
* 이 글은 학부생 시절 개인 Notion에 작성했던 강의 필기 노트를 Velog에 옮긴 글입니다.
📗: 운영체제 제10판 | Abraham Silberschatz, Peter Baer Galvin, Greg Gagne 저/박민규 역 | 퍼스트북
배경
기본 하드웨어
각각의 프로세스는 독립된 메모리 공간을 가짐.
특정 프로세스만 접근할 수 있는 합법적인 메모리 주소 영역을 설정하고, 프로세스가 합법적인 영역만을 접근하도록 보호해야 함.
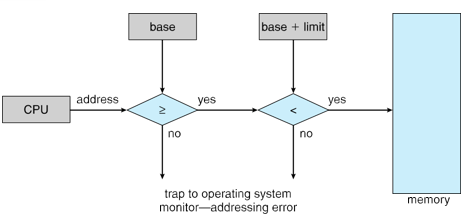
메모리 공간의 보호는 CPU 하드웨어가 사용자 모드에서 만들어진 모든 주소와 레지스터를 비교함으로써 이루어짐.
- 베이스(base) 레지스터: 가장 작은 합법적인 물리 메모리 주소의 값을 저장
- 상한(limit) 레지스터: 주어진 영역의 크기를 지정
논리 주소 공간 구조
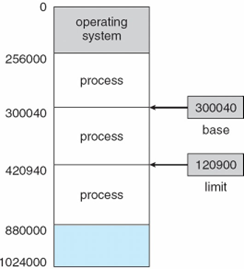
베이스와 상한 레지스터를 통한 주소 보호
주소의 할당
프로그램이 실행되기 위해서는 메인 메모리에 적재되어 프로세스가 되어야 함
입력 큐(디스크에서 메인 메모리로 적재되기를 기다리고 있는 프로세스들의 집합)에서 하나의 프로세스를 선택해서 메모리에 적재 후 실행, 프로세스가 실행되는 동안 메모리에서 명령어와 자료를 엑세스
주소는 각 단계에서 다양하게 표현
- 소스 코드에서는 심볼(변수)로 표현
- 컴파일된 코드에서는 재배치 가능한 주소로 바인딩(Ex. 모듈의 시작에서부터 14바이트)
- 링커나 로더는 재배치 가능한 주소를 절대주소로 바인딩
- 각 바인딩 과정은 한 주소 공간에서 다른 주소 공간으로 맵핑
명령어와 자료의 바인딩은 시점에 따라 다음과 같이 구분
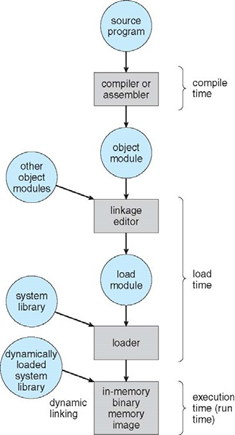
- 컴파일 시간 바인딩
- 프로세스가 메모리 내에 들어갈 위치를 컴파일 시간에 미리 알 수 있으면 컴파일러는 절대 코드를 생성할 수 있음
- 만일 이 위치가 변경되어야 한다면 이 코드는 다시 컴파일 되어야 함
- 적재 시간 바인딩
- 프로세스가 메모리 위치를 컴파일 시점에 알지 못하면 컴파일러는 일단 이진코드를 재배치 가능 코드로 만들어야 함
- 실행 시간 바인딩
- 프로세스가 실행하는 중간에 메모리 내의 한 세그먼트로부터 다른 세그먼트로 옮겨질 수 있다면 바인딩이 실행 시간까지 지연
- 특별한 하드웨어 지원이 필요(베이스,상한 레지스터 사용)
논리 vs 물리 주소 공간
논리 주소: CPU(프로그램)가 생성하는 주소
물리 주소: 메모리가 취급하게 되는 주소(즉, 메모리 주소 레지스터 MAR 에 주소지는 주소)
바인딩 기법
