지도학습Supervised Learning: 학습을 위한 다양한 feature와 분류 결정값인 Label 데이터로 모델을 학습한 뒤, 별도의 테스트 데이터 세트에서 미지의 레이블을 예측한다.
= 명확한 정답이 주어진 데이터를 먼저 학습한 뒤 미지의 정답을 예측.
학습 데이터 세트: 학습을 위해 주어진 데이터 세트
테스트 데이터 세트: 머신러닝 모델의 예측 성늘을 평가하기 위해 별도로 주어진 데이터 세트
ㄴ분류 - classification
모듈명 : sklearn
sklearn.datasets 데이터 세트 생성하는 모듈 모임
sklearn.tree트리기반 ml 알고리즘을 구현한 클래스 모임
sklearn.model_selection 학습데이터와 검증 데이터, 예측 데이터로 데이터를 분리하거나 최적의 하이퍼 파라미터로 평가하기 위한 다양한 모듈의 모임
하이퍼 파라미터 : 머신러닝 알고리즘별로 최적의 학습을 위해 직접 입력하는 파라미터들
이를 통해 머신러닝 알고리즘의 성능을 튜닝할 수 있다.
train_test_split()
-첫번째 param :feature
-두번째 param :label
-세번째 param :테스트 데이터 세트 비율
-네번째 param :학습/테스트 용 데이터 세트 생성 위해 주어지는 난수 발생 값 (random seed와 같은 의미)
반환을 앞 변수 네개에 반환
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.2, random_state=11)DecisionTreeClassifier 객체의 fit()메서드에 학습용 feature데이터 속성과 결정값 데이터 세트를 입력해 호출하면 학습을 수행함.
와 학습이 완료된 객체래 ㅅㅅㅅㅅㅅㅅㅅㅅㅅㅅㅅㅅㅅㅅㅅ개재밌다
예측은 반드시 학습데이터가 아닌 다른 데이터를 이용해야 함
일반적으로 테스트 데이터 세트 이용
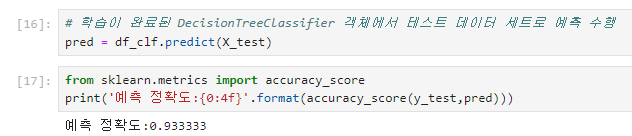
predict() 메서드에 테스트용 피처 데이터 세트를 입력해 호출하면 학습된 모델 기반에서 테스트 데이터 세트에 대한 예측값을 반환함
이제 예측을 평가.
여러 성능 평가 방법 중 여기서는 정확도를 측정
정확도는 예측 결과가 실제 레이블 값과 얼마나 정확하게 맞는지를 평가하는 지표
sklearn은 정확도 측정을 위해 accuracy_score()함수를 제공
-첫번째 param: 실제 레이블 데이터 세트
-두번째 param: 예측 레이블 데이터 세트
1.데이터 세트 분리: 데이터를 학습 데이터와 테스트 데이터로 분리
2.모델 학습 : 학습 데이터를 기반으로 ML알고리즘을 적용해 모델을 학습
3.예측 수행 : 학습된 ML모델을 이용해 테스트 데이터의 분류(ex:꽃 종류)를 예측
4.평가 : 예측된 결괏값과 테스트 데이터의 실제 결괏값을 비교해 ML 모델 성능을 평가
Estimator , fit(), predict()
fit()모델 학습
predict() 모델 예측
지도 학습의 주요 두 축인
분류(classification) 회귀(regression)
의 다양한 알고리즘을 구현한 모든 사이킷런 클래스는 fit과 predict만을 이용해 간단하게 학습과 예측결과를 반환
사이킷런에서는
분류 알고리즘을 구현한 클래스 = classifier
회귀 알고리즘을 구현한 클래스 = regressor로 지칭
사이킷런은 많은 유형의 classifier와 regressor 클래스를 제공
이 둘을 합쳐서 Estimator라고 부름
cross_val_score와 같은 evalution 함수.
GridSearchCV와 같은
하이퍼 파라미터 튜닝을 지원하는 경우 이 Estimator를 인자로 받음.
인자로 받은 Estimator에 대해서 cross_val_score(),GridSearchCV.fit() 함수 내에서
이 Estimator의 fit()과 predict()를 호출해서 평가를 하거나
하이퍼 파라미터 튜닝을 수행한대
P.94까지
