YouTube를 통해 간략하게 BERT에 대해 정리한 내용을 작성한다. 참고한 유튜브 영상은 다음과 같다.
BERT가 이러이러하고 이러이러해서 탄생했다정도로만 알기 위해서 작성한다. 실제의 수학적 동작방식이나 코드에 대해서는 작성하지 않는다. 이렇게만 작성해도 이해가 안가는 부분이 많으므로 해당 부분에서는 버트가 양방향 처리이며 멀티쓰레드가 가능하므로 대용량 처리에 적합하다. 라는 정도만 알면 될 듯 하다.
자연어 처리
BERT가 무엇인지 찾아보면 자연어처리라는 말이 먼저 나오는것 같다. 자연어 처리와 관련된 기본 지식을 먼저 정의한다.
자연어(NPL)
Natural Language Processing
사람의 언어를 컴퓨터가 이해하게 만들어야 하는 처리 과정을 자연어 처리라고 한다.
자연어 처리가 어려운 이유
문장의 숨은 의미를 컴퓨터가 찾기 어렵다. 기계가 이해하기에 너무 많은 변수들이 존재한다
- 단어 자체의 의미
- 문맥적, 함축적, 반어적, 비유적 등의 각종 의미
- 문장의 표현
- 순서도치, 축약, 생략, 장황, 완곡한 표현
도치(倒置)는 어순을 바꾸어 표기하거나 발음하는 것을 말한다.머신러닝
인공신경망을 이용한 머신러닝을 딥러닝이라 한다.(현재는 같은 의미로 사용)
