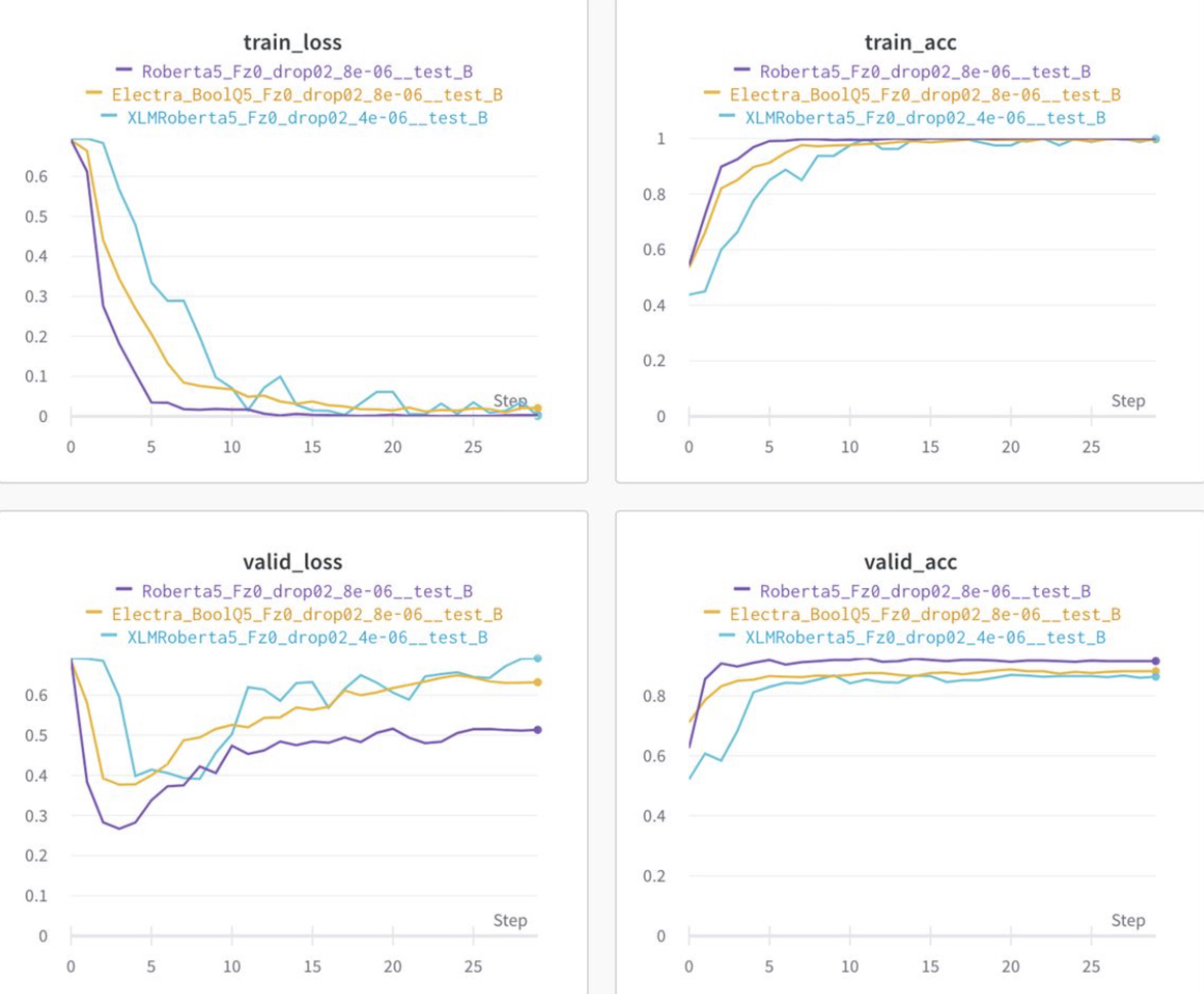
각 pretrained model별 성능을 확인
(Valid ACC : bert 62.4, xlm-roberta 86.8, electra 88.8, roberta 92.6 등)
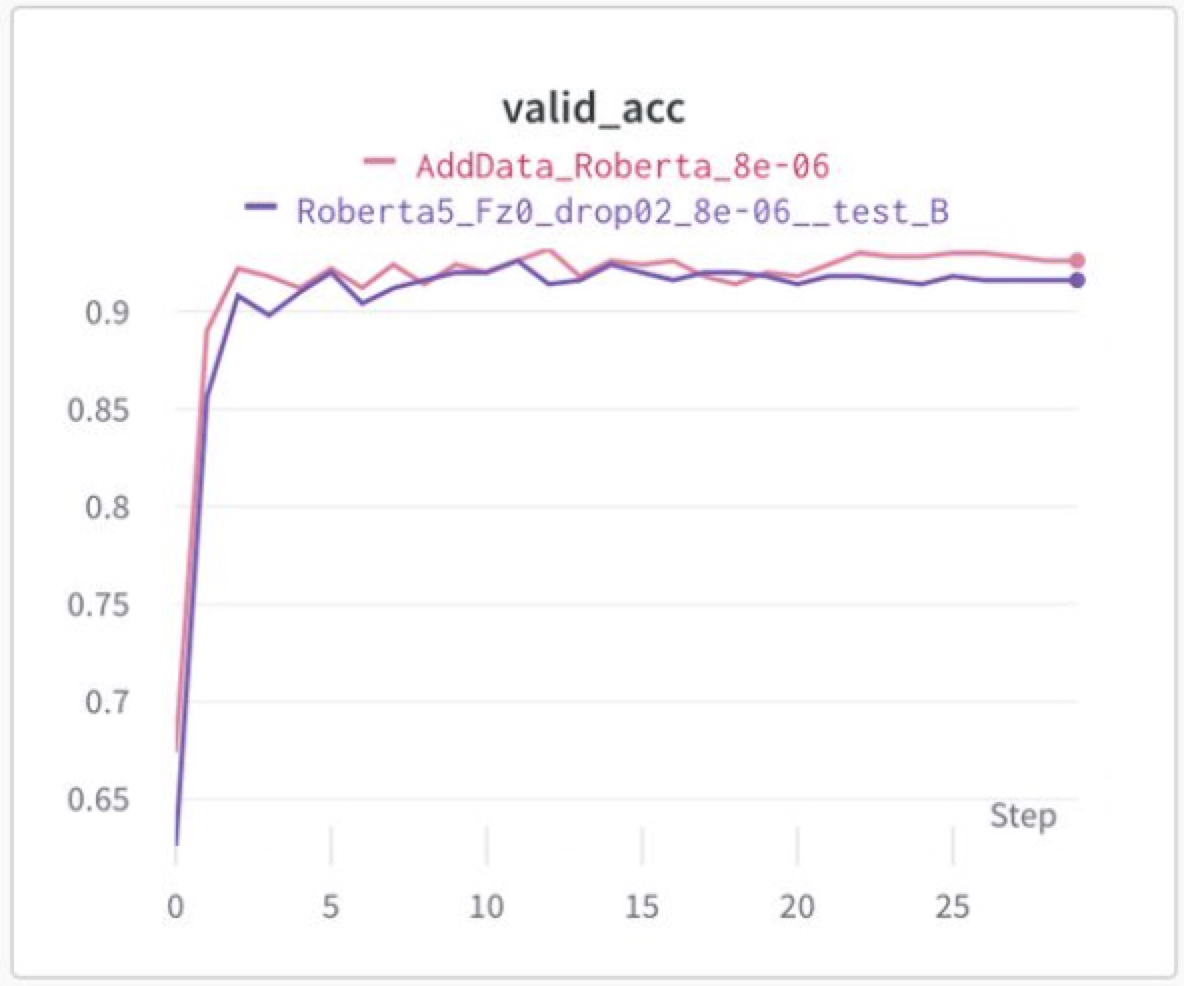
Classifier 초기 epoch freeze (Freeze를 하지 않았을 때 가장 성능이 높았음)
lr 별 성능 차이 확인 (Roberta model은 lr 8e-6에서 가장 높은 성능)
batch 변경 성능 확인 (Roberta model은 batch 32에서 가장 높은 성능)
Seed 변경 test (seed 42)
Loader Droplast False
다양한 조합의 앙상블 -
최종 제출 모델 (제출 ACC 1차 평가 92.2, 2차 평가 91.2)
-
KLUE/Roberta Super glue 번역 데이터 활용 모델과 사용하지 않은 모델의 soft 앙상블
-
-
BoolQ
- 핵심 Idea
- 입력 생성 방식
- Text 전처리
BoolQ의 text는 길이가 길고, 괄호, 특수문자, 다양한 나라의 언어를 포함하고 있어서 전처리를 변경하는 시도를 많이 하였다.
아래 처럼 다양한 특수문자를 빼보기도하고, 대체하기도 하였다.
