2.1 Lock-based Protocols
PG4. Lock-based Protocols (1/3)
핵심 개념
- locking protocol은 트랜잭션들이 lock을 요청(request)하고 해제(release) 할 때 따라야 하는 규칙의 집합.
- lock의 목적은 같은 데이터 항목에 대한 동시 접근(concurrent access)을 통제하는 것.
- 즉, 아무 스케줄이나 허용하는게 아니라, 문제가 생기지 않는 스케줄만 남기도록 제한하는 역할을 함.
lock의 두 가지 모드
1) S lock (Shared lock)
- 읽기 전용 lock
- 여러 트랜잭션이 동시에 가질 수 있음
2) X lock (Exclusive lock)
- 읽기 + 쓰기 가능
- 다른 어떤 lock과도 같이 있을 수 없음
- 중요한 포인트: X lock은 "반드시 write해야 한다"는 뜻이 아니라, read도 가능하고 write도 가능한 stronger lock이라는 뜻.
호환성 행렬
- S와 S: 가능
- S와 X: 불가능
- X와 S: 불가능
- X와 X: 불가능
포인트
- "X lock이면 읽기도 가능하다"
- "S lock은 여러 개 가능하지만 X lock은 항상 단독"
- "locking protocol은 가능한 스케줄의 집합을 제한한다"
요약
- S는 같이 읽기 가능, X는 혼자만 접근 가능이라고 기억하면 됨.
PG5. Lock-based Protocols (2/3)
핵심 개념
- 트랜잭션은 lock 요청이 grant(허가) 된 다음에만 진행할 수 있음.
- 즉, 그냥 read/write를 바로 하는 게 아니라, 먼저 그 데이터에 대한 접근 권한을 받아야 함.
grant 조건
- 어떤 데이터 item에 대해 새 lock을 주려면, 이미 다른 트랜잭션들이 가지고 있는 lock들과 호환 가능(compatible) 해야 함.
예시
- 이미 S lock 여러 개가 걸려 있는 데이터에는 또 다른 S lock 가능.
- 이미 어떤 트랜잭션이 X lock을 가지고 있으면, 다른 트랜잭션은 어떤 lock도 못 받음
기다림(wait)
- lock이 바로 grant되지 않으면, 요청한 트랜잭션은 incompatible lock이 모두 해제될 때까지 wait 해야 함.
- 즉, lock manager 입장에서는 "지금은 안 됨 -> 앞선 충돌 lock이 풀리면 나중에 grant" 흐름.
포인트
- S lock은 여러 트랜잭션 동시 보유 가능
- X lock은 단 하나의 트랜잭션만 보유 가능
- lock이 안 되면 abort가 아니라 우선 wait가 기본, 다만 deadlock이면 나중에 rollback이 개입될 수 있음.
요약
- lock 요청은 호환되면 즉시 허용, 충돌하면 대기
PG6. Lock-based Protocols (3/3)
슬라이드에 나온 연산
-
lock-S(A)
-
read(A)
-
unlock(A)
-
lock-S(B)
-
read(B)
-
unlock(B)
-
display(A+B)
-
위 순서는 겉보기엔 문제 없어 보여도, 이 방식만으로는 serializability를 보장하지 못한다고 말함
왜 문제인가?
A를 읽고 unlock한 다음, B를 읽기 전 사이에 다른 트랜잭션이
- A도 바꾸고
- B도 바꾸면
내가 본 A와 B가 같은 시점의 값이 아니게 됨
그래서 display(A+B) 가 실제로는 어떤 직렬 실행 결과와도 맞지 않는 이상한 값이 될 수 있음
노트 보충
노트에서는 이런 식으로 lock/unlock이 read/write를 감싸는 형태를 well-formed schedule이라고 설명
하지만 well-formed라는 것만으로는 부족하고, 추가 규칙이 더 있어야 직렬가능성이 보장됨.
그 추가 규칙이 바로 뒤에 나오는 2PL
포인트
- "왜 단순 lock만으로는 serializable하지 않은가?"
- "A+B 예제에서 무슨 문제가 생기는가?"
- 정답 키워드: **중간에 unlock해서 일관되지 않은 시점의 값을 읽게 됨
요약
**lock을 쓰는 것 자체만으로는 부족하고, lock을 잡고 푸는 순서 규칙이 필요
PG7. Two-phase Locking Protocol (1/2)
핵심 개념
2PL은 lock 흭득/해제를 두 단계로 나눔
1) Growing phase
- lock을 얻을 수 있음
- lock을 해제할 수 없음
2) Shrinking phase
- lock을 해제할 수 있음
- 새로운 lock을 얻을 수 없음
가장 중요한 규칙
한 번이라도 lock을 풀기 시작하면, 그 뒤로는 새로운 lock을 절대 얻을 수 없다
이게 2PL의 핵심 문장.
왜 좋은가?
- 이 규약은 serializability를 보장
- 그리고 각 트랜잭션은 자기의 마지막 lock을 흭득한 시점(lock point) 기준으로 직렬 순서를 정할 수 있음
포인트
- growing: 얻기만 가능
- shrinking: 풀기만 가능
- "처음 unlock 이후에 새 lock 가능?" -> 불가능
- 직렬화 기준: lock point
요약
2PL = 앞에서는 잡기만, 뒤에서만 풀기만 한다
PG8. Two-phase Locking Protocol (2/2)
핵심 개념
2PL은 conflict serializable schedule을 만들어줌
하지만 완벽한 건 아니고, 몇 가지 한계가 있음
1) Cascading rollback 가능
- 기본 2PL에서는 트랜잭션이 write한 뒤, commit 전에 X lock을 풀 수도 있음
- 그러면 다른 트랜잭션이 그 값을 읽을 수 있고, 나중에 원래 write한 트랜잭션이 abort되면 읽은 쪽도 연쇄적으로 rollback될 수 있음.
- 이것이 cascading rollback
2) strict 2PL
이를 막기 위해 strict 2PL을 사용
- 모든 X lock을 commit/abort까지 유지
- 그래서 다른 트랜잭션이 미완료 write 결과를 읽지 못함
- 즉 cascading rollback 방지에 효과적
3) rigorous 2PL
더 강한 버전은 rigorous 2PL
- S, X 모든 lock을 commit/abort까지 유지
- 이 경우 트랜잭션들은 commit 순서대로 직렬화할 수 있음
4) deadlock은 막지 못함
2PL은 serializability는 보장하지만, deadlock-free는 아님
즉 서로 lock을 기다리다가 막힐 수 있음
5) 모든 conflict-serializable schedule을 생성하지는 못함
- 2PL이 만드는 스케줄은 모두 conflict-serializable
- 하지만 conflict-serializable한 스케줄 전부를 2PL이 만들 수 있는 건 아님
자주 헷갈리는 차이
- 2PL: 직렬가능성 보장
- strict 2PL: + cascading rollbacak 방지
- rigorous 2PL: + 모든 lock을 끝까지 유지, commit 순서 직렬화 가능
요약
2PL은 직렬가능성은 주지만, deadlock과 cascading rollback 문제는 따로 봐야함
PG9. Lock Conversions
핵심 개념
2PL에서는 lock 모드 변환도 가능
Growing phase
- S 흭득 가능
- X 흭득 가능
- S->X 업그레이드(upgrade) 가능
Shrinking phase
- S 해제 가능
- X 해제 가능
- X->S 다운그레이드(downgrade) 가능
왜 필요한가?
예를 들어 처음엔 읽기만 할 줄 알고 S lock을 걸었는데,
나중에 값을 수정해야 하면 X lock이 필요.
이때 기존 S를 X로 upgrade 하는 것
중요한 규칙
- upgrade는 growing phase에서만
- downgrade는 shrinking phase에서만
이걸 어기면 2PL의 성질이 깨질 수 있음
포인트
- "S->X는 upgrade"
- "X->S는 downgrade"
- "upgrade는 1단계, downgrade는 2단계"
요약
강한 lock으로 바꾸는 건 앞단계, 약한 lock으로 바꾸는 건 뒷단계
PG10. Why 2PL ensures conflict serializability
핵심
슬라이드는 증명 흐름을 보여줌
가정:
- 2PL을 따르는데도 non-serializable schedule이 있다고 해보자
- 그러면 precedence graph에 cycle이 있어야 함
그리고 각 트랜잭션 의 마지막 lock 흭득 시점을 라고 두면,
2PL에서는 -> 이면 < 가 성립함
즉 충돌 관계가 있으면, 먼저 영향을 준 트랜잭션의 lock point가 더 앞서야 함
그런데 cycle이 있으면
< < ... < <
가 되어야 하는데, 이건 모순임
그래서 cycle은 존재할 수 없고, 결국 2PL은 conflict serializability를 보장.
쉽게 말하면
2PL에서는 lock을 푸는 순간부터 새 lock을 못 잡기 때문에,
충돌 관계가 거꾸로 꼬여서 순환(cycle)되는 일이 생기기 어렵고,
결국 precedence graph가 DAG가 된다는 뜻.
포인트
- non-serializable -> precedence graph에 cycle
- 2PL이면 -> 일 때 <
- cycle이면 < 모순
- 따라서 2PL -> conflict serializable
요약
2PL에서는 lock point 순서가 precedence graph의 위상절렬 순서가 됨
PG11. Automatic Acquisition of Locks (1/2)
핵심 개념
실제 DBMS에서는 사용자가 매번 lock(A), unlock(A)를 직접 쓰지 않음.
트랜잭션은 그냥 read/write 명령만 수행하고, lock은 DBMS가 자동으로 흭득해줌.