어떤 입력과 결과를 주고 컴퓨터가 그 중간 과정을 정답과의 오답률을 줄이는 방향으로 계속 수치를 대입하여 스스로 학습하는 방법.
우리가 잘 모르는 변수를 스스로 알아내는데 탁월한 방식으로 NLP에 아주 적합한 방식이 될 수 있다.
언어모델
어떤 단어가 주어졌을 때 그 다음에 올 단어를 생성하는 모델 ( 원래 번역을 위해서 탄생함 )
초기 모델 - seq2seq
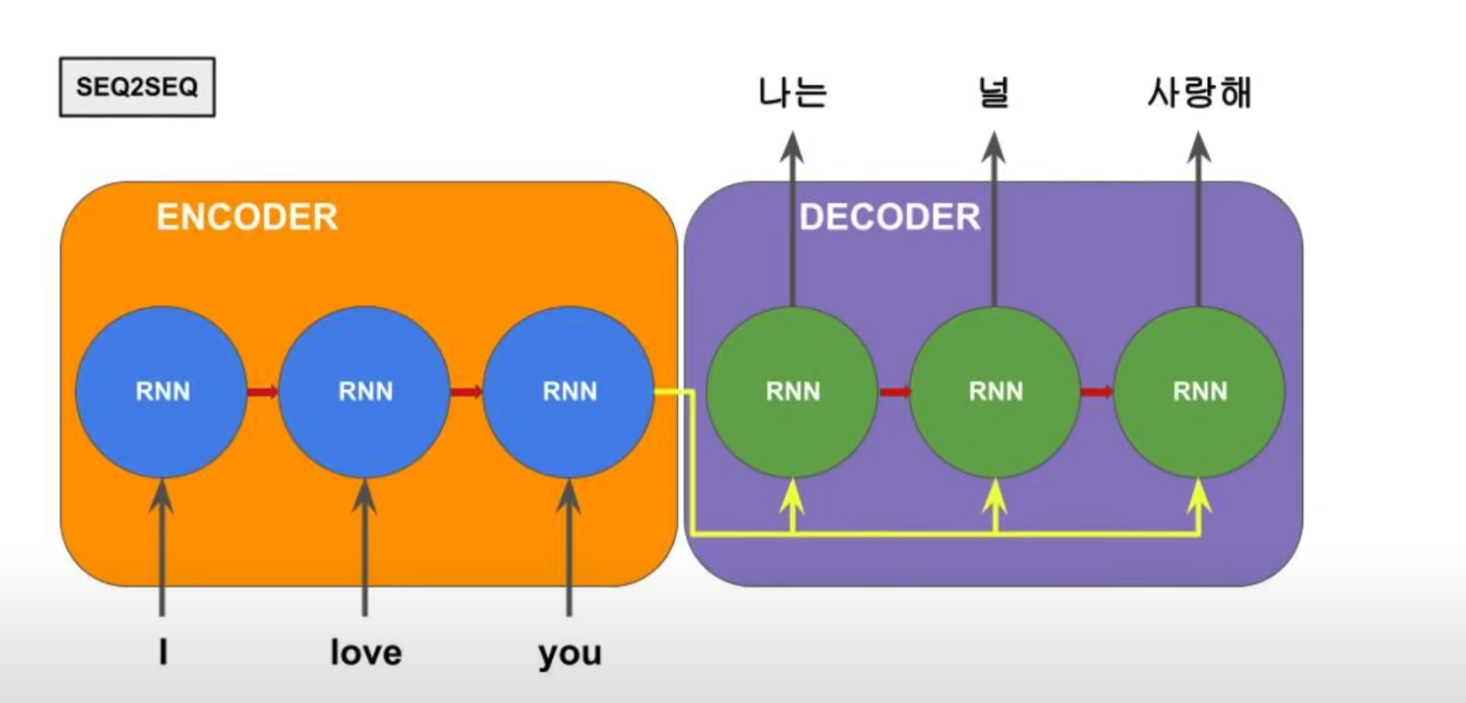
입력 문장이 길면 번역 품질이 떨어지는 현상이 발생하였는데 문제는 다음과 같다.
- 하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하니까 정보 손실이 발생
- RNN의 고질적인 문제인 기울기 소실(vanishing gradient) 문제가 존재
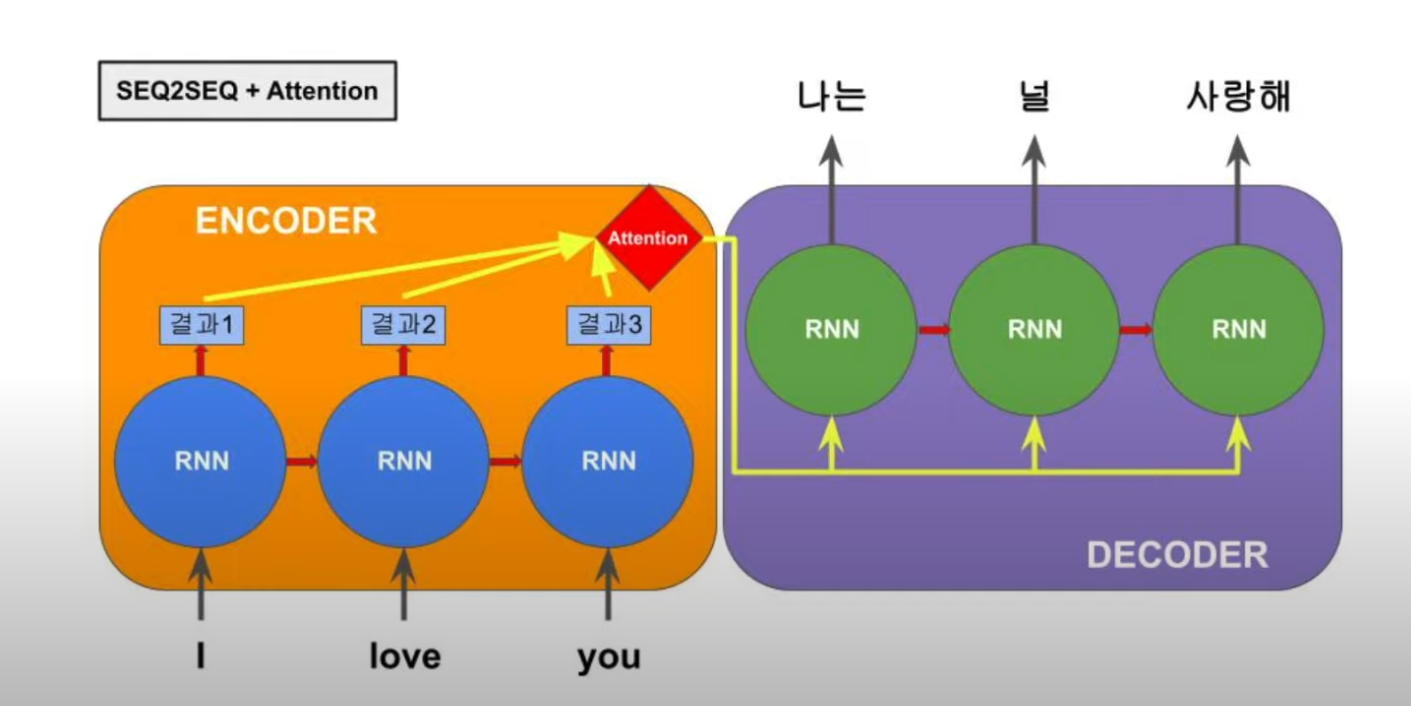
이전의 각 단어 마다의 결과값 전체를 볼수 있고, 그 중 중요한 결과값을 찾아서 다이렉트로 참고할 수 있음
RNN(순환신경망)의 단점
연산을 하기 위해서는 그 전의 결과값이 현재 입력과 같이 입력되어야 하는 구조.
