Disk System
Disk System
-
파일은 디스크에 저장된다.
-
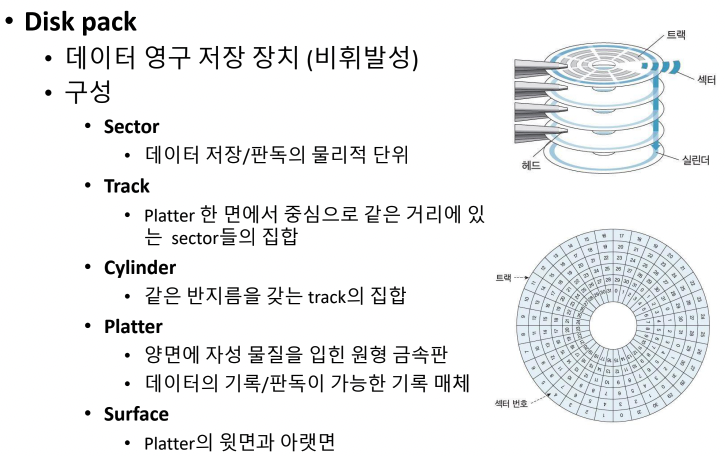
Disk Pack
- 데이터 영구 저장 장치(비휘발성)
- 구성
- cylinder > track > sector
- 한 칸들이 sector, sector가 모인 것이 track, 이 track들이 모인 것이 cylinder
- platter는 그냥 원형 금속판
- surface는 platter의 윗면, 아랫면을 지칭할 때 쓴다.
-
Disk Drive
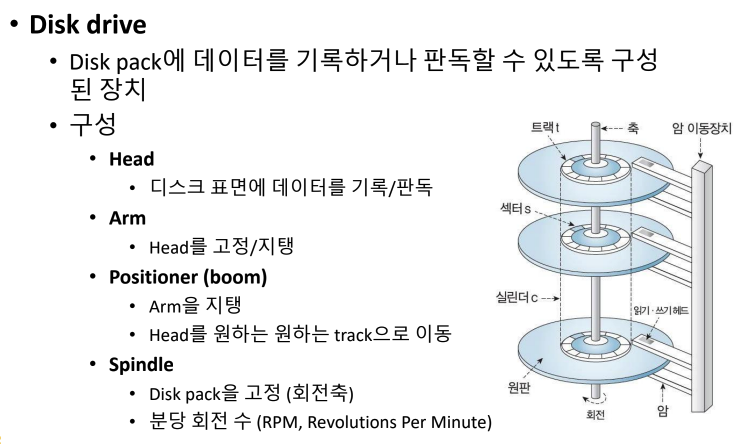
- Disk Pack에 데이터를 기록하거나 판독할 수 있도록 구성된 장치이다.
- Head : track의 정보를 읽는 역할을 한다.
- Arm : head를 잡고 있는다.
- Positioner(boom) : arm들을 잡고 있는다.
- Spindle : 원하는 면을 돌려서 head에 오게 만든다. Disk pack을 돌리는 회전축이다.
- RPM이 높으면 정보를 더 빨리 읽을 수 있다.(분당 몇 바퀴 도느냐)
Disk Address
- 몇 번째 실린더인지, 어떤 surface인지, 어떤 sector인가를 알아야 원하는 sector를 가서 정보를 읽어올 수 있다.
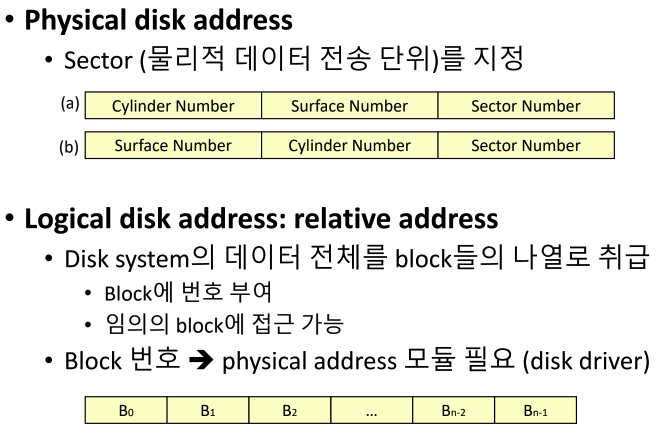
- 하지만 하드 디스크의 제품이 회사마다 다르고 용량도 다르기 때문에 OS는 이를 아우를 수 있도록, 더 추상화된 개념이 필요하다. 따라서 OS는 섹터 단위의 주소를 요청하는 것이 아니라, 그저 block 단위로 요청한다.
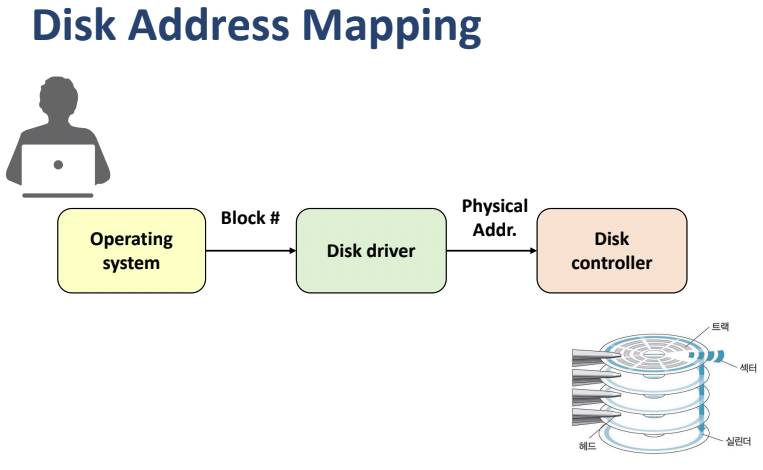
- 그렇기 때문에 OS가 block으로 요청을 하면 결국엔 sector 주소의 데이터가 읽혀야 한다.
- 이를 disk driver가 해결해준다. block 주소를 sector 주소로 바꿔준다.
- 이 disk driver는 disk를 가장 잘 아는, 그 disk를 만든 제조사에서 제공해준다.
Data Access in Disk System

- 원하는 데이터에 직접 접근하는 과정
- seek time : 디스크의 head를 필요한 cylinder로 이동하는 시간
- Rotational delay : seek time 뒤에, 필요한 sector로 head를 가져다 놓는 데에 걸리는 시간
- Data transmission time : Rotational delay, 해당 sector에 데이터를 쓰거나 읽는 데에 걸리는 시간

파일 시스템 개요
-
사용자들이 사용하는 파일들을 관리하는 운영체제의 한 부분
-
파일 시스템의 구성
- 파일 : 연관된 정보의 집합
- 디렉토리 구조 : 시스템 내 파일들의 정보를 구성 및 제공
- 파티션 : 디렉토리들의 집합을 논리적/물리적으로 구분
Access Methods

- 순차 접근
- 카세트 테이프에서, 처음 곡을 다시 듣고 싶으면 맨 처음으로 돌아가야 한다.
- a를 보고 c를 보고 싶으면 b를 꼭 접근해야 한다.
- 직접 접근
- a를 본 다음 c를 보려면 b를 건너뛸 수 있다.
File Concept