노트에도 상용 DBMS는 lock 제어를 사용자에게 맡기지 않는다고 함.
read(D) 처리
슬라이드 알고리즘은 이 뜻
- 이미 가 D에 lock을 갖고 있으면 그냥 read(D)
- 없으면
- 다른 트랜잭션이 X lock을 갖고 있는지 확인- 있으면 기다림
- 없으면 S lock을 부여
- 그 다음 read(D) 수행
차이
read는 다른 트랜잭션의 X lock만 없으면 가능
왜냐하면 S lock끼리는 호환되기 때문
요약
읽기는 X만 피하면 되고, DBMS가 자동으로 S lock을 건다
PG12. Automatic Acquisition of Locks (2/2)
wirte(D) 처리
- 이미 가 D에 X lock을 갖고 있으면 그냥 write(D)
- 아니면
- 다른 어떤 트랜잭션도 D에 어떤 lock도 없어야 함- 만약 가 이미 S lock을 갖고 있으면 X로 upgrade
- 없으면 새로 X lock을 부여
- 그 다음 write(D) 수행
read와 write의 차이
- read: 다른 트랜잭션의 X lock만 없으면 됨
- write: 다른 트랜잭션의 모든 lock이 없어야 함
즉 write가 훨씬 더 강한 조건을 요구
포인트
- wirte 전에 필요한 lockdms? -> X
- 이미 S가 있으면? -> upgrade
- 왜 read보다 write가 더 기다리기 쉬운가? -> 충돌 대상이 더 많아서
요약
쓰기 전에는 베타적 접근이 필요해서 X lock이 필요하고, 이미 S가 있으면 upgrade함
PG13. Implementation of Locking
핵심 개념
DBMS 내부에는 lock manager가 있고,
트랜잭션들은 여기에 lock / unlock 요청을 보낸다고 보면 됨
lock manager의 역할
- lock 요청이 오면 grant 가능한지 판다
- 가능하면 grant message
- deadlock 상황이면 경우에 따라 rollback 요구 메시지
- 요청한 트랜잭션은 결과가 올 때까지 기다림
lock table
lock manager는 lock table을 유지
여기엔
- 현재 granted된 lock
- 아직 대기 중인 pending request
가 기록됨
그리고 보통 lock table은
- **메모리 내부(in-memory)
- hash table
- key=lock 대상 데이터 item 이름
으로 구현된다고 슬라이드가 말함
포인트
- lock manager = lock 요청 처리 담당
- lock table = 현재 lock 상태 저장
- 빠른 탐색 위해 hash table 사용
요약
DBMS는 lock manager와 lock table로 동시 접근을 통제한다
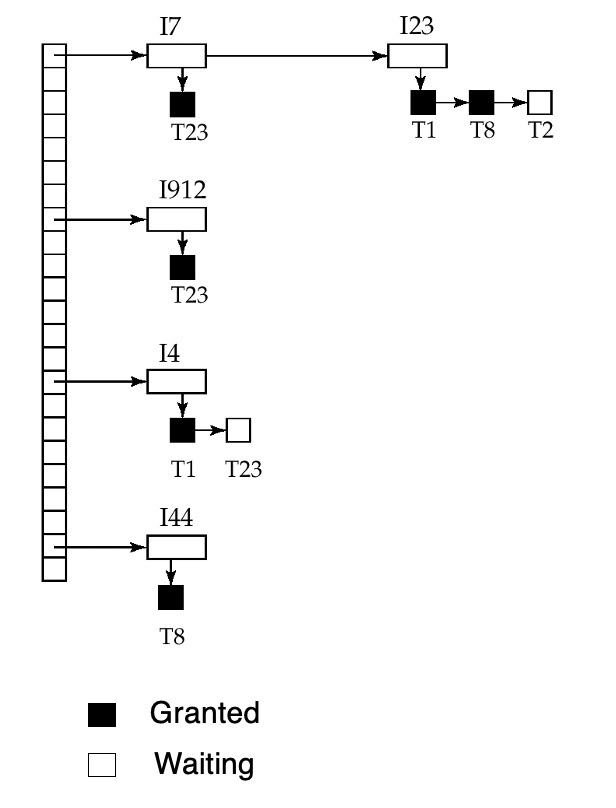
PG14. Lock Table
핵심 개념
lock table은 lock manager가 내부적으로 유지하는 자료구조
여기에는
- 이미 grant된 lock
- 아직 허용되지 못하고 대기 중인 요청
이 함께 기록됨.
슬라이드에서 검은 사각형은 granted, 흰 사각형은 waiting을 뜻함.
새 요청은 해당 데이터 item의 큐 뒤에 붙고, 앞선 lock들과 호환될 때만 grant됨.
unlock이 발생하면 해당 요청을 지우고, 뒤에서 기다리던 요청들이 이제 가능한지 다시 검사.
트랜잭션이 abort되면 그 트랜잭션의 granted/waiting 요청을 모두 제거해야 해서, lock manager가 트랜잭션별 보유 lock 목록도 같이 들고 있을 수 있음.
그림 해석
해시 버킷 기반 lock table 예시.
- I7에는 T23의 lock이 이미 grant되어 있고 대기자는 없음
- I23에는 T1, T8의 lock이 grant되어 있고, T2가 기다리고 있음
여기서 T1, T8이 동시에 grant된 걸 보면 둘은 보통 S lock이고, T2는 호환되지 않는 X lock을 기다린다고 이해하면 됨.
- T23은 I7, I912에 대해서는 lock을 가지고 있지만, I4에 대해서는 기다리고 있는 상태라고 해석할 수 있음
포인트
- lock table은 "현재 granted + pending request"를 함께 관리
- 새 요청은 큐 뒤에 추가
- grant 기준은 앞선 요청들과의 호환성
- abort 시에는 그 트랜잭션 관련 항목 전부 제거
요약
**lock table은 "누가 어떤 데이터에 lock을 가졌는지, 누가 기다리는지"를 관리하는 핵심 표
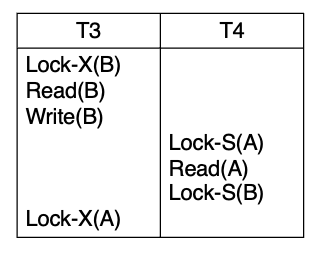
PG15. Deadlock
핵심 개념
deadlock(교착상태)는 서로가 서로를 기다려서 아무도 더 진행하지 못하는 상태.
슬라이드 예시는 아주 전형적.
- T3는 먼저 B에 X lock을 잡고 읽고/쓴 뒤, 나중에 A에 X lock을 요청
- T4는 먼저 A에 S lock을 잡고 읽은 뒤, 나중에 B에 S lock을 요청
그러면
- T4는 B 때문에 T3을 기다리고
- T3는 A 때문에 T4를 기다리게 됨
결국 둘 다 멈춤. 이게 deadlock.
왜 생기나?
2PL은 serializability는 보장하지만, deadlock-free는 보장하지 않음
즉 "올바른 결과"는 만들 수 있어도, 그 과정에서 서로 lock을 기다리다가 멈춰버릴 수는 있다는 뜻.
그래서 슬라이드에 "Deadlocks are a necessary evil" 이라고 적혀 있음.
현실적인 locking system에서는 deadlock 가능성을 완전히 없애기 어렵다는 의미.
포인트
- deadlock = 상호 무한 대기
- 두 개 이상 트랜잭션이 서로 필요한 lock을 쥐고 있을 때 발생
- 2PL에서도 deadlock 가능
요약
deadlock은 "네가 풀어야 내가 가고, 내가 풀어야 네가 가는" 상태
PG16. Starvation
핵심 개념
starvation(기아상태)는 deadlock이랑 다르게, 시스템 전체가 꼭 멈춘 건 아니지만 특정 트랜잭션만 계속 기회를 못 얻는 상태
슬라이드 예시는
- 어떤 트랜잭션이 X lock을 기다리고 있는데
- 그 사이에 다른 트랜잭션들이 계속 S lock을 받아버려서
- 그 X lock 요청이 끝없이 뒤로 밀리는 상황
또는 deadlock이 생길 때마다 같은 트랜잭션이 계속 victim으로 선택되어 rollback되는 것도 starvation이 될 수 있음
deadlock과 차이
- deadlock: 서로 기다려서 전체 진행이 멈춤
- starvation: 시스템은 돌아가는데 특정 트랜잭션만 계속 희생됨
노트에서도 deadlock은 불가피하게 생길 수 있지만 starvation은 설계로 막아야 한다고 강조.
즉 concurrency control manager는 공정성(fairness)을 고려해서 설계해야 함
포인트
- starvation은 잘못 설계된 lock allocation 정책 때문에 발생
- deadlock과 달리 "시스템 전체 정지"가 아니라 "특정 트랜잭션의 무한 지연"
- deadlock은 완전 회피 어렵지만 starvation은 방지해야 함
요약
starvation은 특정 트랜잭션만 계속 손해 보는 상태
PG17. Graph-based Protocol
핵심 개념
2PL의 대안으로 graph-based protocol을 소개함.
핵심 아이디어는 모든 데이터 항목 집합 D = {, , ..., }에 대해 부분 순서(partial ordering)를 정해두는 것.
만약 -> 라는 순서가 있으면, 두 항목을 모두 접근하는 트랜잭션은 반드시 를 먼저, 를 나중에 접근해야함.
이렇게 보면 데이터 집합 전체를 방향성 비순환 그래프(DAG)로 볼 수 있고, 이를 슬라이드에서는 database graph라고 부름
왜 이게 중요한가?
2PL은 "lock을 언제 풀 수 있는가"를 제어하는 방식이고,
graph-based protocol은 "어떤 순서로 접근해야 하는가"를 미리 강제하는 방식.
즉, 트랜잭션이 마음대로 여기저기 접근하는 게 아니라 그래프 방향을 따라가며 접근하게 만드는 것.
그래서 서로 반대 방향으로 올라가면서 꼬이는 상황을 줄일 수 있음
노트 보충
노트에서는 이 방식이 일반 데이터 전체에 적용되긴 현실적으로 어렵다고 설명.
왜냐하면 일반 데이터에는 자연스러운 부분 순서를 정하기 힘들기 때문.
대신 색인(index) 구조처럼 원래 순서성이 있는 데이터 구조에는 적용이 자연스러움.
그리고 그래프 기반 규약 중 가장 단순한 형태가 바로 다음 슬라이드의 tree-based protocol
요약
graph-based protocol은 lock 해제 규칙보다 "접근 순서"를 강제하는 방식
PG18. Tree-based Protocol
핵심 개념
tree-based protocol은 graph-based protocol의 가장 단순한 형태.
