* 출처 : 유튜브 HPC Lab. KOREATECH
Virtual Memory Management 1
-
Non-continuous allocation
- 사용자 프로그램을 block 단위로 나누지만, 필요한 것들만 메모리에 올려놓고 사용한다.(적재/실행)
-
Paging / Segmentation system
-
가상 메모리 관리의 목적
- 가상 메모리 시스템 성능을 최적화한다.
- cost model, 구체적인 성능을 표현하기 위한 지표.
- 다양한 최적화 기법이 있다.
- 가상 메모리 시스템 성능을 최적화한다.
Cost Model for Virtual Memory System
- Cost Model
- Page Fault Frequency(발생 빈도)
- Page Fault Rate(발생률)
- 프로세스를 일정한 크기인 페이지로 잘라 놓는다.
- 이 전체 프로세스는 Swap Device에 있다.
- 필요한 것이 메모리에 올라가고, CPU가 이를 참조해 작업을 수행하게 된다.
- CPU가 참조하려고 메모리를 확인했을 때 없으면 Page Fault가 발생하게 된다.
- I/O 작업이 필요해져 CPU를 반납하고 해당 프로세스는 Running 상태에서 block(asleep) 상태가 된다.
- I/O 작업이 완료되면 Ready 상태가 되고 Running이 된다.
- 이렇게 프로세스가 바뀌고(CPU에 다른 프로세스가 올라가는), 다시 자신의 프로세스로 바뀌는 등 이러한 것이 컨텍스트 스위칭
- 이는 kernel이 개입하게 되는데 overhead가 커진다.(cost가 증가한다)
- 따라서 시스템 성능을 향상 시키기 위해서(오버헤드를 줄이기 위해)는 page fault rate를 최소화해야 한다.
- 메모리는 페이지 프레임 단위로 잘라 놓는다.
* 페이징 시스템이라고 가정

-
Page reference string(페이지 참조 문자열)
- 참조한 페이지들을 어떤 순서로 참조했는지 적어 놓는 것.
- 프로세스의 수행 중 참조한 페이지 번호 순서
- 이러한 정보가 있어야 페이지들을 효율적으로 사용하고 있는지 알 수 있다.
-
위에서 |w|는 절댓값이기도 하지만, 여기서는 길이 혹은 갯수라고 봐도 된다.
- 분모 |w|는 이 프로세스가 실행하면서 참조한 전체 페이지 갯수(중복된 것도 포함해서 계산된다)
- page fault가 났던 페이지 갯수
- 즉 전체 페이지 갯수 중 page fault가 난 것들로, page fault 발생률을 뜻하게 된다.
- page fault / 전체 page
Hardware Components

Bit Vectors
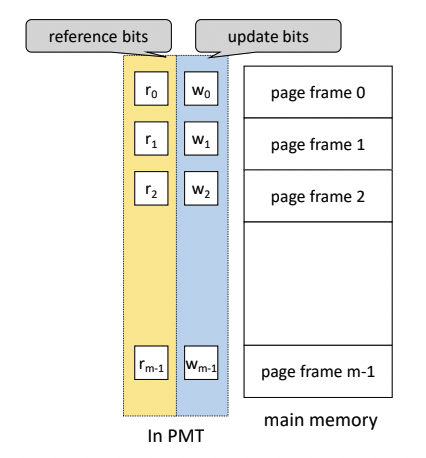
- Bit Vectors
- 비트들이 array 형태로 있다고 생각.
- 페이지 프레임 하나마다 reference bits와 update bits가 있다.(PMT에 존재)
- Page 사용 상황에 대한 정보를 기록하는 비트들.
- 대표적인 비트들
- reference bits(used bit)

- 참조 비트
- 메모리에 적재된 각각의 page가 최근에 참조 되었는지를 표시한다.
- 나중에 메모리가 꽉 차서 특정 page를 골라 swap out 시켜야 할 때, 최근 참조가 안된 page를 swap out 시킬 수도 있다.
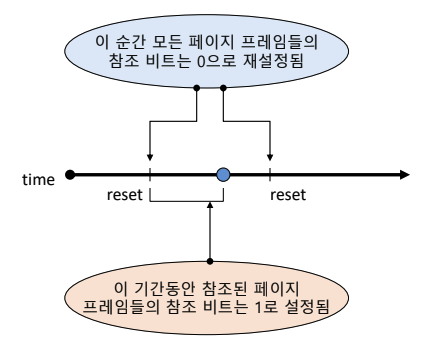
- 어느 순간에 모든 페이지 프레임의 참조 비트를 0으로 재설정한다.
- Update bits(modified bits, write bits, dirty bits)

- Page가 메모리에 적재된 후, 프로세스에 의해 수정되었는지를 표시한다.
- reference bits와는 달리 주기적으로 초기화를 하진 않는다.
- 메모리에서 나올 때 초기화한다. 즉 update bit를 0으로 바꾼다.
- 프로세스가 어떤 페이지에 write를 했다면 데이터가 바뀌었다는 의미이다.
- update bit를 1로 바꾼다.
- 프로세스에 대한 전체 페이지들은 swap device에 있다.
- 메모리에서 나올 때 swap device에도 업데이트를 적용해야 하는지 말아야 하는지 알 수 있다.
- dirty bits는 이 페이지가 더럽혀졌다는 것을 의미한다.
- reference bits(used bit)
- 비트들이 array 형태로 있다고 생각.
Virtual Memory Management 2
Software components

- 가상 메모리 성능 향상을 위한, 소프트웨어적인 관리 기법
Allocation Strategies
- 고정 할당, Fixed allocation
- 프로세스가 실행되는 동안, 고정된 크기의 메모리가 주어진다.
- 페이지 프레임의 수를 고정해서 준다.
- 가변 할당, Variable allocation
- 프로세스가 실행되는 동안, 할당되는 메모리의 크기는 유동적으로 바뀐다.
- 페이지 프레임의 수가 3개가 될 수도 있고 4개가 될 수도 있는 방식
- 고려 사항
- 프로세스 실행에 필요한 메모리 양을 예측할 필요가 있다.
- 너무 큰 메모리 할당은 메모리를 낭비시킬 수 있다.
- 너무 적은 메모리 할당은 page fault rate, 즉 page fault를 많이 발생시키게 되니 시스템의 성능이 저하될 수 있다.
Fetch Strategies
-
운영체제에서 메모리나 디스크에서 말하는 Fetch
- 어떤 데이터를 가져오는 것.
-
필요한 데이터를 언제 가져올 것인가에 대한 것이 fetch strategies
-
Demand Fetch(Demand Paging)
- 필요할 때, 즉 참조해야 할 때 메모리에 적재하는 전략이 Demand Fetch(Demand Paging)이다.
- page fault overhead가 계속해서 발생할 수 있다.
-
Anticipatory Fetch(pre-paging)
-
참조될 가능성이 높은 page를 예측한다.
-
이렇게 가까운 미래에 참조될 가능성이 높은 page를 미리 메모리에 적재하는 전략이다.
-
예측 성공 시, page fault overhead가 없다. 혹은 줄일 수 있다.
-
Hit ratio에 민감하다.
-
만약 가져온 페이지들에서 중간에 끊어야 하면, 사용하지 않은 페이지들을 다시 swap device에 넣어야 한다. 이는 kernel 개입이 상대적으로 커져서 오버헤드가 크게 발생할 수 있다. prediction overhead
-
-
-
실제 대부분의 OS는 Demand Fetch 기법을 사용한다.
- 일반적으로 준수한 성능을 보여주고 있다.
- Anticipatory Fetch는 예측하는 것이 쉽지 않고, 예측을 잘못하면 자원 낭비가 크다.
-
그럼에도 Anticipatory Fetch를 배우고 사용하는 이유
- 우리가 만든 프로그램은 작은 OS다. 그 안에서 여러 기능을 하는 것이므로.
- 내가 알고리즘을 짰으니까, 내가 프로그램을 만들었으니까 앞으로 어떤 자원이 사용될지 알 것이다.
- A를 읽었다면, 알고리즘에 의해 다음에는 B를 읽을 것이라는 것을 나는 알 수 있다.
- 이렇게 내가 내부적으로 아니까 Anticipatory Fetch 기법을 사용할 수 있다.
Placement Strategies

- page는 공간의 크기들이 일정하기 때문에 불필요하다. 프로그램을 4KB로 쪼개서 비어있는 페이지 프레임에 그냥 넣으면 된다.
Replacement Strategies

- 새로운 page를 어떤 page와 교체할 것인가?
- 이 상황은 비어 있는 page frame이 없을 경우 발생한다.
Cleaning Strategies

