교차검증 cross_val_score
K_Fold로 데이터를 학습하고 예측하는 코드
1. 폴드 세트를 설정
2. for 루프에서 반복으로 학습 및 테스트 데이터의 인덱스 추출
3. 반복적으로 학습과 예측을 수행하고 예측 성능을 반환
cross_val_score(는 이런 일련의 과정을 한꺼번에 수행해주는 API
cross_val_score(estimator, X, y=None, scoring=None, cv = None, n_jobs=1, verbose =0 , fit_params=None, pre_dispatch='2*n_jobs')
이 중 estimator, X, y, scoring, cv가 주요 파라미터
estimator는 사이킷런의 분류 알고리즘 클래스인 classifier 또는 회귀 알고리즘 클래스인 regressor를 의미
X는 피처 데이터 세트
y는 레이블 데이터 세트
scoring은 예측 성능 평가 지표를 기술
cv는 교차 검증 폴드 수
cross_val_score()는 classifier가 입력되면
stratified K 폴드 방식으로 레이블 값의 분포에 따라 학습/테스트 세트를 분할(회귀인 경우는 stratified k폴드 방식으로 분할할 수 없어서 k폴드로 분할)
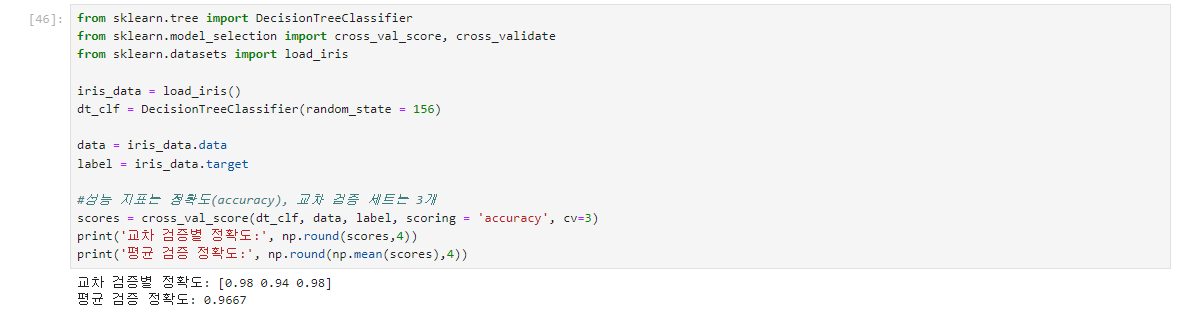
cross_val_score()는 cv로 지정된 횟수만큼 scoring 파라미터로 지정된 평가 지표로 평가 결괏값을 배열로 반환.
일반적으로 이를 평균해서 평가 수치로 사용
cross_val_score() api는 내부에서 estimator를 학습(fit) 예측(predict) 평가(evaluation) 시켜주므로 간단하게 교차 검증을 수행할 수 있음.
붓꽃 데이터의 cross_val_score() 수행 결과와 앞 예제의 붓꽃 데이터 stratifiedKFold의 수행 결과를 비교해보면
각 교차 검증별 정확도와 평균 검증 정확도가 모두 동일함.
cross_val_score()가 내부적으로 stratifiedKFold를 이용하기 때문
비슷하게 cross_validate()가 있음.
cross_val_score는 단 하나의 평가지표만 가능하지만
cross_validate는 여러 개의 평가 지표를 반환할 수 있음.
