stratified k 폴드는 불균형한 분포도를 가진 레이블 (결정 클래스) 데이터 집합을 위한 k 폴드 방식.
불균형한 분포도를 가진 레이블 데이터 집합은 특정 레이블 값이 특이하게 많거나 매우 적어서 값의 분포가 한쪽으로 치우치는 것.
ex
대출사기 데이터
이 데이터 세트는 1억건
수십개의 피처,
대출 사기 여부를 뜻하는 레이블(사기1 정상 0 )
아주 작은 확률로 대출 사기 레이블이 존재. 이렇게 작은 비율로 1레이블 값이 있다면 k 폴드의 아주 작은 확률로 대출사기 레이블이 존재.
K폴드로 랜덤하게 학습 및 테스트 세트의 인덱스를 고르더라도 레이블 값인 0과 1의 비율을 제대로 반영하지 못하는 경우가 쉽게 발생합.
= 레이블 값으로 1이 특정 개별 반복별 학습/테스트 데이터 세트에는 상대적으로 많이 들어있고, 다른 반복 학습/테스트 데이터 세트에는 그렇지 못한 결과가 발생
대출사기 레이블이 1인 레코드는 비록 건수는 작지만 알고리즘이 대출 사기를 예측하기 위한 중요한 피처 값을 가지고 있기 때문에 매우 중요한 데이터 세트.
따라서 원본 데이터와 유사한 대출 사기 레이블 값의 분포를 학습/테스트 세트에도 유지하는 게 매우 중요함
stratified k 폴드는 이처럼 k 폴드가 레이블 데이터 집합이 원본 데이터 집합의 레이블 분포를 학습/테스트세트에 제대로 분배하지 못하는 경우의 문제를 해결해줌
stratified k 폴드는 원본 데이터의 레이블 분포를 먼저 고려한 뒤 이 분포와 동일하게 학습과 검증 데이터 세트를 분배.

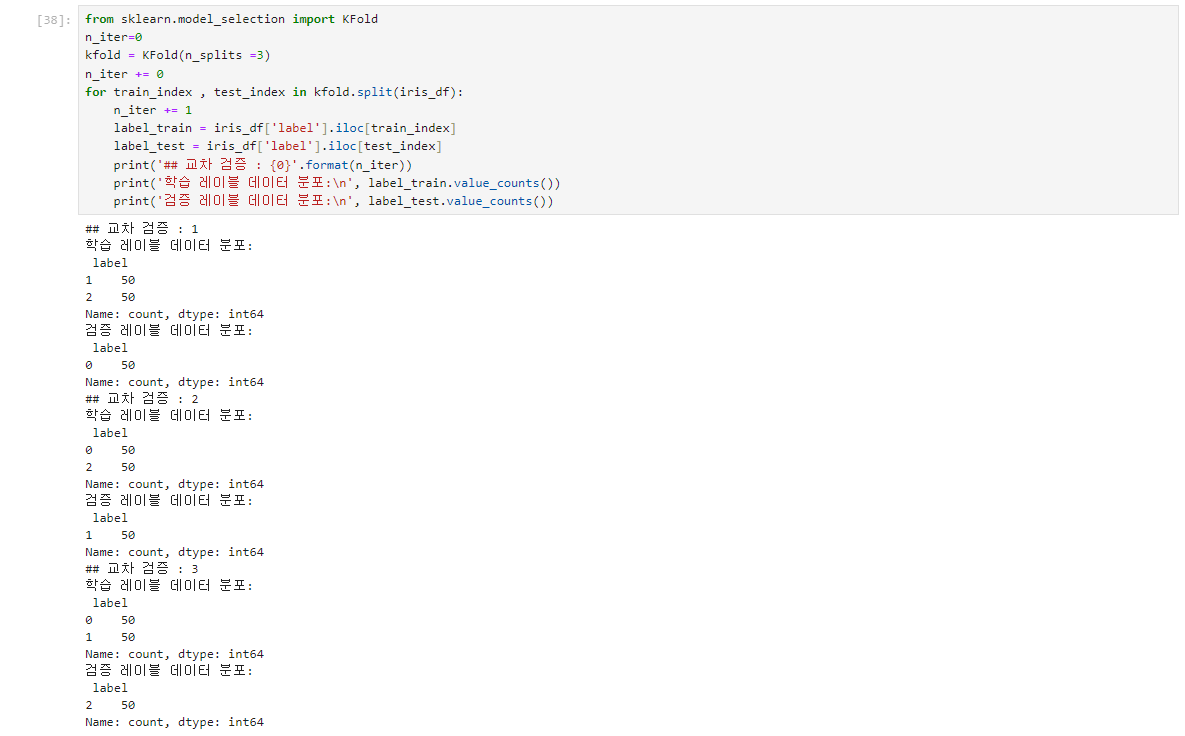




stratified K폴드의 경우 원본 데이터의 레이블 분포도 특성을 반영한 학습 및 검증 데이터 세트를 만ㄷ4ㅡㄹ 수 있으므로
왜곡된 레이블 데이터 세트에서는 반드시 Stratified K 폴드를 이용해 교차 검증해야함.
일반적으로 분류(classification)에서의 교차 검증은 K폴드가 아니라 stratified k 폴드로 분할되야 함.
회귀(regression)에서는 stratified k 폴드가 지원되지 않음.
회귀의 결정값은 이산값 형태의 레이블이 아니라 연속된 숫자값이기 때문에
결정값별로 분포를 정하는 의미가 없기 때문.
111쪽까지 끝