- 앞 전에 배운 update bit(혹은 dirty bit이라고 한다) 관련
- 프로세스는 swap device 영역이 아니라 아니라 메인 메모리에 올라온 페이지 프레임에 write 등의 작업을 하게 된다.
- 그러면 dirty bit가 1이 된다.
- swap device의 데이타와 메인 메모리에 올라온 페이지 프레임의 데이터가 다르게 된다.
- 다르므로 바꾼 내용을 반영해줘야 한다.
- 변경된 내용을 swap device에 적용해주는 것이 write-back이다.
- 변경된 page를 언제 write-back 할 것인가?
- swap device에 언제 반영할 것인가? 이것이 cleaning strategies이다.
- Demand Cleaning, 가장 쉬운 방법
- 해당 페이지 프레임이 메모리에서 내려올 때 write-back한다.
- Anticipatory Cleaning(pre-cleaning)
- 해당 페이지 프레임에 write한 후, 이제 read만 할 거면, 굳이 메모리에서 내려올 때가 아니라 미리 write-back하면 된다.(page 교체할 때가 아니라 여유 있을 때 미리 해놓는다)
- 하지만 write-back한 후 내용을 수정할 경우, 즉 예측에 실패하면 overhead가 더 생기게 된다.
- 실제 대부분의 OS는 Demand Cleaning 기법을 사용한다.
- 일반적으로 준수한 성능을 보여준다.
- Anticipatory Cleaning은 잘못된 예측 시 자원 낭비가 크다.
Load Control Strateiges

-
운영체제에서 load는 부하 혹은 얼마나 일을 떠맡았는가이다.
- 프로세스가 많이 들어오면 load가 큰 것이다.
-
시스템의 multi-programming degree를 조절하는 것이 load control strateiges이다.
- Allocation strategies와 연계된다.
-
plateau, 고원 상태 유지가 필요하다.
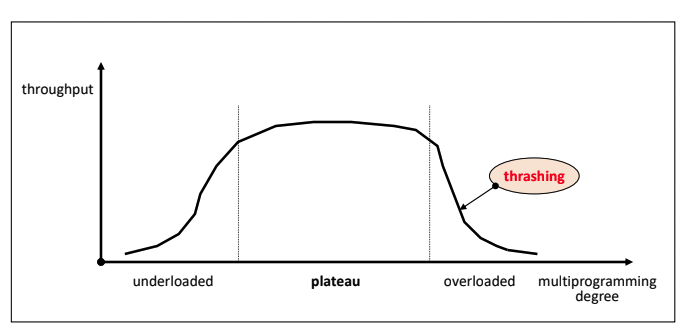
-
multi-programming degree를 너무 낮추면 낭비가 심하다. 그리고 제대로 활용하지 못하니 성능이 저하된다고 볼 수 있다.
-
너무 높으면 자원에 대한 경쟁이 심화되고 성능이 저하 된다.(프로세스가 몰리고 메모리가 꽉 차면 page fault가 자주 일어나서)
- page fault는 많이 비싼 연산이다.
Replacements Strategies - Fixed Allocation
Locality

- 프로세스가 프로그램/데이터의 특정 영역을 집중적으로 참조하는 현상
- 공간적 지역성
- 참조한 영역과 인접한 영역을 참조하는 특성
- 시간적 지역성
- 한 번 참조한 영역을 곧 다시 참조하는 특성
Locality Example
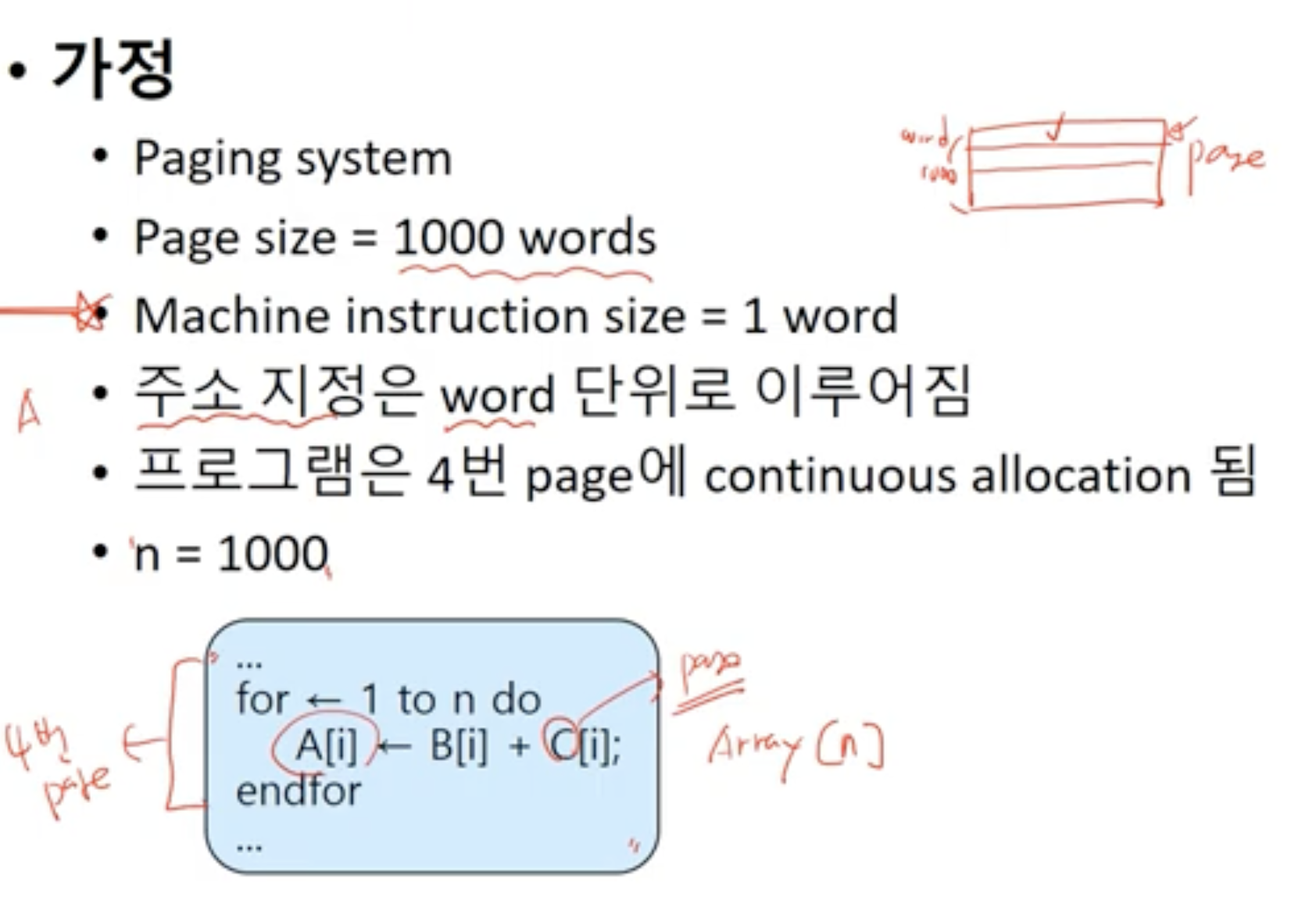
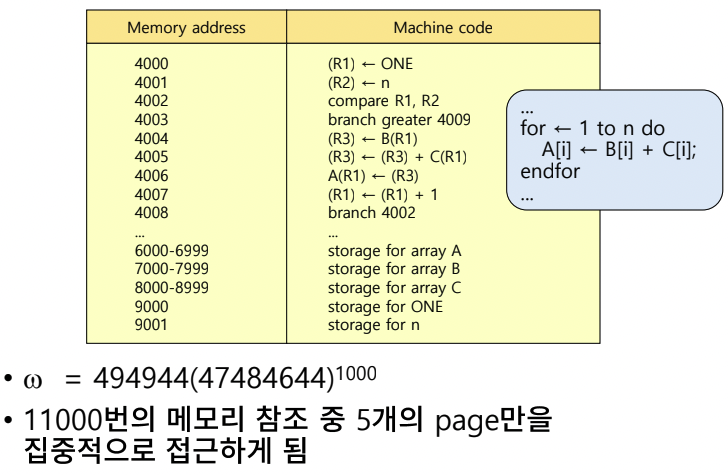
- for문을 돌다보니 특정 페이지 영역이 자주 참조되는 것을 알 수 있다.
Fixed allocation
- 프로세스에게 주어지는 페이지 프레임이 고정되어 있다.
- 만약 프로세스 A에게 주어진 페이지 프레임이 4개(1, 2, 3, 4)이고, 이 4개를 다 쓰고 있는 상태에서 1개(5)가 더 들어오려고 하면 4개 중 1개가 빠져야 한다. 즉 교체가 일어나야 한다.
- 어떤 페이지를 교체해야 할지가 Replacement Strategies이다.
Min Algorithm (OPT algorithm)