규칙:
- 오직 X lock만 허용
- 첫 번째 lock은 아무 데이터에나 가능
- 그 다음부터는 어떤 데이터 Q를 lock하려면, Q의 parent가 현재 같은 트랜잭션에 의해 lock되어 있어야 함
- unlock은 어제든 가능
- 한 번 lock했다가 unlock한 데이터는 다시 relock 불가
2PL과 다른 핵심 차이
- 2PL: 한번 unlock 시작하면 새 lock 흭득 불가
- tree protocol: unlock한 후에도 다른 새로운 lock 흭득 가능, 다만 이미 unlock한 같은 항목은 다시 못 잡음
즉 tree protocol은 2PL처럼 "앞에서는 잡기만, 뒤에서는 풀기만" 구조가 아님.
대신 트리의 부모-자식 관계를 따라가야 한다는 구조적 제약이 있음.
포인트
- only X locks
- 첫 lock은 자유
- 이후는 parent locked 조건 필요
- unlock은 자유
- unlock 후 relock 금지
- 2PL과 다르게 unlock 후 new lock 가능
요약
tree protocol은 부모를 잡고 자식을 내려가는 방식이며, 한번 푼 노드는 다시 못 잡는다
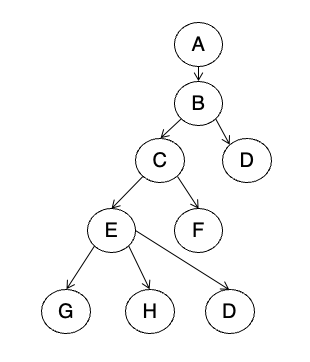
PG19. Tree-based Protocol Examples
그림 구조 읽기
트리 그림은 대략
A -> B -> (C, D), 그리고 C 아래에 E, F, 또 E 아래에 G, H 등이 있는 구조.
핵심은 자식 노드를 잡으려면 부모를 이미 잡고 있어야 한다는 규칙으로 예시를 판단하는 것.
T1 해석
T1:
- lock-X(B);
- lock-X(C);
- lock-X(D);
- unlock(B);
- unlock(D);
- lock-X(E);
- unlock(C);
- unlock(E);
이 순서를 보면,
- B를 잡고
- 그 자식인 C, D를 잡고
- B를 먼저 풀어도
- C를 아직 잡고 있으므로 그 자식인 E를 나중에 잡는 건 가능함
즉 unlock 후에도 새로운 lock 흭득이 가능한 tree protocol 특징을 잘 보여주는 예시.
T2, T3 해석
둘 다
- lock-X(E);
- lock-X(H);
까지는 같음.
차이는 unlock 순서.
- T2: unlock(E); 후 unlock(H);
- T3: unlock(H); 후 unlock(E);
tree protocol에서는 unlock 순서가 반드시 leaf-to-root일 필요는 없음
슬라이드가 이 둘을 같이 보여주는 이유는, 부모를 먼저 풀 수도 있고 자식을 먼저 풀 수도 있다는 점을 보여주기 위함임. 다만 한번 푼 노드는 다시 잡을 수 없음
포인트
"이 스케줄이 tree protocol을 만족하는가?"
- 처음 lock은 자유인지
- 이후 lock은 parent가 잡혀 있는지
- 이미 unlock한 노드를 다시 lock하지 않았는지
3가지를 보면 됨
요약
tree protocol 예시는 'unlock 후 새 lock 가능'과 'parent lock 필요'를 동시에 보여줌
PG20. Graph-Based Protocol (1/2): 장점
핵심 개념
tree protocol이
- conflict serializability 보장
- deadlock 없음
을 동시에 만족한다고 말함.
그리고 2PL보다 더 일찍 unlock 가능하므로,
- 대기 시간이 짧아지고
- 동시성이 증가할 수 있음
또 deadlock이 없으니, deadlock 해소를 위한 rollback이 필요 없다고 설명함
왜 deadlock이 없나?
핵심 이유는 lock 요청 방향이 한쪽으로만 진행되기 때문.
예를 들어 부모 -> 자식 방향으로만 내려간다고 하면, 어떤 트랜잭션은 위에서 아래로만 lock을 요구할 수 있음.
그러면 서로가 반대 방향으로 올라가며 상대방 lock을 기다리는 식의 원형 대기가 잘 생기지 않음.
노트에서도 이것이 그래프 기반 규약의 가장 큰 장점이라고 설명.
요약
tree protocol은 직렬가능하면서 deadlock-free이고, 2PL보다 빨리 unlock할 수 있음
PG21. Graph-Based Protocol (2/2): 단점
핵심 개념
대표 단점은 세 가지.
1) recoverability / cascade freedom 보장 안 함
tree protocol은 serializability는 주지만, recoverability나 cascade-free 스케줄을 자동으로 보장하지는 않음.
그래서 회복 가능성을 보장하려면 commit dependency 같은 추가 장치가 필요.
2) 실제로 접근하지 않는 데이터도 lock해야 할 수 있음
예를 들어 A와 F만 접근하고 싶어도, 트리 구조상 그 사이 경로에 있는 B, C도 같이 lock해야 할 수 있음
즉 경로 유지를 위해 불필요한 lock 오버헤드가 생김. 이건 추가 대기 시간과 동시성 저하로 이어질 수 있음.
3) 2PL과 가능한 스케줄 집합이 다름
- 2PL에서는 불가능하지만 tree protocol에서는 가능한 스케줄이 있고
- 그 반대도 있음
즉 둘은 단순히 상하위 관계가 아니라, 서로 다른 제약으로 서로 다른 스케줄 집합을 만드는 규약임
노트 보충
노트에서는 이런 이유 때문에 그래프 기반 규약은 보편적 범용 해법이라기보다, 특정 구조(특히 index구조)에서 2PL을 보완하는 역할을 한다고 설명함. 일반 데이터 전체에 적용하기는 비현실적인 경우가 많음.
요약
graph/tree protocol은 deadlock-free라는 강점이 있지만, 회복성과 불필요한 lock 비용 문제가 있음
2.2 Multiple Granularity Locking
PG23. Multiple Granularity Locking
왜 필요한가
기존에는 "데이터 item 하나에 lock 건다" 정도로 생각했는데, 실제 DBMS에서는 lock 대상 크기가 다양함.
예를 들면:
- 데이터베이스 전체
- 테이블(relation) 전체
- 페이지(page)
- 레코드(record, tuple)
이런 식으로 서로 다른 크기(granularity)에 lock을 걸 수 있음
이걸 Multiple Granularity Locking, MGL이라고 함.
데이터는 큰 다위 안에 작은 단위가 포함되는 계층 구조로 생각할 수 있고, 그래서 보통 트리 형태로 표현함.
또 어떤 노드에 명시적으로 lock을 걸면, 그 하위 노드들은 같은 모드로 묵시적으로 잠긴 효과가 생긴다고 설명.
왜 이렇게 하냐?
핵심은 동시성(concurrency)과 lock 관리 비용(overhead) 사이의 균형 때문.
-
fine granularity: 아래쪽 작은 단위에 lock
-> 동시성 높음-> 하지만 lock을 많이 관리해야 해서 overhead 큼
-
coarse granularity: 위쪽 큰 단위에 lock
-> overhead 작음-> 하지만 다른 트랜잭션을 많이 막아서 동시성 낮음
쉽게 말하면
- 레코드 하나만 잠그면 다른 사람도 같은 테이블의 다른 레코드는 쓸 수 있어서 좋음, 대신 lock이 너무 많아짐
- 테이블 전체를 잠그면 관리가 쉬움, 대신 다른 사람은 그 테이블 거의 못 씀
포인트
- "fine granularity와 coarse granularity의 trade-off를 설명하라"
- "왜 DBMS가 여러 크기의 lock을 지원해야 하는가"
요약
MGL은 동시성과 lock 관리 비용 사이에서 적절한 균형을 잡기 위한 계층적 lock 방식
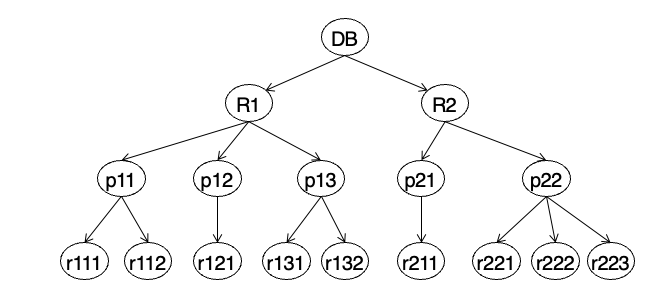
PG24. Example of Granularity Hierarchy
계층은 database -> relation -> page -> record 순서라고 외우면 됨.
노트에서는 relation 대신 좀 더 물리적인 저장 단위인 file을 쓰는 경우도 있다고 설명함.
이 구조가 의미하는 것
예를 들어
- DB에 lock을 걸면 전체가 영향을 받고
- R1에 lock을 걸면 R1 아래 페이지/레코드들이 영향을 받고
- p11에 lock을 걸면 그 페이지 아래 레코드들만 영향을 받음
즉 위로 갈수록 coarse, 아래로 갈수록 fine이야.
포인트
- 계층 순서 정확히 외우기
- "relation/page/record 중 어느 쪽이 fine인가?" -> record 쪽
- "coarest level은?" -> database
요약
MGL은 DB -> 테이블 -> 페이지 -> 레코드의 트리 구조로 이해하면 된다
PG25. Intention Lock Modes
이 부분이 MGL의 핵심.
기존 S, X만으로는 상위 노드와 하위 노드의 관계를 효율적으로 관리하기 어려워서 의도 lock(intention lock)이 추가됨.
슬라이드는 S, X외에 세 가지를 더 소개함
- IS (Intention-Shared)
- IX (Intention-Exclusive)
- SIX (Shared and Intention-Exclusive)
1. IS
IS는 "나는 이 노드의 하위 어딘가에서 나중에 S lock을 걸 거야" 라는 뜻.
즉 지금 당장 이 노드를 shared로 읽겠다는 게 아니라, 아래쪽에서 읽기 lock을 사용할 계획이라는 표시.
