아직 학생이기도하고 영어가 미숙하다보니 본 리뷰에 오류가 있을 수도 있습니다. 이 점 감안해주시고 혹시나 찾으신다면 피드백 감사히 받겠습니다.
할 수만 있다면 나의 첫...논문...!을 위해서 Data Augmentation 관련해서 논문들 조사를 하다가 꽤 흥미로운 논문을 찾아서 리뷰해보았습니다. 기존의 Data Augmentation과는 반대 방향의 새로운 방법론 자체를 제시한 논문이라 꽤 재밌더라구요. 그래서 오랜만에 한 번 리뷰를 써보려 합니다.
Introduction
Data Augmentation의 경우 GT의 존재 여부 상관없이, 수많은 학습 방법론에서 쓰이는 기법 중 하나입니다. 대개 방법론도 간단하고 어느 학습 알고리즘에도 쓰기 쉬울만큼 범용성도 넓은데다가 성능의 향상까지 어느정도 늘 보장하고 있어 정말 많이 사용되곤 합니다. 주로 해당 기법이 사용되는 방법은 이미지가 갖고 있는 의미적인 정보는 유지하면서 회전, 노이즈, 반전 등의 기법을 사용해 동일한 라벨을 가진 데이터를 복제하는 방식인데요.
하지만 여기서 저자들은 새로운 기법을 제안합니다. 어느 특정 데이터에 대해서 추가적으로 이런 것도 positive한 데이터라는 것을 제시하기보다는, negative한 데이터를 제시하며 여기로 가서는 안된다라는 기법을 제시하고 이를 Negative Data Augmentation(NDA)이라고 칭합니다. 직관적으로 설명하면 부분적으로 의미론적인 정보는 그대로 갖고 있지만, 실제로는 데이터 분포 밖의 이미지를 임의로 생성하고 이건 정답이 아니라는 정보를 줌으로써 모델을 학습시키는 방법을 말합니다. 논문에서는 이러한 부정적인 정보가 적은 데이터셋에서 꽤나 유용한 inductive bias라는 것을 시사하기도 합니다.
연구진들은 이러한 기법을 GAN과 unsupervised representation learning에 접목시켜 이러한 방법론이 효과적임을 보여주려 합니다. 자세한 부분은 아래서 하나씩 다뤄보도록 하겠습니다.
Negative Data Augmentation
기존에 존재하는 Data Augmentation 기법의 경우에는 아래와 같이 여러 종류가 있습니다.

대부분의 Data Augmentation 전략은 세상의 data들이 형성하는 분포인 안에 존재하는 여러 prior들을 적용시킨 새로운 이미지들을 형성하는 것이 목표이지만, NDA의 경우에는 OOD(Out Of Distribution)의 prior인 의 분포를 따르는 새로운 Data를 형성하는 것이 목표입니다. 그래서 저자들은 몇 가지 가정을 부가적으로 합니다. 우선 두 distribution은 disjoint하다는 것이고요, 두번째로 의 sampling은 어렵지 않다는 것입니다.
그렇다면, 여러가지 Data Augmentation 기법 중 뭐가 Negative한 기법이라고 볼 수 있을까요? 위에 강아지 사진을 보면 Jigsaw의 경우 Negative하다고 볼 수 있지만, 만약 나뭇잎으로만 뒤덮인 숲사진이 있다면 해당 사진의 경우에는 Jigsaw를 적용해도 그닥 큰 효과는 못 볼 것입니다. 또한 CutMix같은 경우 이미지를 서로 Cut해서 넣고 그 비율에 따라 relabeling을하고 이를 학습시키는 방식으로 Classification task에는 잘 작동하는 것으로 알려져있지만, 과연 해당 이미지가 GAN에서도 좋은 input으로써 작동을 할 까요? output에 대한 정보는 당연히 전달을 못하구요. 이렇듯 해당 방법론을 구분하는 데는 domain과 task 등 고려해야 할 요소가 꽤 많다고 합니다.
그래도 하나씩 봐보면 가장 우선적으로 생각할 수 있는 방법은 많은 양의 랜덤 노이즈를 삽입하는 것입니다. 해당 prior는 일반적이나 무언가 특별한 정보를 주기는 쉽지않고 대개 학습과정에서 굉장히 비효율적이라고 합니다. 특히, 연구진은 NDA의 분포가 와 가까울 때 NDA를 이용한 학습이 의미가 있다고 시사하며 이런 방법은 좋지 않다고 말하고 있습니다. 결과적으로는 local feature는 보존하되 global feature는 깨트리는 방식으로 NDA에 접근했고 이러한 실험결과는 뒤에서 추가적으로 설명해드리려고 합니다.