- 컴파일 또는 적재 시 바인딩 기법: 논리=물리
- 실행 시간 바인딩 기법: 논리≠물리, 이 경우 논리 주소를 가상 주소라 함
메모리 관리 장치(MMU)
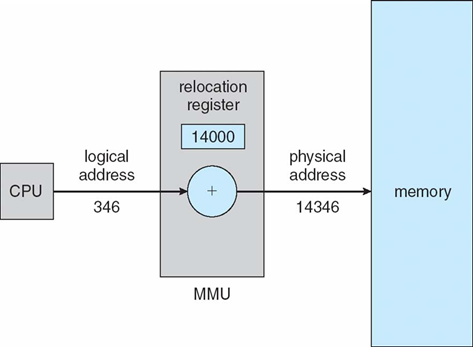
- 가상 주소를 물리 주소로 변환하는 하드웨어 장치
- 사용자 프로세스에 의해 생성된 모든 주소에 재배치 레지스터의 값이 더해짐
- 재배치 레지스터는 일종의 기준 레지스터(base)
사용자 프로그램은 논리 주소만을 다루고 실제적인 물리 주소를 결코 알 수 없음
→ 메모리 참조 시 실행시간 바인딩이 발생
동적 적재
동적 적재에서 각 루틴은 실제 호출되기 전까지는 메모리에 올라오지 않고 재배치 가능한 상태로 디스크에서 대기
장점
- 향상된 메모리 공간 활용
- 사용되지 않는 루틴은 메모리에 적재되지 않음
- 오류 처리 루틴과 같이 아주 간혹 발생하면서도 많은 코드를 필요로 하는 경우 유용
동적 적재는 운영체제로부터 특별한 지원을 필요로 하지 않음
- 사용자 자신이 프로그램의 설계를 책임
- 운영체제는 동적 적재를 구현하는 라이브러리 루틴을 제공
동적 연결 및 공유 라이브러리
- 정적 연결: 로더에 의해 시스템 라이브러리와 프로그램 코드가 이진 프로그램 이미지로 결합
- 동적 연결: 연결이 실행시간 까지 연기, 주로 공유 라이브러리에 사용
동적 연결을 지원하지 않으면 모든 시스템 라이브러리를 호출하는 프로그램들은 그들의 이진 프로그램 이미지 내에 시스템 라이브러리 루틴들을 한 부씩 가지고 있어야 함
내부 동작 루틴
- 작은 코드 조각인 스텁을 사용하여 메모리에 적재된 라이브러리의 위치를 찾음
- 라이브러리가 메모리에 없으면 로더를 실행하여 디스트에서 가져옴
- 메모리에 있으면 스텁 자신을 찾아낸 루틴의 번지로 대체하고 실행
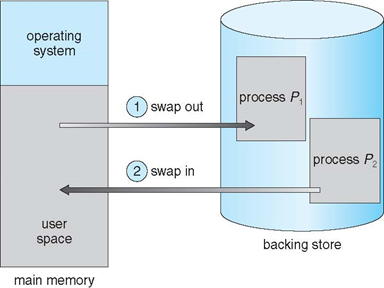
스와핑
프로세스는 실행 도중에 임시로 보조 메모리(디스크)로 보내졌다가 다시 메모리로 되돌아올 수 있으며, 이를 스와핑이라 한다,
스와핑은 우선순위 기반 스케줄링 알고리즘에 적용될 수 있음
- 낮은 우선순위 프로세스를 디스크로 스왑
- 높은 우선순위 프로세스가 끝나면, 낮은 우선순위 프로세스는 다시 메모리로 스왑
- 우선순위 기반 알고리즘에서 사용되는 스와핑의 변형을 롤 인, 롤 아웃이라고 함
스왑 시간의 대부분이 디스크 전송 시간 → 전송 시간은 스왑될 메모리의 크기와 비례
연속 메모리 할당
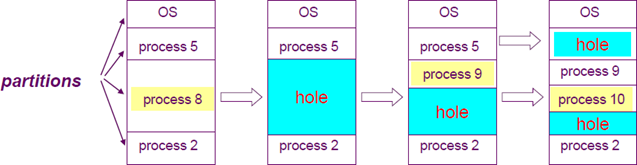
메모리는 일반적으로 운영체제와 사용자 프로세스들, 두 개의 부분으로 분할
연속 메모리 할당 시스템에서 각 프로세스는 연속된 메모리 공간을 차지한다.