즉, 이전 연산이 끝나기 전에는 다음 연산을 할 수 없다 -> 싱글쓰레드
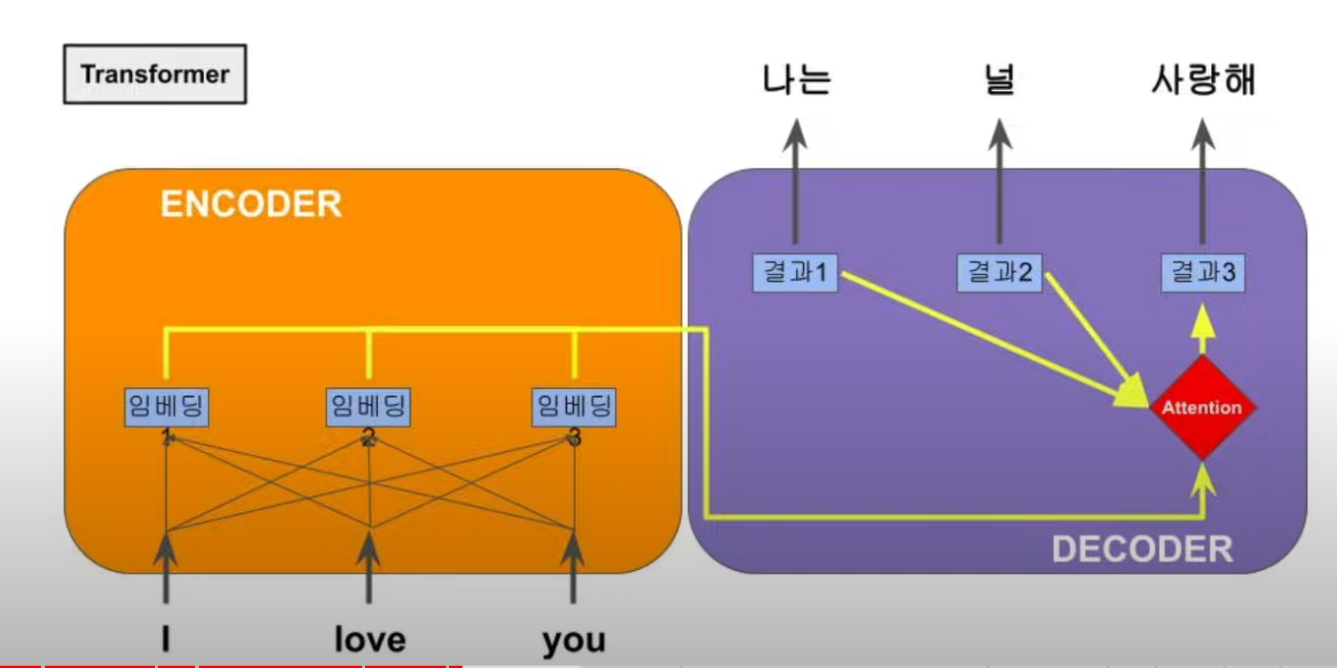
Google Transformer
컴퓨터에게는 다중코어가 있어서 병렬 연산이 가능하니까 RNN을 거치지 않고 각 단어의 특정 결과값을 미리 결정할 수 있다면, 어텐션 구조하에서 병렬 연산에 의해 빠르게 동작하는 모델을 만들수 있다.
