
* 이 글은 학부생 시절 개인 Notion에 작성했던 강의 필기 노트를 Velog에 옮긴 글입니다.
📗: 운영체제 제10판 | Abraham Silberschatz, Peter Baer Galvin, Greg Gagne 저/박민규 역 | 퍼스트북
배경
프로그램 코드는 실행 시 메모리에 적재되어 있어야 하지만, 전체 프로그램의 사용은 빈번하지 않음
→ 프로그램의 일부만 메모리에 적재하고 실행(나머지는 디스크에 적재)
이점
- 더 이상 물리 메모리의 크기 제약을 받지 않음
- 각 프로그램 실행 시 메모리를 덜 차지함
- 동시에 더 많은 프로그램의 실행이 가능
- 응답 시간이 증가하지 않으면서 CPU 활용도와 효율성 증대
- 프로그램을 메모리로 적재하거나 스왑 시 더 적은 I/O 횟수 필요
- 각 사용자 프로그램이 더 빨리 실행
가상 메모리는 실제의 물리 메모리 개념과 사용자의 논리 메모리 개념을 분리
- 프로그램의 일부만 메모리에 적재하고 실행
- 물리 주소 공간 보다 훨씬 큰 논리 주소 공간(가상 주소 공간) 을 제공
- 여러 프로세스들에게 공유되는 주소 공간을 허용
- 효율적인 프로세스 생성이 가능
- 더 많은 프로그램들이 병행 실행 될 수 있음
- 프로그램을 메모리로 적재하거나 스왑 시 더 적은 I/O 횟수 필요
가상 메모리 공간은 프로세스가 메모리에 저장되는 논리적인 관점
- 0번지 주소부터 시작되는 연속적인 주소 공간
- 반면, 물리 메모리는 페이지 프레임들로 구성
- 때문에 프로그램이 분할 되고, 비 연속적으로 물리 메모리에 배치됨
- 논리 주소를 물리 주소로 변환하는 MMU 필요
가상 메모리 구현
- 요구 페이징
- 요구 세그멘테이션
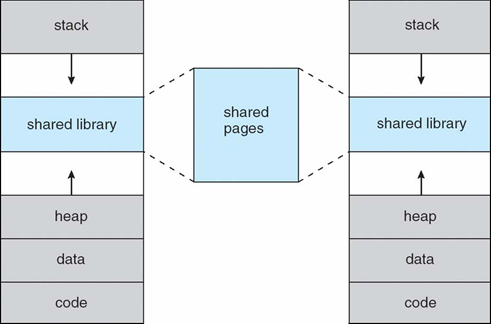
프로세스의 가상 주소 공간
일반적으로 논리 주소 공간의 최대 주소에서 스택이 시작되어 낮은 주소로 확장되고, 힙은 높은 주소 방향으로 확장
- 두 영역 사이의 사용되지 않는 주소 공간은 빈 영역(hole)
- 확장될 빈 영역(성긴 주소)에 동적 연결 라이브러리 등이 배치
- 시스템 라이브러리 등은 가상 주소 공간을 매핑하여 공유
요구 페이징
프로세스 전체를 메모리에 적재하지 않고, 필요한 페이지 만을 물리 메모리에 적재
- 스와핑을 갖는 페이징 시스템과 유사
- 게으른 스와퍼
- 페이지가 필요하지 않으면 메모리를 적재하지 않음
- 페이지를 관리하는 스와퍼를 페이저라 함
기본 개념
- 페이저가 필요한 페이지들을 메모리에 적재
- 메모리에 적재될 페이지들은 어떻게 결정하는가? → 요구 페이징을 위해 새로운 MMU 기능이 필요
- 필요한 페이지들이 이미 메모리에 있으면? → 요구 패키징이 아닌 시스템과 다를 게 없음
- 필요한 페이지들이 메모리에 없으면? → 이를 감지하여 저장 장치에서 메모리로 페이지 적재
유효-무효 비트
페이지가 메모리에 올라와 있는지 구별하기 위해 페이지 테이블에 유효-무효 비트 표시
- 유효 비트(v,valid)로 세트되면 페이지가 메모리에 있음을 표시
- 무효 비트(i, invalid)로 세트되면 페이지가 메모리에 없음을 표시
- 초기에는 i로 지정
주소 변환 중 무효 비트 i로 세트되어 있으면 페이지 부재 발생
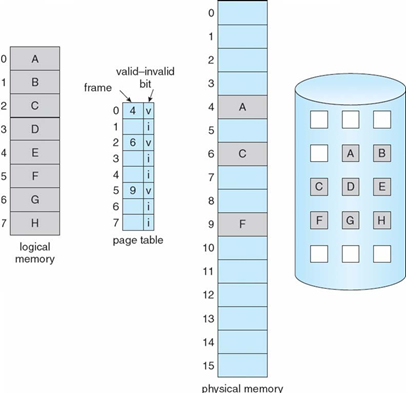
페이지 부재
프로세스가 메모리에 올라와 있지 않는 페이지를 접근하는 경우 페이지 부재 트랩(인터럽트)이 발생
페이지 부재 처리 과정
- 운영체제는 내부 테이블(PCB와 함께 유지)을 검사하여 메모리 참조가 유효한지 무효한지 조사
- 무효한 참조 → 프로세스 중단
- 메모리에는 없는 유효한 참조
- (b)인 경우 빈 공간 즉, 자유 프레임을 검색
- 새로 할당된 프레임으로 해당 페이지를 읽어 들이도록 요청
- 페이지 테이블을 갱신(유효 비트 세트)
- 페이지 부재 트랩에 의해 중단되었던 명령어를 다시 수행

