정규식 함수 (Regular Expression)
정규식 함수는 문자열 데이터의 다양한 패턴을 검색 조작할 수 있다.
정규식 함수에는 다음과 같은 함수가 있다.
- REGEXP_LIKE
- REGEXP_REPLACE
- REGEXP_INSTR
- REGEXP_SUBSTR
- REGEXP_COUNT
우선적으로 REGEXP_LIKE 와 REGEXP_REPLACE 에 대해서 알아보자
정규식 함수는 WHERE <조건>에 입력이 되는데 아래 처럼 사용할 수 있다.
REGEXP_LIKE
| 함수 | 출력 내용(쿼리) | 부연설명 |
|---|---|---|
REGEXP_LIKE(TEXT,'[a-z]') | TEXT 컬럼이 알파벳을 포함 | |
REGEXP_LIKE(TEXT,'[a-z]{6}') | 알파벳이 6번 연속 | 중괄호는 반복을 뜻함 |
REGEXP_LIKE(TEXT,'[a-z][0-9]') | 알파벳과 숫자가 이어진 | |
REGEXP_LIKE(TEXT,'[a-z] [0-9]') | 알파벳+공백+숫자가 이어진 | 공백이 1칸이면 1칸 이상 2칸이면 2칸 이상 |
TEXT REGEXP '[a-z][0-9]{3}' | 알파벳 3회 반복+숫자 3회 반복 | |
REGEXP_LIKE(TEXT,'[[:SPACE:]]') | 공백을 포함 | 공백의 수는 상관없다 |
TEXT REGEXP '^[a-z]' | 알파벳으로 시작 | |
TEXT REGEXP '[0-9]$' | 숫자로 끝나는 | |
TEXT REGEXP '^[^a-z]' | 알파벳으로 시작하지 않는 | |
TEXT REGEXP '[^a-z]' | 알파벳으로만 구성된 경우 제외 | ( 헷갈리기 쉽다 ) |
TEXT REGEXP '^[a-z0-9]' | 알파벳 OR 숫자로 시작 | Z와 0사이에 ' | ' 이 생략되어 있다 |
TEXT RLIKE '^[^a-z0-9]' | 숫자 OR 알파벳으로 시작하지 않는 | |
ID RLIKE '^m' | ID 컬럼에서 M으로 시작하는 | 정규식 함수 조건에 대소문자 구분 없음 |
| ID REGEXP '^m(a|o)' | 첫번째 문자 M, 두번째 문자 A OR O 로 시작 | |
| TEXT REGEXP 'a|D|c' | a or d or c포함 | 정규식 함수 조건에 대소문자 구분 없음 |
세가지 모두 같은 출력
WHERE REGEXP_LIKE(TEXT,'[a-z]'WHERE TEXT REGEXP '[a-z]'WHERE TEXT RLIKE '[a-z]'
정규식 함수를 이용하면 WHERE ~ LIKE 대신 사용할 수 있다.
4개의 코드 모두 같은 결과를 출력한다.
SELECT NAME, ID, position FROM PROFESSOR where ID LIKE '%er';
SELECT NAME, ID, position FROM PROFESSOR where ID RLIKE 'er$';
SELECT NAME, ID, position FROM PROFESSOR where ID RLIKE 'e(r)$';
SELECT NAME, ID, position FROM PROFESSOR where ID RLIKE '[e][r]$';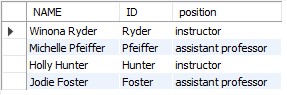
REGEXP_REPLACE
REPLACE 함수를 정규식으로 이용할 수 있다.
간단히 표를 보자
| 함수 | 출력내용 | |
|---|---|---|
| 보기엔 이상하지만 오른쪽 처럼 입력 되어 있음 ! >> | A B C D E | |
REGEXP_REPLACE('A B C D E','( ){1}','') | ABCDE | 공백을 없애라 |
REGEXP_REPLACE('A B C D E','( ){3}',' ') | A B C D E | 3칸 짜리 공백을 한칸으로 |
REGEXP_REPLACE('A B C D E','( ){2,}','') | A BCDE | 2칸 이상의 공백을 없애라 |
REGEXP_REPLACE('A B C D E','( ){2,}','*') | A B*C*D*E | 2칸 이상의 공백을 *로 |
REGEXP_REPLACE('A B C D E','( ){2}','*') | A B*C* D**E | 2칸 짜리 공백을 *로 |
REGEXP_REPLACE(TEXT, '[[:DIGIT:]]', '*') | TEXT 컬럼의 숫자를 *로 바꿔라 |
REGEXP_REPLACE(phone, '(\d{3})(\d{4})(\d{4})', '\1-\2-\3')
-- 01023456789 >> 010-2345-6789
REGEXP_REPLACE(name, '(.)(.+)(.)', '\1***\3')
-- 김길동 → 김***동

작은것부터