OSI 7계층
정리하자면 허브와 스위치는 네트워크를 생성하는 데에 사용되고, 라우터는 이렇게 생성된 네트워크들을 연결시키는 데에 사용된다.
DMA
Direct Memory Access : 특정 하드웨어 하위 시스템이 CPU와 독립적으로 메인 시스템 메모리에 접근할 수 있게 해주는 컴퓨터 시스템의 기능. 이와 반대되는 개념으로 PIO(Programmed I/O)가 있다. 장치들 사이에 전송되는 모든 데이터가 중앙처리장치인 CPU를 거쳐가는 방식이다. DMA는 이렇게 계속해서 CPU가 필요한 PIO의 단점을 보완하기 위해 나온 기능이다.
트랜잭션, Transaction
네트워크 바이트 순서/호스트 바이트 순서
AF_INET
File Descriptor
시스템으로부터 할당받은 파일이나 소켓을 대표하는 함수
Unix I/O
Socket
https://www.youtube.com/watch?v=w9ESLX7MSxM&t=1s
이걸로 무엇을 하든 상관없다. 일단 얘를 적절한 주소 구조체로 만들기만 하면 된다. 받을 때나 보낼 때나 마찬가지이다.
소켓은 네트워크 상에서 다른 프로세스와 통신하기 위해 사용되는 파일이다.
정적 컨텐츠 / 동적 컨텐츠
네트워크 응용 프로그램에서의 RIO Package
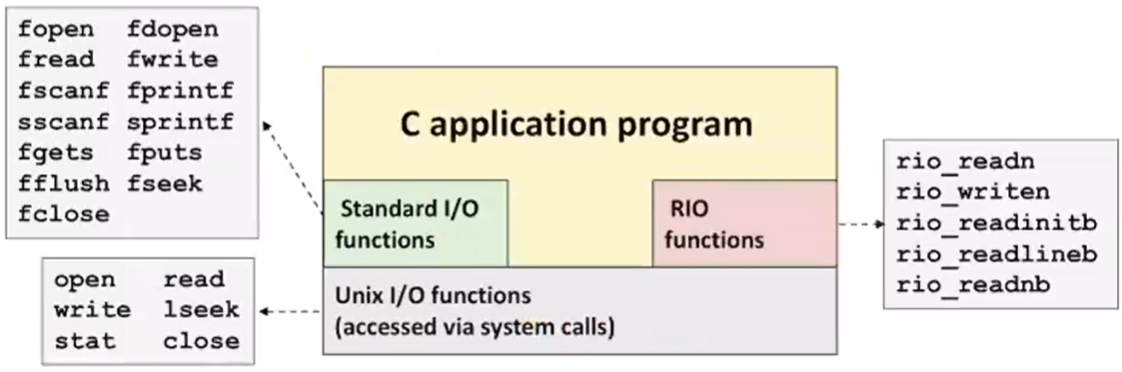
네트워크 응용 프로그램에서 발생할 수 있는 Short Count를 자동으로 처리한다. 동시에, 안정적이면서 효율적인 I/O를 제공한다.
*Short Count
URL / URI
11장. 네트워크 프로그래밍
11.1 클라이언트-서버 프로그래밍 모델
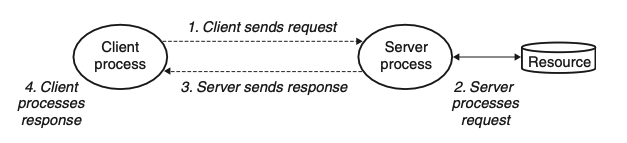
대부분의 네트워크 프로그램은 클라이언트-서버 모델을 기반으로 한다.
- 클라이언트-서버 트랜잭션
- 클라이언트가 서버에게 요청을 보낸다.
- 서버가 요청을 처리한다.(서버가 받은 요청에 따라 동작을 수행한다)
- 서버가 응답을 클라이언트에게 보낸다.(결과를 클라이언트에게 돌려준다)
- 클라이언트가 응답을 처리한다.(받은 결과를 바탕으로 동작을 수행한다)
11.2 네트워크
호스트(그냥 일반 컴퓨터라고 가정)에게 네트워크란, 단지 데이터를 보내고 혹은 받을 수 있는 I/O 디바이스이다.