단어를 바로 인베딩 처리하고 몇가지 연산 장치들을 고안하여 문장 전체에 대해서 한꺼번에 연산을 할 수 있게 만들었다. 문장의 단어에 대한 특성이 가중된 수치를 미리 뽑을 수 있으면 우리는 이를 한대 모을 수 있는데, 그것이 행렬(Matrix).
행렬은 컴퓨터에게는 대량 고속 병렬처리가 가능한 데이터이고 행렬을 사용함으로써 다음이 가능해진다.
- 초대량의 데이터를 학습할 수 있다.
- 전이학습이 가능 (미리 사전 학습된 모델을 바탕으로 시간과 비용을 줄이면서 우수한 성능의 모델 만듬)
BERT
Bidirectional (양방향) Encoder Representations (표현) Transformers
Bert 등장배경
GPT-1은 트랜스포머 구조에서 인코더 부분을 생략하고 언어 모델의 기본인 문장 생성에 집중해 보기 위해 디코더만을 발전시켜 만들 모델이다.
하지만 단 방향으로만 예측하는 것은 그 문맥을 이해하는데 한계가 있다고 생각하여, 예측해야 하는 단어의 왼쪽 뿐만 아니라 미래에 나올 그 오른쪽 단어들에 대해서도 양방향으로 한꺼번에 학습을 할 수 있으면 더 좋은 성능이 나올 것이다 해서 만들어졌다.
BERT는 분석의 초점에 맞추기 위해서 GPT와는 반대로 트랜스포머에서 디코더 부분은 무시하고 인코더에만 집중한다. 그러면 입력되는 학습 데이터는 어차피 완성된 전체의 문장일 것이니까, 그 뒤의 단어를 예측하는 것이 아니라 중간에 어떤 단어를 가리고(Mask), 그것을 예측하기 위해 양방향으로 전체 문장을 분석하는 학습을 진행하는 것. 이렇게 문장의 마지막 단어 예측이 아닌 중간에 단어를 예측하는 구조로 되어 있으며 이를 Masked Language Model(MLM)라고 부른다.
이것은 비지도 학습으로, 데이터에 대한 라벨링이 필요 없이 웹상에 존재하는 각종 문장을 긁어와서 학습 재료로 쓸 수 있게 되면서 더욱 저렴한 데이터 가공 비용으로 더욱 방대한 학습량을 달성할 수 있게 되었다. 그 결과 정체되어 있던 자연어 처리 성능을 한 단계 발전시키는 큰 성능 향상을 가져옴.
또한 BERT는 대량의 데이터 학습을 통한 사전 학습 모델로, 각각의 태스크에 맞게 추가 신경망레이어를 올리고, 약간의 파인 튜닝을 거치면 대부분의 태스크에서 거의 최고의 성능을 보여준다.
