INDEX
주소 검색 쿼리를 만들때 와일드카드를 이용했었습니다.
SELECT *
FROM 테이블
WHERE 칼럼 LIKE '%' || '검색어' || '%'FULL 스캔을 하므로 테이블의 데이터가 늘어날수록 검색속도가 느려집니다.
그래서 검색조건을 바꾸기로 했습니다.
먼저 지역을 선택하고하고 (서울특별시)
해당하는 시군구를 선택시킵니다 (강남구)
여기에서 시군구에 해당하는 행정코드가 있는데(11680660)
이 행정코드로 시작하는 PK 칼럼의 데이터를 검색해보았습니다.
SELECT *
FROM 테이블
WHERE PK칼럼 LIKE '검색어' || '%'PK로 설정된 칼럼은 자동으로 인덱스가 생성되기 때문에
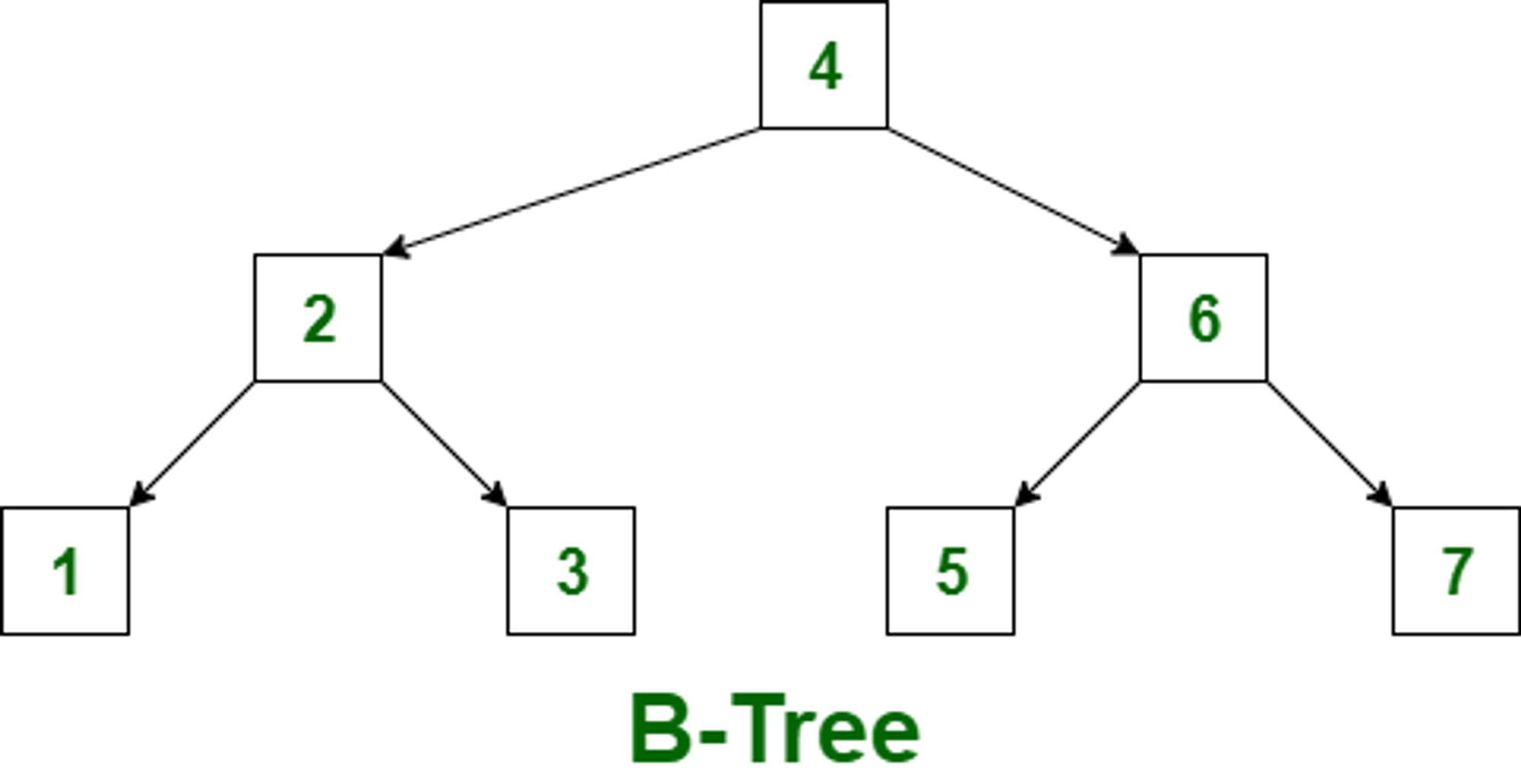
%를 끝에만 붙이게 된다면 해당 쿼리는 B-Tree 인덱싱을 사용해 빠르게 검색이 됩니다.