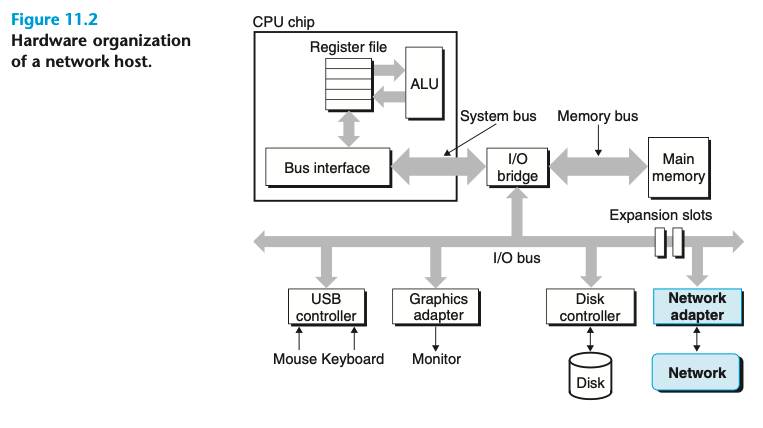
위 그림은 컴퓨터의 마더보드(Mother Board)를 아주 단순하고 직관적으로 나타낸 Diagram이다. I/O 버스와 연결된 확장 슬롯 중 특정 슬롯이 네트워크 어댑터와 연결되어 있다. 이렇게 네트워크를 거쳐 넘어온 데이터는 네트워크 어댑터를 거쳐 I/O 버스로 들어오게 된다. I/O 브릿지를 거쳐 메인 메모리에 적재되고, 메모리 버스와 시스템 버스를 통해 CPU와 소통할 수 있게 된다. 이 때 전송은 대게 DMA 전송으로 이뤄진다.
*DMA
Direct Memory Access, 특정 하드웨어 하위 시스템이 CPU와 독립적으로 메인 시스템 메모리에 접근할 수 있게 해주는 컴퓨터 시스템의 기능.(원칙적으로 메모리는 CPU에 의해서만 접근할 수 있다) 이와 반대되는 개념으로 PIO(Programmed I/O)가 있다. 장치들 사이에 전송되는 모든 데이터가 중앙처리장치인 CPU를 거쳐가는 방식이다. DMA는 이렇게 계속해서 CPU가 필요한 PIO의 단점을 보완하기 위해 나온 기능이다.
반대의 절차를 거쳐, CPU에서 메인 메모리의 데이터를 외부 네트워크로 보낼 수 있을 것이다. 컴퓨터가 디스크와 소통하는 것처럼, 똑같이 네트워크와 소통한다.
네트워크 분류
네트워크는 지리적인 근접 정도에 따라 분류할 수 있다.
-
SAN : System Area Network
방 사이즈 정도로 아주 작은 단위이다.
48-Bit Address로 각 호스트는 유니크한 주소를 가지고 있다. 이를 MAC Address라고 한다.
호스트는 다른 호스트에게 Chunk(512B) 단위로 비트(데이터)를 보낸다. 이를 Frame이라고 칭한다.
이 때 데이터는 허브를 통해 전송되게 되는데, 스위치와는 달리 모든 포트로 데이터를 전송한다. 스위치는 데이터를 원하는 목적지에만 전달할 수 있어, 현대에는 스위치를 주로 사용하고 있다.
ex. Ethernet Segment
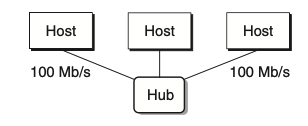
* Ethernet Segment : 몇 개의 호스트와 허브로 이루어져 있다.