예:
- DB에 IS
- R1에 IS
- t11에 S
이런 식으로 내려갈 수 있음.
2. IX
IX는 "나는 이 노드의 하위 어딘가에서 나중에 X lock 또는 S/X lock을 포함한 더 강한 작업을 할 거야" 라는 뜻.
즉 하위 레벨에서 수정(write) 가능성이 있다는 신호.
예:
- DB에 IX
- R1에 IX
- t13에 X
3. SIX
SIX = S + IX
이 표현은 꼭 외워야 함.
즉 현재 노드 전체는 S lock처럼 읽으면서, 그 하위 일부 노드에서는 X lock으로 수정도 하겠다는 뜻.
노트의 설명이 아주 중요:
- 예를 들어 테이블 전체를 읽으면서
- 그 중 조건에 맞는 몇 개 레코드만 수정하려는 상황
이럴 때 상위 노드에 SIX가 적합함.
즉 "전체는 읽고, 일부는 고친다"라는 패턴.
직관적으로 구분
- IS: 아래에서 읽을 예정
- IX: 아래에서 쓸 예정
- SIX: 현재 전체는 읽고, 아래 일부는 쓸 예정
왜 intention lock이 필요한가?
intention lock이 있으면 상위 노드를 S나 X로 lock할 때 모든 하위 노드를 전부 검사하지 않아도 됨.
즉 상위 노드만 보고 "아래에서 누가 뭘 하려는지" 어느 정도 알 수 있어서 효율적.
포인트
- SIX = S + IX
- IS는 하위에 S 걸 의도
- IX는 하위에 X 또는 S/X 작업 걸 의도
- SIX는 "전체 읽기 + 일부 수정"
요약
intention lock은 상위 노드에 '하위에서 무슨 lock을 걸 예정인지'를 미리 표시하는 장치
PG26. Compatibility Matrix with Intention Lock Modes
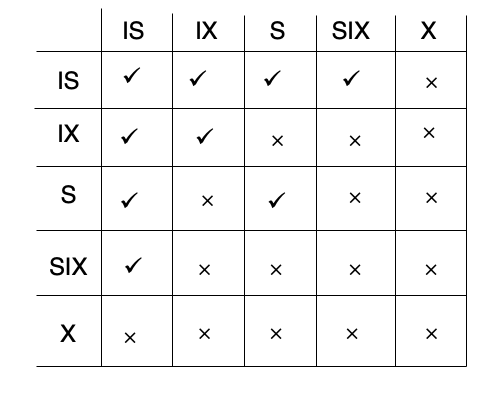
여기서 IX와 IX가 호환된다는게 처음엔 이상해 보일 수 있음.
이유는 현재 노드에서는 "아래쪽에서 수정할 수동 있음"만 표시한 상태라서, 아직 같은 하위 노드에서 충돌한다고 확정된 게 아니기 때문.
실제 충돌은 더 아래 노드에서 날 수 있다고 노트도 설명
포인트
- IS와 IX는 가능
- 둘 다 하위에서 뭔가 하겠다는 뜻이지만, 현재 노드에서 바로 충돌한다고 보지 않음
- IX와 IX도 가능
- 마찬가지로 실제 충돌은 더 아래에서 판단
- SIX는 생각보다 강하다
- 전체를 읽고 일부를 쓸 수 있으니, 대부분과 충돌함
- X는 절대 단독
- 기존 X와 동일하게 가장 강한 lock
팁
- IS는 거의 다 된다, 단 X만 안 된다
- X는 아무것도 안 된다
- SIX는 꽤 많이 막힌다
- IX는 IS, IX만 된다
요약
IS는 넓게 호환, X는 전부 불가, SIX는 강한 혼합 모드라 대부분과 충돌
PG27. MGL Scheme 규칙
이제 실제로 MGL에서 lock을 어떻게 거는지 규칙이 나옴.
규칙 1. 호환성 행렬을 지켜야 함
당연히 위에서 본 compatibility matrix를 따라야 함.
즉 상위 노드든 하위 노드든, 이미 있는 lock과 호환되어야 lock을 흭득할 수 있음
규칙 2. 루트를 먼저 lock해야 함
트리 구조이므로 루트(root)를 먼저 lock해야 하고, 루트는 어떤 모드로도 lock 가능함
규칙 3. Q를 S 또는 IS로 잠그려면
노드 Q를 S 또는 IS로 잠그려면
Q의 부모가 현재 IS 또는 IX로 잠겨 있어야 함
규칙 4. Q를 X, SIX, IX로 잠그려면
노드 Q를 X, SIX, IX로 잠그려면
Q의 부모가 현재 IX 또는 SIX로 잠겨 있어야 함.
위 규칙이 중요한 이유는
- 아래에서 읽기만 할 건지
- 아래에서 쓰기까지 할 건지
를 상위에서 일관되게 표현하게 만들기 때문
규칙 5. 트랜잭션은 2-phase여야 함
아마 어떤 노드를 unlock한 뒤에는 새로운 노드를 lock할 수 없음
즉 MGL도 2PL의 성질을 유지함
규칙 6. 자식이 잠겨 있으면 부모를 unlock 못 함
어떤 노드 Q를 unlock하려면, Q의 자식 노드들 중 현재 lock된 것이 없어야 함
그래서 결과적으로 lock은 root->leaf 방향으로 흭득, unlock은 leaf->root 방향으로 해제하게 됨.
노트 보충
- 상위 노드에 SIX를 가지고 있으면
- 하위 노드에는 IX 또는 X를 걸 수 있음
하지만
- 상위에 SIX가 있는데
- 하위에 또 SIX를 요구하는 건 올바르지 않다고 설명함
이유는 상위에서 이미 S 성격을 포함하고 있는데, 하위에서 또 중복된 S를 섞은 SIX를 요구하면 의미가 겹치기 때문
포인트
- root first
- S/IS는 parent가 IS or IX
- X/SIX/IX는 parent가 IX or SIX
- lock은 root->leaf
- unlock은 leaf->root
- MGL도 two-phase
요약
MGL은 상위에서 intention을 표시하고, root에서 leaf로 내려가며 lock하고, 반대로 올라오며 unlock하는 2PL 기반 규약
MGL Example 1
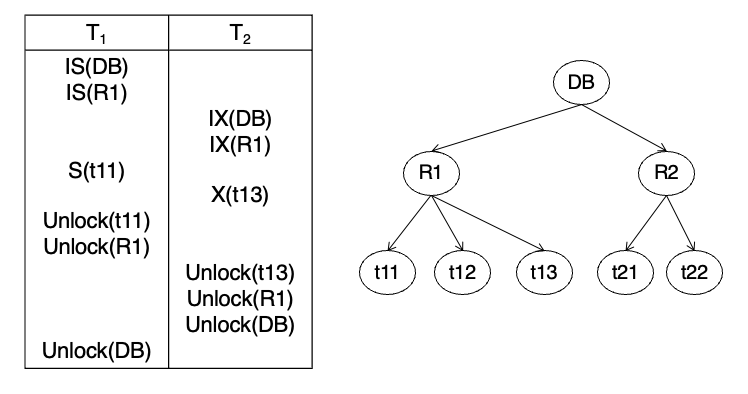
결과: no lock conflict, no waiting
왜 충돌이 없나?
T1은 R1 아래에서 t11을 읽기
T2는 R1 아래에서 t13을 쓰기 함
상위 노드에서는
- IS(DB) 와 IX(DB) 가능
- IS(R1) 와 IX(R1) 가능
그리고 하위에서는
- T1은 t11에 S
- T2는 t13에 X
즉 같은 relation R1 아래이긴 하지만 서로 다른 tuple을 접근하므로 충돌이 없음
노트도 이 예제를 통해 tuple-level locking을 지원하면 같은 테이블의 서로 다른 tuple을 동시에 접근 가능하다고 설명.
포인트
- 같은 테이블이라도 다른 tuple이면 동시 수행 가능
- 상위에서 IS/IX가 호환된다는 점을 실제 예제로 확인하는 문제
요약
예제 1은 "같은 테이블의 다른 tuple 접근은 MGL에서 동시에 가능"을 보여줌
PG29. MGL Example 2
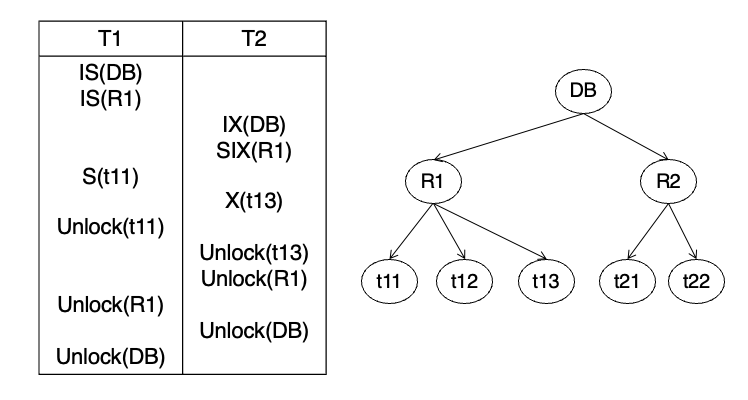
결과: no lock conflict
왜 충돌이 없나?
핵심은 IS(R1)와 SIX(R1)가 호환된다는 점.
호환성 행렬에서
- IS <-> SIX: 가능
따라서 T1은 R1 아래에서 일부를 읽고,
T2는 R1 전체를 읽는 성격 + 일부 쓰기 성격을 동시에 가질 수 있어도,
현재 구조에서는 충돌이 없는 것.
그리고 실제 하위 접근도
- T1은 t11
- T2는 t13
로 다르기 때문에 문제 없음
이 예제가 보여주는 것
SIX는 강한 모드이긴 하지만, IS와는 호환될 수 있다는 점을 보여줌
즉 "누군가 아래에서 읽으려는 의도(IS)"와 "나는 이 relation 전체를 읽고 일부를 수정할 것(SIX)"이 현재 노드 수준에서는 함께 존재 가능하다는 뜻.