PK가 아닌 칼럼을 검색할때는 해당 칼럼에 인덱스를 추가합니다.
CREATE INDEX "스키마명"."생성할 인덱스명" ON "스키마명"."테이블명" ("칼럼명") 더불어 추가설정들이 있지만(PCTFREE, INITRANS, MAXTRANS, STORAGE 등)
디폴트값을 사용하더라도 충분히 좋은 성능이 나옵니다.
페이징
화면에 보여줄수 있는 데이터의 수는 제한되어 있습니다.
이때 페이징을 통해서 보여줄 데이터를 분할하여 가져오게 됩니다.
페이징에도 여러가지 방법이 있고 이러한 페이징의 속도차리를 비교해보았습니다.
모두다 5만건의 데이터를 가져오는 쿼리입니다.
- 첫번째 방법
SELECT *
FROM (
SELECT ROWNUM AS RN
, AA.*
FROM (
SELECT ID
FROM 테이블
WHERE 조건
) AA
)
WHERE RN BETWEEN 20001 AND 70000;첫번째 방법은 조건에 맞는 모든 쿼리를 가져온 뒤에 모든 로우에 순서를 붙이고 순서에 해당하는 5만개의 로우를 반환합니다.
인덱스를 사용하지 않았을 경우 평균적으로 4.2초가 걸렸습니다.
- 두번째 방법
SELECT *
FROM (
SELECT ROWNUM AS RN
, AA.*
FROM (
SELECT ID
FROM 테이블
WHERE 조건
) AA
WHERE ROWNUM <= 70000
)
WHERE RN >= 20000;두번째 방법은 조건에 맞는 쿼리를 가져온 뒤에 조건 이하의 순서까지만 ROWNUM을 붙이게됩니다.
이후 최종적으로 5만개의 로우를 위해서 다시 조건으로 자르게 됩니다.
이렇게 뒷부분부터 자르는 이유는 순서를 부여하는 ROWNUM이 1부터 생성되기 때문에 앞부분부터 자를수가 없습니다.
이번에는 인덱스를 사용하지 않았을 경우 평균적으로 3.5초가 걸렸습니다.
- 세번째 방법
SELECT *
FROM (
SELECT ROWNUM AS RN
, AA.*
FROM (
SELECT ID
FROM 테이블
WHERE 조건
ORDER BY ID
) AA
OFFSET 20000 ROWS
FETCH NEXT 50000 ROWS ONLY
) -- 평균적으로 3.8초세번째 방법은 Oracle 12c 이후 버전부터 사용할 수 있는 방법입니다.
처음 20000개의 로우를 건너뛰고 다음 5만개의 로우를 반환하게됩니다.
인덱스를 사용하지 않았을 경우 평균적으로 3.8초가 걸렸습니다.
OFFSET이 최적화가 아직 덜 된건지 제 경우만 가장 빠르지 않은건지는 몰라도 여전히 고전적인 두번째 방법이 가장 빠르긴하네요