- 최소화
- page fault가 가장 적어지면 성능이 좋아진다.
- 최적의 솔루션으로 Optimal Solution
- 기법
- 앞으로 가장 오랫동안 참조되지 않을 page를 교체한다.
- refenrence string을 미리 알고 있어야 한다.
- 실현 불가능한 기법이다. 미래를 알고 있다고 가정하는 기법이기 때문이다.
- 다른 교체 기법의 성능 평가 도구로 사용된다.
- 알고리즘 1개를 만들었는데, 이 알고리즘이 얼마나 최적화될지, 최적 기법과 비교해본다.
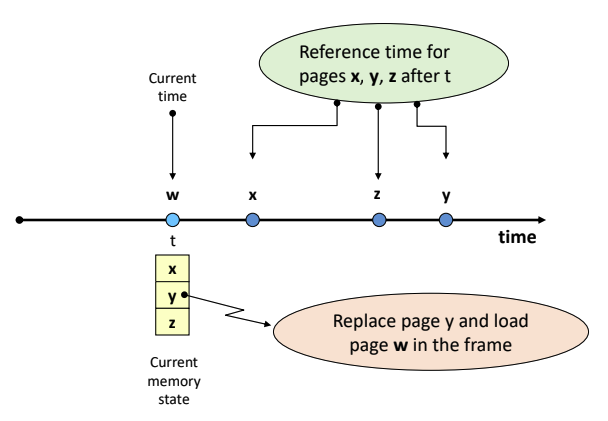
- 해당 프로세스에게 할당된 프레임이 꽉 찬 상태에서 w가 들어올 때, 가장 오랫동안 참조하지 않을 y를 교체한다.
- 알고리즘 1개를 만들었는데, 이 알고리즘이 얼마나 최적화될지, 최적 기법과 비교해본다.
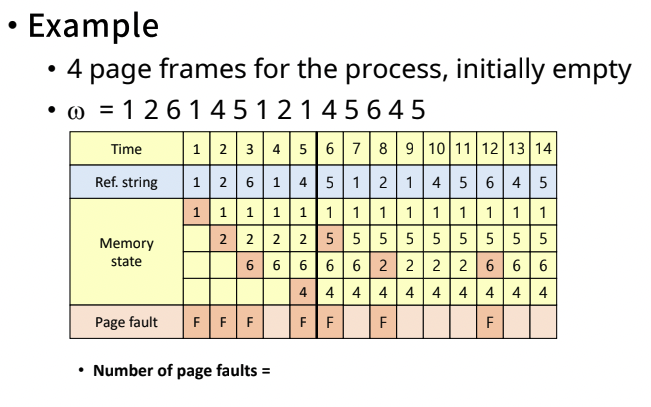
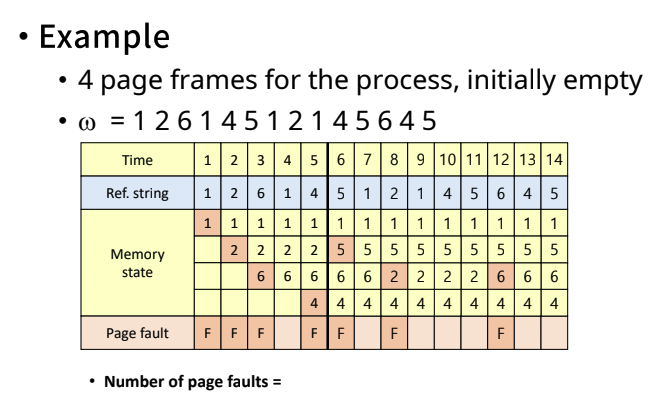
- Example
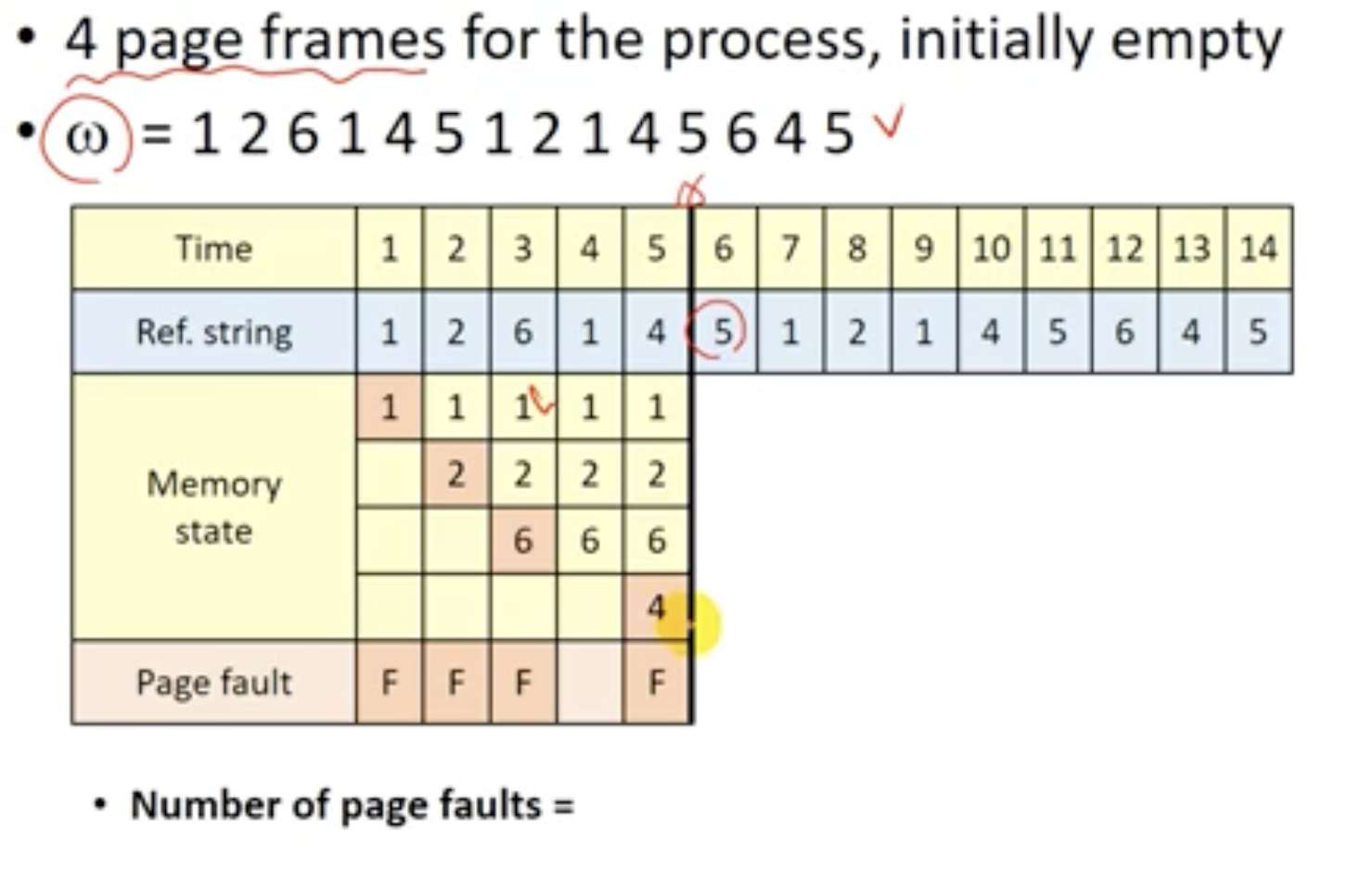
- reference string을 알고 있다고 가정한다.
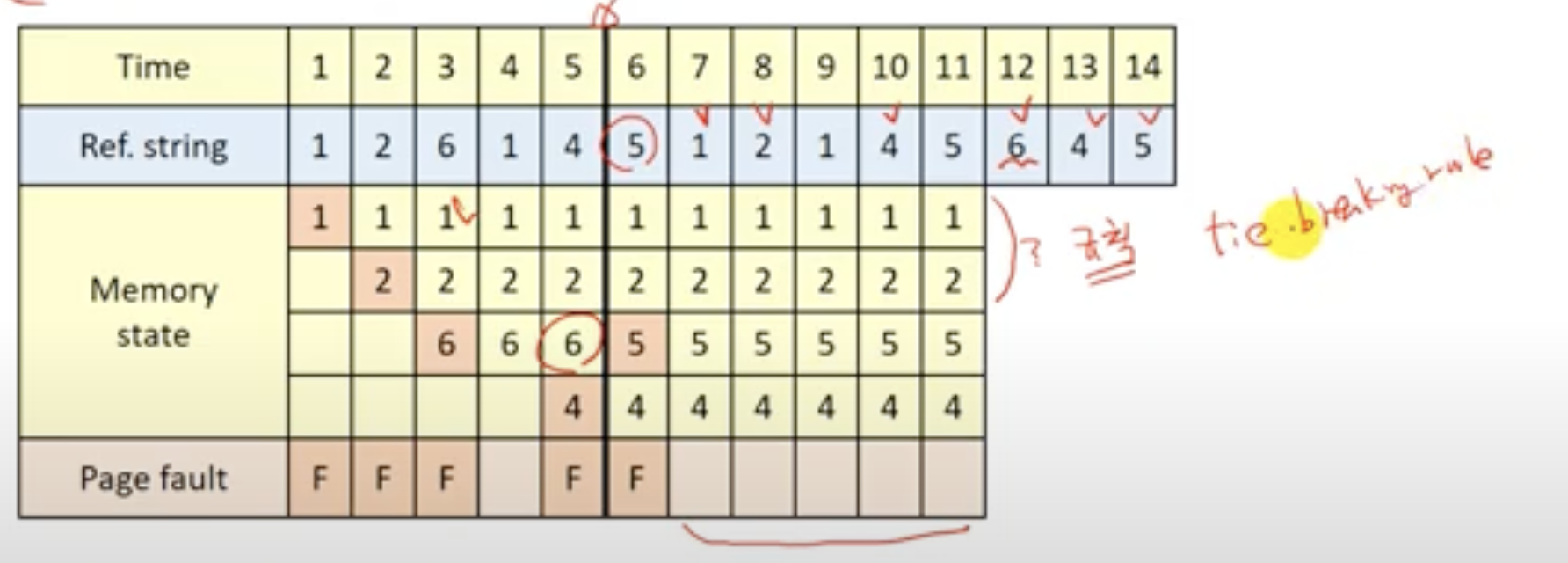
- tie-breaking-rule
- 위와 같이 1, 2 둘 다 빠져도 되는 tie 상황이 왔을 때(동점 상황), 필요한 규칙이 tie-breaking-rule이다.
- 위에서는 번호가 작은 페이지를 뺀다고 가정한다.
- 최종
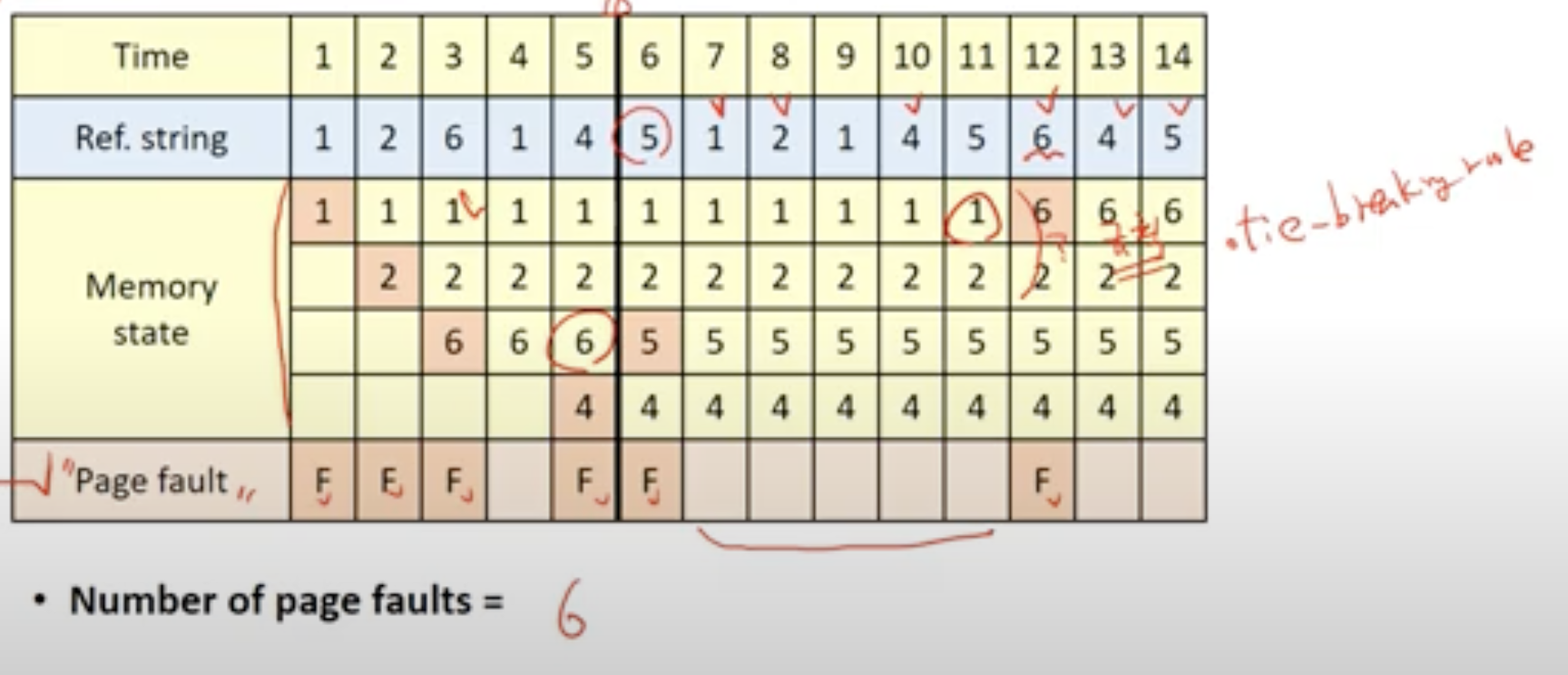
- reference string을 알고 있다고 가정한다.
Randon Algorithm
- 무작위로 교체할 page를 선택해 바꾼다.
- low overhead
- no policy
- 알고리즘을 만들어 평가해봤더니, 랜덤 방식보다 안 좋더라. -> 또다른 성능 평가의 기준으로 사용할 수 있다.
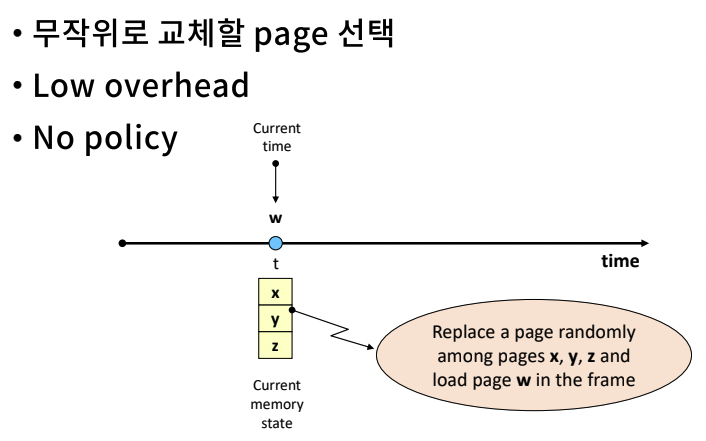
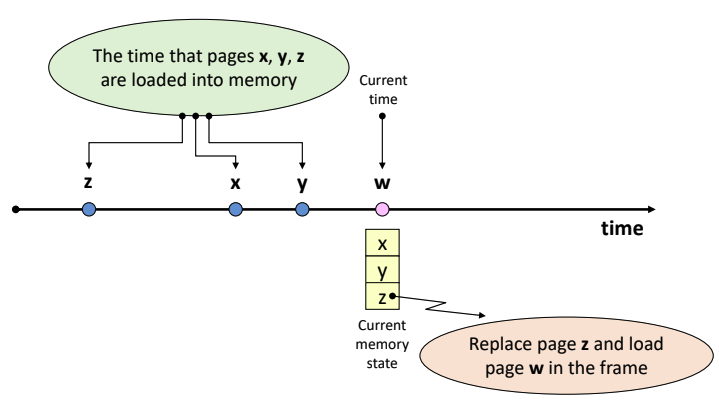
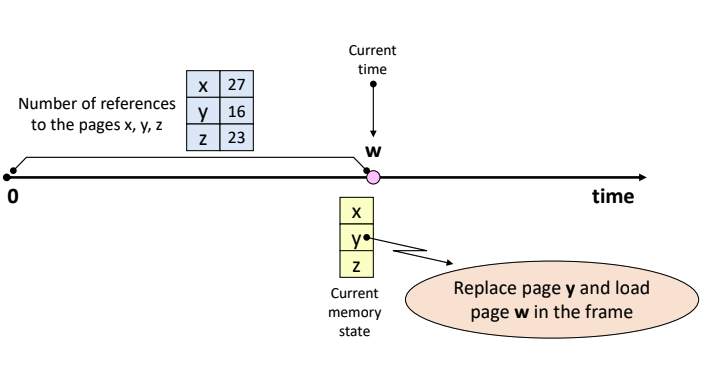
- x, y, z 중 아무거나 선택하여 w와 바꾼다.
FIFO Algorithm
- 먼저 들어온 것을(오래된 페이지를) 먼저 내보내자.
- First In First Out
- 가장 오래된 page를 교체한다.
- page가 적재된 시간을 기억하고 있어야 한다.
- 자주 사용되는 page가 교체 될 가능성이 높다.
- Locality에 대한 고려가 없다.
- 맨 처음 적재된 페이지가 가장 중요한 페이지일 수 있음에도 불구하고, 가장 먼저 들어왔다는 시간적인 이유로 교체되게 된다.
- FIFO anomaly(이상한 것)
- FIFO 알고리즘의 경우, 더 많은 page frame을 할당 받음에도 불구하고 page fault 수가 증가할 수 있다.
- FIFO 알고리즘의 경우, 더 많은 page frame을 할당 받음에도 불구하고 page fault 수가 증가할 수 있다.
- 가장 먼저 들어온 z를 교체해준다.
- 6번째에서 1번을 내보냈는데, 7번째에서 1번을 다시 들여오게 된다. 즉 1번은 자주 사용되는데 먼저 들어왔다는 이유로 쫓겨났다가 다시 들어올 때 불필요한 page fault가 발생한다.
- 8번째에서의 2번도 마찬가지이다. 13번째 4도 마찬가지이다. 방금 내보냈는데 또 들어오게 된다.
- Locality를 고려하지 않아 아쉬운 상황이 많이 발생한다.
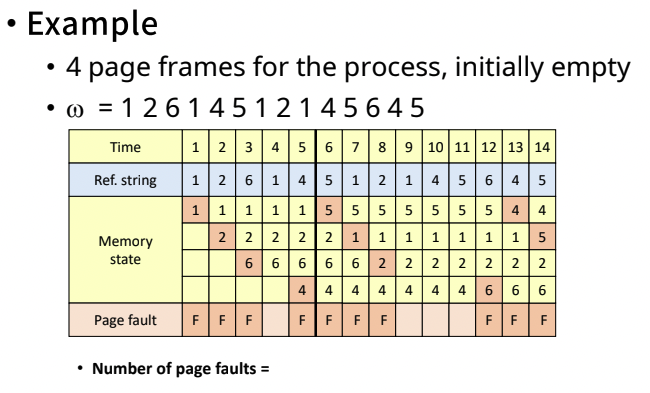
- page fault가 10번 발생했다.(최적 알고리즘인 MIN에서는 6번 발생했었다)
- 이러한 점을 보완하기 위해 page frame을 더 주자는 전략을 선택할 수도 있다.
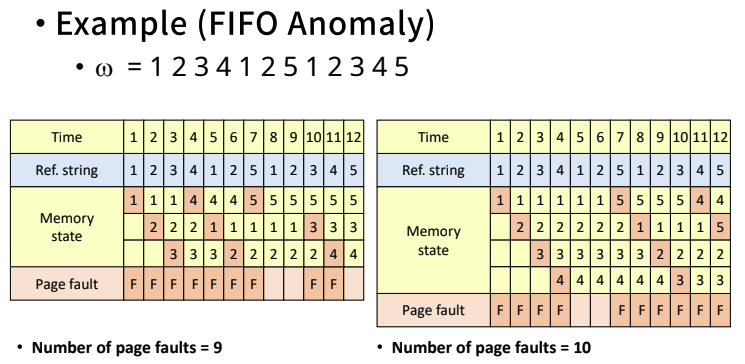