메모리 할당
사용 가능한 메모리 블록인 공간(hole)의 크기가 다양하며(가변 분할) 메모리에 분산되어 있음
새 프로세스가 도착하면 이를 수용할 수 있는 충분한 크기의 공간을 할당
운영체제는 할당된 분할과 가용한 분할(hole)에 관한 정보를 유지해야 함
동적 메모리 할당 문제
일련의 가용 공간-리스트로부터 크기 n-바이트 블록을 요구하는 것을 어떻게 만족시켜 줄 것이냐를 결정하는 문제
- 최소 적합
- 첫 번째 사용 가능한 공간을 할당
- 최적 적합
- 사용 가능한 공간들 중에서 가장 작은 것을 선택
- 리스트가 정렬 되어 있지 않으면 전 리스트를 검색
- 많은 작은 공간들이 생성
- 최악 적합
- 가장 큰 공간을 선택
- 리스트가 정렬 되어 있지 않으면 전 리스트를 검색
- 할당하고 남게 되는 공간은 충분히 커서 다른 프로세스들을 위하여 유용하게 사용
단편화
단편화는 공간 중 일부가 사용 못하게 되는 것을 말함
- 외부 단편화: 유휴 공간들을 모두 합치면 충분한 공간이 되지만 그것들이 너무 작은 조각들로 여러 곳에 분산되어 있을 때 발생(최초 적합, 최적 적합에서도 발생)
- 내부 단편화: 일반적으로 메모리는 고정된 크기의 정수 배로 할당되어 할당된 공간이 요구된 공간보다 약간 더 클 수 있는데, 이들 두 크기 사이의 남는 부분
외부 단편화는 압축을 하여 해결 가능
메모리의 모든 내용들을 한군데로 몰고 모든 자유 공간들을 다른 한 군데로 몰아서 큰 블록을 생성
압축은 프로세스들의 재배치가 실행 시간에 동적으로 이루어지는 경우에만 가능
세그먼테이션
사용자 관점에서 지원되는 메모리 관리 방식
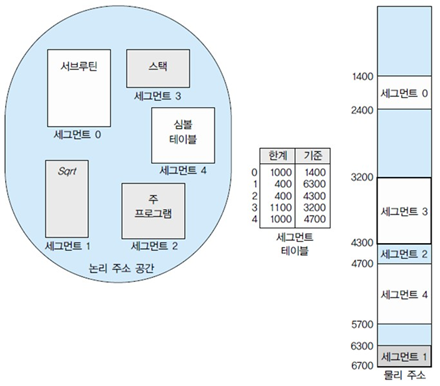
프로그램은 세그먼트의 집합이며, 세그먼트는 다음과 같은 것들의 논리적 단위이다.
