아직 학생이기도하고 영어가 미숙하다보니 본 리뷰에 오류가 있을 수도 있습니다. 이 점 감안해주시고 혹시나 찾으신다면 피드백 감사히 받겠습니다.
오늘 리뷰해 볼 논문은 MLP-Mixer입니다. 사실 ViT를 먼저 리뷰해보고 싶었지만, Transformer 자체도 아직 이해가 좀 부족한 것 같아서 글을 쓸 정도로 읽히지는 않더라구요... 그래도 꾸준한 블로그 습관을 위해 MLP-Mixer로 글을 써보려 합니다. MLP-Mixer의 경우에는 새로운 Architecture를 제안하는 논문이기도 하고, 그 Architecture가 간단한 구조라서 되게 잘 읽히기도 했고 꽤 성능이 좋아서 흥미롭게 읽을 수 있었습니다. 다만 이게 진짜 새로운 Architecture인가 아니면 CNN의 파생인가 여부에 대한 논쟁이 좀 있습니다.
Introduction
Computer Vision 관련 딥러닝에 대해서는 2014년 AlexNet의 등장을 기점으로 CNN이라는 기술이 등장하면서 급속도로 발전해왔습니다. 하지만 최근 self-attention을 기반의 ViT가 등장해 SoTA를 휩쓸면서 CNN이 갖고 있던 왕좌를 점점 Transformer가 물려받는 분위기가 Vision 분야에서는 나타나고 있습니다.
연구진은 ViT에서 사용한 Patch단위의 연산에 대한 idea에 CNN과 self-attention이 아닌 MLP만으로 MLP-Mixer라는 구조를 제안하였고, 해당 Model로 SoTA에 가까운 성능을 얻을 수 있었습니다. 다만 MLP-Mixer에 주요 layer들이 어떻게 보면 특별한 case의 CNN으로 해석이 될 수가 있고, 다만 이를 Patch 단위의 MLP로 구현을 한 방법의 차이일 수도 있겠다라는 의견도 있습니다.
Mixer Architecture
우선 전반적인 MLP-Mixer의 구조와 후에 설명드릴 MLP 구조에 대한 이미지는 다음과 같습니다.
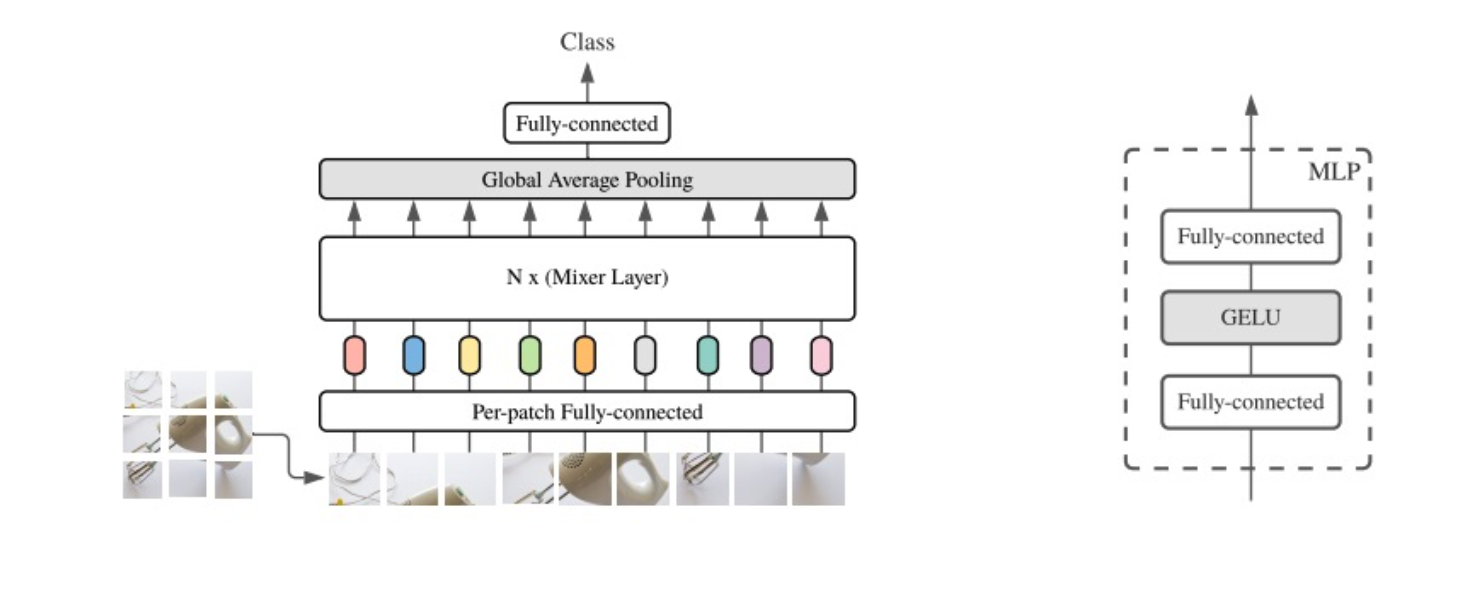
MLP-Mixer의 구조는 Mixer Layer에 들어가기 앞서, Patch 단위의 Embedding부터 진행이 됩니다. (H,W) size의 image에 대해서 Patch Size인 (P,P)만큼 Patch를 생성해줍니다. 그럴 경우 개의 Patch가 생성이 되게 됩니다. 그리고 각 Patch들을 1차원 vector로 embedding을 진행해줍니다. 해당 Embedding 과정은 FC Layer로 이루어져있습니다. 이때 ViT와는 다르게 따로 Positional Encoding을 해주지 않고, Patch의 순서를 그대로 살려서 Layer에 넣어줍니다.