- 하지만 오히려 page fault가 9에서 10으로 늘어났다. page frame을 더 주었는데도 불구하고 page fault가 더 많이 발생했다.
Locality를 활용하는 알고리즘들
LRU (Least Recently Used) Algorithm
- 가장 오랫동안 참조되지 않은(적재가 아니라 참조) page를 교체한다.
- page를 참조할 때마다 시간을 기록해야 한다는 overhead가 발생한다.
- Locality에 기반을 둔 교체 기법이다.
- MIN 알고리즘에 근접하는 좋은 성능을 보여준다.
- 따라서 실제로 가장 많이 활용되는 기법이다.
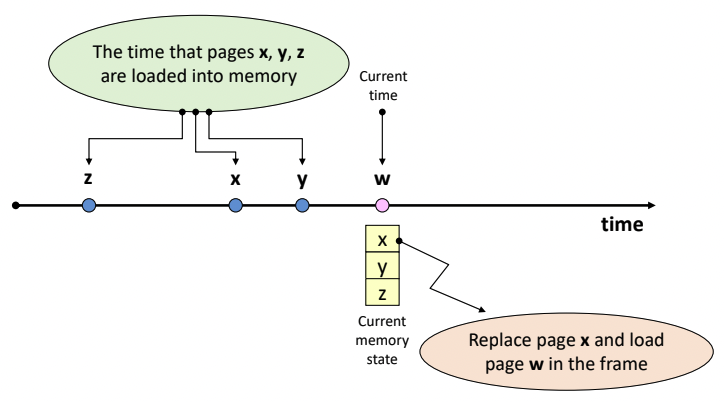
- z, x, y 순으로 메모리에 적재되었고, x가 참조된지 가장 오래된 page라면 x를 교체한다.
- 단점
- 참조 시 시간을 기록해야 하는 overhead가 발생한다.
- 간소화된 정보 수집으로 해소가 어느정도 가능하다.
- ex. 정확한 시간 대신, 순서만 기록한다.
- 간소화된 정보 수집으로 해소가 어느정도 가능하다.
- Loop 실행 시(for, while 문) 필요한 크기보다 작은 수의 page frame이 할당된 경우, page fault의 수가 급격히 증가한다.
- ex. loop 1번을 위한 page 갯수가 4개(1, 2, 3, 4)인데 할당받을 수 있는 page frame이 3개라면
- 처음엔 1, 2, 3이 올라갔다가 4가 들어갈 때 참조한지 가장 오래된 1이 교체된다. 그러면 4, 2, 3이 된 상태에서 1이 들어오게 되는데 이 때는 2가 교체되어 4, 1, 3이 된다. 이제 2가 들어가는데 3이 교체되어 4, 1, 2가 된다. 그 다음 3이 들어갈 때 4가 교체되어 3, 1, 2가 된다. 그 다음 4가 들어가 3, 4, 2가 된다. 이러한 경우 계속해서 page fault가 발생하게 된다.
- 참조 시 시간을 기록해야 하는 overhead가 발생한다.
- page fault가 7번 발생한다. MIN 알고리즘이 6번 발생한 것을 생각해보면 성능이 꽤 괜찮다는 것을 알 수 있다.
Locality를 활용하는 알고리즘들
LFU (Least Frequently Used) Algorithm
-
가장 참조 횟수가 적은 page를 교체하겠다는 알고리즘이다.
-
page 참조 시 마다 참조 횟수를 누적 시켜야 한다.
-
Locality 활용
- 시간을 기록해야 하는 LRU 대비 적은 overhead가 발생한다.(++만 해주면 된다)
- 적은 것을 빼고, 자주 참조하는 것을 넣는다는 것은, 앞으로 참조할 확률이 높다는 것이다.
-
단점
- 참조될 가능성이 높은 page가 교체 될 가능성이 있다.
- ex. 방금 들어왔는데, 1번 기록되었다고 바로 교체될 수도 있다.
- 참조 횟수를 누적해야 한다는 overhead는 발생한다.
-
위 상황에서는 y를 교체할 것이다.
-
Example
- 2, 6, 4 중 1개를 빼야 한다.
- Tie breaking Rule이 필요하다.
- 가장 먼저 들어온 친구를 빼자고 치면 2번이 빠질 것이다.
- page fault는 총 7번이다.
- locality 기반이라서 성능이 괜찮다.
Locality를 활용하는 알고리즘들
NUR(Not Used Recently) 알고리즘
-
LRU, LFU에서는 시간이나 순서, 횟수를 기록했어야 됐다.
-
LRU approximation scheme
- LRU보다 적은 overhead로 비슷한 성능을 달성하기 위한 목적이다.(간략하게 해보자)
- 최근 사용되었는지 안되었는지만 체크해보자.
-
Bit vector 사용
-
Reference bit vector (r) : 프레임의 페이지가 참조되면 1이 된다. 즉 최근에 참조되었다는 의미이다.
- 주기적인 시간에 0으로 초기화된다.
- 어느 시간 대에 이것이 최근에 참조되었는지 추상적으로 알 수 있다.
-
Update bit vector (m) : 내용이 바뀌면 1로 바뀐다.
-
-
교체 순서