최종적으로는 Batch 16으로 학습시 괄호안에 포함된 다양한 나라의 언어 설명을 제거 하고 평가시 성능 향상을 확인하였다. 단, Batch 32에서는 성능이 하락하였음

- CLS Token Weight Sharing (valid acc 86.29 → 87.29)
긴 문장에서 [CLS] 토큰을 문장이 끝나는 구간마다 넣어줘서, [CLS] 토큰 임베딩 학습이 전체 문장에 대해서 되도록 수정함
기존 : [CLS] + 지문(문장들....) + [SEP] + 질문
변경 : [CLS] + 문장1 + [CLS] + 문장2 .... + [SEP] + 질문
- Text 전처리
- Model
지문과 질문을 [SEP] 토큰으로 이어붙여 [CLS] 토큰의 아웃풋으로 classification을 진행하였다.
다양한 pretrain model을 테스트 하였고, 실험한 model들은 아래와 같다.

- 앙상블 방식
Stratified K-fold를 수행하되 성능이 낮은 fold는 성능을 향상시키기위해 튜닝을 해서 앙상블을 하였다.
특히 5fold가 성능이 너무 낮게 나와서 하이퍼 파라미터를 변경해가며 튜닝하였다.
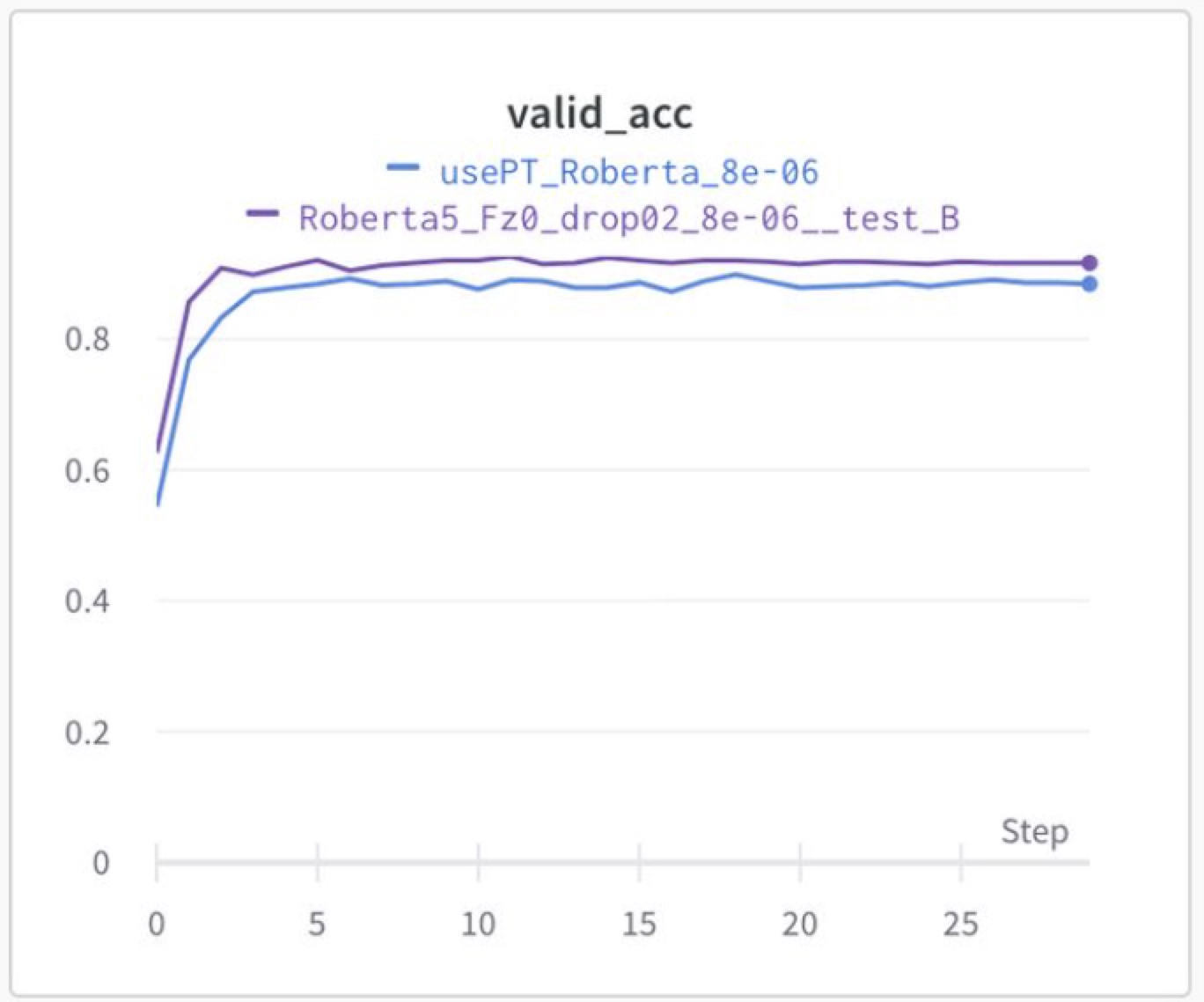