-
LAN : Local Area Network
빌딩 혹은 캠퍼스 정도되는 지역 단위의 네트워크이다.
ex. Ethernet
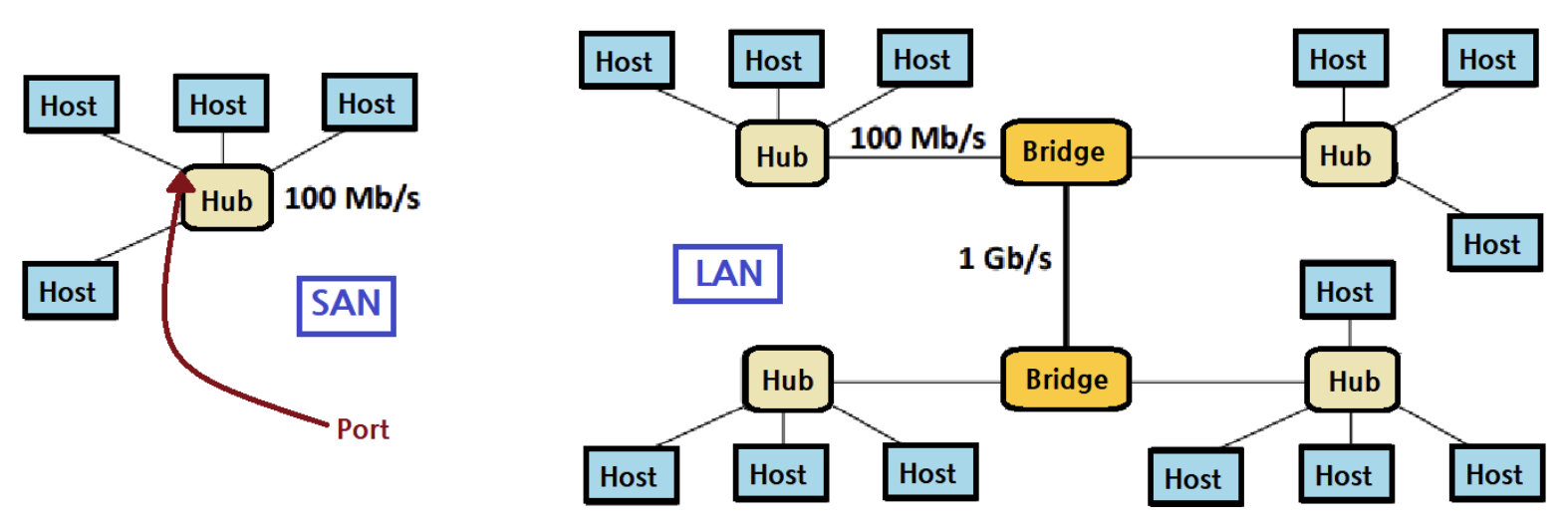
브릿지를 통해 각 Ethernet Segment(SAN)을 묶는다.
-
WAN : Wide Area Network
국가, 세계 단위의 방대한 크기의 네트워크를 의미힌다.
ex. Point-to-Point Phone Line
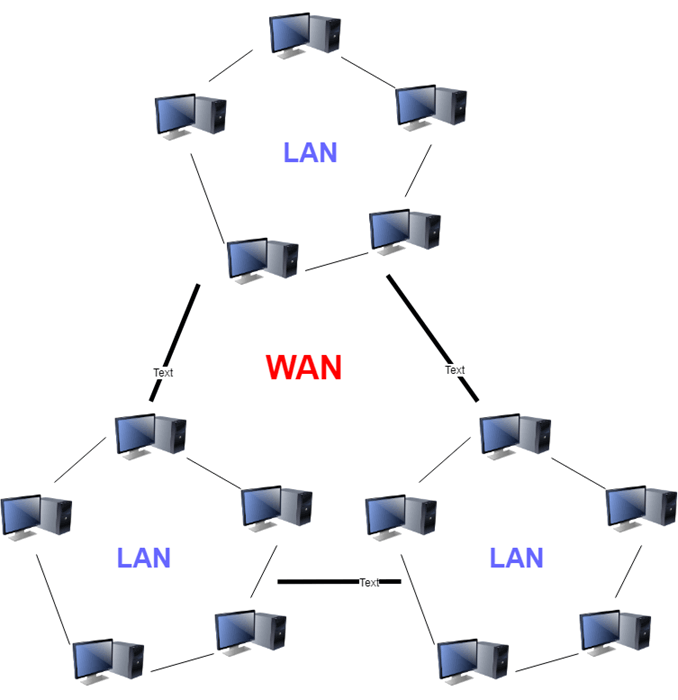
WAN은 이처럼 LAN들을 라우터들로 연결해놓은 것이다. 각 LAN들은 서로 다른 네트워크 방식으로 되어 있을 수 있다.
