Scene Representation Networks: Continuous 3D-Structure-Aware Neural Scene Representations Review
paper-review
아직 학생이기도하고 영어가 미숙하다보니 본 리뷰에 오류가 있을 수도 있습니다. 이 점 감안해주시고 혹시나 찾으신다면 피드백 감사히 받겠습니다.
아직 많은 논문을 읽어보지는 않았지만, 3D와 관련된 Implicit neural representation 논문에는 NeRF와 이 논문이 되게 자주 등장해서 읽어보게 되었습니다.
Introduction
해당 논문도 지금까지 봐왔던 논문들과 유사하게 few-shot 3D reconstruction 관련된 어려움과 도전과제에 대해 시사하며 시작합니다. 또한 지금까지의 classic 3D scene representation 기법인 voxel grid, point cloud, mesh들과 같은 end-to-end deep learning model들에 대해서 discrete한 representation이기에 가질 수 밖에 없는 단점에 대해서도 이야기합니다. resolution limit과 computation의 trade-off와 같은 문제말이죠.
그래서 연구진은 Scene Representation Network라는 방식을 소개합니다. 해당 방법에 대해서 간단하게 요약하자면 3D좌표를 input으로 받고 해당 좌표에 대한 정보를 output으로 도출하는 모델을 설계하는 것입니다. SRN은 diffrentiable rendering algorithm을 기반으로 3D shape를 continuous하고 differentiable하게 표현하는 implicit 모델링 방식을 제안합니다. 이러한 모델링은 end-to-end로 train이 가능하며, Novel view synthesis와 interpolation 등의 추가적인 처리를 통해 pose가 고정되어있는 2D image로부터의 supervision을 가능하게 합니다.
Formulation
우선, 가장 큰 목표는 주어진 dataset을 기반으로 3D shape과 appearance를 generalize할 수 있는 neural scene representation 를 형성하는 것입니다. 이때 주어진 Dataset은 단순 Image가 아닌 로 N개 쌍의 Image 와 = 의 extrinsic matrix와 의 intrinsic matrix로 구성되어 있습니다. 그러고 나면 특정 view point에서 scene을 rendering할 수 있는 rendering function 역시도 생성해야 합니다. 즉 와 를 먼저 생성한 후 이를 posed 2D Image에 대해서 optimizing하면서 framework를 학습시키는 구조입니다. 자세한 학습 과정은 아래서 더 서술하겠습니다/
Representing Scenes as Functions
연구진에서 1차적으로 formulate한 함수인 는 한 spatial location 를 feature representation 로 매핑시키는 것입니다.
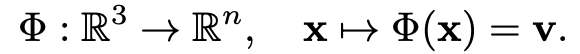
feature vector 는 표면의 색상이나 reflectance등의 정보를 enccoding해서 저장할 것입니다. 이러한 방식의 표현은 기존에 이산형으로 3D data를 표현한 방식처럼 해석될 수 있지만, 해당 모델에 input으로 넣는 좌표 data를 얼마만큼 sampling하는지 정도에 따라 달라집니다. 그렇기에 해석 방식에 따라 이산형으로 해석될 수도 있지만, 모델자체는 continuous하게 여겨집니다.
그리고 는 world coordinate를 input으로 사용하는 3D 구조에 대한 정보를 갖고 있습니다. 그렇기 때문에 우리는 multi-view와 perspective geometry에 관한 정보들을 통해 상호작용 하는 것을 각 장면들의 unknown property를 학습하는 과정을 통해 얻을 수 있습니다. 해석이 좀 난해하긴 하지만, 결론적으로는 multi-view consistent한 view 합성을 가능하게 해준다고 합니다.
Neural Rendering
주어진 Scene Representation 에 대해서 연구진은 neural rendering algorithm 도 소개하려 합니다. 식은 아래와 같이 이루어집니다.
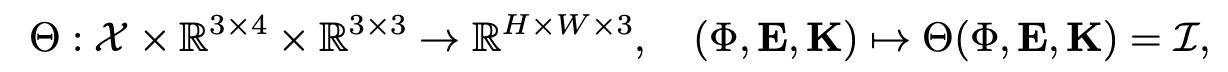
해당 Rendering에 key idea는 geometry 정보 역시도 implicit하게 내부에 표현되어 있고, 이를 기반으로 scene을 형성한다는 것입니다. 각 하나하나의 pixel에 대해서 rendering하기 위해서는 다음과 같은 두 가지의 세부 문제를 해결해야 합니다.
- world 좌표계에서 camera ray와 scene geometry의 교집합을 찾는 것
- feature vector 를 color로 매핑하는 것
우선 연구진은 1을 neural ray marching algorithm으로 해결하였다고 합니다.