그리고 학습 데이터에 대한 성능 평가 지표와 수행 시간도 같이 제공
그러나 보통 cross_val_score() 하나로도 대부분의 경우 쉽게 사용함
GridSearchCV - 교차 검증과 최적 하이퍼 파라미터 튜닝을 한 번에
하이퍼 파라미터는 머신러닝 알고리즘을 구성하는 주요 구성 요소. 이값을 조정해 알고리즘의 예측 성능을 개선할 수 있음
사이킷런은 GridSearchCV API를 이용해 classifier나 regressor와 같은 알고리즘에 사용되는 하이퍼 파라미터를 순차적으로 입력하면서
편리하게 최적의 파라미터를 도출할 수 있는 방안을 제공
grid_parameters = {
'max_depth':[1,2,3],
'min_samples_split': [2,3]
}결정 트리 알고리즘의 여러 하이퍼 파라미터를 순차적으로 변경하면서
최고 성능을 가지는 파라미터 조합을 찾으려면
위처럼 파라미터의 집합을 만들고 순차적으로 적용하면서 최적화를 수행할 수 있음
하이퍼 파라미터는 다음과 같이 순차적으로 적용되며 총 6회에 걸쳐 파라미터를 순차적으로 바꿔 실행하면서
최적의 파라미터와 수행결과를 도출.
for 루프로 모든 파라미터를 번갈아 입력하면서 학습시키는 방법을 좀 더 유연하게 api 레벨에서 제공한 것.
1 1 2 2 3 3
2 3 2 3 2 3
Grid SearchCV는 교차 검증을 기반으로 이 하이퍼 파라미터의 최적 값을 찾게 해줌
이 데이터 세트를 cross-validation을 위한 학습/테스트 세트로 자동으로 분할한 뒤
하이퍼 파라미터 그리드에 기술된 모든 파라미터를 순차적으로 적용해 최적의 파라미터를 찾을 수 있게 해줌
GridSearchCV는 사용자가 튜닝하고자 하는 여러 종류의 하이퍼 파라미터를 다양하게 테스트하면서
최적의 파라미터를 편리하게 찾게 해주지만 동시에 순차적으로 파라미터를 테스트하므로 수행시간이 상대적으로 오래 걸리는 것에 유념해야 함
위의 경우 순차적으로 6회에 걸쳐 하이퍼 파라미터를 변경하면서 교차 검증 데이터 세트에 수행 성능을 측정
CV가 3회라면 개별 파라미터 조합마다 3개의 폴딩 세트를 3회에 걸쳐 학습/평가해 평균 값으로 성능을 측정,
6개의 파라미터 조합이라면 총 CV 3회X6개 파라미터 조합 = 18회의 학습/평가가 이뤄짐
GridSearchCV 클래스의 생성자로 들어가는 주요 파라미터
estimator:classifier, regressot pipeline이 사용될 수 있음
param_grid : key+리스트 값을 가지는 딕셔너리가 주어짐. estimator의 튜닝을 위해 파라미터명과사용될 여러 파라미터 값을 지정함.
scoring: 예측 성능을 측정할 평가 방법을 지정. 보통은 사이킷런의 성능 평가 지표를 지정하는 문자열 "ex: 정확도의 경우 accuracy"로 지정하거나
별도의 성능 평가 지표 함수도 지정 가능
cv : 교차 검증을 위해 분할되는 학습/테스트 세트의 개수를 지정
refit: 디폴트가 True이며 True로 생성시 가장 최적의 하이퍼 파라미터를 찾은 뒤 입력된 estimator 객체를 해당 하이퍼 파라미터로 재학습 시킴
train_test_split()을 이용해 학습 데이터와 테스트 데이터를 먼저 분리하고 학습 데이터에서 GridSearchCV를 이용해 최적 하이퍼 파라미터를 추출.
결정 트리 알고리즘을 구현한 DecisionTreeClassifier의 중요 하이퍼 파라미터인 max_depth와 min_samples_split의 값을 변화시키면서 최적화
테스트할 하이퍼 파라미터 세트는 딕셔너리 형태로 하이퍼 파라미터의 명친은 문자열 key값으로, 하이퍼 파라미터의 값은 리스트 형으로 설정

학습 데이터 세트를 GridSearchCV 객체의 fit 메서드에 인자로 입력
GridSearchCV 객체의 fit () 메서드를 수행하면 학습 데이터를 cv에 기술된 폴딩 세트로 분할해
paramgrid 에 기술된 하이퍼 파라미터를 순차적으로 변경하면서 학습/평가를 수행해서 그 결과를 cv_results속성에 기록
cvresults는 gridsearchcv의 결과 세트로서 딕셔너리 형태로 key값과 리스트 형태의 value값을 가짐.
cvresults를 Pandas의 DataFrame으로 변환하면 더 쉽게 볼 수 있음.