NDA For GAN
이제는 이러한 NDA 기법을 GAN에 어떻게 적용했는지 설명해보려 합니다. 우선 그에 앞서 신기한 현상 하나를 제시하고 있는데요. 주로 VQA task에 쓰이긴 하지만 가상으로 물체들을 생성하고 렌더링해서 학습하는 CLEVR라고 불리는 데이터셋이 존재합니다.

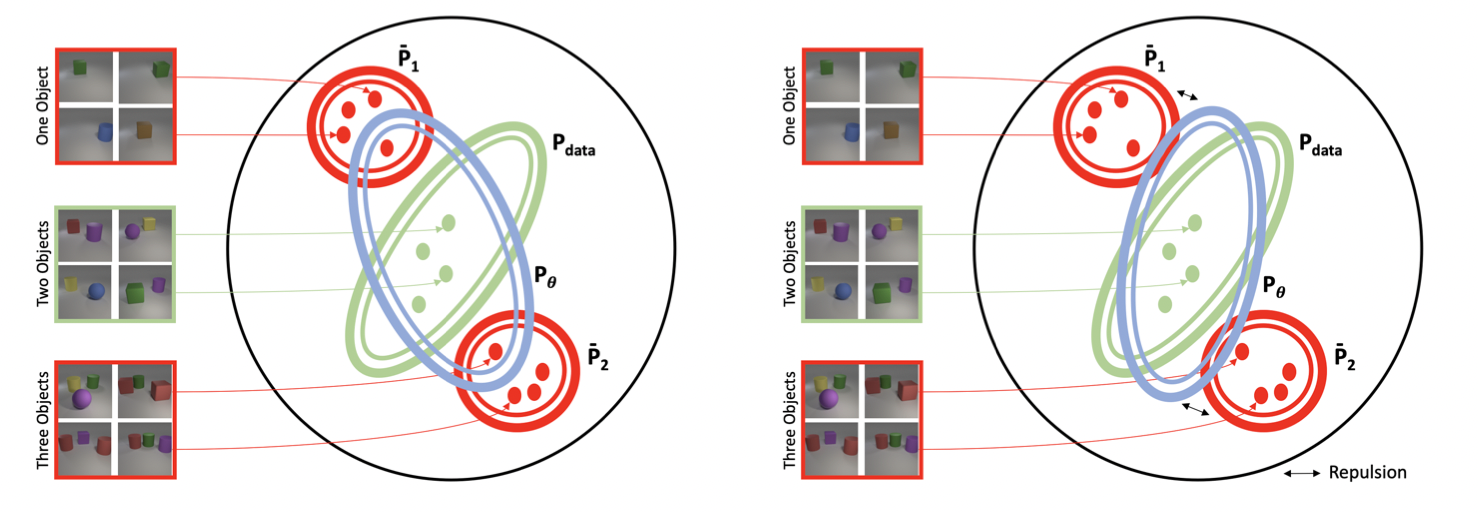
연구진은 해당 Dataset에서 물체가 2개만 존재하는 이미지들만 뽑아 GAN을 학습시켰다고 하는데요. 놀랍게도 GAN의 결과물 중 낮은 확률로 물체가 1개 혹은 3개가 존재하는 이미지가 생성됐다고 합니다. GAN이 자기가 평생 못 본 이미지를 만들어낸 것이죠. 이러한 결과에 대해서 연구진은 아래 그림과 같은 이유를 제시합니다.