포인트
- IS와 SIX 호환
- SIX는 전체 읽기 + 일부 수정
- 실제 하위 tuple이 다르면 동시 가능
요약
예제 2는 IS와 SIX가 호환될 수 있음을 보여주는 대표 예제
PG30. MGL Example 3
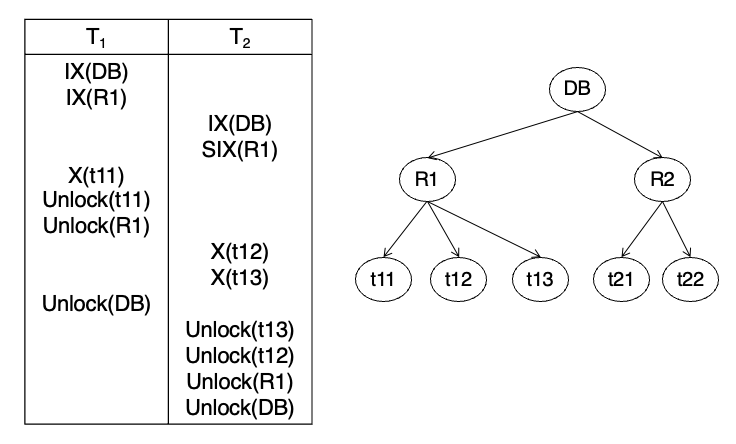
결과: T2의 SIX(R1)에서 lock conflict가 발생해서 T2가 그 지점에서 기다림 그리고 T1이 unlock(R1) 한 뒤에야 T2가 진행 가능함.
왜 충돌이 나나?
상위 DB에서는
- IX(DB)와 IX(DB) 가능
하지만 R1에서는
- T1이 IX(R1)
- T2가 SIX(R1)를 요청
호환성 행렬상
- IX <-> SIX = 불가능
그래서 T2는 R1에서 멈춰야 함.
T2가 R1 테이블에 SIX를 요구할 때 T1이 R1에 IX를 가지고 있으므로 충돌 발생.
그 시점에서 기다려야 하고, T1이 R1 unlock하면 lock manager가 T2를 깨워서 진행시킴.
이 예제가 중요한 이유
예제 1, 2는 둘 다 "동시 가능"이었는데,
예제 3은 상위 relation 수준에서 이미 충돌이 날 수 있다는 걸 보여줌.
즉 하위 tuple이 다르더라도, 상위 노드의 intention/mixed lock 모드 조합이 충돌하면 기다려야 한다는 뜻
포인트
- IX와 SIX는 호환 안 됨
- T2는 SIX(R1)에서 대기
- 대기 지점을 잘 찾는 문제가 나올 수 있음
요약
예제 3은 tuple이 아니라 relation 수준 lock 조합 때문에 대기가 발생하는 경우를 보여줌
2.3 Deadlock
PG32. Deadlock Example
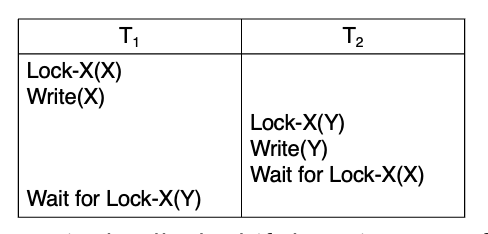
핵심 개념
슬라이드는 두 트랜잭션을 보져무
- T1: write(x) 다음 write(Y)
- T2: write(Y) 다음 write(X)
가능한 실행 순서 중 하나는
- T1이 먼저 X에 X-lock을 걸고 write(X)
- T2가 먼저 Y에 X-lock을 걸고 write(Y)
- 그 다음 T1은 Y에 X-lock이 필요해서 기다리고
- T2는 X에 X-lock이 필요해서 기다리게 되는 경우.
이렇게 되면 서로가 서로를 기다리므로 더 이상 진행하지 못한다. 이 상태가 deadlock.
슬라이드 정의대로, 어떤 트랜잭션 집합이 있고 그 집합의 모든 트랜잭션이 집합 안의 다른 트랜잭션을 기다리면 시스템은 deadlocked 상태라고 함
쉽게 이해하기
이건 "내가 가진걸 네가 원하고, 네가 가진건 내가 원하는" 상황
둘 다 자기 lock은 안 놓고 상대가 먼저 놓기만 기다리니까 무한 대기가 생김
포인트
- deadlock은 단순 대기(wait)와 다르다는 점
- deadlock은 서로 기다리는 순환 구조가 있다는 점
요약
deadlock은 서로 필요한 lock을 쥔 채 상대가 먼저 풀기만 기다리는 상태
PG33. Deadlock Handling
1. Timeout-based scheme
이 방식은 트랜잭션이 lock을 정해진 시간까지만 기다리게 하고, 시간이 지나면 timeout으로 보고 rollback 시키는 방식.
구현은 단순하고, 결과적으로 무한 대기는 방지할 수 있지만 문제도 있음
- starvation 가능
- 적절한 timeout 값 정하기 어려움
너무 짧으면 원래 곧 끝날 대기도 불필요하게 rollback 시키고, 너무 길면 deadlock을 오래 방치하게 됨.
2. Deadlock prevention protocol
아예 시스템이 deadlock 상태에 들어가지 못하게 설계하는 방식.
1) predeclaration
트랜잭션이 실행 시작 전에 자기가 필요한 모든 데이터를 한 번에 lock하게 하는 방법.
이론적으로는 deadlock을 막을 수 있지만, 실제로는 트랜잭션이 무슨 데이터를 다 접근할지 미리 정확히 아는 경우가 많지 않아서 실용성이 낮음.
2) partial ordering 부여
모든 데이터 item에 순서를 정해 두고 그 순서로만 lock하게 만드는 방식.
이건 앞에서 본 graph-based protocol과 연결되는 내용. 순서가 정해져 있으면 서로 반대 방향으로 lock을 요구하며 원형 대기에 빠질 가능성을 줄일 수 있음.
요약
deadlock handling은 기다리다 시간 지나면 끊는 방법(timeout)과, 애초에 deadlock이 안 생기게 규칙을 두는 방법(prevention)으로 나뉜다
PG34. Wait-die/Wound-wait Schemes
두 방식 모두 트랜잭션 timestamp를 사용해서 deadlock을 예방하는 방식.
그리고 둘 다 오래된(old) 트랜잭션이 유리하게 설계되어 있음.
rollback된 트랜잭션은 재시작할 때 원래 timestamp를 그대로 유지해야 starvation을 막을 수 있음
1. Wait-die
이건 non-preemptive 방식.
규칙은:
- old가 young을 기다리는 건 가능
- yound이 old를 기다리는 건 불가능 -> young이 die(rollback)
즉 충돌이 났을 때, lock을 새로 요청한 트랜잭션이 더 오래된 놈이면 기다리고, 더 젊은 놈이면 스르로 물러나.
강조하는 포인트는,
"둘 중 old는 wait하고 young은 die한다"가 아니라, 새롭게 lock을 요청한 트랜잭션 기준으로 old면 wait, young이면 die라는 것.
이미 lock을 쥐고 있던 쪽의 상태가 동시에 바뀌는 건 아님.
2. Wound-wait
이건 preemptive 방식.
규칙은:
- old가 young을 만나면 기다리지 않고 young을 rollback 시킴 -> wound
- young은 old를 기다릴 수 있음
즉 wait-die보다 old가 더 강하게 우선권을 가짐.
그래서 슬라이드에서는 wait-die보다 rollback 수가 더 적을 수도 있다고 말함.
3. 둘의 핵심 비교
- wait-die: old는 기다릴 수있고, young은 죽는다
- wound-wait: old는 상대를 죽이고, young은 기다릴 수 있다
그리고 두 방식 모두 rollback된 트랜잭션은 원래 timestamp 유지가 중요.
그래야 매번 새 트랜잭션처럼 더 젊어져서 계속 밀리는 starvation을 막을 수 있음.
포인트
- wait-die=non-preemptive
- wound-wait=preemptive
- 둘 다 old 우선
- 재시작 시 original timestamp 유지
요약
wait-die는 old가 기다리고 young이 죽는 방식, wound-wait는 old가 young을 강제로 죽이는 방식
PG35. Deadlock Detection (1/2): Wait-for Graph
핵심 개념
deadlock은 wait-for graph로 표현할 수 있음
그래프 G=(V,E)에서
- V: 시스템 안의 모든 트랜잭션
- E: 대기 관계를 나타내는 방향 간선
간선 -> 는
가 가 lock을 풀어주길 기다리고 있다는 뜻.
어떤 트랜잭션이 다른 트랜잭션이 현재 보유한 데이터를 요청하면, 그 순간 wait-for graph에 방향 간선이 추가됨.
그리고 가 더 이상 필요한 lock을 쥐고 있지 않게 되면 그 간선은 제거됨.
가장 중요
시스템이 deadlock 상태인 것은 wait-for graph에 cycle이 있을 때 그리고 그때뿐이다.
즉 deadlock detection은 결국 사이클 탐지 문제. 그래서 DBMS는 주기적으로 deadlock-detection algorithm을 돌려서 cycle이 있는지 검사해야함.
노트도 방향 그래프에서 cycle 감지는 간단하므로 감지 작업 자체는 비교적 단순하다고 설명
요약
wait-for graph에 사이클이 생기면 deadlock이다
PG36. Deadlock Detection (2/2): 그래프 해석
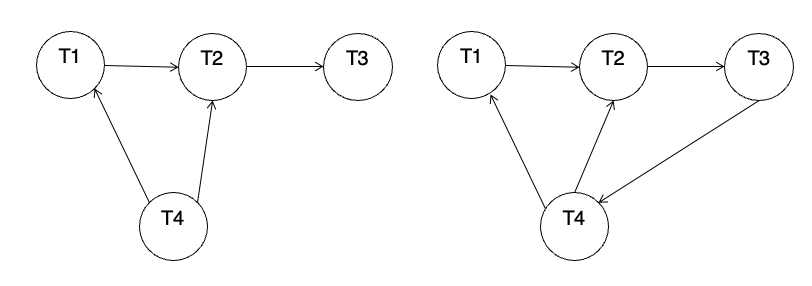
왼쪽: cycle 없음
오른쪽: cycle 있음
왼쪽 그래프는 대기 관계가 있더라도 원형으로 닫히지 않으므로 deadlock이 아님
오른쪽 그래프는 cycle이 존재하므로 deadlock 상태.