-
보조 기억 장치에 저장된 연관된 정보들의 집합
- 보조 기억 장치 할당의 최소 단위
- sequence of bytes, 결국 바이트들로 이루어져 있다.
-
내용에 따른 분류
- 프로그램 파일
- 데이터 파일
-
형태에 따른 분류
- text file : 문자로 이루어진 파일
- binary file : 0, 1로 이루어져 있다.
File Concept
-
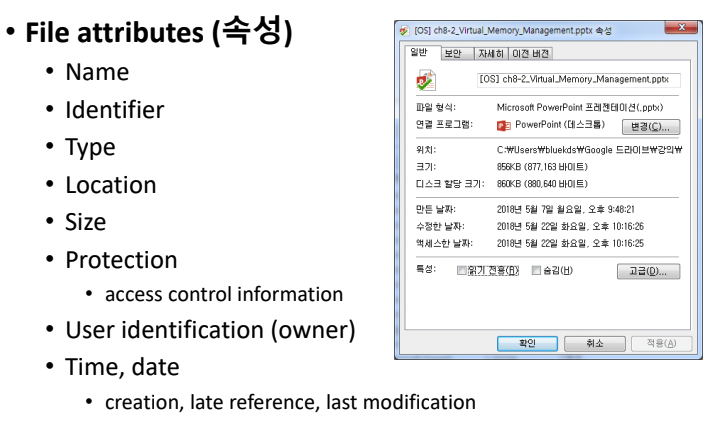
File attributes(속성)
- Name
- Identifier
- Type ex) .c, .exe
- Location
- Size
- Protection : access control information
- User identification(owner)
- Time, date : creation, late reference, last modification
-
File operations
- open : 그 파일의 메타 데이터가 물리 메모리로 올라오게 된다.
- create
- write
- read
- reposition, 옮길 수 있다.
- delete
- OS는 system call을 통해 file operations을 수행할 수 있어야 한다.
File Access Methods
-
sequential access (순차 접근)
- File을 recode(or bytes) 단위로 순서대로 접근
- ex. fgetc(), 한 바이트씩 읽어온다.
- File을 recode(or bytes) 단위로 순서대로 접근
-
Directed access (직접 접근)
- 원하는 block을 직접 접근한다.
- ex. lseek(), seek()
- 원하는 block을 직접 접근한다.
-
Indexed access
- index를 참조하여 원하는 block을 찾은 후 데이터에 접근한다.
- ex. c에서 배열의 index를 통해 바로 찾는 경우.
- index를 참조하여 원하는 block을 찾은 후 데이터에 접근한다.
File System Organization
-
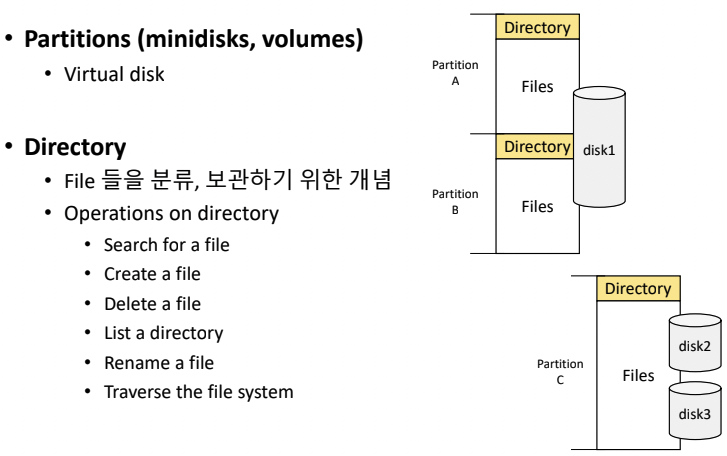
Partitions
- C 드라이브, D 드라이브처럼(파티션) disk를 나누는 것이다.
- 2개의 드라이브 등을 하나의 파티션으로 묶기도 한다.
- virtual disk
-
Directory(folder)
- File들을 분류하고 보관하기 위한 개념이다.
- operations on directory
- search for a file
- create a file
- delete a file
- list a directory(ls 커맨드로 디렉토리 안에 뭐가 들어있는지 확인이 가능하다)
- rename a file
- traverse the file system(파일 시스템 전체를 탐색 가능하다)
- OS는 system call을 동해 위와 같은 operations를 수행할 수 있어야 한다.
-
Mounting
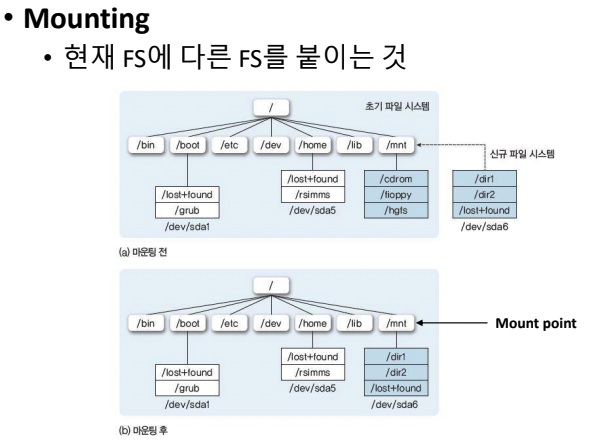
- 현재 파일 시스템에 다른 파일 시스템을 붙이는 것이다.
- 그 붙이는 곳을 mount point라고 한다.
디렉토리 구조
Flat Directory Structure
- 파일 시스템 내에 하나의 Directory만 존재한다.
- Issues
- File naming : 한 디렉토리 안에 모든 파일이 존재하기 때문에 파일들의 이름을 겹치게 하면 안된다.
- File protection : 이름이 같아 덮어씌워지게 되면 원래 파일이 지워져 보호의 이슈가 있다.
- File management : 파일들을 구분지어 관리하기 어려워진다.
- 이러한 이슈들은 다중 사용자 환경에서 문제가 더욱 커지게 된다.
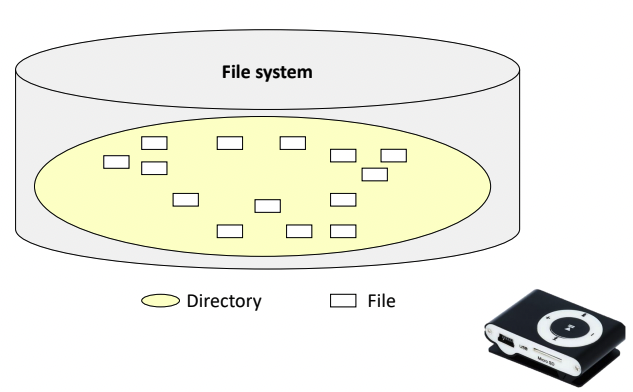
- 초창기 MP3가 그 예이다. 디렉토리가 따로 없이 기기에 그냥 음악을 넣는다는 개념이었다. 즉 MP3 자체가 디렉토리였다고 생각하면 된다. 그 안에 디렉토리는 따로 없었다.
2-Level Directory Structure

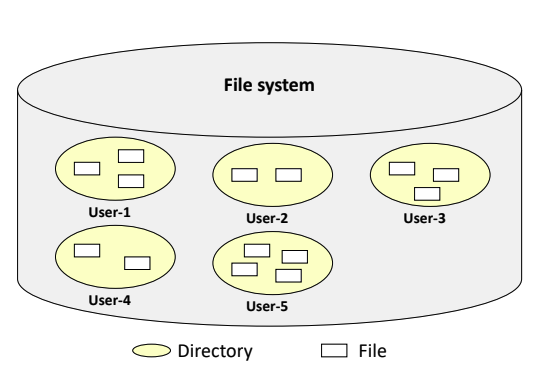
- user 1이 A라는 파일을 user 2에게 보여주고 싶으면, user 1의 모든 파일을 보여줘야 한다는 보안의 이슈가 생길 수 있다.
Hierarchical Directory Structure

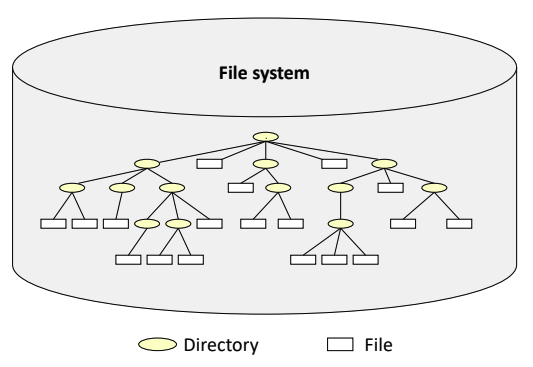
Acyclic Graph Directory Structure

-
Acyclic : 원형이 될 수 없는, 루프가 만들어질 수 없는
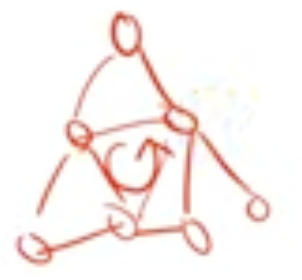
- 위 그림은 루프가 만들어진 모습이다.
-
Link
- 위의 그림에서 /tmp/three가 /two/one/two로 이어지는 것이 링크이다. 바로가기라고 생각하면 된다.
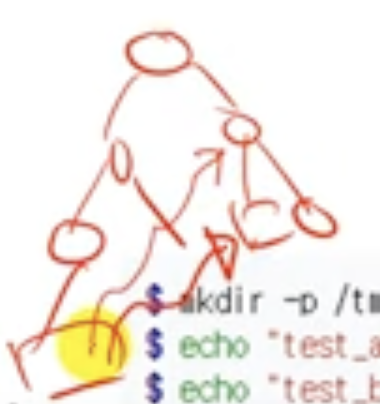
- 위의 그림에서 /tmp/three가 /two/one/two로 이어지는 것이 링크이다. 바로가기라고 생각하면 된다.
-
Acyclic Graph Directory Structure
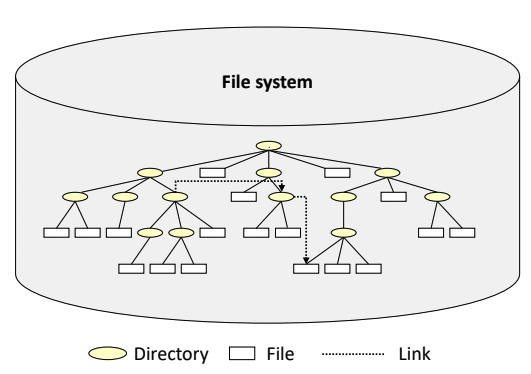
- 어떤 폴더로 바로가는 것을 만들 수 있다.
- Acyclic
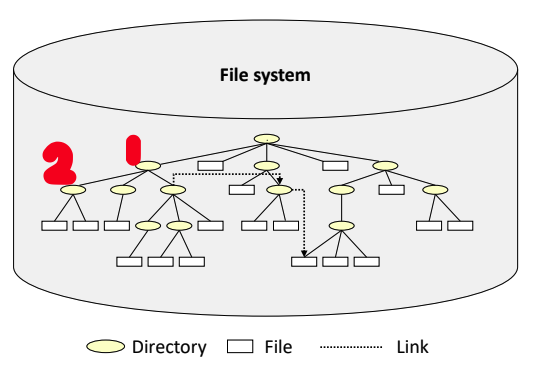
- 2에서 1로 바로가는 것을 만들게 되면 다시 2로 갈 수 있다.
- 이 예는 좀 애매하지만, 만약 루프가 만들어진다면 링크로 연결된 폴더로 이동했더라도 다시 자신으로 돌아갈 수 있게 되는데 이러한 경우를 안 만들게 하는 것이 Acyclic Graph Directory Structure이다. 위의 그림에서는 그러한 경우가 생기지 않는다.
- 만약 A에서 B로 가게 링크(바로가기)를 만들었고, B에서도 A로 바로 갈수 있게 만들었다면 이는 루프가 생긴 경우이다.
General Graph Directory Structure

