Machine Learning Study
1.0111 pandas lib

회사에서는 실행 하면 하루종일 걸렸는데집에선 1초도 안걸린다...나도 회사에서 좋은 컴퓨터로 코딩하고파!오늘 잘 시간 늦었다 내일 늦지 말자 호이짜!
2.0112 pandas
fedora에 jupyter를 깔았다.vscode에서 실행시켜보려 했는데 안된다.환경설정하고 공부하다가 12시에 잤다.다음주 부터 있을 테크세션에 발표할 내용을 정리해봤다.\-list comprehension\-lambda식\-여러 함수들의 반환값 달라보여도 규칙이 있
3.0113 pandas
잠깐 고향에 다녀올 생각이다.오늘 갔다가 내일 와야지공부좀 해놓고 가서도 하고ㅎㅎㅎㅎhttps://elfin-lan-616.notion.site/Peer-FeedBack-91c9006178ca4df88e7657dc81bb786e
4.0116 pandas
복습!3회차오늘도 titanic 끝내일부터는 다른 걸 해보자그냥 이 책 다하기 ㄱㄱㄱ오늘 여기까지 자야지
5.0117 ML
지도학습Supervised Learning: 학습을 위한 다양한 feature와 분류 결정값인 Label 데이터로 모델을 학습한 뒤, 별도의 테스트 데이터 세트에서 미지의 레이블을 예측한다.= 명확한 정답이 주어진 데이터를 먼저 학습한 뒤 미지의 정답을 예측.학습 데이
6.0118 ML
사이킷런에서 비지도학습인 차원 축소, 클러스터링, 피처 추출(feature extraction) 등을 구현한 클래스 역시 대부분 fit()과 transform() 적용비지도학습과 피처 추출에서의 fit()은 지도학습의 fit()과 같이 학습을 의미하는 것이 아니라 입력
7.0119 ML
내장된 예제 데이터 세트분류나 회귀 연습용 예제 데이터datasetx.load_boston()datasets.load_breast_carcer()datasets.load_diabetes()datasets.load_digits()datasets.load_iris()fet
8.0120 ML
술먹고왔는데 공부하고싶었다.교차 검증알고리즘을 학습시키는 학습 데이터와 이에 대한 예측 성능을 평가하기 위한 별도의 테스트용 데이터가 필요이 방법 역시 과접합(overfitting)에 취약한 약점을 가질 수 있음.과적합은 모델이 학습 데이터에만 과도하게 최적화되어, 실
9.0121 ML

stratified k 폴드는 불균형한 분포도를 가진 레이블 (결정 클래스) 데이터 집합을 위한 k 폴드 방식.불균형한 분포도를 가진 레이블 데이터 집합은 특정 레이블 값이 특이하게 많거나 매우 적어서 값의 분포가 한쪽으로 치우치는 것.ex대출사기 데이터이 데이터 세
10.0122 걍 잠
4망
11.0123 ML
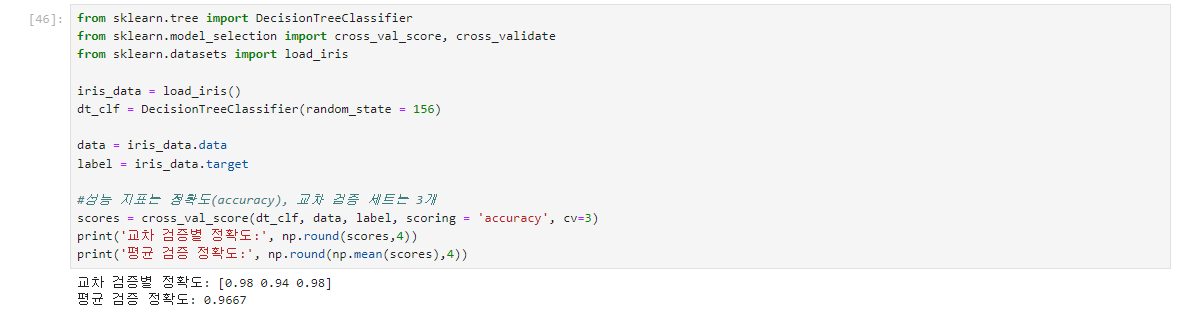
교차검증 cross_val_scoreK_Fold로 데이터를 학습하고 예측하는 코드1\. 폴드 세트를 설정2\. for 루프에서 반복으로 학습 및 테스트 데이터의 인덱스 추출3\. 반복적으로 학습과 예측을 수행하고 예측 성능을 반환cross_val_score(는 이런 일
12.0206 ML
자 오랜만에 왔죠?직장체험이 끝나고 휴식기를 잠시 가졌다.교재를 준비해왔으니 공부를 이어가야지뭐 이런식으로 데이터 확인하고scale과 encoding을 해봤습니다.각각 어느 정도의 정확도가 나오는지도 봤고용밋밋하던 파이썬에서 이런게 나오니 엄청 신기했읍니다.검증까지 한
13.0207 ML
오차행렬까지 함! 아직 중간중간에 빠뜨려서 기억못하거나 이해 안되는 말들이 좀 있다. 오늘 유난히 집중이 잘 안돼서 그런가? 이 단원을 복습할 때 쯤엔 알게 되지 않을까??
14.0208 ML
와 오늘 정말 힘이 없다..오늘은 precision, recall을 공부했다.정밀도와 재현율이 책이 정말 대단한게 알기 쉽게 잘 풀어 써져있다.공룡책 최고
15.0209 ML
F1 스코어, ROC 곡선, AUC한 두세번정도 보면 완전히 이해할 것 같은데??이제 연휴니까 좀 쉬어야이!
16.0220 ML
휴가를 마치고 돌아왔읍니다피마 인디언 당뇨병 DATA로 임곗값 조정을 통한 재현율 수치 높이기를 했읍니다.오늘로평가지표 단원을 마무리했읍니다
17.ML 0223
오늘 좀 신기한 걸 했다!