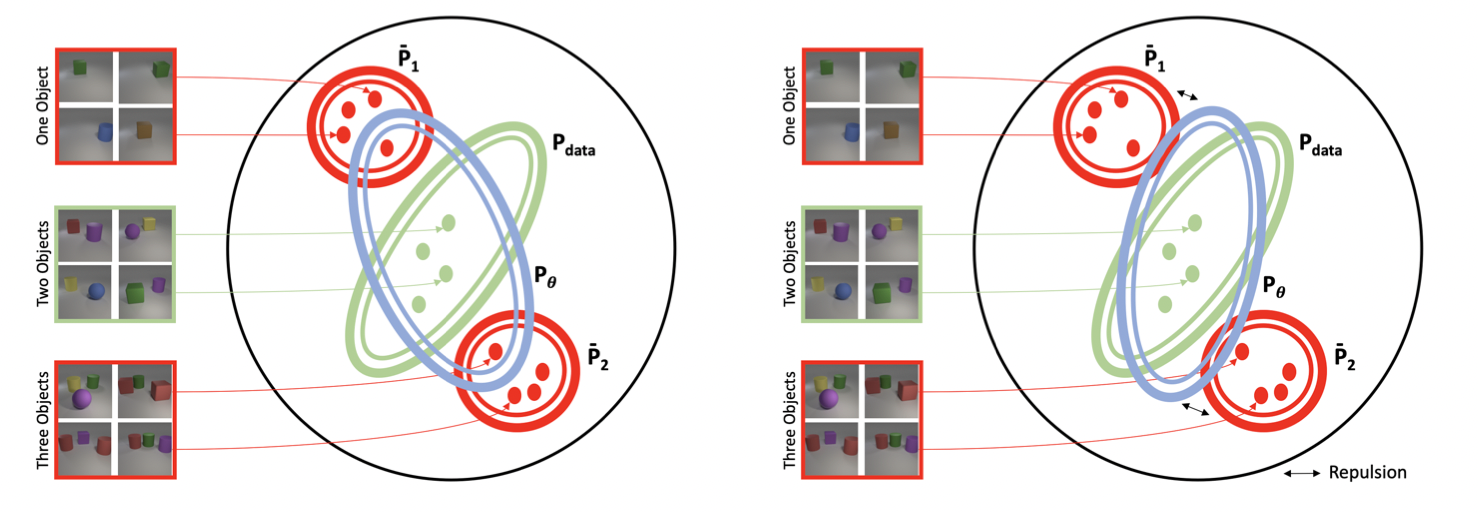
좌측그림이 연구진이 설명한 예시인데요. 모델에게는 한정된 데이터셋이 주어지고 모델이 하는 일은 이걸 기반으로 데이터셋의 분포 를 추정하는 것입니다. 하지만 데이터셋이 부족하다는 한계로 인해 모델이 바라본 데이터셋으로 만든 분포는 OOD인 과 같은 분포에 접근을 하게 되는 것이죠.
그래서 연구진은 기존의 GAN에서 사용하는 minmax Game에서 Generator의 분포 부분을 아래와 같이 변화시키면서 NDA 학습법을 제안합니다.
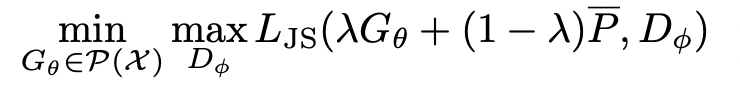
여기서부터는 살짝 제 뇌피셜 이해가 들어가는데, 우선 는 를 따라 real/fake를 판단할 것이고, 는 를 최대한 모방해야 합니다. 하지만 이 과정에서 OOD인 를 추가 parameter로 던져주어 결국은 가 를 모방하게 되는 것이죠. 이런식으로 Model이 학습해야 할 방향에 대해서 어디로 가야할지와 동시에 어디로 가지 말아야 할지에 대한 정보도 던져주는 것입니다. 위 그림에서 보시면 오른쪽 부분과 같이 각 에 대해서 여기로 오지마! 라는 Negative한 정보를 던져주면서 가 추정하는 분포가 점차 에 가까워지는 것을 확인할 수 있습니다.(물론 가상의 Figure지만요)
NDA For Contrastive Representation Learning
여기까지 잘 따라오셨으면 별 무리 없이 NDA가 뭐고 연구진들이 얘를 어떻게 써먹었구나에 대한 감은 찾으셨을 겁니다. Contrastive Learning은 GAN보다 NDA를 더 쉽게 사용했는데요. Contrastive Learning에서는 말 그대로 Positive Augmentation을 기반으로 Positive pair를 형성하고 그 외에 image들에 대해서는 Negative Pair로 여겨져 loss를 최소화하는 방법으로 알려져있는데 말 그대로 여기 Negative pair에다가 Negative Augmentation을 거친 image들을 넣는 것으로 잘 해결됩니다. 식으로 보면 아래와 같습니다.