- 루프, 즉 다시 위로 올라가는 것도 허용하겠다는 구조이다.
- 무한 루프에 들어가지 않도록 조치를 취해줘야 한다.
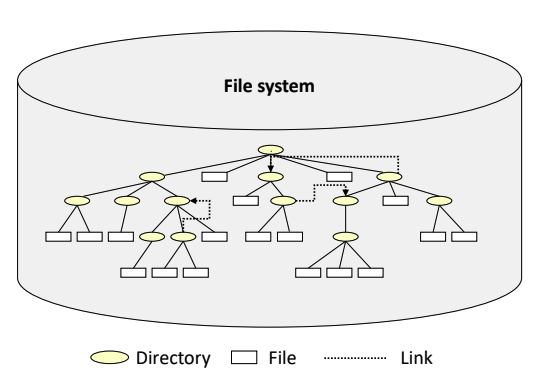
파일 보호
File Protection
- file에 대한 부적절한 접근 방지
- 다중 사용자 시스템에서 더욱 필요하다.
- 접근 제어가 필요한 연산들
- read
- write
- execute
- append
File Protection Mechanism
-
파일 보호 기법은 system size 및 응용 분야에 따라 다를 수 있다.
-
password 기법
- 각 file들에 대해 password를 부여한다.
- 비현실적
- 사용자들이 파일 각각에 대한 password를 기억해야 한다.
- 접근 권한 별로 서로 다른 password를 부여해야 한다.
- ex. read는 그냥 할 수 있게, write는 password가 필요하도록.
- 복잡해지고 불편해진다.
- ex. read는 그냥 할 수 있게, write는 password가 필요하도록.
- 중요한 파일에는 사용하는 경우도 있다.
-
Access Matrix 기법

- 접근 행렬, 2차원 표
- 접근 권한을 2차원 표에 적어두는 기법이다.
- 범위(domain)와 개체(object)사이의 접근 권한을 명시.
- domain : user group, 사용자
- object : file, 파일
- 파일마다 사용자 또는 사용자 그룹의 접근 권한을 적어두는 것이다.
- Access right
- <object-name, rights-set>
- 어떤 object에 대해 그 domain이 가진 권한.
-
Example
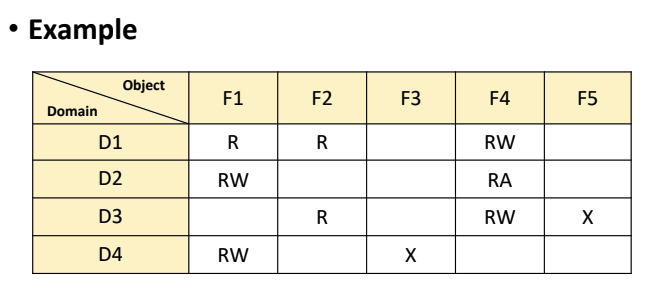
-
파일에 관한 도메인의 권한들이 적혀지게 된다.
Global Table
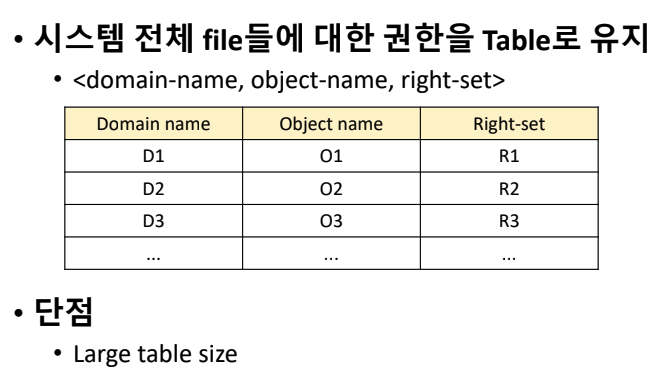
- access matrix를 통째로 저장한다.
- 시스템 전체 file들에 대한 권한을 table로 유지한다.
- 단점
- 빈 공간에 대한 것들도 저장하기 때문에 table의 사이즈가 커진다.
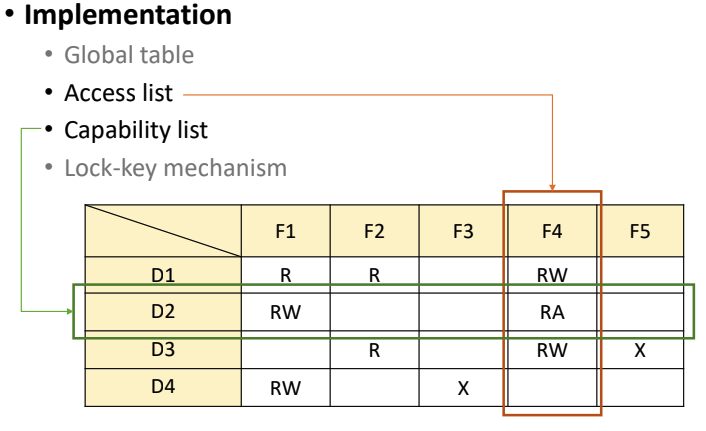
- access list는 column, 열 단위로 저장한다.
- capability list는 row, 행 단위로 저장한다.
Access List

- 만약 D3가 해당 object에 대해 아무런 권한이 없다면 list에 저장하지 않으면 된다.
- 따라서 저장 공간을 줄일 수 있게 된다.
- object 생성 시, 각 domain에 대한 권한을 부여한다.
- domain이 object에 접근하면 권한을 검사한다.
- ls -l을 해보면 각 파일들에 대한 권한을 알 수 있다.
- object에 domain이 access할 때마다, 권한을 확인해야하는 overhead가 발생한다.
- 뷔페에 들어갈 때 한 번 들어가면, 혹은 들어갈 권한이 있으면 도장을 줘서 그냥 들어가게 해준다.
- 이와 비슷한 것이 capability list이다.
Capability List

- 마찬가지로 어떤 파일에 대한 권한이 없으면 그냥 list에 저장을 안하면 되므로 저장 공간을 아낄 수 있다.
- 매번 권한 리스트를 봐야하는 overhead가 줄어들게 된다.
- 각 Domain이 file에 대한 접근 권한을 나열하여 가지고 있다.
- file에 접근할 때 이 배열 자체를 보여주면 되기 때문에, 배열 안에서 접근 권한을 매번 탐색할 필요가 없다.
- 신분증 느낌으로 생각하면 된다.
- capability list 자체를 보호해야 되기 때문에(보안 문제가 생긴다) kernel 안에 저장되고, 이를 보호하기 위한 overhead가 발생한다.
Lock-key Mechanism
- Access list와 Capability list를 혼합한 개념이다.
- object는 lock을, domain은 key를 가진다.(자물쇠 - 열쇠)
- domain 내 프로세스가 object에 접근 시, object와 key의 짝이 맞아야 한다.
- 이 key list들은 시스템(kernel)이 관리해야 하기에 overhead가 발생한다.
Comparison of Implementations
-
Global table
- 간단하지만, 다 저장하는 만큼 많은 메모리가 필요하다.
-
Access list
- object 별 권한 관리가 용이하다.
- 모든 접근마다(domain이 접근할 때) access list를 탐색해 권한을 가지고 있는지 봐야 한다.
- object에 자주 접근하게 되면 느리게 된다.
-
Capability list
- domain이 가진 리스트 자체를 그저 보여주면 되기 때문에 리스트 내의 object들에 대해 접근이 빠르다.
- object별 권한 관리가 어려워진다.
- file 1에 대해 read 권한을 할 수 없게 만들고 싶으면, 모든 domain의 capability list를 탐색해 그 access right set을 없애야 한다.