예로, 호스트 A에서는 Ethernet 방식을 사용하나, 호스트 B는 FibreChannel 방식을 사용할 수도 있다. 이렇게 서로 다른 두 네트워크 방식을 맞춰주는 것이 프로토콜, Protocol이다.
IP(Internet Protocol)
서로 다른 네트워크 방식으로 통신하는 LAN과 WAN들이 데이터를 주고 받을 수 있도록 통일된 하나의 약속, 규격이 필요하다. 프로토콜이라는 소프트웨어를 각 라우터와 호스트에 설치하여 서로 다른 네트워크 방식에서도 소통을 가능케하는 것이다. 즉 프로토콜은 하나의 네트워크에서 다른 네트워크로 데이터가 전달될 때, 호스트와 라우터가 어떻게 협력할지 규칙을 정한 것이다.
프로토콜의 임무
-
Naming Scheme
각 호스트(혹은 라우터)는, 자신을 유일하게 구별할 수 있는 최소 하나의 주소를 할당 받는다. -
Delivery Mechanism
Standard Transfer Unit인 패킷(Packet)을 정의한다.
서로 다른 네트워크는, 프레임(Data Link 계층에서 데이터에 MAC 주소만 부여한 것)을 각자 다른 방식으로, 즉 비호환적으로 패키징한다. 인터넷 프로토콜은 통일된 방식으로 이러한 데이터를 패킷으로 묶는다.
- Packet Header : 패킷의 사이즈와 Source(송신한 곳), Destination(수신할 곳) 주소를 담는다.
- Packet Payload : 실제로 보내고자 하는 데이터가 담긴다. -
internet에서 데이터가 하나의 호스트에서 다른 호스트로 이동하는 방법
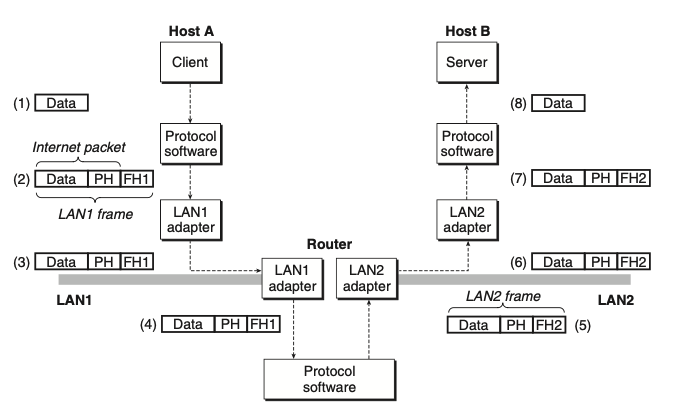
위 그림은 인터넷 프로토콜을 통해 서로 다른 네트워크 방식으로 통신하고 있는 LAN에서 어떻게 다른 LAN으로 데이터를 전송하는지 보여주고 있다.
-
클라이언트(호스트 A)는 커널 버퍼로 데이터를 복사하는 시스템 콜을 호출한다.
-
호스트 A의 프로토콜 소프트웨어는 호스트 A가 전송한 데이터에, 호스트 B의 주소를 나타내는 PH(internet Packet Header)와 LAN1 라우터 주소를 나타내는 FH(Frame Header)를 덧붙인다.
-
LAN1 어댑터는 이 프레임을 받아 네트워크로 복사한다.
-
프레임이 라우터에 도착하면, LAN1 어댑터는 이것을 프로토콜 소프트웨어로 전달한다.
-
라우터는 PH를 읽고, 어느 라우터로 보낼지 결정한다. 즉 기존 FH를 제거하고 새로운 FH를 덧붙이게 된다.(라우터도 프로토콜 소프트웨어가 있다)
-
FH와 PH를 벗겨내고 서버(호스트 B)가 데이터를 읽게 된다.