-
주 프로그램(main())
-
프로시저
-
함수
-
메서드
-
객체
-
광역 변수, 지역 변수
-
스택
-
심볼 테이블, 배열
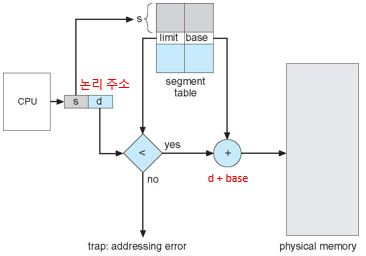
논리주소는 <segment-number, offset(상대값)> 두 부분으로 구성
사용자가 정의한 이차원 주소를 일차원의 실제 주소로 사상하는데에 세그먼트 테이블을 사용
테이블의 각 항목은
- 세그먼트의 기준(base): 세그먼트의 시작 주소를 표시
- 세그먼트의 한계(limit): 세그먼트의 길이를 명시
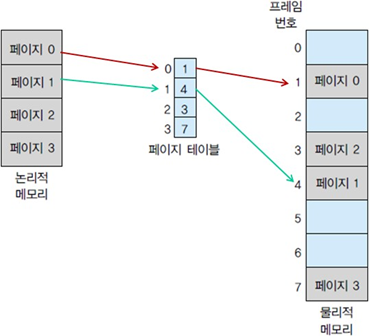
페이징
페이징은 논리 주소 공간이 연속적인 공간에 모여 있어야 한다는 제약을 제거
기본 방법
- 물리 메모리는 프레임이라 불리는 같은 크기 블록으로 분할(크기는 2의 멱승으로 512바이트~16M바이트)
- 논리 메모리는 페이지라 불리는 같은 크기 블록으로 분할
- 프로세스가 실행될 때 프로세스의 페이지는 보조 메모리로부터 메인 메모리 프레임으로 들어감
- 모든 자유 프레임 리스트들은 추적 관리
- 논리 주소에서 물리 주소로 변환하는 페이지 테이블 필요
- 내부 단편화가 발생함
주소 변환
CPU에 의해 생성된 주소는 두 부분으로 분할
- 페이지 번호(p): 페이지 테이블을 액세스할 때 사용
- 페이지 변위(d, offset): 페이지 테이블의 베이스 주소 + 페이지 변위 = 물리주소
Ex) 논리 주소 공간의 크기가 2^m이고, 페이지의 크기가 2^n이라면…
→ 논리 주소의 상위 m-n 비트는 페이지 번호를 나타내고, 하위 n 비트는 페이지 변위를 나타냄
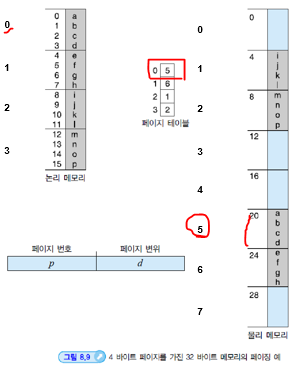
내부 단편화 계산
페이지가 2048 B이고 프로세스가 72,766 B를 요구한다면?
페이지 크기 = 2048 바이트
프로세스 크기 = 72766 바이트
= 35 페이지 + 1086 바이트36 번째로 할당되는 페이지 프레임은 2048 - 1086 =962 바이트의 내부 단편화가 발생
- 최악 = 1 페이지- 1 바이트
- 평균 = 1/2*페이지 크기
페이지 테이블 하드웨어 구현
페이지 테이블은 메인 메모리에 저장(프로세스마다 페이지 테이블을 가짐)
- 페이지 테이블 기준 레지스터(PTBR)가 페이지 테이블을 가리킴
- 페이지 테이블 길이 레지스터(PTBR)가 페이지 테이블의 크기를 표시
매 데이터/명령 접근을 위해 두 번의 메모리 액세스를 요구
물리 주소에서 페이지 테이블 참조 → 페이지 테이블에서 데이터/명령 참조
(*페이지 테이블도 메모리이다)
TLB
두 번의 메모리 접근 문제는 TLB라고 불리는 특수한 소형 하드웨어 캐시(캐시 메모리) 를 사용하여 해결
- 매우 빠른 연관 메모리로 구성(참조 시 주소 필요 없음)
- TLB 내의 각 항목은 키(페이지 번호)와 값(프레임 번호)의 두 부분으로 구성
- 페이지 테이블의 일부를 저장하고 있음
- 주소 변환
- A’가 TLB에 있으면 프레임 번호 가져옴
- 없으면 페이지 테이블에서 프레임 번호 가져옴
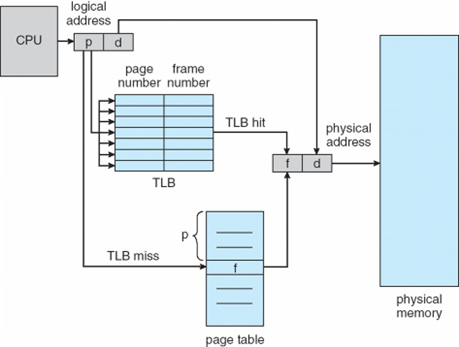
- 실제 메모리 접근 시간
페이지 번호가 TLB에서 반복되는 비율을 적중률이라 한다.