- 이 두 방법을 혼합하여 사용하는 OS가 많다.
- domain이 object에 대해 처음으로 접근할 때, access list를 탐색한다.
- 접근이 가능할 때에는 capability list를 생성 후 해당 domain에게 전달한다.
- 이후 접근은 권한 검사가 불필요해진다.
- 마지막 접근 후에는 그 domain의 capability list를 삭제한다.
- domain이 object에 대해 처음으로 접근할 때, access list를 탐색한다.
- 이렇게 하면 파일에 대한 권한을 수정해야 할 때, 그 파일의 access list 1개를 탐색해 수정하면 돼서 여러 list를 탐색할 필요가 없고(capability list만 사용하는 경우 domain 모두를 탐색해서 그 안의 access right set을 변경해줘야 했다), 동시에 capability list까지 있으니 domain이 object에 접근할 때 매번 탐색을 해야한다는 overhead가 줄어들게 된다.
파일 시스템 구현
Allocation of File Data in Disk

Contiguous Allocation
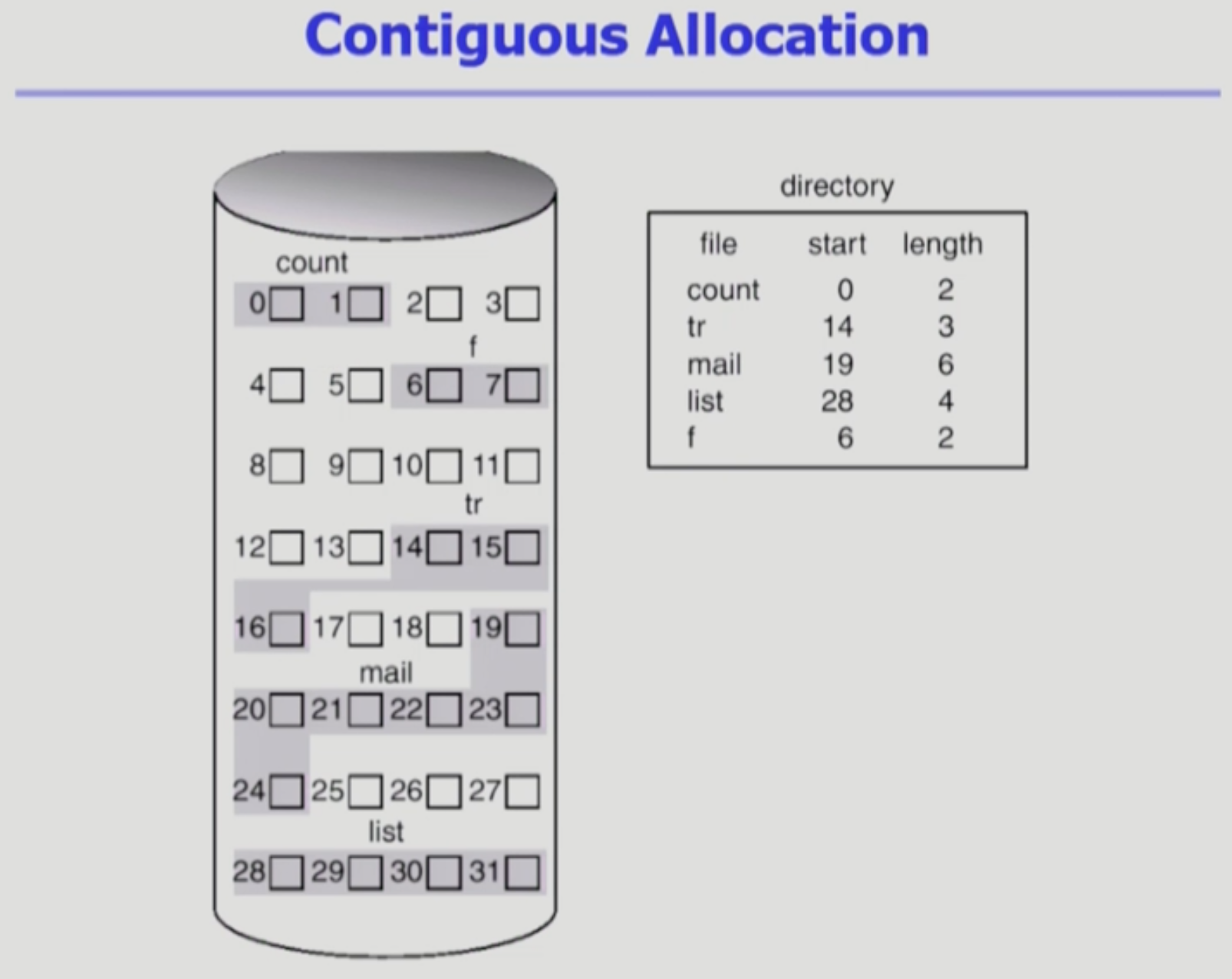
- 하나의 파일이 disk에 연속해서 저장되는 방식이다.
- 2개의 block을 가지는 파일이 0과 1 섹터에 연속되어 저장되어 있다.
- directory가 file에 대한 정보를 가지고 있다. 위 그림에서는 어느 위치부터 길이가 어떻게 되는지.

-
단점
- external framentation
- 새로운 파일이 생기고, 그 파일이 3개의 블락으로 이루어져 있다면 17, 18에 들어갈 수 없다.
- file grow가 어렵다.(파일의 크기를 키우는 데에 있어 제약이 있다)
- tr이 17, 18까지는 확장이 가능하나, 19는 mail이 저장되어 있어 더 이상 확장이 불가능하다.
- 파일의 크기가 커질 것을 대비하여 tr에게 19까지 할당을 해주었다가, 만약 커지지 않는다면 17, 18, 19 공간은 낭비되게 된다. 다른 3개 블락의 파일이 들어올 수 없기 때문이다. 비어있더라도 tr에게 할당되었기 때문이다. 이는 internal framentation이다.
- external framentation
-
장점
- Fast I/O
- 하드 디스크와 같은 매체는 대부분의 시간이 head를 움직이는 데에 사용된다. 바깥에서 안쪽으로 이동하는 시간.
- 한 번의 seek로 많은 데이터를 읽을 수 있다. file의 block들이 연속되어 있기 때문이다. 위 그림의 19번에서 쭈욱 읽으면 된다.
- realtime file 용으로, 또는 이미 run 중이던 process의 swapping 용
- deadline이 있는 realtime file에 빠르게 반응해주기 좋다.
- swapping은 프로세스가 필요하면 빠르게 페이지를 올려줘야 한다. 즉 공간보다는 속도가 더 중요하다. 어차피 지워질 데이터이다.
- Direct Access가 가능하다. mail의 5번째 block에 23번에 접근하고 싶으면 19로 가서 +4를 해주면 된다.
- Fast I/O
Linked Allocation
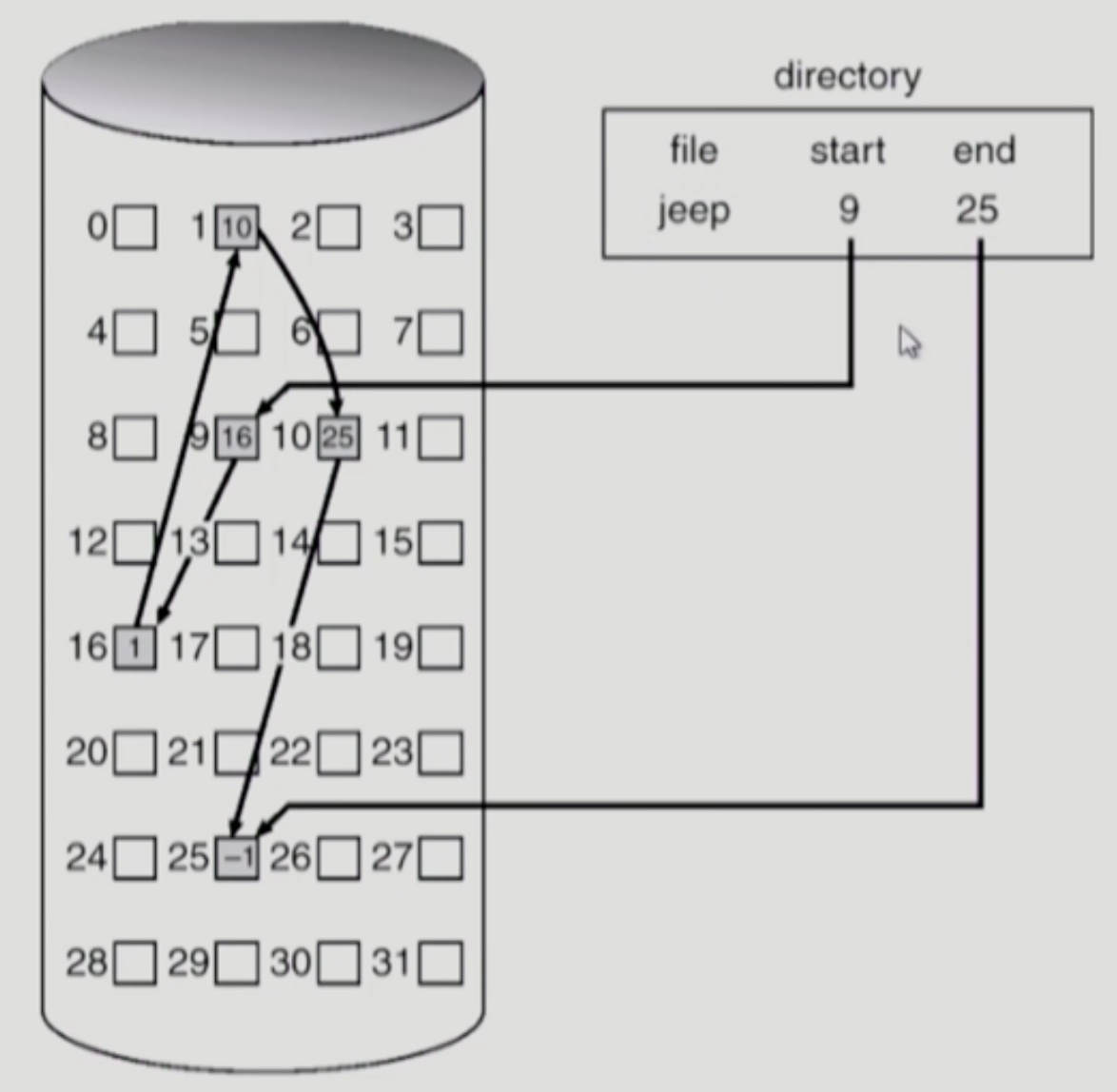
- start로 가면 end는 어디까지인지, directory가 저장하고 있다. end에는 -1이 저장되어 있다.