요구 페이징의 성능
유효 접근 시간
=(1-p) ma + P 페이지 부재 처리 시간
- p: 페이지 부재 확률 0 ≤ p ≤ 1.0
- ma: 메모리 접근 시간
- 페이지 부재 처리 시간: 인터럽트 처리,페이지 읽기, 프로세스 재 시작
Ex) 메모리 접근 시간: 200ns
페이지 부재 처리 시간: 8ms (ns: 10^(-9), ms: 10^(-3) 즉, 1,000,000ns=1ms)
유효 접근 시간?
= (1-p) 200ns + p 8,000,000ns
=200+7,999,800 * p
1000번에 한번 페이지 부재가 발생한다면(p=0.1%) 유효 접근 시간은 8.2us
→ 요구 페이징으로 인해 40배 느려짐
쓰기 시 복사
가상 메모리는 프로세스 생성(fork()) 시 페이지를 공유하여 생성 시간을 줄임 (원래는 fork() 시 주소 공간이 각자 있었음 )
쓰기 시 복사
- 자식 프로세스가 시작할 때 부모의 페이지를 당분간 함께 공유하여 사용
- 둘 중 한 프로세스가 공유 중인 페이지에 쓸 때 페이지의 복사본이 생성
- 수정되는 페이지만 복사본을 만들어 효율적인 프로세스 생성

fork() 직후. 수정이 없을 때

프로세스 1이 페이지 c를 수정 한 후
페이지 교체
모든 메모리가 사용 중이어서 빈 프레임이 없는 경우 페이지 교체를 수행한다.
페이지 교체 알고리즘
- 사용 중인 페이지 중 하나를 선택하여 교체
- 새로운 페이지는 메모리로 가져옴
- 교체되는 페이지(victim)는 디스크에 저장
- 수정된 페이지 만을 디스크에 저장하여 페이지 전송 오버헤드를 줄임(변경이 없는 페이지는 이미 디스크에 있기 때문에 메모리 페이지를 저장할 필요가 없다 )
- 변경 비트 사용(1이면 변경됨을 나타냄)
- 성능
- 페이지 부재가 최소가 되도록 기대
- 일부 페이지는 자주 교체되어 메모리에 여러 번 가져오는 경우도 발생
FIFO 페이지 교체
가장 오래된 페이지를 내쫓는다. 큐 사용.