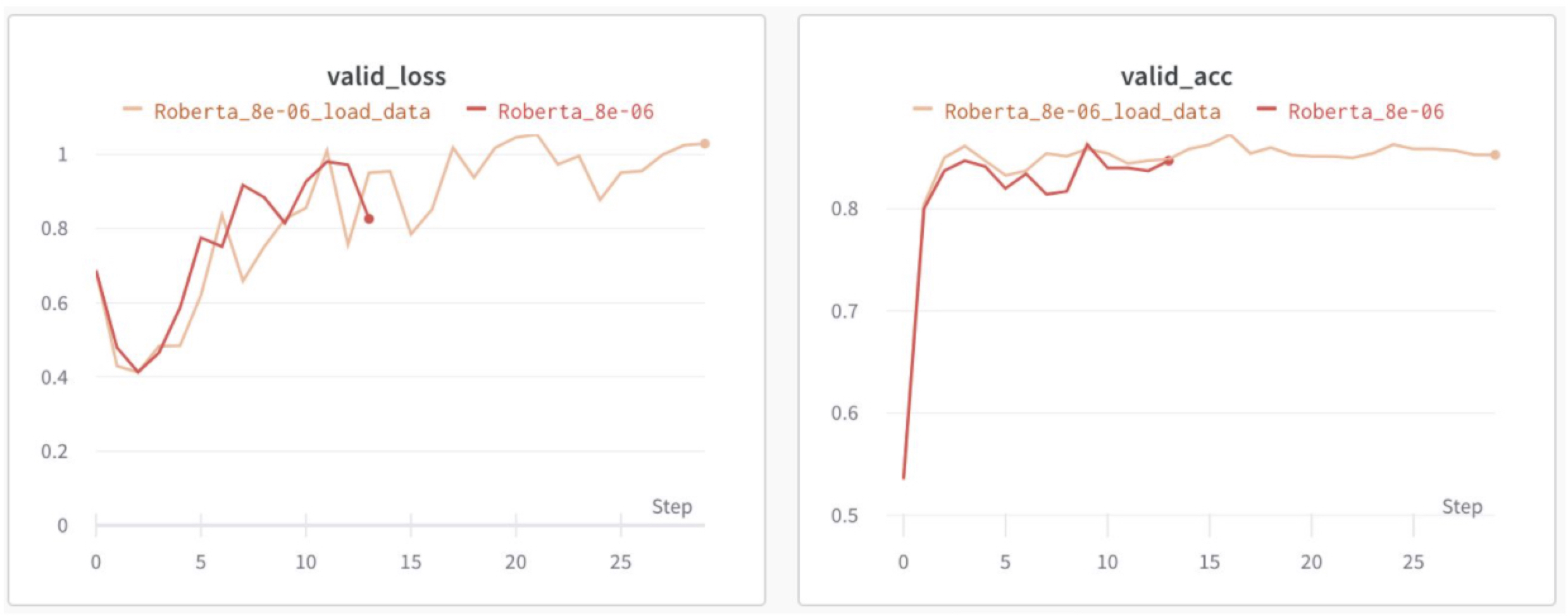
추가로 언어모델의 fine tuning의 경우 2~4epoch에서 valid loss는 최소를 찍으나, 그뒤로 valid loss와 valid acc가 동시에 향상되는 현상이 있다. 일반적으로 valid acc 가 높은 모델이 성능이 좋으나, 앙상블 관점에서 valid loss 최적 모델을 같이 soft 앙상블 해주었고, 최대 성능을 낼 수 있었다.
- 입력 생성 방식
- 최종 제출 모델
- KLUE/Roberta k-fold 튜닝(5개) + valid loss 최적 모델 soft 앙상블
- 핵심 Idea
4. 소감
좋은 결과가 있었던 것은 다양한 실험을 많이 했기 때문이라 생각한다. wandb로 기록한 결과를 돌아보니 정말 밤낮없이 많이 실험했던 것 같다. 아래 기록은 내 wandb log인데, 팀원 6명의 실험을 다합치면 정말 많은 실험을 했다고 생각한다. 또 팀원들이 서로 도와서 힘들어도 끝까지 열심히 한 것도 좋은 결과의 원인이 되었다고 생각한다. NAVER CLOVA 멘토님이 중간중간 조언해 주신 것도 큰 힘이되었다. 열심히 한 만큼 결과가 좋아서 뿌듯했고, 앞으로도 더 좋은 모델을 만들어 사회에 좋은 영향을 끼칠 수 있도록 노력해야겠다.