-
장점
- external fragmentation이 발생하지 않는다.
- 비어 있는 곳 아무데나 들어가도 연결리스트로 연결되어 있기 때문이다. 연속적으로 저장되어 있지 않더라도, start로 들어가 찾을 수 있다.
- external fragmentation이 발생하지 않는다.
-
단점
- Direct Access가 불가능하다.
- start에서 4번째 block을 보려면, 즉 중간 위치를 보려면 앞의 block들인 9 16 10을 거쳐야 한다. 즉 바로 접근이 불가능하다.
- 9, 16 등 거리가 멀리 떨어져 있으면 head가 멀리 이동해야 할 수 있다. 이러한 시간이 많이 걸릴 수 있다.
- Reliability
- 한 sector가 고장나면 pointer가 유실되어 다음 것을 읽을 수 없게 된다. 많은 부분을 잃게 된다.
- pointer를 위한 공간이 block의 일부가 되어 공간 효율성을 떨어뜨린다.
- sector는 512bytes로 이루어져 있다. 포인터는 (32비트의 경우) 4바이트이므로 섹터에서 쓸 수 있는 실질적인 저장 공간은 508 바이트가 된다.
- Direct Access가 불가능하다.
Indexed Allocation
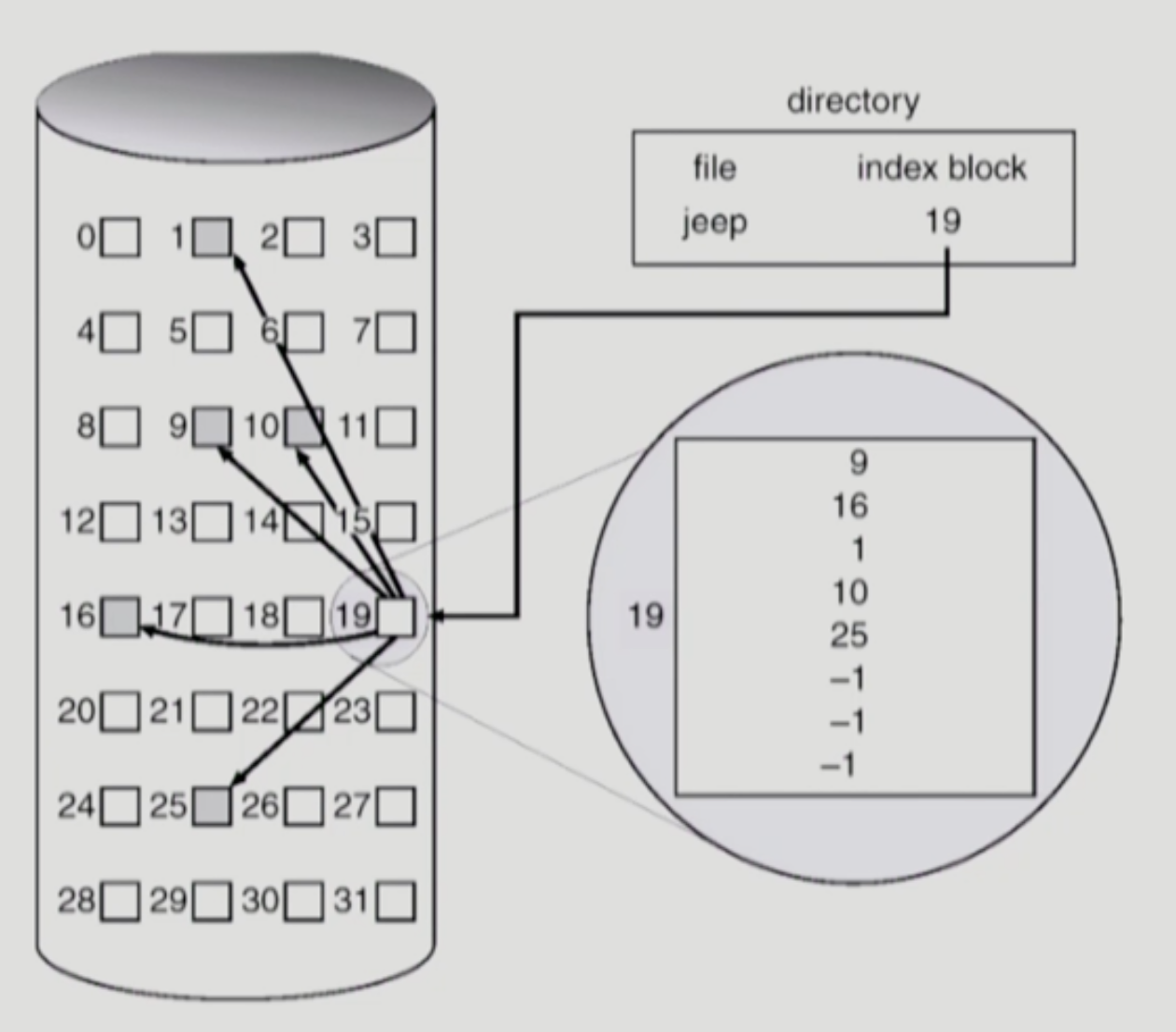
- 19라는 index block은 jeep 파일이 어떤 block으로 구성되어있는지, block index들을 담고 있다. 지금 jeep이라는 파일은 5개의 block으로 구성되어 있다.
- jeep의 4번째 block을 보고 싶으면, 앞전의 linked처럼 하나하나 연결된 것들을 따라가는 것이 아니라, 곧바로 배열처럼 10번 block에 접근할 수 있다.19[3]
- 즉 직접 접근, Direct Access가 가능하다.
- contiguous allocation에서 생긴 external fragmentation도 해결이 가능하다. 아무 block에나 흩어져 있어도 index block을 통해 기억과 접근이 가능하다. 새로운 파일이 들어오더라도 나뉘어져서 아무데나 들어간 다음, index block이 기억하고 있으면 된다.