Belady의 모순
FIFO는 Belady의 모순 발생
→ 프레임을 더 주었는데 오히려 페이지 부재율이 증가하는 현상

최적 페이지 교체
앞으로 가장 오랫동안 사용되지 않을 페이지를 찾아 교체

앞으로 가장 오랫동안 사용되지 않을 페이지를 어떻게 알 수 있는가?
→ 미래(순서)를 알아야 한다… 지역성이라는 특성을 이용하면 미래 예측이 어느 정도 가능
LRU 페이지 교체
최근의 과거를 가까운 미래의 근사치로 추정
- 가장 오랜 기간 동안 사용되지 않은 페이지를 교체
- LRU(Least Recently Used)


LRU 알고리즘 구현
두 가지의 구현 방법이 가능하다.
-
계수기(counter)
- 각 페이지 항목마다 계수기 추가
- 페이지 참조마다 계수기 증가
- 페이지 교체 시 가장 작은 값의 계수기의 페이지를 교체
- LRU 페이지를 찾기 위해 페이지 테이블을 검색 해야 함
- 메모리 참조마다 계수기 갱식을 위해 메모리 쓰기 작업 필요
-
스택(stack)
- 페이지 번호의 스택을 유지(스택은 보통 이중 연결 리스트로 구현)
- 페이지가 참조될 때마다 페이지 번호는 스택 중간에서 제거되어 스택 꼭대기(top)에 놓임
- 페이지 테이블 검색 필요 없음
- 포인터 값 변경 오버헤드 발생
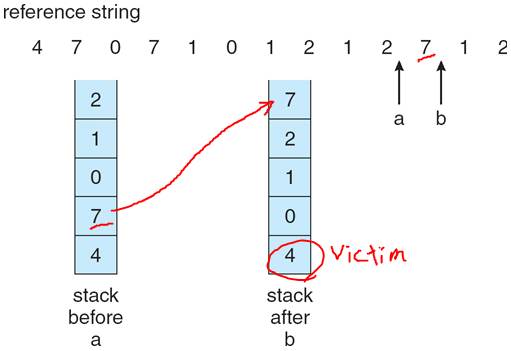
LRU 근사 페이지 교체
LRU 교체 알고리즘은 하드웨어 오버헤드가 큼
LRU 근사 페이지 교체
- 페이지 항목에 1비트 참조 비트 사용
- 참조 비트는 0으로 초기화하고, 페이지가 참조되면 1로 세트
- 참조 비트가 0인 페이지를 교체함
- 페이지가 사용된 순서는 모름
부가적 참조 비트 알고리즘
일정한 간격마다 참조 비트들을 기록함으로써 추가적인 선후 관계 정보를 얻음
- 각 페이지에 대해 8비트의 시프트 레지스터 할당
- 일정한 시간 간격마다 타이머 인터럽트
- 참조 비트는 8 비트 정보의 최상위 비트로 이동
- 나머지 비트들은 하나씩 오른쪽으로 이동
- 가장 최근 8구간 동안의 그 페이지의 사용 기록을 저장
Ex) 00000000 → 페이지를 한 번도 사용하지 않음
11000100인 페이지는 0110111인 페이지 보다 더 최근에 이용
2차 기회 알고리즘
참조 비트를 사용하고 클록 교체라고도 함
- 교체될 페이지를 순서대로 조사
- 참조 비트가 1이면 0으로 세트하고 한 번 더 기회를 줌
- 참조 비트가 0이면 해당 페이지를 교체
- 순환 큐를 사용하여 구현
- 포인터(시계의 침)가 다음에 교체될 페이지를 가리킴
개선된 2차 기회 알고리즘
(참조 비트, 변경 비트) 두 개의 비트를 조합하여 등급을 설정
- (0,0) 최근에 사용되지도 변경되지도 않은 경우 → 교체하기 가장 좋은 페이지
- (0,1) 최근에 사용되지는 않았지만 변경은 된 경우 → 이 페이지가 교체되면 디스크에 내용을 기록해야 하기 때문에 교체에 적당하지 않음
- (1,0) 최근에 사용은 되었으나 변경은 되지 않은 경우 → 이 페이지는 곧 다시 사용될 가능성이 높음
- (1,1) 최근에 사용도 되었고 변경도 된 경우 → 아마 곧 다시 사용될 것이며 교체되면 디스크에 그 내용을 먼저 기록해야 함
페이지 교체가 필요할 때 클록 알고리즘과 같은 방법을 사용(가장 낮은 등급이면서 처음 만난 페이지를 교체)
계수 기반 페이지 교체
-
LFU(Least Frequently Used) 알고리즘
참조 횟수가 가장 작은 페이지를 교체
→ 활발하게 사용되는 페이지는 참조 횟수 값이 클 것이다
-
MFU(Most Frequently Used) 알고리즘
가장 작은 참조 횟수를 가진 페이지가 가장 최근 참조된 것이고 앞으로도 사용될 것이다
페이지 버퍼링 알고리즘
페이지 교체 알고리즘과 병행하여 적용
가용 프레임 여러 개를 풀(pool)에 저장(버퍼링)
- 페이지 부재 시 새로운 페이지를 풀로 먼저 읽음(교체될 프레임 디스크 쓰기 전)
- 교체될 프레임을 가용 프레임 풀에 추가
- 편리한 시점에 교체될 프레임을 디스크에 저장
가용 프레임 풀은 유지하면서 프레임의 임자 페이지를 기억할 수도 있음
- 이 프레임 재 참조 시 디스크를 읽을 필요가 없음
- 희생 페이지를 잘못 선정한 경우 유용
프레임의 할당
각 프로세스에게 할당해야 하는 프레임 수 결정 문제
- 최소 프레임 수는 아키텍처에 의해 결정
- 최대 프레임 수는 가용 물리 메모리에 의해 결정
할당 알고리즘
- 균등 할당 모든 프로세스에게 똑같이 할당 ex) 5개의 프로세스, 93개의 프레임일 때 → 프로세스 당 18개의 프레임 균등 할당, 3개는 자유 프레임 버퍼 풀
- 비례 할당 각 프로세스의 크기 비율에 맞추어 할당