Differentiable Ray Marching Algorithm
연구진은 ray와 scene geometry의 교점을 구하는데 있어 먼저 각 ray에서 한 point를 sampling하는 방법을 제시했습니다. 해당 식은 다음과 같이 계산이 됩니다.
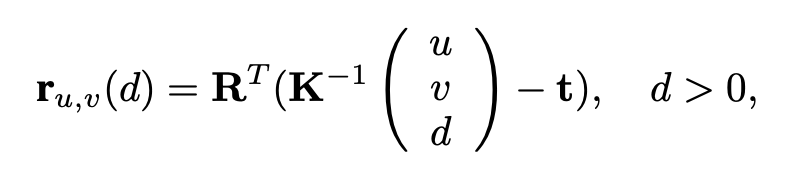
여기서 는 카메라 픽셀 좌표이고, d는 카메라로부터 point까지의 거리로 생각하면 될 것 같습니다. 즉 초점으로부터 u,v pixel을 통과하는 ray에 대해서 d까지만큼 거리의 해당하는 점을 의미하고, 이를 camera matrix를 활용해서 변환을 시켜줍니다. 이렇게 world coordinate에서의 point들을 정의한 후에는 다음과 같은 최적화 문제를 푸는 형식으로 식을 세웠습니다.
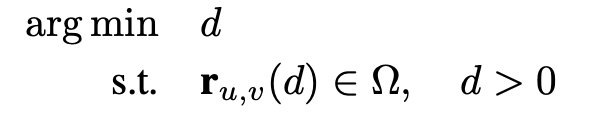
이 식에서 는 Scene geometry surface에 해당하는 point들의 집합으로 위 식을 풀어쓰자면 Scene Geometry surface와 접하는 가장 가까운 d를 찾자는 식입니다. rendering하는 입장에서는 카메라와 가장 가까운 surface의 색상값만 sampling하면 되기에 위와 같은 식을 설립하는 것으로 생각하였습니다.
여기서 이제 중요한 것은 최적의 d값을 어떻게 찾느냐인데 연구진은 d를 작게 설정하고 적절한 step씩 증가시키면서 이를 실험했습니다. 그리고 이 적절한 step의 값은 다음과 같은 알고리즘을 통해 찾습니다.
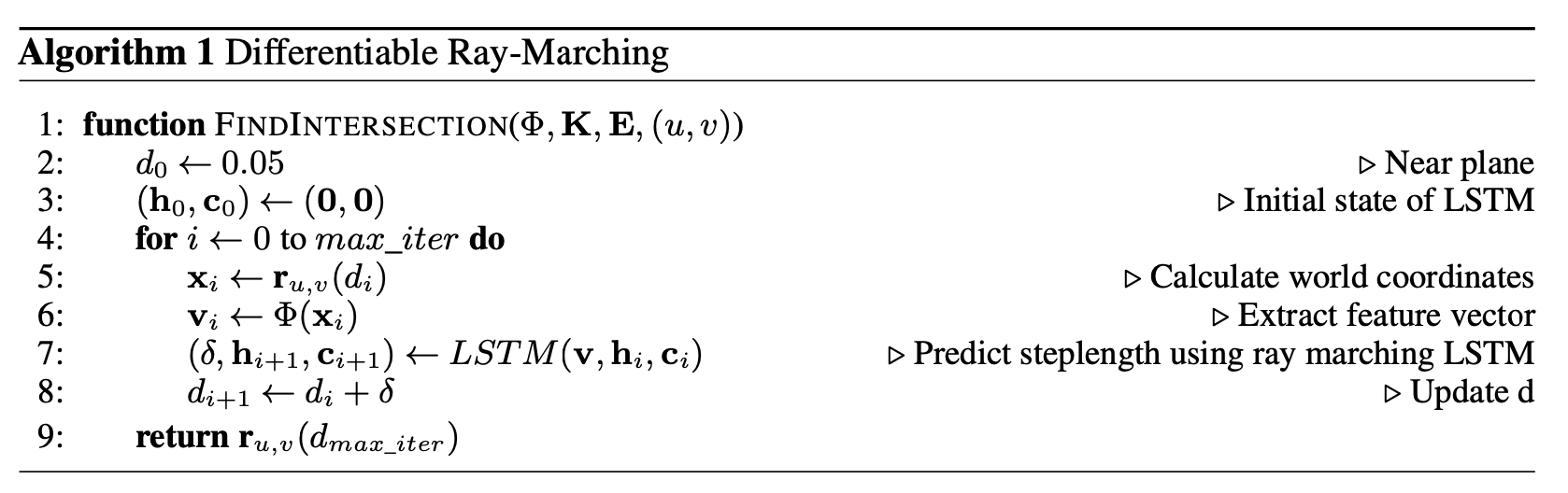
LSTM이라는 형식의 모델을 활용해 기존의 h라는 c라는 cell state를 계속 갱신하면서 각 time step에서의 world coordinate을 에 대입한 결과인 feature vector 를 input으로 삼아 새로운 d값 즉, 값을 찾는 형식입니다. 해당 방식은 Ray Marching 기법에 LSTM을 적용해 RM-LSTM이라고 불리운다고 합니다.