Bert 방식
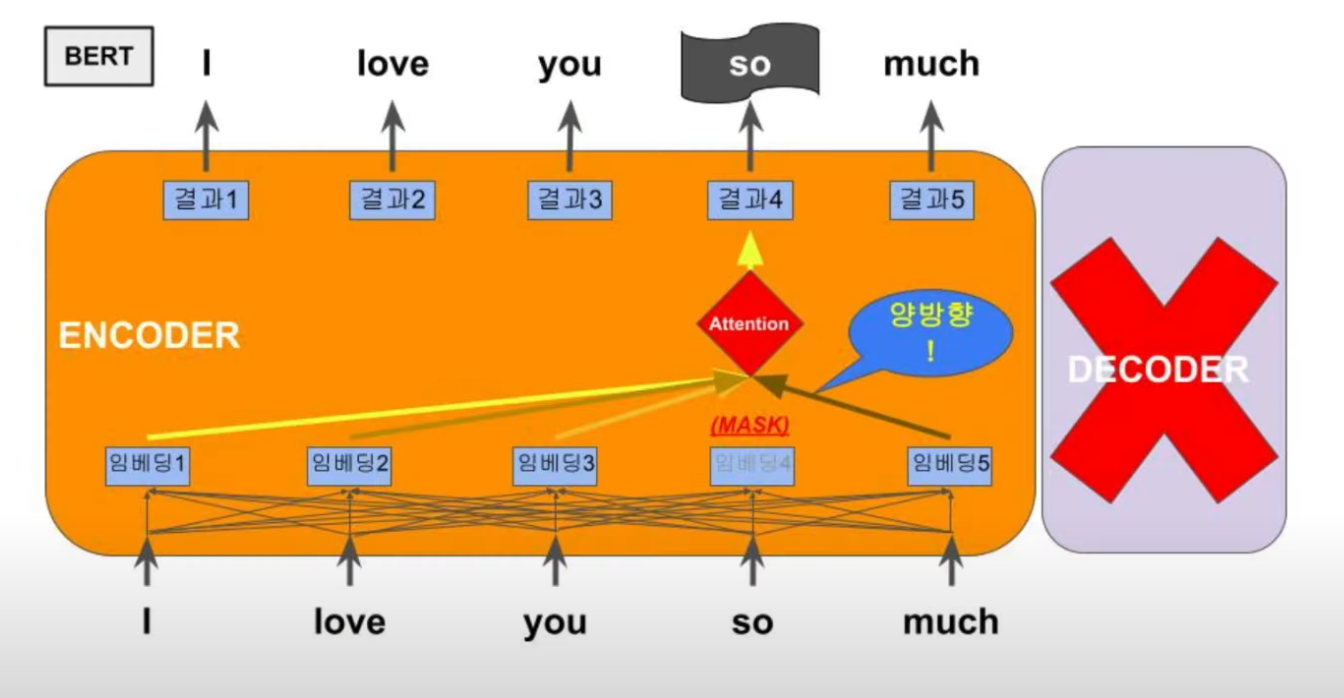
MNM과 다음 문자 예측 방식인 NSP로 학습하게 된다. BERT는 두 문장을 입력할 수 있는 구조로 만들어 졌는데 여기서 두 문장을 분석하여 연속된 문장인지 아닌지 학습하는 장치가 있음
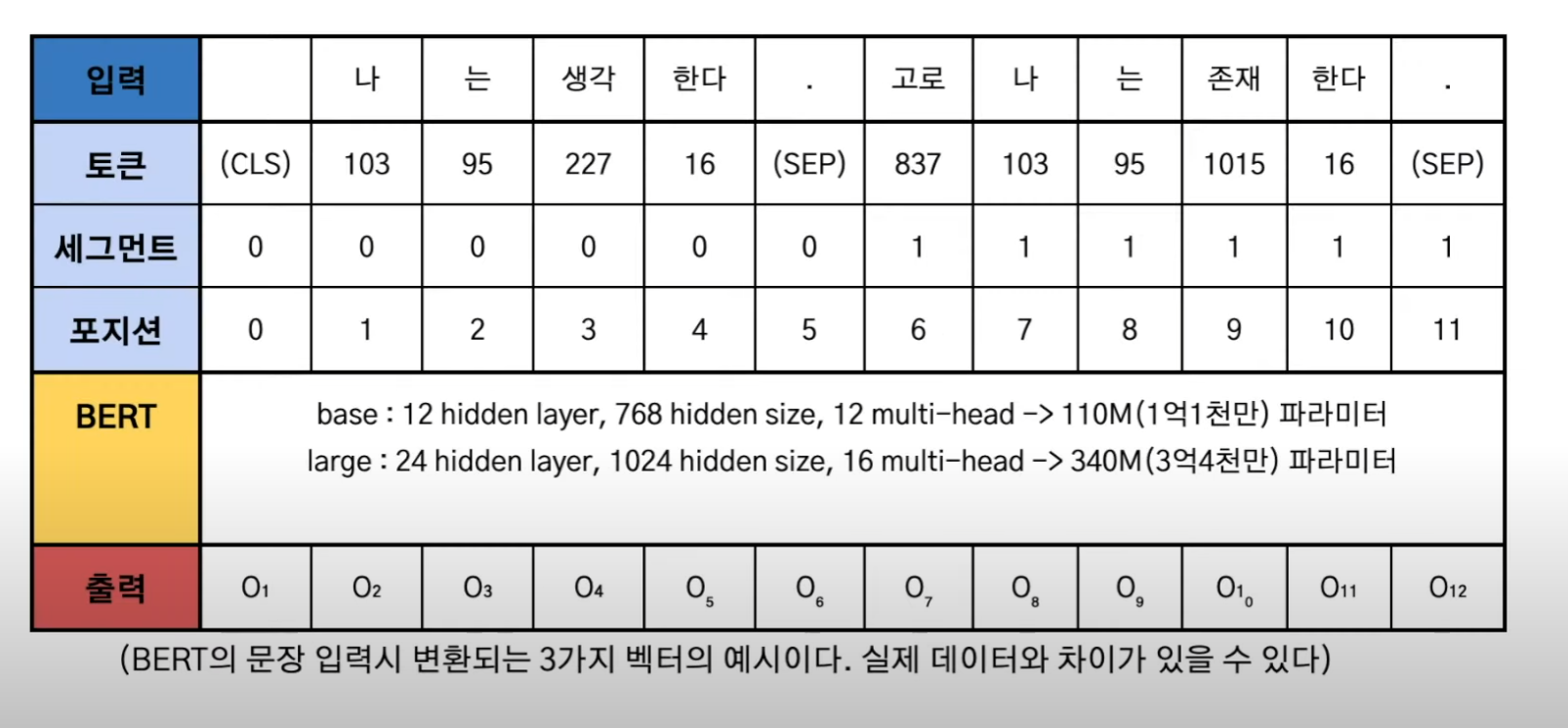
입력된 문장을 세가지 임베딩으로 나눠서 처리
- 토큰 : 각 단어를 치환한 수치
- 세그먼트 : 문장이 첫 번째 문장인지 두 번째 구분하는 구분값
- 포지션 : 한꺼번에 연산할 때 이 단어가 몇 번째 단어인지를 체크하기 위해서 그 위치를 나타내는 수치값
Bert 기반 기술
RoBERTa
A Robustly Optimized BERT Pretraining Approach
BERT가 아직도 잠재된 성능을 온전히 끌어내지 못했다는걸 발견하고 파라미터와 사용되는 데이터 및 트레이닝 방법의 변화를 주어 성능을 더 높일 수 있었다는것을 보여준다.
ALBERT
A Lite BERT
큰 사이즈에서 손해보는 부분이 있다라는 점을 이용하여 입력 인베딩의 사이즈를 줄여서 사이즈 대비 성능 효율을 올리는 튜닝함.
DistilBERT