그 후, 각 Patch Vector에 대해서 N개의 Mixer Layer를 통과시켜줍니다. Mixer Layer의 구조는 다음과 같습니다.
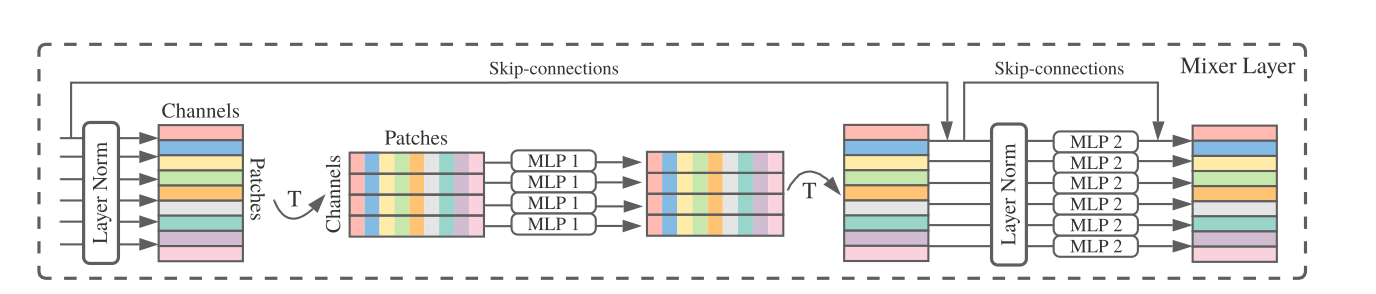
우선 들어오는 Patch Vector에 대해서 Layer normalization을 진행해줍니다. 이때 Patch Vector는 총 S개가 존재하고 , 각 Patch Vector의 size는 parameter로 인해 정해지는데요 이 개념을 Channels(C)라고 부르겠습니다. 그렇다면 Data는 S X C 형태의 행렬 형식을 띄게 됩니다. 이 data는 위에서 언급한 normalization을 거친 후, 크게 보면 2개의 MLP를 지나게 됩니다. 이때 첫번째 MLP에 대해서는 Patch들 간의 연산이 진행되기 때문에 token-mixing MLP라고 불리고, 두번째 MLP에 대해서는 Channel간의 연산이 진행되기 때문에 channel-mixing MLP라고 불립니다.
token-mixing MLP에 대해서는, patch별로 연산이 진행되어야 하기 때문에 기존의 data를 transpose 해준 후, MLP Layer를 통과하게 됩니다. 그 후 channel-mixing mlp 연산을 위해서 다시 Transpose를 해준 후, Layer Normalization을 거친 후, MLP Layer를 거치게 됩니다. 이 때, 각 MLP Layer는 하나의 FC Layer를 거치는 것이 아니라 위 첫번째 이미지의 우측 모델 같은 FC Layer - GELU - FC Layer 형태로 연산이 이루어집니다. 식으로 표현하면 아래와 같습니다.