노트에서는 오른쪽 예시가 T2, T3, T4가 deadlock 상태라고 설명함.
또 트랜잭션 하나가 여러 트랜잭션을 동시에 기다릴 수도 있다는 점도 덧붙임.
왜냐하면 기다리는 lock이 여러 트랜잭션에 의해 공유될 수 있기 때문
포인트
문제로 그래프를 주고 deadlock 여부를 묻는다면, 사이클만 찾으면 된다
모든 대기 관계를 어렵게 해석할 필요 없이, 최종적으로 원형 대기가 있는지 보면 됨.
요약
대기가 많아도 cycle이 없으면 deadlock 아니고, cycle이 있으면 deadlock이다
PG37. Deadlock Resolution
핵심 개념
deadlock이 감지되면, 그냥 두면 안 풀리니까 어떤 트랜잭션 하나를 희생(victim) 시켜야 함.
즉 그 트랜잭션을 rollback해서 cycle을 끊어야함.
슬라이드는 rollback 비용이 가장 작은 victim을 고르는 게 이상적이라고 말함.
rollback 방식 두 가지
1) Total rollback
트랜잭션 전체를 abort하고 다시 시작하는 방식. 단순하지만 손해가 클 수 있음.
2) Partial rollback
deadlock을 깨는 데 필요한 지점까지만 되돌리는 방식.
슬라이드는 이게 더 효율적일 수 있다고 설명.
즉 무조건 처음부터 다시 할 필요 없이, 필요한 만큼만 철회.
starvation 문제
항상 같은 트랜잭션만 victim으로 고르면 starvation이 발생할 수 있음.
그래서 victim 선택 비용 계산ㅇ네 그 트랜잭션이 지금까지 몇 번 rollback당했는지도 포함해야 함.
그래야 특정 트랜잭션만 계속 희생되는 걸 막을 수 있음.
노트 보충
실제 상용 DBMS에서 current blocker를 철회하는 방식이 널리쓰인다고 설명.
current blocker는 wait-for graph에서 사이클을 완성시키는 마지막 대기 관계를 제공한 트랜잭션임.
예시로, 원래 deadlock이 아니던 그래프에 어떤 edge가 추가되면서 deadlock이 됐다면, 그 edge를 만든 쪽을 victim으로 보는 식.
lock wait 자체도 드물고, deadlock은 그보다 더 드물다는 뜻으로 정리.
요약
deadlock이 감지되면 cost가 작은 victim을 골라 rollback해서 cycle을 끊고, 같은 희생자가 반복되지 않게 해야함
2.4 Insert and Delete Operations
PG39. Insert/Delete 연산의 기본 원리
- delete는 지울 튜플에 대해 X-lock이 있어야 수행할 수 있음.
- insert도 새로 들어오는 튜플에 대해 X-lock이 부여.
즉 insert와 delete는 둘 다 데이터 변경 연산이니까, 읽기용 S-lock이 아니라 베타적 접근 X-lock이 필요하다는 뜻.
여기서 중요한 건, insert/delete는 단순히 "어떤 기존 튜플 하나를 읽고 쓰는 문제"가 아니라는 점.
새 튜플이 생기거나 기존 튜플이 사라지면서, 다른 트랜잭션이 보고 있는 '집합 자체'가 바뀔 수 있다는게 핵심.
요약
insert/delete는 X-lock이 필요하고, 문제의 핵심은 개별 튜플 변경이 아니라 결과 집합 변화 때문에 phantom이 생긴다는 점
Phantom Phenomenon이 뭔가
팬텀 현상은 내가 어떤 조건을 만족하는 튜플 집합을 읽는 중간에, 다른 트랜잭션이 그 조건에 해당하는 새 튜플을 넣거나 지워서 결과 집합이 바뀌는 현상
즉 나는 "같은 조건으로 같은 범위를 읽었다"고 생각하는데, 실제로는 중간에 유령처럼 새 튜플이 나타나거나 사라져서 결과가 달라지는 것.
중요한 건, 두 트랜잭션이 같은 튜플을 직접 건드리지 않아도 개념적으로는 충돌할 수 있다는 점.
이전까지의 lock 충돌은 보통 "같은 데이터 item을 같이 접근하느냐"로 생각했는데, 팬텀은 조건(predicate) 수준에서 충돌함.
예를 들어 "Busan에 있는 모든 계좌"라는 집합은 중간에 새 튜플이 들어오면 바뀌니까, 기존 튜플만 잠그는 tuple locking으로는 충분하지 않음.
요약
팬텀은 같은 튜플 충돌이 아니라, 같은 조건 결과 집합이 중간에 바뀌는 문제!
PG40. Phantom Phenomenon Example (1/2)
은행 데이터베이스

그리고 두 트랜잭션이 있음.
- T1: Account 테이블에서 Busan의 모든 계좌를 읽고, 그 합이 Assets[Bussan]과 맞는지 비교
- T2: 새로운 계좌 <400, Busan, 700>를 Account에 삽입하고, Assets[Busan]도 그에 맞게 갱신
즉 T1은 "Busan 계좌 전체 집합"을 보고 있고, T2는 그 집합 안에 새 원소를 하나 넣는 역할.
이때 두 트랜잭션은 기존 튜플을 꼭 직접 공유하지 않더라도, Busan 계좌 집합이라는 의미적 수준에서 충돌.
요약
T1은 Busan 계좌 전체를 검사하고, T2는 Busan 계좌를 새로 넣기 때문에 집합 수준에서 충돌
PG41. Phantom Phenomenon Example (2/2)
왜 이 실행이 non-serializable인가
슬라이드의 가능한 실행 순서는 아래와 같음

이 실행이 왜 문제냐면, T1은 Account를 읽을 때는 Busan 계좌가 200, 300 두 개뿐인 상태를 봤음.
그래서 T1이 Account에서 본 Busan 합계는 1000+500=1500이야. 그런데 나중에 읽은 Assets[Busan]은 T2가 수정해서 2200이 되어있음.
즉 T1 입장에서는 "Account 쪽 합계는 1500으로 보였는데, Assets는 2200이네?"라는 모순된 상태를 보게 됨.
슬라이드는 이 실행이 <T1, T2>직렬 실행도 아니고 <T2, T1> 직렬 실행도 아니므로 non-serializable이라고 말함.
왜냐하면
- <T1, T2>였다면 T1은 Account도 1500, Assets도 1500을 봐야 하고
- <T2, T1>였다면 T1은 Account에 새 계좌까지 포함된 2200과 Assets 2200을 봐야함.
그런데 실제로는 Account 쪽은 예전 집합, Assets는 갱신된 값을 보였으니 둘 중 어느 직렬 실행과도 같지 않음
요약
T1이 Account는 '삽입 전 상태'로 보고 Assets는 '삽입 후 상태'로 봐서, 어느 직렬 실행과도 일치하지 않으므로 non-serializable
왜 tuple locking만으로는 팬텀을 못 막나
tuple locking은 이미 존재하는 개별 튜플들만 잠그는 방식.
그런데 T2가 삽입하는 <400, Busan, 700>은 T1이 처음 읽을 때는 존재하지 않았던 새 튜플.
그러니까 T1이 기존 Busan 계좌튜플들을 S-lock으로 잘 보호했더라도, 아직 존재하지 않던 새 튜플의 삽입 자체는 막지 못할 수 있음
그래서 팬텀이 생김
즉 tuple locking은 "현재 있는 레코드" 충돌에는 강하지만,
"이 조건을 만족하는 레코드 집합 전체"를 보호하는 데는 약함.
팬텀은 바로 그 빈틈을 찌르는 현상.
요약
tuple locking은 기존 튜플은 보호해도, 새로 생기는 튜플 때문에 바뀌는 조건 결과 집합은 보호하지 못함
"테이블 락이면 왜 T2가 기다리나?" 정답
만약 table locking only를 쓴다면, T1이 Account 테이블을 읽을 때 Account 테이블 전체에 대한 S-lock을 가지게 됨.
그런데 T2가 새 튜플을 삽입하려면 Account 테이블을 변경해야 하니까 Account 테이블에 대한 X-lock이 필요.
S-lock과 X-lock은 호환되지 않으므로, T2는 insert(Account[400, Busan, 700]) 시점에서 T1이 lock을 풀 때까지 기다려야 함. 그래서 팬텀이 발생하지 않음.
즉 테이블 락을 쓰면 삽입 자체가 중간에 끼어들 수 없어서 phantom은 막히는데, 문제는 테이블 전체를 막아버리니까 동시성이 너무 낮아진다는 것.
요약
테이블 락에서는 T1의 Account 테이블 S-lock 때문에, T2의 Account 테이블 X-lock 요청이 막혀 삽입이 지연
PG42. How to Handle Phantom Problem
팬텀 문제 해결 흐름을 세 단계로 보여줌.
1. insert/delete가 없으면 phantom도 없음
당연히 새 튜플이 생기거나 지워지는 일이 없으면, "유령처럼 결과 집합이 바뀌는 현상" 자체가 생기지 않음.
하지만 현실의 데이터베이스는 시간이 지나면서 계속 바뀌니까, 이건 근본 해결은 아님.
2. table locking only
이론적으로는 팬텀을 막을 수 있음
하지만 테이블 전체를 잠그면 다른 트랜잭션이 그 테이블에서 거의 아무것도 못 하니까 동시성이 매우 낮아져서 실용적이지 않다고 말함
3. index locking
실제 해결책으로 많이 쓰는 건 index locking.
관계(relation)는 보통 적어도 하나 이상의 인덱스를 가지고 있고, 트랜잭션은 보통 인덱스를 통해 튜플을 찾게 되므로, 특정 index bucket / index node에 lock을 걸어 조건 집합 자체를 보호하는 방식이 가능.
슬라이드는 index locking이 higher concurrency while preventing phantom을 제공한다고 정리.
노트 설명이 정말 중요.
T1이 인덱스에 S-lock을 가지고 있으면, T2가 새로운 Busan 튜플을 넣으려면 인덱스도 함께 수정해야 하는데, 이때 필요한 인덱스 X-lock이 grant되지 못해서 삽입이 막힘. 그래서 팬텀이 방지됨.
요약
팬텀은 table locking으로 막을 수 있지만 비효율적이고, 실제로는 index locking 계열이 더 현실적인 해결책
PG43. Applying 2PL for Index
이 슬라이드는 "index에도 2PL을 엄격히 적용하면 팬텀을 막을 수 있다"는 내용을 설명.
- lookup 하는 트랜잭션은 접근한 모든 nonleaf/leaf 노드를 S-mode로 잠가야 함.
- leaf에 조건을 만족하는 튜플이 없어도, 그 leaf까지 잠겨야 함.
- insert/update/delete 하는 트랜잭션은 영향 받는 모든 nonleaf/leaf 노드에 X-lock을 걸어야 함.
- split/merge가 발생하면 부모 노드도 잠겨야함.
- 그리고 2PL을 준수해야함.
왜 이러면 phantom이 안 생기나
핵심은 조회 트랜잭션이 조건 범위를 결정하는 인덱스 경로와 leaf 영역 자체를 잠가 두기 때문
그러면 다른 트랜잭션이 그 범위에 새 튜플을 삽입하려면 관련 인덱스 노드를 바꿔야 하는데, 이미 조회쪽이 S-lock으로 잡고 있으니 필요한 X-lock을 못 얻음. 그래서 조건 결과 집합을 바꾸는 삽입/삭제가 중간에 끼어들 수 없어서 phantom이 안 생김
그런데 왜 비실용적이냐
슬라이드와 노트 둘 다 not practical이라고 함.
이유는 인덱스가 데이터베이스에서 아주 자주 접근되는 구조인데, 2PL 방식으로 끝까지 lock을 들고 있으면 동시성이 크게 떨어지기 때문.
특히 내부 노드까지 오래 붙잡고 있으면 병목이 심해짐.
요약
인덱스에 2PL을 엄격히 적용하면 phantom은 막히지만, 인덱스 접근이 너무 자주 일어나서 성능상 비효율적
PG44. Concurrency in Index Structures
이 슬라이드는 왜 인덱스에 일반적인 2PL을 그대로 쓰기 어려운지 강조.
- 인덱스는 원래 데이터 접근을 돕기 위한 구조
- 그래서 다른 일반 데이터 item보다 훨씬 자주 접근됨
- 여기에 2PL을 그대로 적용하면 low concurrency
- 그래서 가능하면 내부 노드 lock을 일찍 풀고 싶다고 말함. 즉 "not in a two-phase fashion"이라는 표현이 나옴
이 말은 곧, 인덱스에서는 "무조건 완전한 직렬가능성을 유지하려는 전통적 2PL"보다,
정확성을 해치지 않는 범위에서 좀 더 느슨하고 효율적인 프로토콜이 필요하다는 뜻.
요약
인덱스는 너무 자주 접근되므로, 일반 2PL처럼 끝까지 lock을 들고 있으면 동시성이 크게 떨어진다
PG45. Crabbing for Index Structures
슬라이드가 소개하는 대안 중 하나가 crabbing임.
B+-tree에서 쓰는 방식으로,
- 먼저 root를 S-mode로 lock
- 필요한 child를 lock한 뒤 parent lock 해제
- 삽입/삭제 시에는 leaf lock을 X-mode로 upgrade
- split/coalescing으로 부모 변경이 필요하면 부모를 X-mode로 lock
하는 식으로 진행함.
핵심 아이디어는 부모를 오래 붙잡지 말고 자식으로 내려가면서 lock을 옮겨가는 것
그래서 2PL보다 동시성은 나아질 수 있음. 하지만 슬라이드는 동시에 can cause excessive deadlocks 라고 적어둠.
노트도 split/merge 시 부모에 대한 lock을 다시 요청해야 하므로 deadlock이 많이 생길 수 있다고 설명함.
이름 의미
노트에서 "crab = 게"라고 설명하는데,
부모 잡고 자식 잡고 부모 풀고 또 이동하는 모습이 게가 옆으로 걷는 것처럼 보여서 crabbing이라고 부른다 함.
요약
crabbing은 부모 lock을 일찍 풀어 인덱스 동시성을 높이려는 방식이지만, split/merge 때 deadlock이 많이 생길 수 있음
PG46. Better protocols are available!!!
실제 상용 시스템 쪽 관점을 보여줌.
- 인덱스 정확성만 유지된다면, 인덱스 내부 노드에 대한 접근 자체는 꼭 serializable일 필요는 없다
- 그래서 parent lock을 먼저 풀고 child lock을 나중에 잡는 더 공격적인 방식도 허용
- 그 사이 구조가 바뀌면 그 변화에 맞게 다시 처리
- B+-tree 내부 노드에서 읽은 정확한 값 자체보다 결국 올바른 leaf node에 도달하는지가 더 중요하다고 설명
노트는 여기서 더 나아가, 실제 상용 시스템에서는 색인 구조 변경 시 latch 같은 더 낮은 수준의 동기화 도구를 사용해 구조 변경의 정확성을 보장한다고 설명함.
즉 트랜잭션 수준 lock과 자료구조 내부 latch를 적절히 섞는 것.
포인트
- 데이터 자체는 serializable하게 관리해야 하지만
- **인덱스 내부 구조는 "정확한 위치 찾기"만 보장되면 약간 느슨하게 관리할 수 있다
- 그래야 성능이 좋아진다
요약
실제 시스템은 인덱스 정확성만 유지되면 내부 접근은 다소 non-serializable해도 허용해 성능을 높인다**
2.5 Transaction Isolation in SQL
PG48. Transactions in SQL (1/2)
핵심 개념
SQL에서는 트랜잭션이 암시적으로 시작됨.
그리고 트랜잭션은 보통 두 가지 방식으로 끝남.
- COMMIT WORK: 현재 트랜잭션을 성공적으로 확정
- ROLLBACK WORK: 현재 트랜잭션을 취소(abort)
또 슬라이드가 강조하는 중요한 점은, 대부분의 DBMS에서 기본적으로 각 SQL 문장이 성공하면 자동으로 commit되는 auto-commit 모드가 많다는 것.
즉 사용자가 별도로 트랜잭션 블록을 묶지 않으면, 문장 하나가 사실상 하나의 트랜잭션처럼 동작하기 쉽다는 뜻.
포인트
- "SQL 트랜잭션은 명시적으로 begin 해야 하나?" -> 슬라이드 기준으로는 **implicitly begins
- "COMMIT과 ROLLBACK 차이"
- "auto commit이 의미하는 것"
요약
SQL 트랜잭션은 보통 암시적으로 시작하고, COMMIT 또는 ROLLBACK으로 끝나며, 실제 시스템은 auto-commit이 기본인 경우가 많음
PG49. Transactions in SQL (2/2)
핵심 명령어
- SET TRANSACTION
- COMMIT
- ROLLBACK
- SAVEPOINT
- ROLLBACK TO SAVEPOINT
SAVEPOINT 예제 해석

예시는 "Kim의 계좌에서 Lee의 계좌로 송금"이야.
- Kim 계좌에서 100 차감
- SAVEPOINT mySavePoint
- 실수로 Park 계좌에 100 추가
- 잘못된 계좌라는 걸 깨닫고 ROLLBACK TO mySavePoint
- 다시 Lee 계좌에 100 추가
- COMMIT
즉 SAVEPOINT는 트랜잭션 전체를 처음부터 날리는 게 아니라, 중간 특정 지점까지만 되돌릴 ㅅ ㅜ있게 해주는 체크포인트 역할. 그래서 실수 복구가 훨씬 유연해짐.
포인트
- ROLLBACK은 보통 트랜잭션 전체 취소
- ROLLBACK TO SAVEPOINT는 중간 지점까지만 복구
- SAVEPOINT는 "부분 rollback을 위한 기준점"으로 기억하면 됨.
요약
SAVEPOINT는 트랜잭션 중간 복구 지점이고, ROLLBACK TO SAVEPOINT는 그 지점까지만 되돌리는 기능
PG50. Weak Levels of Consistency
왜 약한 일치성을 허용하나
슬라이드는 일부 응용은 완전한 serializability까지는 필요 없고, 대신 더 빠른 성능을 원한다고 설명함.
예를 들면
- 대략적인 총 잔액만 보고 싶은 읽기 전용 트랜잭션
- 질의 최적화를 위한 통계 정보처럼 근사치여도 괜찮은 값
이런 경우에는 "완전히 정확한 값"보다 속도와 처리량이 더 중요할 수 있음. 그래서 SQL은 일부 non-serializable execution도 허용하는 방향으로 설계돼 있음.
슬라이드도 이걸 accuracy와 performance 사이의 tradeoff라고 정리함.
쉽게 말하면
모든 업무가 은행 이체처럼 "한 치의 오차도 허용 불가"는 아님.
어떤 건 통계, 집계, 모니터링처럼 "거의 맞으면 되는" 경우도 있어서, 그런 응용은 더 약한 isolation level을 써서 성능을 얻을 수 있다는 뜻.
요약
SQL은 정확도를 조금 더 희생해서라도 성능을 얻고 싶은 응용을 위해 약한 일치성 수준도 제공
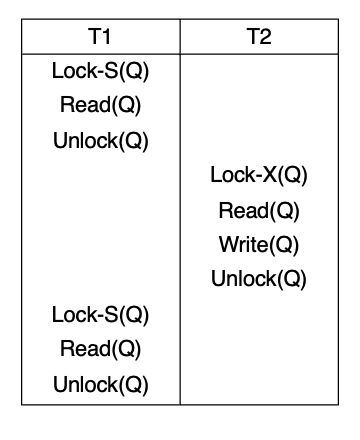
PG51. Degree-two Consistency
핵심 개념
슬라이드는 degree-two consistency를 2PL과 비교해서 설명함.
- S-lock은 언제든 해제 가능
- 새 lock도 언제든 흭득 가능
- 하지만 X-lock은 트랜잭션 끝까지 유지
- 그래서 serializability는 보장되지 않음
즉 앞에서 배운 2PL은 "한 번 unlock 시작하면 새 lock 금지"였는데, degree-two consistency는 그 제약을 품.
대신 쓰기 쪽 X-lock은 끝까지 잡아서 최소한 dirty update/lost update 쪽 문제를 줄이려는 구조라고 보면 됨.
왜 serializable이 아니냐
읽기 lock을 빨리 풀어버릴 수 있으니까, 같은 데이터를 두 번 읽을 때 중간에 다른 트랜잭션이 값을 바꿔서 결과가 달라질 수 있음. 즉 repeatable read가 보장되지 않음.
슬라이드도 "programmer must ensure that no erroneous database state will occur"라고 적어놈.
즉 이 수준에서는 개발자가 어느 정도 책임을 져야 함.
요약
degree-two consistency는 읽기 lock은 빨리 풀고, 쓰기 lock만 끝까지 유지하는 완화된 일관성 수준
Cursor Stability
슬라이드는 cursor stability를 degree-two consistency의 특수한 경우라고 설명함.
- 읽을 때는 각 tuple에 S-lock
- 읽고 나면 즉시 unlock
- X-lock은 트랜잭션 끝까지 유지
즉 커서가 현재 가리키는 행을 읽는 동안만 안정적으로 보호하고, 그 행이 지나가면 바로 읽기 lock을 풀어버리는 방식임. 그래서 읽기 성능은 좋아지지만, 같은 질의를 다시 했을 때 결과가 달라질 수 있음.
노트에서도 read committed가 많은 시스템에서 cursor stability로 구현된다고 연결해 설명하고 있음
요약
cursor stability는 "지금 읽는 행만 잠깐 보호하고 바로 푸는" 읽기 중심 완화 기법
PG52. Transaction Isolation in SQL (1/2)
본격적으로 SQL의 isolation level 네 가지가 나옴.
1. Serializable
슬라이드는 Serializable을 먼저 제시함.
이 수준은 직렬 실행과 동일한 효과를 목표로 하는 가장 강한 수준.
슬라이드 문구상 "the default"라고 되어 있지만, 바로 다음 슬라이드와 노트에서는 SQL 표준 측면의 기본값과 상용 DBMS의 실제 기본값을 구분해서 봐야 한다고 설명.
즉 개념적으로 가장 기본 레벨처럼 소개되지만, 실제 제품 기본 설정은 종종 다르다는 것.
2. Repeatable Read
- committed record만 읽음
- 같은 데이터를 다시 읽으면 같은 값이 나와야 함
- 그래서 읽은 데이터에 대한 read lock을 계속 유지하는 방향이 필요
- 하지만 슬라이드가 분명히 말하듯 phantom phenomenon은 꼭 막지 않아도 됨
즉 repeatable read는 "같은 row를 다시 읽으면 값이 바뀌지 않게 해주는 수준"이지, "조건 결과 집합 전체가 절대 안 바뀐다"까지는 아니라는 점이 중요. 이 차이가 serializable과의 핵심 차이.
3. Read Committed
- committed data만 읽음
- 슬라이드에서 degree two consistency와 같고, 대부분 시스템은 cursor stability로 구현한다고 설명
즉 dirty read는 막지만, 같은 값을 다시 읽었을 때 결과가 달라질 수는 있음.
4. Read Uncommitted
- uncommitted data도 읽을 수 있음
- 가장 약한 수준
정리
슬라이드는 serializable을 제외한 나머지 3개는 non-serializable execution을 허용한다고 설명함.
즉 Repeatable Read, Read Committed, Read Uncommitted는 강도 차이는 있지만 모두 "완전직렬화"는 아님.
요약
Serializable > Repeatable Read > Read Committed > Read Uncommitted 순으로 강하고, 뒤로 갈수록 성능은 좋아질 수 있지만 일관성은 약해짐
PG53. Transaction Isolation in SQL (2/2)
설정 문법
SET TRANSACTION [READ ONLY | READ WRITE] ISOLATION LEVEL [Serializable | Repeatable Read | Read Committed | Read Uncommitted];
기본값 관련 주의
SQL2 기본값 쪽으로
- READ WRITE
- SERIALIZABLE
- READ UNCOMMITTED이면 READ ONLY
라고 적혀있음. 그런데 바로 아래에서
"many commercial database systems, read committed is the default consistency level"
이라고 따로 말함.
즉 정리하면,
- 표준(SQL2) 관점의 기본값
- 상용 DBMS 제품의 실제 기본값
을 구분해야함.
실무에서는 보통 Read Committed가 기본인 경우가 많아서, 정말 serializable이 필요하면 명시적으로 바꿔야 한다고 함.
요약
SQL 표준 기본값과 상용 DBMS 실제 기본값은 다를 수 있고, 실무에서는 Read Committed가 기본인 경우가 많다
PG54. Transaction Isolation Effect
이 표는 isolation level에 따라 어떤 lock 프로토콜과 보호 효과가 있는지 요약해줌.
Read Uncommitted
- 쓰는 데이터에는 long exclusive lock
- 하지만 읽을 때는 사실상 dirty read 허용
- 그래도 lost update는 막음
- 슬라이드 표가 흥미로운 점은, 가장 약한 수준이어도 쓰기 lock을 끝까지 들고 있으므로 "내 dirty data를 남이 덮어쓰지 못하고, 나도 남의 dirty data를 덮어쓰지 않는다"고 설명한다는 점.
Read Committed
- 쓰기에는 long X-lock
- 읽을 때는 short share lock
- 보호 효과: No lost update, No dirty read
즉 읽고 바로 공유 lock을 푸니까, 같은 행을 나중에 다시 읽으면 값이 바뀔 수 있음.
repeatable read까지는 안 보장됨.
Serializable
- 쓰기에는 long X-lock
- 읽기에도 long S-lock
- 보호효과: No lost update, No dirty read, Repeatable read
즉 읽은 데이터도 끝까지 보호해서 가장 강한 격리 수준을 제공함.
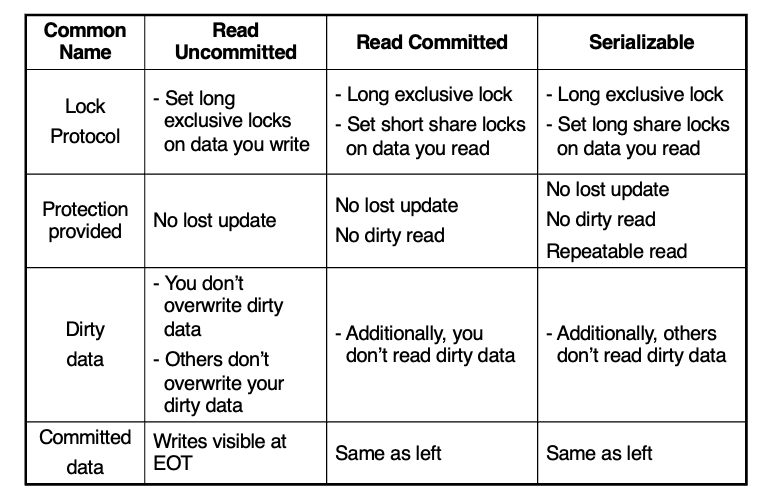
요약
표 기준으로 Read Uncommitted는 lost update만 막는 약한 수준, Read Committed는 dirty read까지 막고, Serializable은 repeatable read까지 보장하는 가장 강한 수준
PG55. Transaction Isolation Example
좌석 예약 예제로 보는 Isolation Level 차이
기본 절차
- 빈 좌석을 찾는다
- 그 좌석을 occupied=1로 바꿔 예약한다
- 고객 승인 받는다
- 승인 안 하면 occupied=0으로 다시 풀고, 다른 좌석을 찾는다
Read Uncommitted
슬라이드는
"모든 좌석이 찼다고 들었는데, 나중에 좌석이 풀릴 수 있다"
고 설명함. 즉 아직 commit도 안 된 중간 상태까지 읽어버릴 수 있어서, 신뢰성이 매우 낮다는 뜻.
Read Committed
매번 질의할 때마다 서로 다른 available seats 집합을 볼 수 있음.
왜냐하면 다른 트랜잭션이 그 사이에 예약하거나 취소하면서 commit한 결과가 보이기 때문.
즉 dirty read는 없지만 non-repeatable read가 가능.
Repeatable Read
슬라이드는
"한 번 available로 본 seat는 다음 질의에서도 계속 available로 남아 있다"
고 설명함. 즉 같은 좌석 row에 대해서는 값이 안정적.
하지만 새 좌석이 중간에 생성되면 다음 질의에서 안 보일 수 있다고 적혀 있음. 이건 바로 팬텀 문제와 연결됨.
즉 repeatable read는 row 값 반복성은 보장하지만, 집합 전체의 변화는 막지 못할 수 있다는 뜻.
요약
Read Uncommitted는 너무 불안정하고, Read Committed는 매번 결과가 달라질 수 있으며, Repeatable Read는 같은 row 값은 유지되지만 팬텀까지는 못 막을 수 있다
PG56. Recap
- 2PL vs tree-based locking
- MGL: S, X, IS, IX, SIX / root-to-leaf lock, leaf-to-root unlock
- Deadlock: wait-die, wound-wait, WFG, timeout
- Phantom phenomenon: index locking
- Transaction isolation: serializable, repeatable read, read committed, read uncommitted
즉 이번 장 전체는
"락 기반 동시성 제어 -> deadlock -> phantom -> SQL isolation level"
이 흐름으로 이어지는 것.
그리고 2.5는 그중 마지막 "SQL이 실제로 사용자에게 어떤 수준을 선택하게 하는가"에 해당.
요약
2.5는 앞에서 배운 락/팬텀/직렬가능성 이론을 SQL의 실제 isolation level 옵션으로 연결하는 단원