- 새로운 것이 들어온다고 가정하면,
- 3, 4는 reference bit가 1이라서 안 바꾸는 것이 좋을 듯 하다.
- 1, 2, 중 2는 write가 일어났다.(m이 1이다)
- 따라서 메모리에서 나올 때 m은 0이 되고, 디스크에 내용을 반영해주는 write-back을 해줘야 한다.
- 추가적인 overhead가 발생하므로 1을 바꿔주는 것이 가장 overhead가 적다.
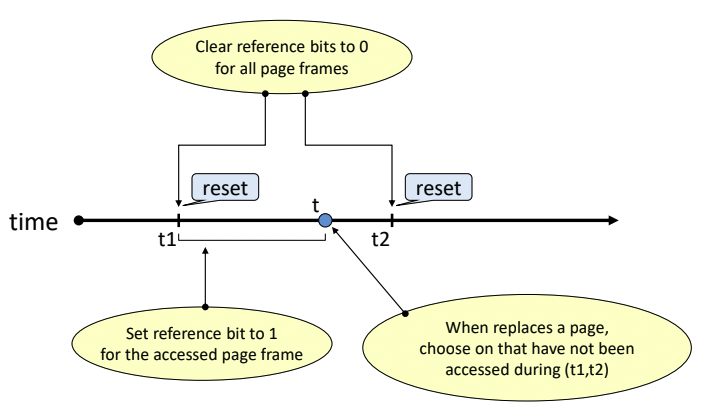
- t1, t2에 주기적으로 reference bit가 0으로 초기화된다.
Locality를 활용하는 알고리즘들
Clock Algorithm
- 이 NUR을 실제로 적용한 예가 IBM VM/370 OS이다.
- reference bit만 사용한다.
- 주기적으로 reference bit가 0이 되지 않는다.
- page frame들을 순차적으로 가리키는 pointer(시계 바늘)를 사용하여 교체될 page를 결정한다.
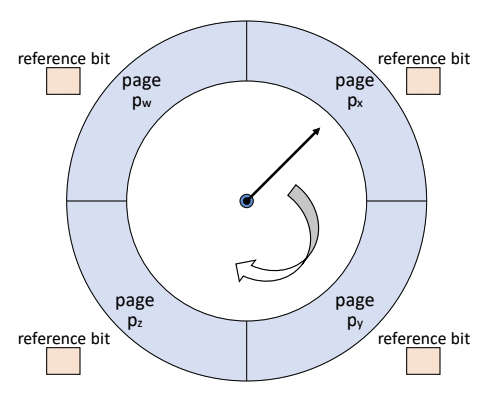
- reference bit가 모두 1이 되었을 때, 그러면 swap out이 일어나지 않고 계속해서 돌 것이다.
- 그런 것이 아니라 만약 Px가 맨 처음이라고 가정하고 reference bit가 모두 1이라면,
- Px를 지나가면서 Px의 reference bit를 0으로 만든다.
- 그러면 나중에 Px에 오면 0이 되어 있으므로 Px가 내려가게 된다.
- Pointer를 돌리면서 교체할 page frame을 결정한다.
- 현재 가리키고 있는 page의 reference bit (r)을 확인한다.
- r = 0인 경우, 교체 page로 결정한다.
- r = 1인 경우, reference bit를 0으로 초기화 후 pointer를 이동한다.
- 먼저 적재된 page가 교체될 가능성이 높다. (위의 예시를 생각해보자)
- FIFO와 유사하다.
- reference bit를 사용해 교체 페이지를 결정한다.
- LRU, NUR과 유사하다.(Locality 반영)
- Example
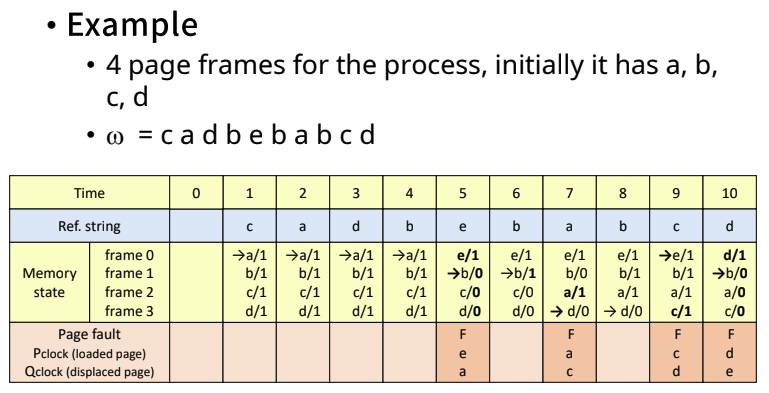
- Pclock은 들어온 페이지
- Qclock은 나간 페이지
Locality를 활용하는 알고리즘들
Second Chance 알고리즘
-
Clock Algorithm (r만 확인)과 유사하다.
-
reference bit만 봤지만, 이제는 update bit도 보겠다. 1번 더 기회를 주겠다.
-
Update bit (m)도 함께 고려한다.
- 현재 가리키고 있는 page의 (r, m) 확인
- reference bit가 1인 page는 0으로 바꿔주고 지나간다.
- update bit가 1인 page는 가리킬 때는 지나갈 때 0으로 바꾸고 write-back (cleaning) list에 삽입한다.
- 1순위 (0, 0)
- 2순위 (0, 1)
- 3순위 (1, 0)
- 4순위 (1, 1)