- 우선순위 할당 비례 할당 방법을 사용하면서 프레임 비율을 프러세스의 크기가 아닌 우선순위를 사용하여 또는 크기와 우선순위의 조합을 사용하여 결정
전역 대 지역 할당
- 전역 교체
- 교체할 프레임을 다른 프로세스에 속한 프레임을 포함한 모든 프레임을 대상으로 찾는 경우
- 프로세스 실행 시간이 크게 변함
- 높은 메모리 이용률
- 지역 교체
- 각 프로세스가 자기에게 할당된 프레임들 중에서만 교체될 희생자를 선택
- 일관된 프로세스의 성능
- 낮은 메모리 이용률
스레싱
교체된 페이지가 얼마 지나지 않아 다시 사용되는 반복적인 페이지 부재가 발생하는 상황
요구 페이징과 스레싱
요구 페이징은 지역성 모델에 기반하여 동작한다.
지역성이란, 집중적으로 함께 참조되는 페이지들의 집합을 의미함
- 스레싱의 발생 원인 어떤 프로세스가 새로운 지역(메모리) 으로 진입할 때 필요한 크기보다 적은 프레임을 할당하게 되면 페이지 부재가 자주 발생
- 스레싱 방지
- 프로세스가 필요로하는 최소한의 프레임 수 보장
- 작업 집합 방법 사용하여 프로세스가 사용하는 프레임 수 조사
작업 집합 모델
- 작업 집합 창, △
-
△=고정된 페이지 참조 횟수
-
최근 △회 만큼의 페이지 참조를 관찰
-
한 프로세스가 최근 △번 페이지를 참조했다면 그 안에 들어있는 서로 다른 페이지들의 집합을 작업 집합 이라고 함

-
- 모든 프로세스의 전체 프레임 요구량, D
- D=시그마 WSS(i)
- WSS(i): 프로세스 P(i)의 작업 집합 크기
- D > m(가용한 총 프레임 수)이면 스레싱
- 프로세스 중 하나를 중지하고 그 프로세스의 페이지들은 다른 프로세스에게 할당하여 스레싱 예방
중요 작업 집합과 페이지 부재율

페이지 부재율의 고점은 새로운 지역으로 들어가 요구 페이징이 시작되는 경우에 발생한다. 새로운 지역의 작업 집합이 메모리에 올라오고 나면 부재율은 낮아진다. 어떤 고점으로부터 다음 고점까지의 시간 간격은 한 작업 집합에서 다른 작업 집합으로의 전이를 나타낸다.