- 장점
- external fragmentation이 발생하지 않는다.
- direct access가 가능하다.
- 단점
- 아무리 작은 파일이더라도, index block을 위해 총 2개의 block을 최소 필요로 한다.
- 실제로 많은 파일들의 크기가 작기 때문에 비효율적일 수 있다.
- 굉장히 큰 파일의 경우, 하나의 index block으로 모든 block을 표현하지 못할 수 있다.
- 이를 해결하기 위한 방안
- linked scheme
- index block의 마지막은 다른 index block을 가르키는 포인터를 저장해둔다.
- multi-level index
- 2단계 페이지 테이블 처럼 2번 거쳐 index를 가르키게 한다.
- 아무리 작은 파일이더라도, index block을 위해 총 2개의 block을 최소 필요로 한다.
UNIX 파일시스템의 구조
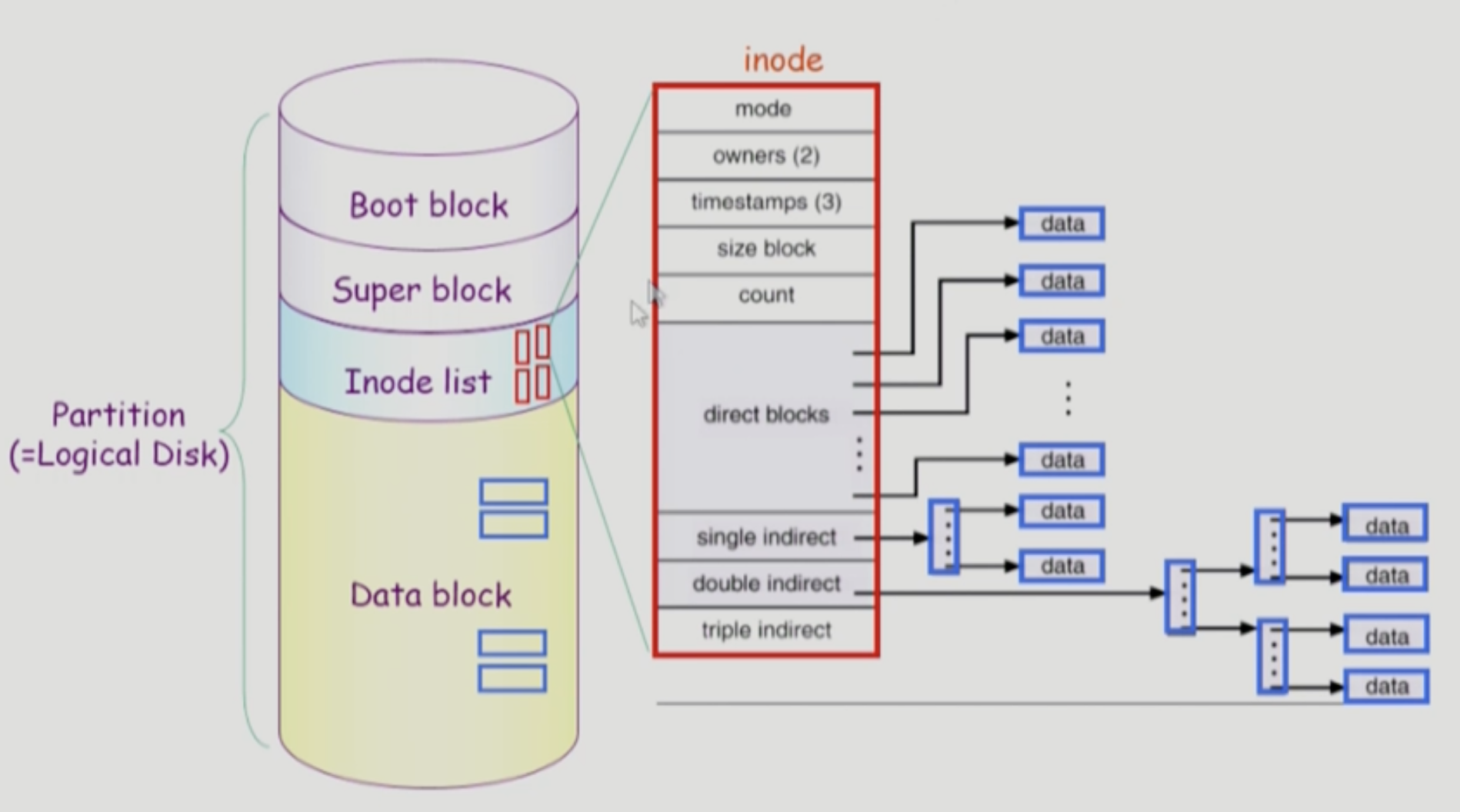
-
하나의 논리적인 디스크인 partition에 file system을 설치해놓은 모습이다.
- 크게 4가지로 구성되어 있다.
- 어떤 파일 시스템이든 제일 앞에 Boot block이 온다.
- 컴퓨터를 켜면 제일 처음 하는 것이 booting이다.
- 부팅을 하기 위한 데이터들은 0번인 boot block에 저장되어 있다.
- 이 boot block에서 kernel의 위치를 찾아 정상적으로 booting이 일어나게 한다.
- 뒤에서 볼 FAT도 0번 block부터 boot block들이 저장되어 있다.
- Super block
- 파일 시스템에 대한 총체적인 데이터들이 저장되어 있다.
- 어디가 빈 block이고, 어디가 file이 저장되어 사용 중인 block인지에 대해 총체적으로 저장되어 있고 관리하고 있다.
- Inode list(Index node list)
- 파일의 메타데이터는 directory에 저장되어 있다. 실제로는 근데 directory가 다 가지고 있지 않다.(실제로 UNIX의 directory는 파일들의 메타데이터 중 극히 일부분만 가지고 있다. 딱 한가지, file의 이름을 directory가 가지고 있다. 나머지 메타데이터는 inode에 저장되어 있기 때문에 inode 번호를 가지고 있기도 하다.) 별도의 위치에 빼서 저장하고 있는데 그 위치가 Inode list이다.
- 파일 하나당 inode가 한 개씩 할당된다. 파일에 대한 메타데이터가 inode에 저장되어 있다.
-
Unix 파일 시스템은 indexed allocation을 변형해서 사용하고 있다.
- inode는 크기가 정해져 있다.
- 즉 위치 정보를 나타내는 포인터도 유한하다.