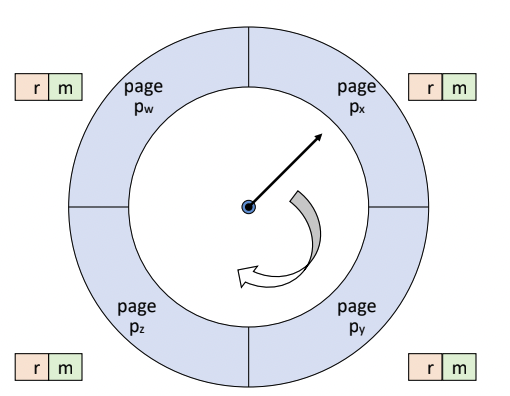
- 현재 가리키고 있는 page의 (r, m) 확인
-
Example

다른 알고리즘들

- reference, update bit말고 다른 bit가 있을 수 있다.
- 가장 오래 전에 참조한 것을 바꾸는 것이 아니라(LRU) 가장 최근에 참조하는 것을 바꾼다.(MRU)
- 가장 적게 참조한 것을 바꾸는 것이 아니라(LFU) 가장 많이 참조한 것을 바꾼다.(MFU)
Replacements Strategies - Variable Allocation
- 프로그램에게 할당해주는 프레임의 수가 가변된다.(Fixed에서는 고정되어 있었다)
Working Set (ws) 알고리즘