TLB 탐색 20 ns, 메모리 접근 100 ns, TLB 적중률 80%일때 실제 메모리 접근시간은?
= 적중률메모리 접근 + (1-적중률) (2*메모리접근)
= 0.8100+0.22*100
= 120ns
메모리 보호
메모리 보호는 각 페이지에 붙어 있는 보호 비트에 의해 구현
페이지 테이블의 각 항목에는 유효/무효 비트 추가
공유 페이지
페이징의 또 다른 장점은 코드를 쉽게 공유할 수 있다는 점이다.
재진입 가능 코드(reentrant code)라면 공유가 가능
- 재진입 가능 코드는 수행하는 동안 절대로 프로그램 내용이 변하지 않는 코드
- 따라서 어려 프로세스들이 동시에 같은 코드를 수행 할 수 있음
공유되는 프로그램: 문서 편집기, 컴파일러, 윈도우 시스템, 실시간 라이브러리, 데이터베이스 시스템
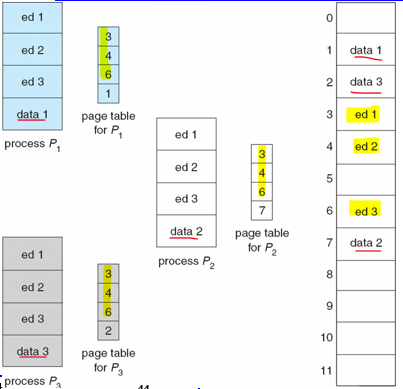
💡 페이징은 메모리를 ‘페이지’라는 고정된 크기로 분할하고, 세그먼테이션은 논리적인 의미를 가지는 단위(함수, 데이터, 메인 등)로 분할한다. 즉, 세그먼트는 크기가 다르다.
페이지 테이블 구조
현대 컴퓨터는 매우 큰 주소 공간을 가진다. 이러한 환경에서는 페이지 테이블도 상당히 커진다.
페이지 테이블을 구성하는 일반적인 방법들을 소개한다.
계층적 페이징
논리 주소 공간을 여러 단계의 페이지 테이블로 분할
두 단계 페이징 기법
: 페이지 테이블 자체가 다시 페이징
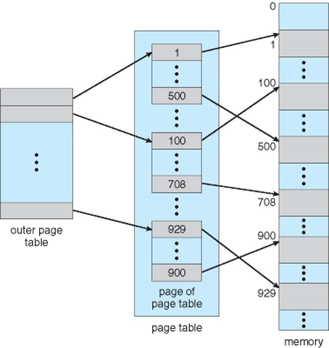
Ex) 32비트 논리주소 공간, 4KB(2^12) 크기의 페이지 일 때…
20비트 페이지 번호와 12비트 페이지 변위로 나누어짐
페이지 테이블도 페이지화되면서 페이지 번호를 10 비트씩 분할
3-단계 페이지 주소
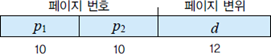
64비트 논리 주소 공간을 가진 시스템에서는 2 단계 페이징 기법이 적절하지 못함
→ 두 번째 바깥 페이지를 도입한 3 단계 페이지 테이블 구성
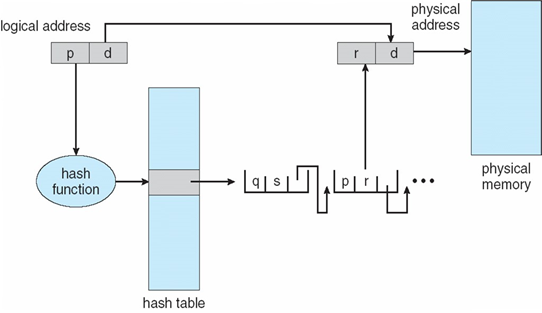
해시형 페이지 테이블
주소 공간이 32 비트보다 커지면서 해시형 페이지 테이블을 사용함
가상 페이지 번호가 해시 값이 되어 페이지 테이블을 참조
같은 위치로 해시되는 충돌인 경우를 위해 각 항목은 연결 리스트로 구성
해시형 페이지 테이블의 동작
- 가상 주소 공간으로부터 페이지 번호 해싱
- 해시형 페이지 테이블에서 연결 리스트를 따라가며 페이지 번호 비교
