라이픽의 이벤트, 통계 및 여러 데이터를 적재하고자 구성한 데이터 플랫폼의 최종 구성현황을 작성한다.
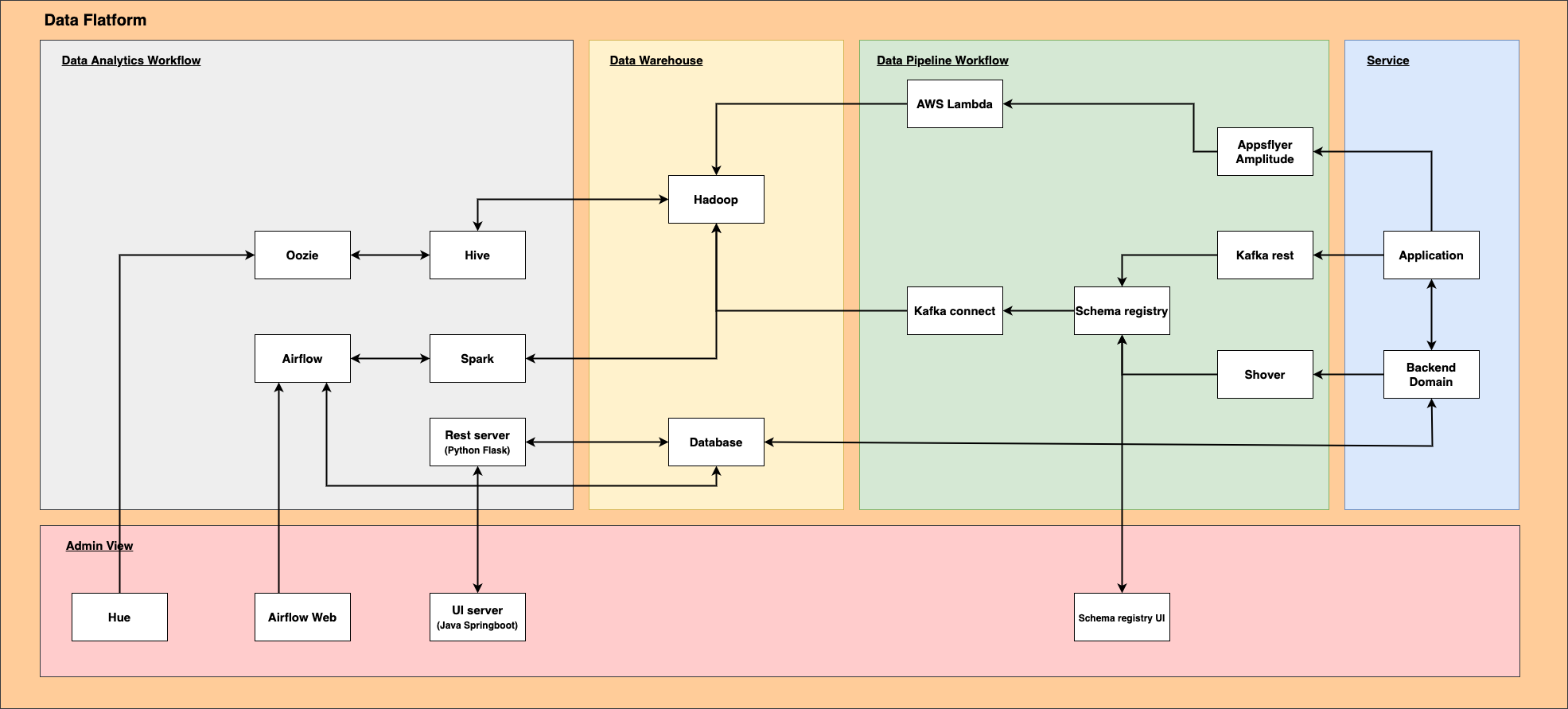
Data Flatform
데이터 적재부터 분석까지 아우르는 라이픽의 전체 서비스
Data Pipeline
데이터를 적재하기 위한 프로세스
Appsflyer / Amplitude
앱에서 발생하는 이벤트를 적재하기 위한 외부 솔루션. 해당 솔루션 웹페이지에서 각종 통계를 볼 수 있으나
보관기간이 있기 때문에라이픽의 저장소에 다시 가져오기 위함
AWS Lambda
AWS에서 제공하는 스케쥴링 서비스,
Appsflyer와Amplitude에서 제공하는 API를 통해 삭제되어지는 데이터를 가져온다.
Kafka Rest
Kafka를 Rest API형태로 프로듀싱 하기 위한 프로세스.
오픈소스를 Fork받아Schema-registry를 통해 비교할 수 있도록 코드 수정
Shover
Kafka 프로듀싱을 Java 라이브러리로 만들어 backend domain에서 사용할 수 있도록 구현.
Spring을 사용하지 않음
Schema registry
스키마를 정의해서 정합성이 검증된 데이터만 Kafka 프로듀싱할 수 있도록 하는 서비스
Kafka Connect
kafka의 Topic에서 컨슈밍하고 일정 조건이 되면 Hadoop으로 전송하는 서비스
Data Warehouse
Hadoop
여러 이벤트나 대용량의 적재가 필요한 데이터를 저장하는 서비스, HDFS로 저장되어 있으며
AWS S3를 마운트하고 있다. 해당 서비스는 EC2에서 구성되며AWS EMR을 사용한다.
Database
추후 UI를 통해 보기위한 통계의 스케쥴 결과를 저장하기 위함. Hive의 조회는 느리기 때문이다.
Data Analytics
Oozie
하둡의 잡(job)을 관리하기 위한 서버 기반의 워크플로 스케줄링 시스템. 자바 기반의 웹 애플리케이션
Hive
하둡에서 동작하는 데이터 웨어하우스 인프라 구조로서 데이터 요약, 질의 및 분석 기능을 제공
Spark (해당 서비스는 구축 예정)
오픈 소스 클러스터 컴퓨팅 프레임워크.
Rest server
MSA로 되어있어서 DB별 JOIN, GROUP BY처리가 되질 않으므로 DB데이터의 행위를 처리하기 위한 서버.
Python으로 되어있으며Pandas를 이용한 Dataframe 처리
Airflow
Oozie의 워크플로우로 구성하기 어려운 스케쥴링을 Airflow로 직접 코드를 작성하여 스케쥴링 한다.
이때 여러 조건이나 DB조회도 Python언어로 조회가 가능.