* 캡슐화: 이렇게 패킷을 프레임화 하여 주고 받는 과정을 캡슐화, Encapsulation이라고 칭한다.
* 보낼 때, data -> packet -> frame
* 받을 때, frame -> packet -> data
11.3 글로벌 IP 인터넷
TCP/IP
IPv4/IPv6
DNS
11.4 소켓 인터페이스
bind
컴퓨터의 위치는 IP 주소로 찾을 수 있고, 컴퓨터에서 소프트웨어는 포트 번호로 찾을 수 있다.
서버가 sockfd 디스크립터를 통해서 communication 하겠다고 OS Kernel에게 알리는 과정이 bind이다.
OS Kernel에게, 생성한 Socket Address와 Descriptor, IP 주소, 포트 번호를 전달하는 작업을 수행한다.
서버 측에만 bind가 존재하는 이유
listen
OS Kernel은 기본 설정으로 인해, socket 함수로 만들어지는 모든 반환 Descriptor를, connection 관계에서 클라이언트 쪽의 endpoint에 위치한 능동 소켓으로 인식한다.
하지만 서버 쪽의 endpoint에 위치한 소켓은 수동 소켓이다.(요청을 받아들이는 개체이기 때문이다) 따라서 OS Kernel이 이 서버 소켓을 수동 소켓으로 인식할 필요가 있다.
그 때 사용하는 것이 listen이다.
OS Kernel에게, 이 sockfd는 서버 소켓이고, 이 서버 소켓이 connection 요청을 받을 것이라고 알려준다.
이 서버 소켓을 listening 소켓으로 사용할 것이라고 알려주는 것이다.
accept
서버는 연결될 준비가 되었음을 알려주고, 연결 request를 받는다.
도착한 클라이언트의 소켓 주소와 사이즈를 업데이트 한다.
연결 식별자 connected descriptor(connfd)를 반환하고, UNIX I/O와 이 식별자를 통해 클라이언트와 통신할 수 있게 된다.
listenfd와 connfd를 따로 두는 이유
listenfd, connfd
- listenfd : 클라이언트의 connect 요청을 받기 위한 endpoint이다. 서버 프로세스에 대해 한 번만 생성되고, 서버가 죽을 때까지 계속 살아있는다.
- connfd : client와의 connection 관계에서의 endpoint이다. 서버가 connect request를 accept 할 때마다 생성된다. 서비스가 종료되면 소멸된다.
connection reset by peer
서버에 없는 정적 컨텐츠를 요구할 때
Tiny 서버
Proxy 서버
* nop-server.py에서 맨 위 주석에 그냥 python을 python3로 바꿔야 제대로 채점이 된다.
- reverse
- forward
- road balancing

웹 브라우저가 바로, 직접적으로 끝단의 웹 서버를 방문하는 것이 아니라 프록시 서버를 거치게 하는 것이다.
프록시 서버의 캐시를 통한 빠른 전송과 비용 절감
부동산 중개인이라고 생각하면 쉽다. 내가 직접 웹 서버에 방문해도 되지만, 프록시 서버가 대신 갔다 와도 된다. 이 때 프록시 서버는 이미 웹 서버의 정보를 캐쉬에 담고 있을 수도 있어서 나는 바로 그 정보를 볼 수 있게 된다. 이렇게 하면 시간이 줄어든다. 그리고 내가 웹 서버에 방문했는지 안했는지에 대한 정보도 남기지 않을 수 있어 익명성을 보장해줄 수 있다.
방화벽
서버로 요청될 request header를 보고, 적절치 않으면 프록시가 차단시킬 수 있다.
익명으로 만듦
프록시가 대신 웹 서버에 방문하기 때문에
캐쉬
Sequential
Concurrent
여러 요청을 동시에 처리할 수 있어야 한다. 가장 간단한 방법은 새로운 쓰레드(Thread)를 생성하는 것이다.
Cache
다른 클라이언트가 동일한 서버에서 동일한 개체를 요청할 경우, 프록시는 웹서버에 연결해서 웹서버의 반응을 가져다 주는 것이 아니라, 연결하지 않고 본인의 캐시에 저장되어 있던 데이터를 클라이언트에게 반환한다.