또한 skip connection이 이루어져 처음 input을 각 MLP의 output에 더해지는 형태를 취하고 있습니다. 그리고 동일한 시점에서 계산되는 MLP들은 같은 가중치를 사용한다고 합니다. Backpropagation의 관점에서 가중치를 update할 모델은 Mixer Layer 1개당, token-mixing MLP 1개 channel-mixing MLP 1개. 총 2개인 것입니다. CNN의 weight sharing과 비슷한 개념으로 볼 수 있을 것 같습니다.
MLP Mixer는 이렇게 Patch Embedding Layer 1개와 다수의 Mixer Layer와 Global average pooling Layer 라는 간단한 구조로 이루어져 있습니다. 하지만 이 모델은 이러한 간단한 구조에도 불구하고 좋은 성능을 내었는데요. 그 내용은 Experiment에서 확인하겠습니다.
Experiment
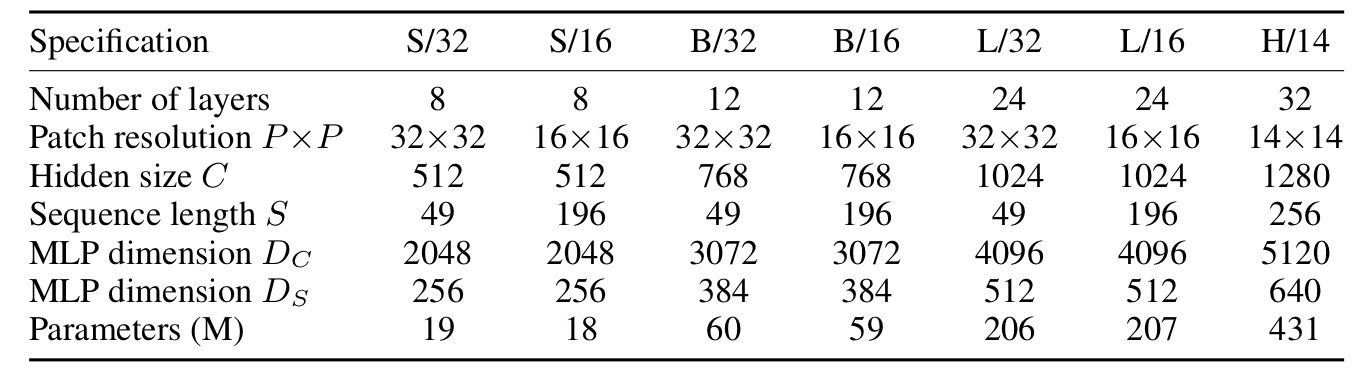
우선 MLP-Mixer의 경우에는 Patch Size에 따라서, Model의 성능이 크게 차이가 나기 때문에 아래와 같이 다양한 모델로 실험을 하였습니다. 이때 앞의 알파벳은 Model Scale(Base, Large, Huge)를 의미하고, 뒤의 숫자는 Patch Size를 의미합니다. 예를 들어 'B/16'은 patch size가 16X16인 Base Model을 의미합니다.