- 4 단계로 나누어서 파일의 위치 정보를 저장한다.
- direct blocks : 굉장히 작은 파일은 direct blocks의 포인터만으로도 충분하다.
- single indirect : 여길 한번 따라가면 index가 여러가지 있는 index block이 있다.
- double indirect : 더 큰 파일을 위해
- triple indirect : 더 더 큰 파일을 위해
FAT File System
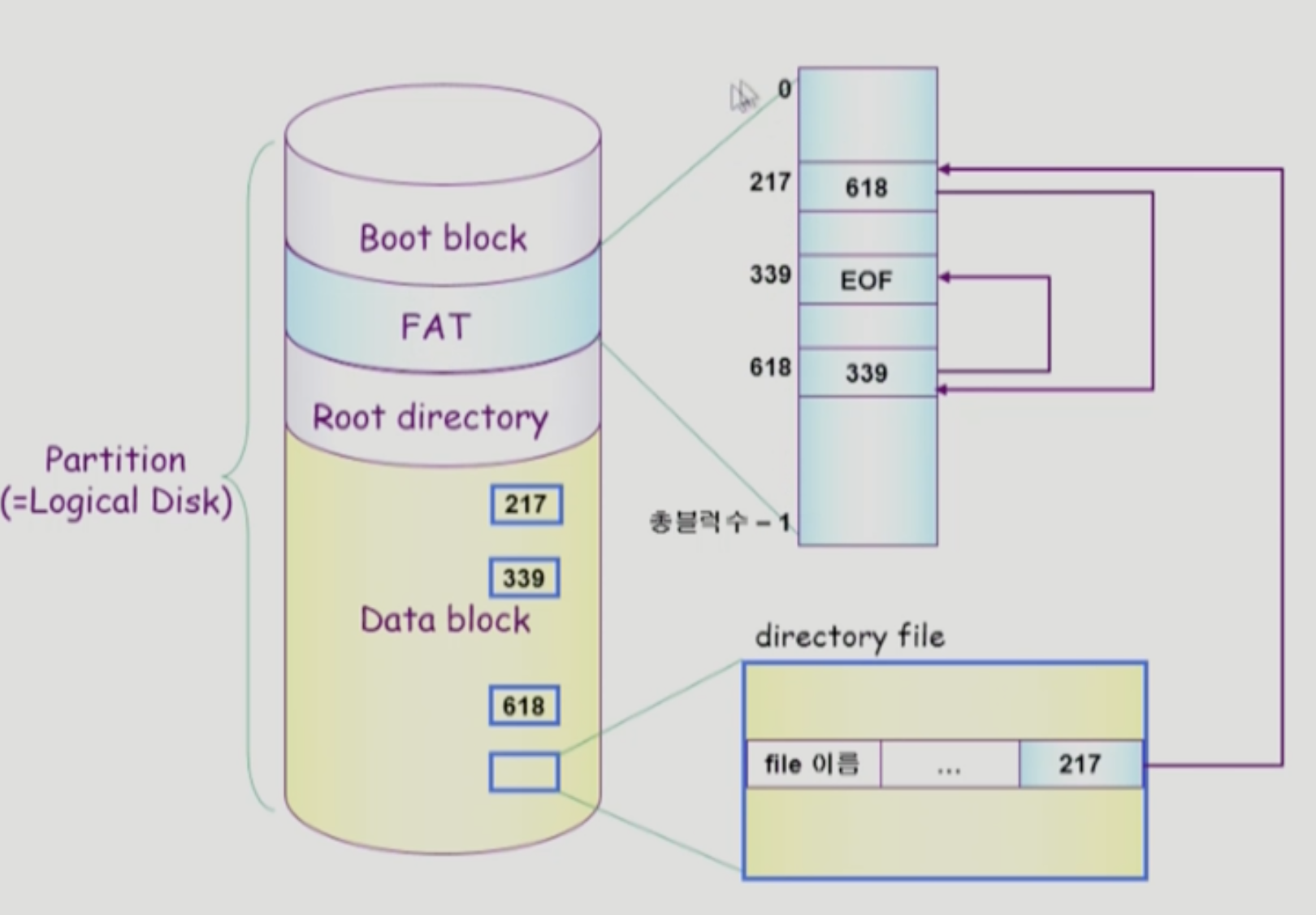
-
linked allocation을 활용한 것이다.
- 다음 위치, 다음 위치를 찾기 위해 block에 접근하여 타고 타고 들어가는 것이 아니라, FAT에서 다음 위치가 어디인지 바로 알 수 있다.
-
파일에 대한 메타데이터 중 위치만 FAT이라는 곳에 저장하고 있다.
- 나머지 메타데이터는 directory가 가지고 있다.
- 파일 이름, 접근 권한, 사이즈, 소유주 등 모든 것을 directory가 가지고 있다. 그 파일에서 첫 번째 block이 어디인지도 directory가 가지고 있다.
- 217번의 다음 block이 어디인지는 별도의 테이블, 혹은 배열인 FAT이 가지고 있다.
- FAT에는 그저 다음 block이 무엇인지에 대한 데이터만 담고 있다. 어떤 파일에 관한 건지는 상관 없다. 그냥 다음 block이 어디인지에 대해서만 데이터를 담고 있다.
- EOF를 만나면 이 파일의 끝임을 알게 된다.
- 나머지 메타데이터는 directory가 가지고 있다.
-
장점
- random access 가능
- reliability
- FAT을 copy해서 1개 더 디스크에 저장해둔다.
- 512 bytes 그대로 활용이 가능하다.
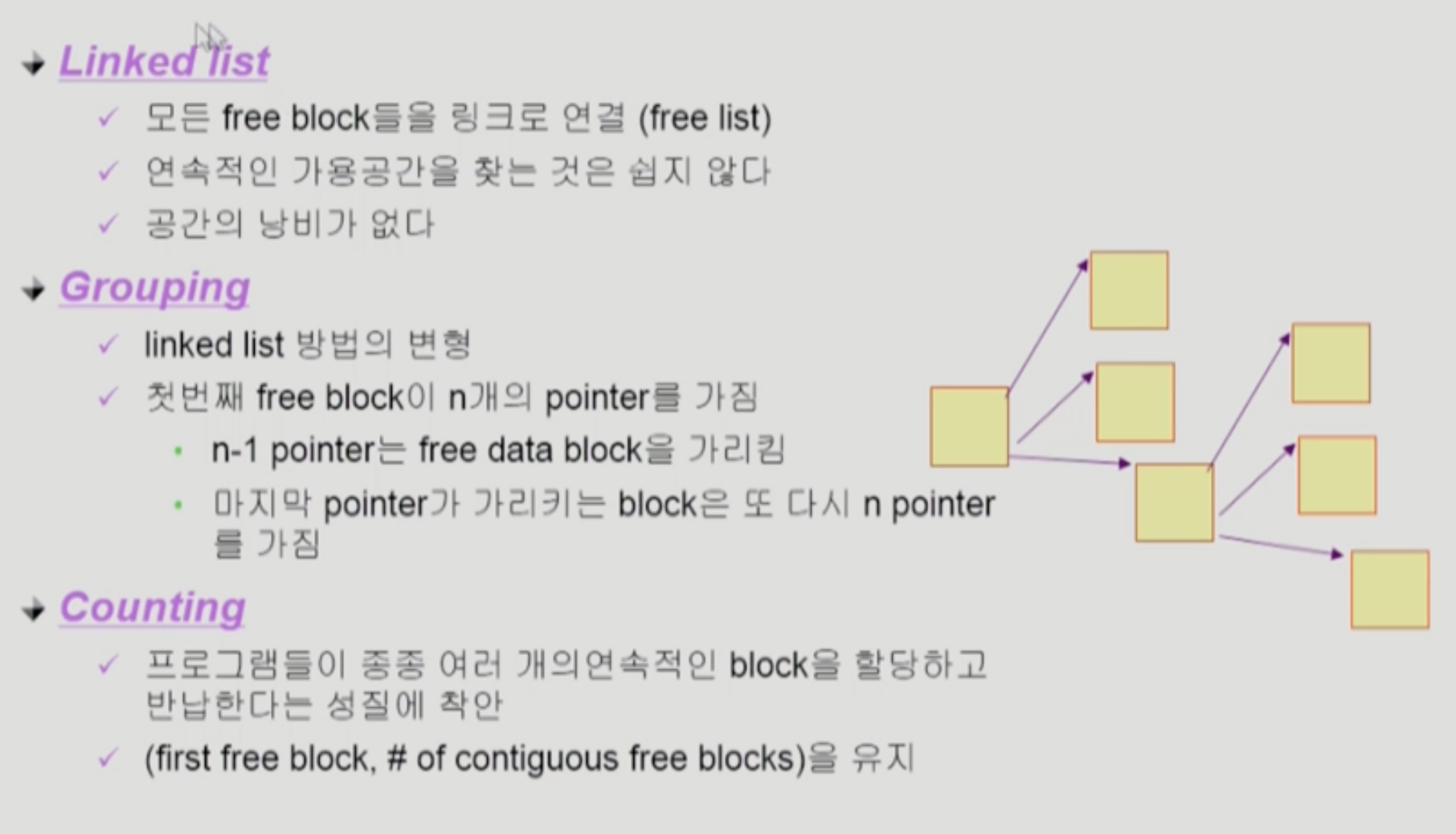
Free Space Management
- 빈 block들을 관리하는 방안
- Bit map or Bit vector
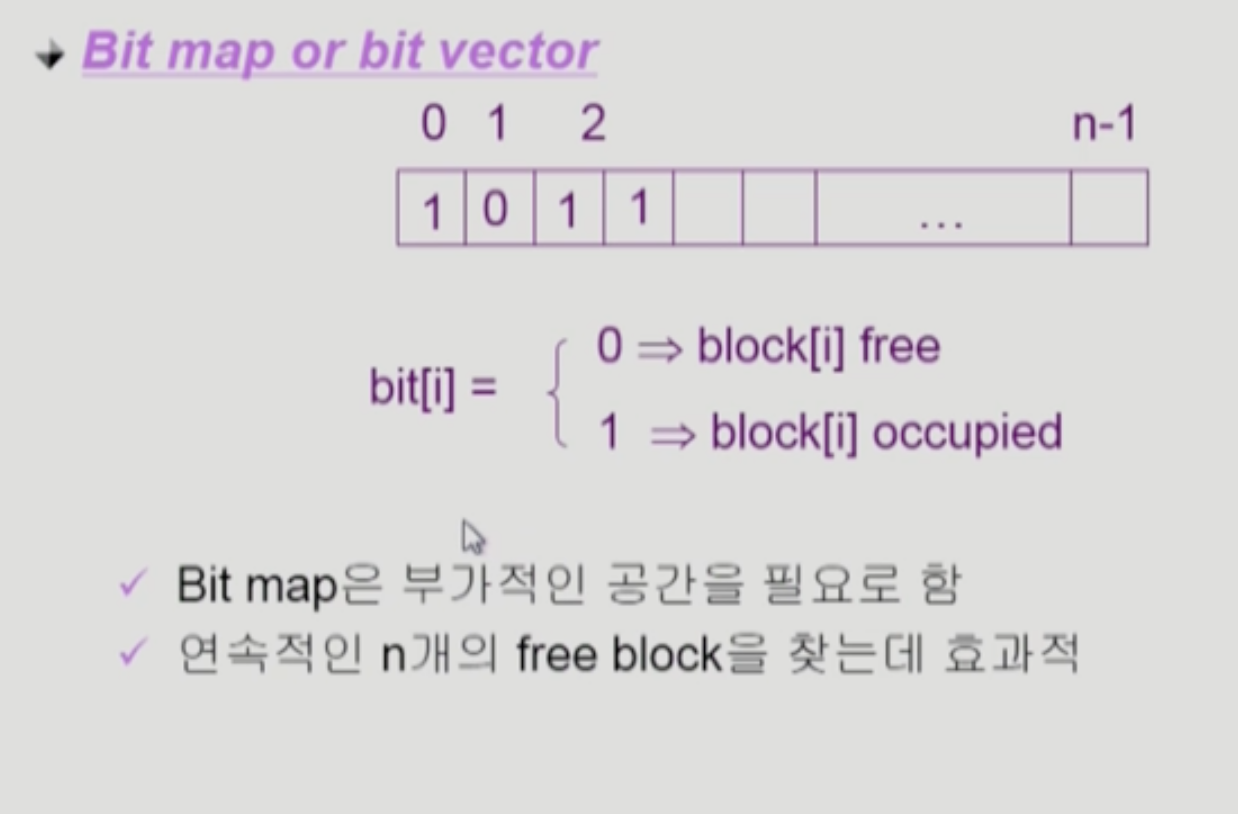
- 부가적인 공간을 필요로 하나 비트이기 때문에 많이 필요로 하진 않는다.
- linked list
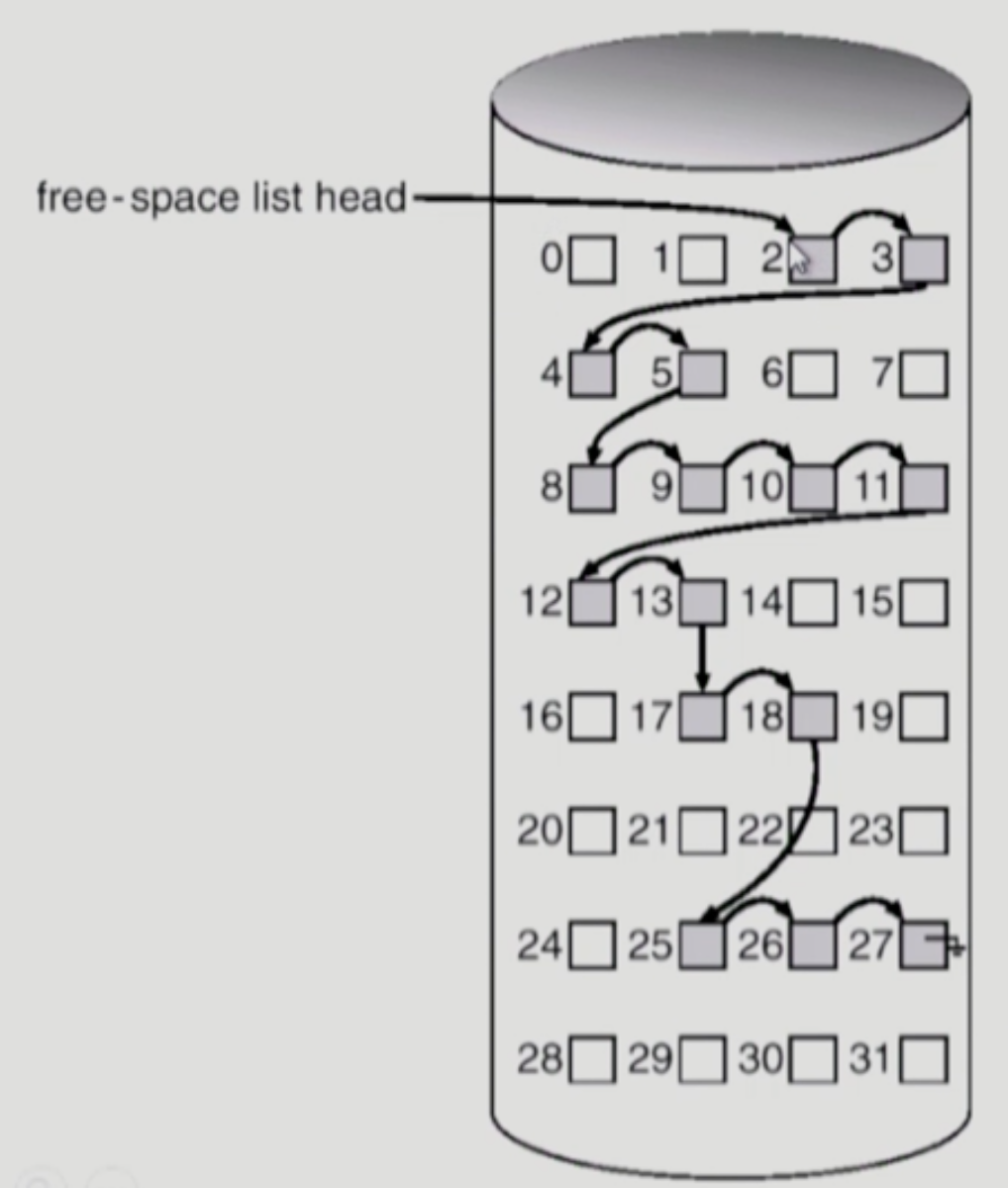
- bit map에 비해 추가적인 공간 낭비는 없다.
- Grouping
- indexed
- 비어있는 어느 한 block이 빈 block들을 가르키고 있게 된다.
- Counting
- 빈 block을 가르키고, 거기서부터 몇 개의 block이 비어있는지 쌍으로 데이터를 저장하고 있다.
- Bit map or Bit vector
Directory Implementation