a distilled version of BERT
큰 모델을 선생으로, 작은 모델을 학생으로 설정하고 큰 모델이 먼저 학습한 결과값을 받아서 작은 모델이 학습함으로써 큰 모델과 거의 유사한 성능을 작은 모델로 이루어낸 기법. 알버트와의 차이는 압축해서 트레이닝을 할 것이냐 트레이닝 된 것을 압축할 것이냐로 표현
BART
Bidirectional Auto-Regressive Transformer
BERT가 인코더만을 이용하여 문장 생성 종류의 태스크에 약점이 있는 것을 보완하기 위해 GPT의 구조를 디코더에 붙여서 만든 모델
ELECTRA
Efficiently Learning an Encoder that Classifies Token Replacements Accurately
BERT가 입력 문장의 15%만을 마스크 하여 학습할 수 있었던 제약을 벗어나기 위해 만든 모델.
먼저, 입력 문장을 작은 사이즈의 MNM모델을 사용하여, 무작위로 바뀌어 생성된 문장을 다시 입력으로 활용하여 학습함으로써 입력 데이터를 100% 학습에 사용할 수 있게 만든 구조. 동일 데이터셋 대비 훈련 효율을 대폭 끌어올린 구조.
제약사항
BERT는 대형 모델이라서 실시간 서비스에 사용하기에는 응답 속도 면에서 제약이 있다.