- 지금 일할 때 필요한 집합
- process가 특정 시점에 자주 참조하는 page들의 집합
- Locality가 포함되어 있다.
- 최근 일정시간 동안(델타) 참조된 page들의 집합
- 시간에 따라 변한다.
- []는 t - 델타, t를 포함한 범위이고 ()는 t - 델타, t를 포함하지 않는 범위이다.
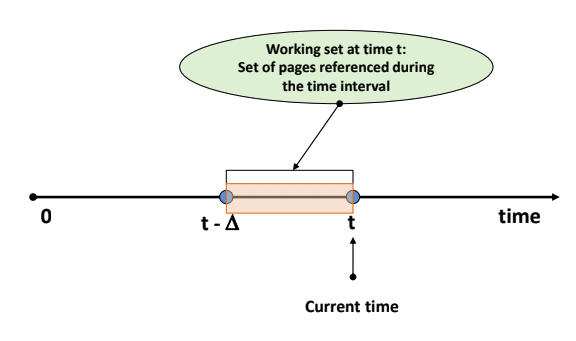
- 주황색으로 색칠한 것이 window로, 우리가 참조하게 되는 영역이라는 뜻이다.
- 최근에 참조한 페이지들을 보유하니 Locality가 반영된다.
- 이 페이지들을 메모리에 항상 유지한다.
- locality기반이니 page fault는 적어지고 시스템의 성능은 향상된다.
- window size는 고정되어 있다.
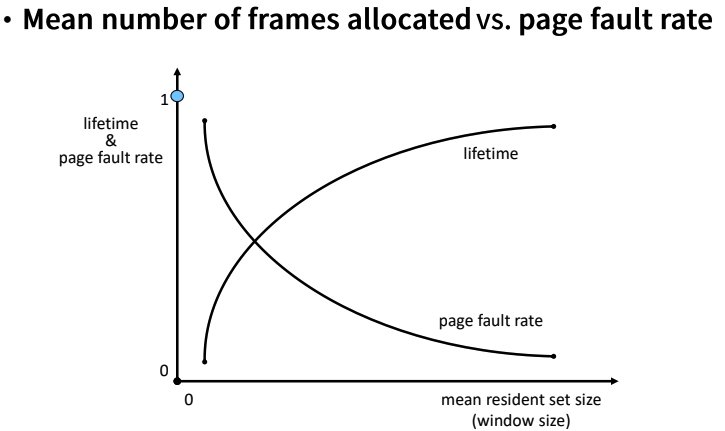
- Window size vs Working Set size
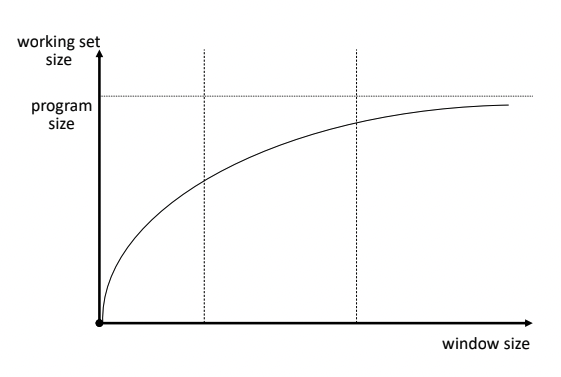
- 윈도우 사이즈가 늘어나면 더 큰 범위를 보게 되니 워킹셋 사이즈도 늘어나게 된다.
- 처음엔 워킹셋 사이즈가 급격히 늘어나나, 어느 수준이 되면 잘 늘어나지 않는 수준이 된다.
- Locality 기반이기 때문에, 어차피 자주 사용하는 페이지는 어느 정도 정해져 있다.
- 처음엔 급격히 늘어날 것이지만, 나중에 가면 자주 사용하는 페이지는 윈도우에 잘 들어오지 않으니 늘어나는 수준이 작아지게 된다.
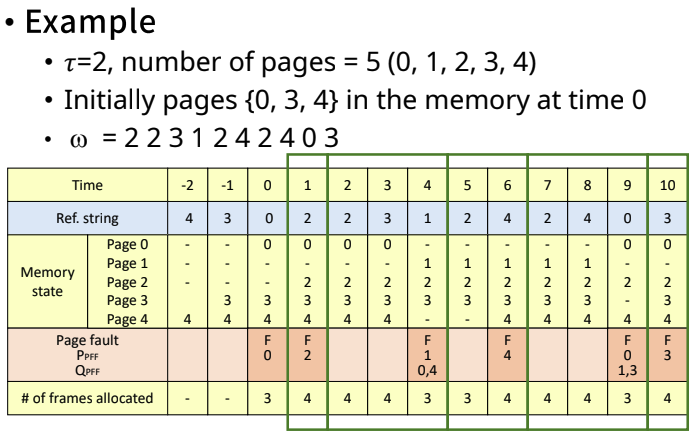
- Example 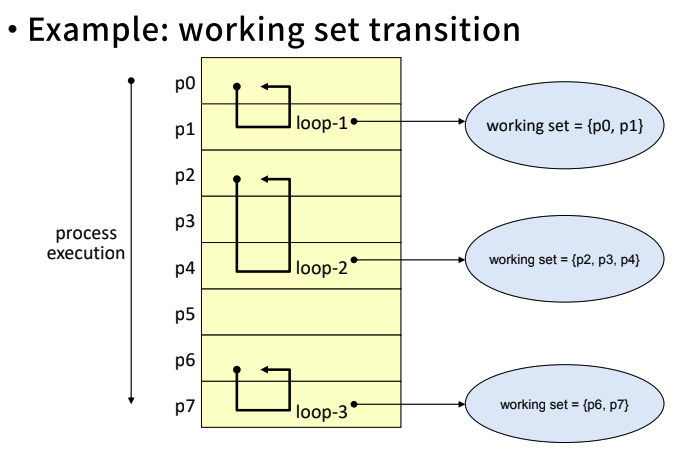
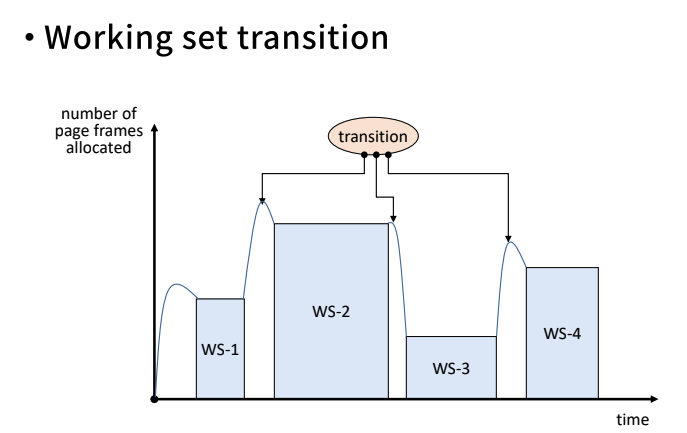

- 윈도우가 움직이고, 4초의 범위안의 Ref.string를 Memory state에서 유지하고 있으면 된다.
- 가지고 있는 frame의 수가 바뀌고 있다.
- page fault는 총 5번 났다.
-
성능 평가

-
여기서 평균 프레임 수는 위의 위의 그림에서 of frames allocated를 평균 낸 숫자이다.
-
page fault가 적게 날수록, 유지해야 하는 frame의 수가 적을수록 좋다.
-
특성
- 적재되는 page가 없더라도, 메모리를 반납하는 page가 있을 수 있다.(윈도우 안에 들어와야 하니까)
- 새로 적재되는 page가 있더라도, 교체해야 하는 page가 없을 수 있다.
-
단점
- 윈도우를 계속 움직이고 계속 보고 있어야 하기 때문에 이러한 점에서 overhead가 생긴다.
- Residence set(상주 집합, 워킹셋)을 page fault가 없더라도, 지속적으로 관리해줘야 한다.
-
윈도우의 사이즈가 커지면, 워킹셋의 프레임들이 더 길게 살아남을 수 있게 된다.
- 이 말은 page 유지 비용이 커지게 된다.
- 대신 많은 page를 담고 있기 때문에 page fault rate는 줄어들게 된다. (hit 확률이 높다)
Page Fault Frequency (PFF) 알고리즘

- 워킹셋은 페이지 폴트가 없어도 Resident set(워킹셋)관리를 했어야 했다. 하지만 이 알고리즘은 페이지 폴트가 나면 관리를 하자는 것이다.
- page fault가 얼마나 자주 나는지에 따라 frame을 얼마나 유지할 지 결정하겠다는 알고리즘.
- Low page fault rate
- 유지하는 frame의 갯수를 줄여도 된다.
- High page fault rate
- 유지하는 frame의 갯수를 늘려줘야 한다.
- Low page fault rate
- page fault가 얼마나 자주 나는지에 따라 frame을 얼마나 유지할 지 결정하겠다는 알고리즘.
- page fault가 발생할 때에만 워킹셋 갱신을 수행하기 때문에 overhead가 상대적으로 이전의 알고리즘보다 적다.

-
그 page fault가 일어나는 빈도를 알아야 한다.
-
inter-fault time
- page fault가 일어나는 사이의 시간
- long이면 긴 주기로 page fault가 일어난다.(page fault가 잘 안 난다)
- short이면 짧게 page fault가 일어난다.
-
이러한 IFT가 정해진 값인 타우보다 크다면, 주기가 길다는 것으로 판단하여 low page fault rate로 인식한다.
-
반면 작다면, page fault 주기가 짧아 page fault가 자주 일어나게 되는 셈으로 high page fault rate로 인식한다.
-
타우는 우리가, 시스템이 정해줘야 한다.
-
IFT가 짧으면 유지하는 frame의 갯수를 늘려줄 것이다.
-
알고리즘

-
Example
- page fault가 일어날 때, 그 일어난 간격과 타우를 비교해 low인지 high인지 판별한다.
- low이면 (tc - t(c-1)]로 윈도우 범위를 줄인다.
- high이면 프레임을 윈도우에 추가로 적재한다.
-
성능 평가

- page fault에 대한 성능은 3.2인 그냥 워킹셋 알고리즘보다 안 좋지만
- 메모리 유지 상태 변화가 page fault 발생 시에만 일어나서 overhead가 적다.
Variable MIN (VMIN) 알고리즘

- 실현 불가능하지만 성능 평가의 지표가 될 수 있다.