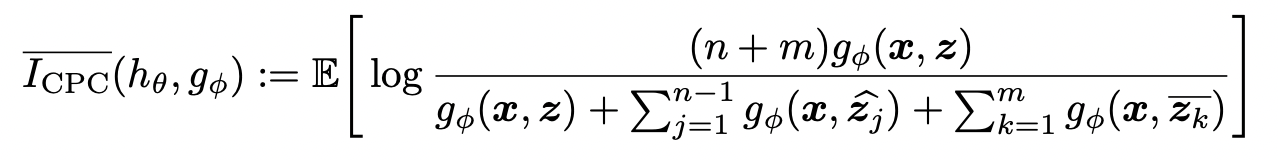
부분이 이제 기존의 negative pair들에 대한 부분이고, 부분이 negative augmentation으로 생성한 negative pair에 대한 부분입니다.
Experiments
GAN
우선 위에서 제시했던 각 Augmentation이 과연 PDA에 적합할까 NDA에 적합할까에 대한 실험 지표입니다. (CIFAR-10에 적용시켰구요, FID는 낮은 게 좋습니다.)

생각했던 대로 분포를 학습하는 입장인 GAN은 대부분의 Cut을 기반으로 하는 Augmentation은 대체적으로 Negative하다는 것을 확인할 수 있었습니다.

성능 역시도 NDA를 적용시킨 모델들이 더 좋은 성능을 보여줌을 확인할 수 있었습니다.
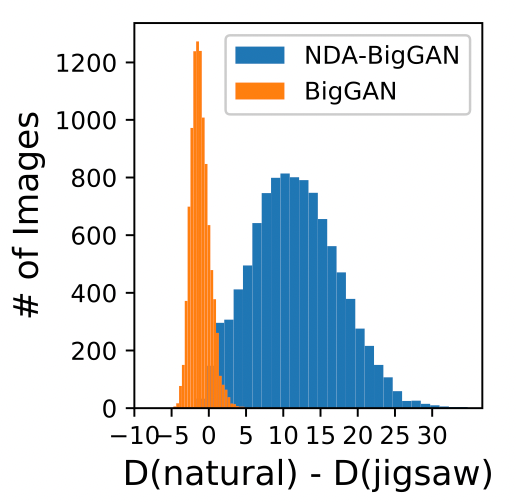
추가로 주목할만한 것은 아래 히스토그램인데요, 아래 히스토그램은 Discriminator가 실제 이미지와 jigsaw augmentation을 거친 이미지에 대해서 뱉은 결과값의 차를 도식화한 자료입니다. NDA-BigGAN 같은 경우에는 차이를 어느정도 잘 인지하지만 BigGAN의 경우에는 거의 유사하게 판단하는 것을 확인할 수 있었습니다. 어떻게 보면 기본적인 학습의 방향성으로도 볼 수 있을 것 같습니다.
Contrastive Learning
아래 표와 같이 NDA를 적용시킨 기법들이 더 좋은 성능을 보여줌을 확인할 수 있습니다.(모델은 MoCo-V2를 사용했다고 합니다. 이건 Accuracy니까 높은 게 좋아요!)

Conclusion
결론은 Negative Data Augmentation으로 OOD의 prior를 적용한 이미지를 생성해서 이를 기반으로 모델에게 가지말아야할 곳에 대한 방향성을 제시했다고 합니다.
Comment
제가 여기서 좀 발전시키고자 하는 방향성은 두 가지인데요. 우선 첫번 째는 과연 Negative한 prior가 저것뿐일까? 좀 더 좋은 성능을 가진 negative prior가 존재하지 않을까 라는 방향성입니다.
두번째는 오늘 소종 교수님과 미팅을 진행했을 때 Adversarial attack에 대해서 좀 들었는데 결국 해당 문제도 boundary에 대한 취약점에 대해 image를 classification boundary 밖으로 이동시켜 모델을 결국 OOD로 보낸다는 것 같은데, 여기서 좀 비슷한 실마리를 찾을 수 있지 않을까...
아무튼 뭔가 발전시킨다는 논문보다는 새로운 방향성을 제시하는 논문이 재밌는 것 같습니다.
Reference
Abhishek Sinha, Kumar Auysh, Jiaming Song et al. Negative Data Augmentation(ICLR 2021)
https://arxiv.org/pdf/2102.05113.pdf