다음은 실험 결과들입니다.
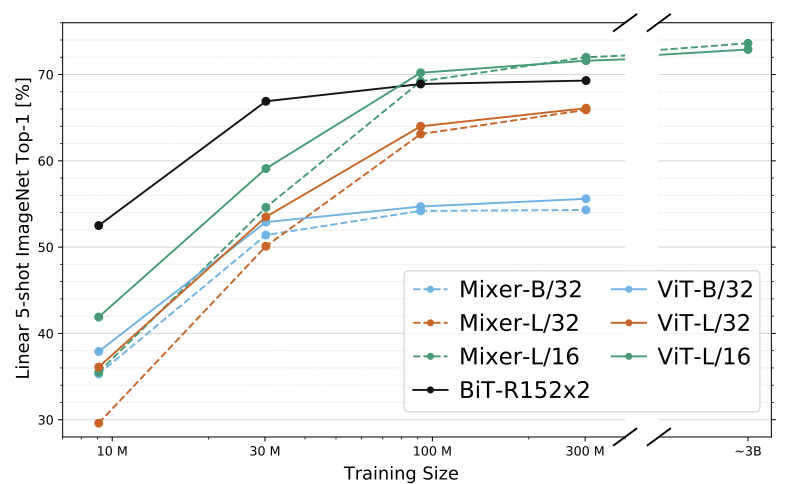
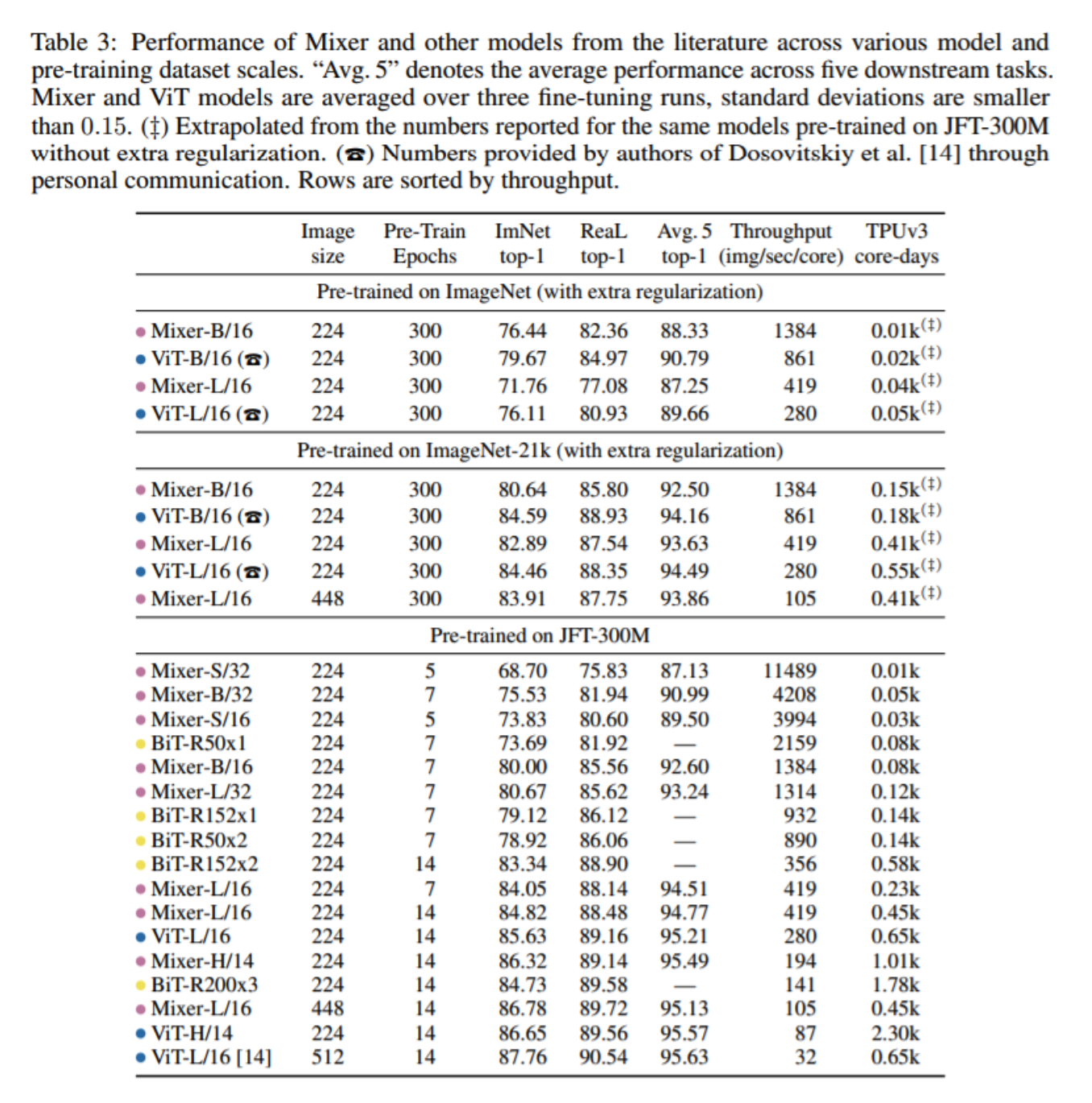
결과에 대해서는 다음과 같이 해석할 수 있습니다. 우선 dataset size가 적을 때는, ViT보다 조금 떨어지는 성능을 보여주지만 큰 dataset에 대해서는 거의 동일한 성능을 보여줌을 확인할 수 있습니다. 또한 TPUv3 core-days를 보시면, 연산량 측면에서 MLP Mixer가 ViT 대비 좀 더 좋은 성능을 보임을 확인할 수 있습니다. 이에 대해서 연구진은 ViT모델은 계산복잡도가 quadratic한 반면, MLP-Mixer의 경우에는 input patch 수와 vector size가 무관하기에 Linear한 complexity를 갖는다는 해석을 하고 있습니다.
Reference
MLP-Mixer: An all-MLP Architecture for Vision - Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer