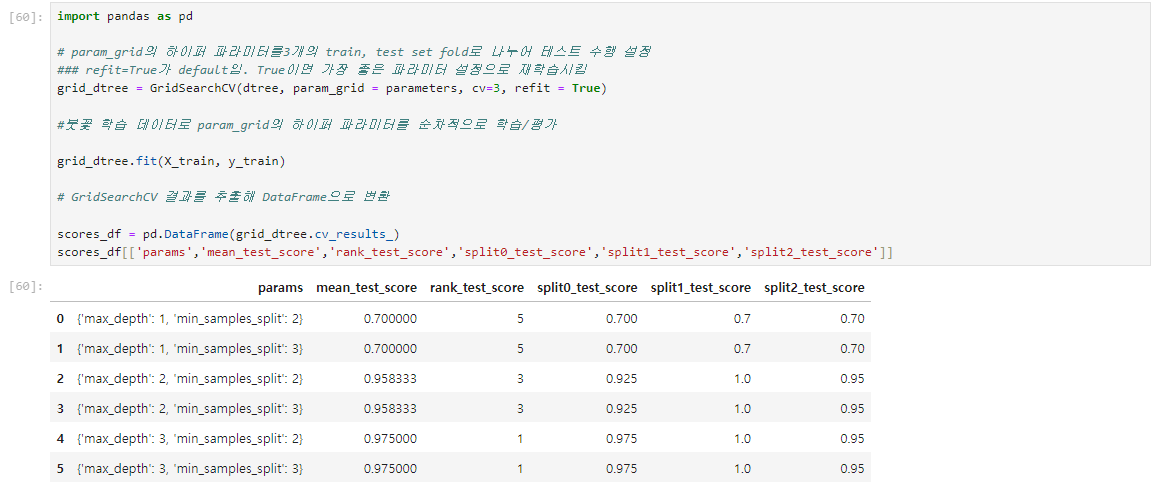
위의 결과에서 총 6개의 결과를 볼 수 있으며 이는 하이퍼 파라미터 max_depth와 min_samples_split을 순차적으로 총 6번 변경하면서
학습 및 평가를 수행했음을 나타냄.
위 결과의 params 칼럼에는 수행할 때마다 적용된 하이퍼 파라미터 값을 가지고 있음.
맨 마지막에서 두번재 행 인덱스 4를 보면 rank_test_score 칼럼 값이 1. 이는 해당 하이퍼 파라미터의 조합인 max_depth 3 min2로 평가한 결과 예측 성능이 1위
그때의 mean test score가 0.975000으로 가장 높음. 맨 마지막 행도 1위로 공동 1위.
split 123은 cv가 3인 경우. 3개의 폴딩 세트에서 각각 테스트한 성능 수치
mean test score는 세개를 평균한 것
GridSearch CV 객체의 fit을 수행하면 최고 성능을 나타낸 하이퍼 파라미터의 값과 그때의 평가 결과 값이 각각 bestparams, bestscore 속성에 기록됨.
cv_results, rank test score 1일 때의 값임.

max3, min2일 때 검증용 폴드 세트에서 평균 최고 정확도가 97.5프로로 측정. GridSearchCV 객체의 생성 파라미터로 refit=True가 디폴트
true일 시 GridSearchCV가 최적 성능을 나타내는 하이퍼 파라미터로 Estimator를 학습해 bestestimator로 저장
이미 학습된 best를 이용해 데이터 세트 예측과 성능 평가

별도의 테스트 데이터 세트로 정확도를 측정한 결과
일반적으로 학습 데이터를 gridSearchCV를 이용해 최적 하이퍼 파라미터 튜닝을 수행한 뒤에 별도의 테스트 세트에서 이를 평가하는 것이
일반적인 머신러닝 모델 적용 방법임