- Example

- 처음 1 ~ 4
- (t, t + 델타]이므로 0은 포함되지 않는다.
- 3은 이 사이에 참조가 되기 때문에 유지된다.
- 4 ~ 7
- 1 2 4 2 참조 스트링으로 3은 보지 않기 때문에 내려가게 된다.
- 미래를 보고 판단하기 때문에 실현 불가능하다.
- 유지해야 하는 프레임의 갯수는 전체적인 시간대에서 적다는 것을 알 수 있다.
- 성능 평가

- 최적의 델타 값

- frame을 유지하는 비용이, page fault를 처리하는 비용보다 적다면 윈도우를 늘려 상대적으로 비용이 큰 page fault를 적게 일어나게 하는 것이 좋다.
- 반면 frame을 유지하는 비용이, page fault를 처리하는 비용보다 크다면 그냥 page fault를 일어나게 하는 것이 낫다. 따라서 윈도우를 줄인다.
가상 메모리 관리
Other Considerations

Page Size

- small page size
- page를 관리하기 위한 테이블이 커진다. 커널이 테이블을 관리하는 overhead가 커지게 된다.
- page 수가 적다보니 page를 여러개 올려야 하니 I/O 시간이 증가하게 된다.
- 상대적으로 큰 page size에 비해 필요한 것만 올라오다보니 hit하는, locality가 향상될 수 있다.
- 큰 page size는 필요 없는 데이터를 많이 담고 있는 page일 수 있기 때문에 locality가 저하된다.
- page들이 자주 교체되므로 page fault가 자주 일어나게 된다.
- 현대에는 점점 page 사이즈가 커진다.
- memory 사이즈도 커지기 때문이다. page 사이즈가 그대로 작으면 이를 처리하는 kernel의 부담이 커지게 된다.
- I/O 작업에서 1번만 가져오면 될 것을 여러번 가져와야 되게 되면 bottle neck 현상이 벌어질 수 있다.
- 현대에는 disk보다 cpu의 발전속도가 더 빠르다. 서로의 갭이 커지고 있다.
- cpu는 빠른 반면 디스크가 빨리 처리하지 못하면 bottle neck이 된다.
- 한 큰 페이지를 CPU가 빠르게 읽는 것이 낫기 때문에, 1번에 디스크에 내리고 올릴 수 있도록 크게 하는 것이 낫다. cpu가 더 빠르게 발전하기 때문에 page size도 그에 맞게 늘려주는 것이 좋다.
Program Restructuring

-
가상 메모리 시스템의 특성에 맞도록 프로그램을 재구성하면, 프로그램을 효율적으로 더 빠르게 동작하도록 만들 수 있다.
-
Example
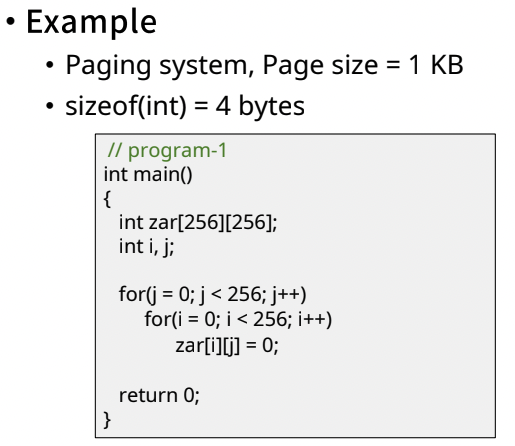
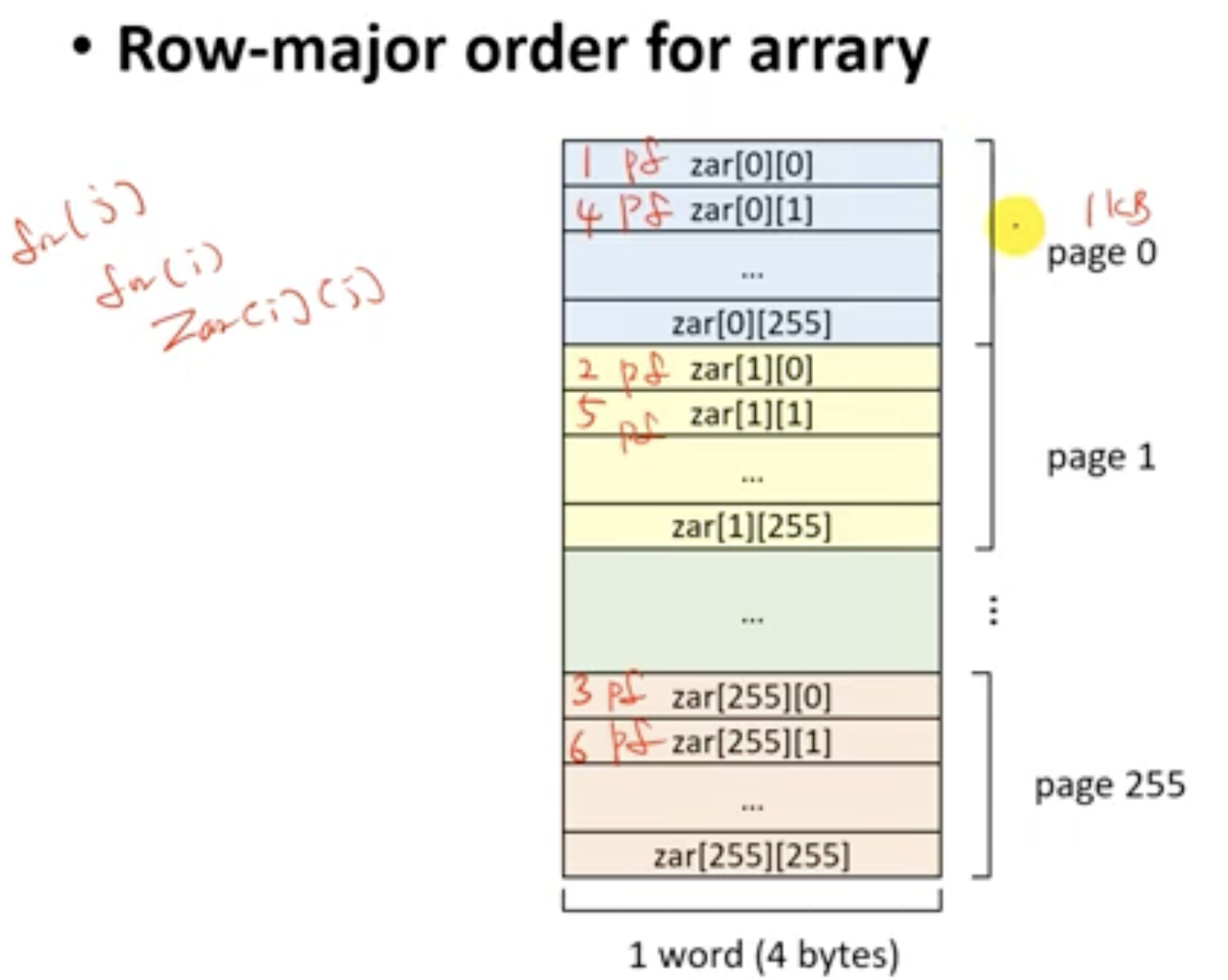
- 위의 예에서는 page fault가 계속해서 나게 된다.
- 첫 번째 for문은 i, 두 번째 for문은 j로 바꾼다.
TLB Reach

- TLB : Translation Lookaside Buffer
- TLB를 통해 접근할 수 있는 메모리의 양을 의미한다. 어디까지의 메모리에 도달할 수 있는지.
- TLB는 여러 개의 엔트리가 있고 각각의 엔트리가 페이지를 가르키고 있다.
- TLB의 hit ratio를 높이려면
- TLB의 크기를 증가시키면 되지만 비용이 비싸진다.
- page의 크기를 증가시킨다.(TLB는 엔트리만, 즉 페이지를 가르키는 주소만 저장하고 있을 것이다. 따라서 page 크기가 커져도, 주소만 가지고 있는 TLB는 커지지 않는다)
- 하지만 그냥 늘리는 것이 좋은 건 아니기 때문에, OS단에서 page size를 다르게 할 수 있게 해준다.