위 알고리즘에서 주의해야할 점은 d값이 를 어떻게 설정하느냐에 따라 꽤 달라지는데, 학습 초기의 경우에서는 모든 값들이 random하게 intialize되기 때문에 이 값을 꽤 크게 잡아야 한다고 합니다. 그리고 이러한 d값에 대한 정보는 world coordinate에 있어서 z좌표, 곧 depth map으로도 계산이 될 수 있다고 합니다.
Pixel Generator Architecture
Pixel generator는 로부터 feature vector 를 기반으로 RGB 값을 형성합니다. 해당 과정은 1X1 convolution만으로 진행이 된다고 합니다. 해당 방식은 2D convolution을 거치지 않기 때문에 다음과 같은 이점을 가진다고 합니다. 우선, 해당 방식은 어떠한 (x,y,z) coordinate에 대해서 항상 동일한 결과값을 내기때문에 multi-view consistent한 결과를 낼 수 있다고 합니다. 만약 2D convolution을 사용한다면 해당 과정에서 view에 따라 주변 pixel의 영향을 받을 것이기에 1x1 convolution만 사용했다고 합니다.
하지만 이런 per pixel formulation의 경우에는 동일한 해상도에서 ray marching, SRN, Pixel Generator를 진행하는 것은 상당한 memory를 요구하기에 최신 CNN architecture를 사용하지 못했다고 합니다.
Generalizing Across Scenes
연구진은 동일한 class에 속하는 object들에 대해 SRN을 일반화하는 것을 시도했습니다. 그렇기에 연구진은 우선 동일 class에 대해 유사한 shape이나 appearance를 포함할 것이므로 각 object에 대해 이를 표현한 latent vector를 생성해줍니다. 그 후 latent vector 를 기반으로 의 parameter들을 생성하는 라는 네트워크를 학습시킵니다. 즉, object를 표현한 latent vector인 를 로 mapping해주는 새로운 network 를 학습시킨다는 것입니다. 식은 다음과 같습니다.
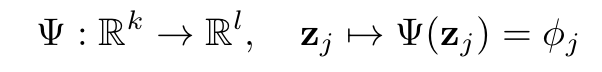
추가로, latent vector 를 구하는 것은 auto-decoder framework를 따랐다고 합니다.
Joint Optimization
위를 종합해서 만든 최종 목적함수는 다음과 같습니다.
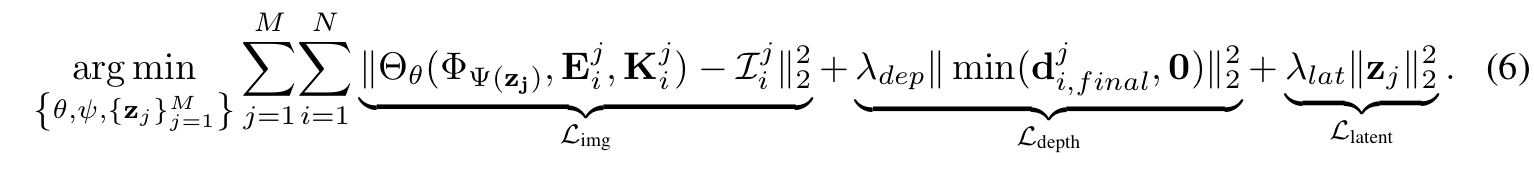
하나씩 차근차근 설명해보자면 는 SRN이 생성해 낸 이미지와 GT에 대해서 L2 Loss를 구하는 방식이고 그 과정에서 Camera Parameter들과 object별 모델을 생성하는 network 와 representation 생성 Network 와 이를 렌더링하는 가 사용됨을 알 수 있습니다. 그리고 두 번째 로스인 의 경우에는 실제로 Ray marching에서 수렴시킨 depth의 값과 실제 depth의 값이 얼마나 차이가 있는지에 대해서 평가하는 loss입니다. 마지막 loss인 의 경우에는 latent vector 를 생성하는데 있어 Gaussian prior를 가요하는 regularization이라고 합니다.
Reference
Scene Representation Networks: Continuous 3D-Structure-Aware Neural Scene Representations - V.Sitzmann