- 일치하면 그에 대응하는 페이지 프레임 번호를 획득
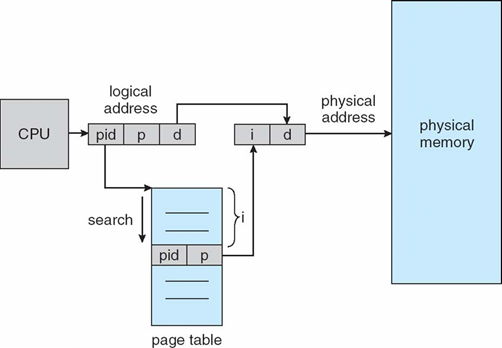
역 페이지 테이블
지금까지의 페이지 테이블은 페이지 마다 하나의 항목을 가짐
→ 페이지 테이블 크기가 커짐
역 페이지 테이블
- 메모리 프레임마다 한 항목식 할당(페이지 테이블로부터 주소를 한번에 알아낼 수 없음을 의미)
- 논리 페이지마다 항목을 가지는 대신 물리 프레임에 대응되는 항목만 테이블에 저장하기 때문애 메모리 공간 절약
- 프레임에 따라 저장되어 있어 테이블에 대한 탐색 시간이 필요
사례: Intel 32비트와 64비트 구조
현재 가장 널리 사용되는 cpu칩
IA-32 구조
세그먼테이션과 페이지화 된 세그먼테이션을 모두 지원
- 각 세그먼트는 최대 4GB
- 한 프로세스 당 16k개 세그먼트를 가질 수 있음
- 각 프로세스의 주소 공간은 두 개의 분할
- 프로세스가 독점적으로 사용하는 8 K개 세그먼트(LDT에 저장)
- 모든 프로세스 사이에서 공유가 가능한 8 K개 세그먼트(GDT에 저장)
- 논리 주소는 셀렉터와 변위의 쌍으로 구성
- 변위 32비트
- 셀렉터 16비트 → 6개의 16비트 세그먼트 레지스터에 저장
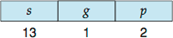
(s=세그먼트 번호, g=세그먼트가 GDT인지 LDT인지를 표시, P=보호와 관련된 정보 표시)
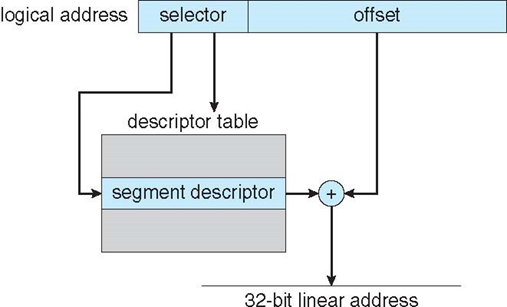
IA-32 주소 변환
CPU가 논리 주소 생성 → 세그먼트 유닛은 각 논리 주소를 32비트 선형 주소로 변환
→ 페이징 유닛이 선형 주소를 메인 메모리의 물리 주소로 변환(페이지 크기는 4KB 또는 4MB)

IA-32 페이징
2 단계 페이징 기법 사용
- 4KB 크기의 페이지를 사용할 때 적용
- p1은 페이지 디렉토리라고 부르는 최상위 페이지 테이블의 항목을 가리킴
- p2는 하위 페이지 테이블의 변위 표시
- CR3 레지스터는 현재 프로세스의 페이지 디렉토리를 가리킴
💡 페이지 크기가 작으면 테이블의 항목이 많아지므로 페이지 테이블의 크기가 커진다. 반비례 관계이다.
9장의 흐름…
주소가 런타임에 결정되면 프로그램 내 주소와 실제 주소가 다르다.
논리주소(가상 주소) → 물리주소 변환하는 하드웨어는 MMU
메모리에 적재하는 방법은 세그먼테이션(논리적 의미, 크기가 다름) 또는 페이징(동일한 크기)
TLB