하나의 거대한 객체(데이터)가 프록시의 전체 캐시를 한번에 소비하여, 다른 객체가 캐시를 사용하지 못할 수도 있으므로 이를 방지해줄 수 있어야 한다.
캐시도 비워줄 필요가 있는데 최근에 사용된 정도가 적은 것을 위주로 캐시를 삭제하는 제거 정책을 택하는 것이 좋다.
객체를 읽고, 쓰는 것 또한 객체를 사용하는 것으로 간주한다. 클라이언트가 서버에 데이터를 요청했고, 프록시의 캐시에 해당 객체가 있다면, 이 때 요청이 읽고 쓰는 것이라면 캐시를 그대로 클라이언트한테 보내주면 된다는 뜻인가?
기타
많은 종류의 오류나 잘못된 입력에 대해, 서버를 그 즉시 종료시키는 것이 아니라 적절히 대응할 수 있도록 견고해야 한다.
끝단의 웹 서버는 일반적으로 오랫동안 실행되는데, 프록시도 당연히 예외는 아니다. 즉 프록시도 오래 실행된다.
Tiny 서버처럼 short count를 자동으로 처리해주어 네트워크 환경에 적합한 Robust I/O 패키지를 사용하는 것이 좋다.
웹의 컨텐츠가 ASCII 텍스트가 아니다. 이미지와 비디오, 이진 데이터일 수 있으니 이를 고려해야 한다.
경쟁 조건(race condition)
여러 프로세스/스레드가 동시에 같은 데이터를 조작할 때, 타이밍이나 접근 순서에 따라 결과가 달라질 수 있는 상황을 말한다.
동기화(synchronization)
여러 프로세스/스레드를 동시에 실행해도, 공유 데이터의 일관성을 유지하는 것이다.
임계 영역(critical section)
공유 데이터의 일관성을 보장하기 위해, 하나의 프로세스/스레드만 진입해서 실행이 가능한 영역이다.
mutual exclusion
하나의 프로세스/스레드만 진입해서 실행하는 것이다.
스핀락(spinlock)
락을 가질 수 있을 때까지 반복해서 시도하는 것이다. 기다리는 동안 CPU를 낭비하는 단점이 있다. 계속해서 LOCK 상태인지 확인해야 해서 효율적이지 않다. 따라서 락이 풀릴 것 같으면 날 깨워라는 방식이 필요하다.
뮤텍스(mutex)
락을 가질 수 있을 때까지 휴식하는 방식이다. 락을 가진 자만이 락을 해제할 수 있다.
락을 가지지 못하면 대기 큐에 넣고, 이후 앞의 작업이 끝나 락을 다른 누군가가 가져갈 수 있게 되면 대기 큐에 가장 먼저 들어온 것이 실행된다.
이 때 이 락의 value를 바꿔주는 과정도 보호 받을 수 있어야 하는데, 이 때 guard가 사용되고 이 guard는 CPU 레벨에서 지원하는 atomic한 명령어를 사용하고 있다.(동시에 요청이 들어와도 1개씩 처리할 수 있도록)
CPU 사이클 낭비를 최소화할 수 있다.
세마포어
멀티프로그래밍 환경에서 다수의 프로세스나 스레드가, 여러 개의 공유 자원에 대한 접근을 제한하는 방법으로 사용된다.
프로세스 간 메시지를 전송하거나, 공유 메모리를 통해 특정 데이터를 공유할 경우 문제가 발생할 수 있다. 즉 공유된 자원에 여러 개의 프로세스 혹은 스레드가 동시에 접근하면서 문제가 발생하는 것을 막기 위해, 공유된 자원 속 하나의 데이터는 하나의 프로세스만 접근할 수 있도록 제한을 둬야 한다.
signal mechanism(순서를 정해주는)을 가진, 하나 이상의 프로세스/스레드가 critical section에 접근 가능하도록 하는 장치이다.
상호 배제만 필요하다면 뮤텍스를, 작업 간의 실행 순서 동기화가 필요하다면 세마포어가 권장된다.
코드
참고한 서적 및 동영상, 블로그
- Unix I/O
- CSAPP 11장