- Directory 밑의 메타데이터들을 관리하는 또 하나의 파일이다.
- Linear list
- file name은 몇 바이트, file size는 몇 바이트, 이런 식으로 메타데이터 별로 크기를 고정한다.
- 따라서 내가 만약 file size가 3바이트인 것을 찾아야 한다면, 곧바로 file size 바이트 구역으로 가서 일치하는 3바이트의 file을 탐색하면 된다.
- 모두 검색을 해야 돼서 비효율적이다.
- Hash Table
- file name을 해싱한다고 치면 어느 특정 값 범위 내로 들어올 것이다. 해당 해싱 값으로 들어가면 된다.

- entry의 각 메타데이터별로 크기가 고정되도록 구현해야 한다. 그렇지 않으면 해당 엔트리에서 file size가 무엇인지 또 탐색해야 한다. 애초에 고정해놓는 것이 바로바로 원하는 메타데이터를 얻어낼 수 있다.
- long file name
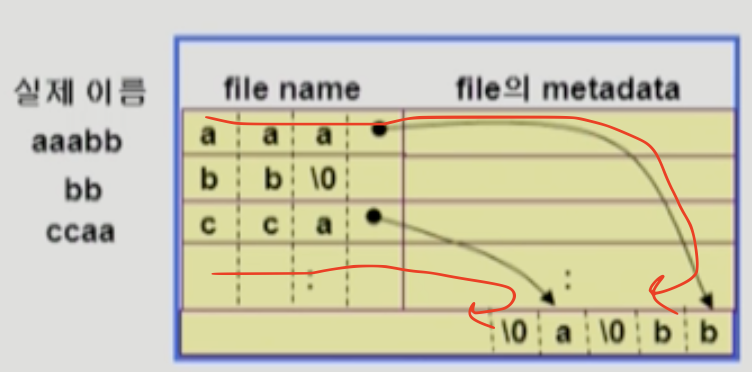
- 마지막에는 포인터를 둬서 directory의 다른 부분에다가 저장해둔다.
VFS and NFS

- Virtual File System(VFS)
- 다양한 파일 시스템이 있지만, 사용자가 같은 인터페이스를 통해 파일에 접근할 수 있게 해주는 OS의 layer이다.
- Network File System(NFS)
- 파일이 로컬 스토리지, 즉 나의 디스크가 아니라 원격에 저장되어 있는 파일 시스템에 저장되어 있는 파일에 접근해야 할 수도 있다. 이를 가능케 해주는 것이 NFS이다.
Page Cache and Buffer Cache

- Page Cache
- 프로세스를 구성하는 페이지에 대한 cache
- Buffer Cache
- read/write 대상인 파일에 대한 cache
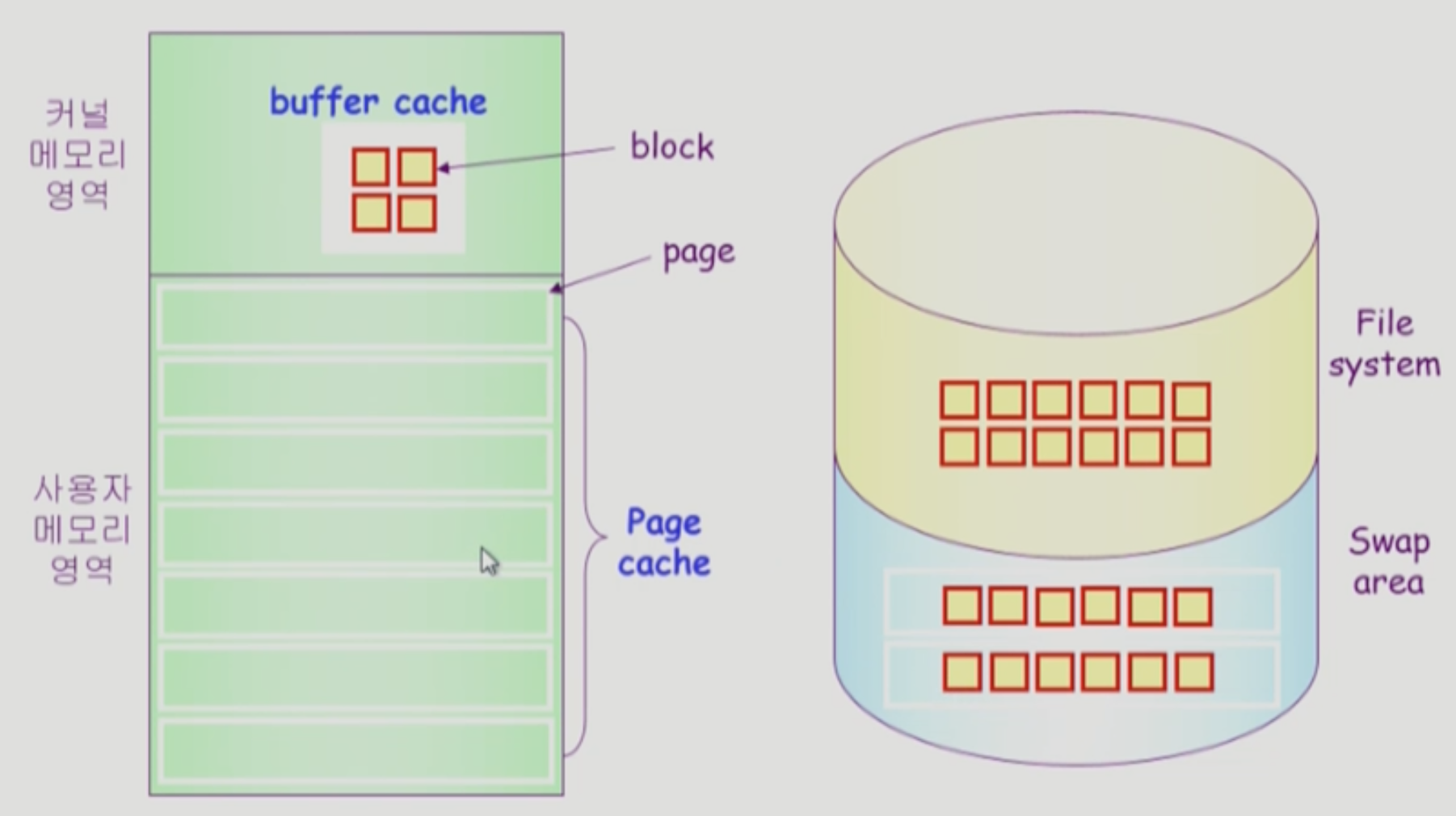
- 최근에는 위와 같이 나누지 않고, 즉 파일에 대한 것이든 프로세스에 대한 것이든 구분을 두지 않고 cache 영역에 올린다.
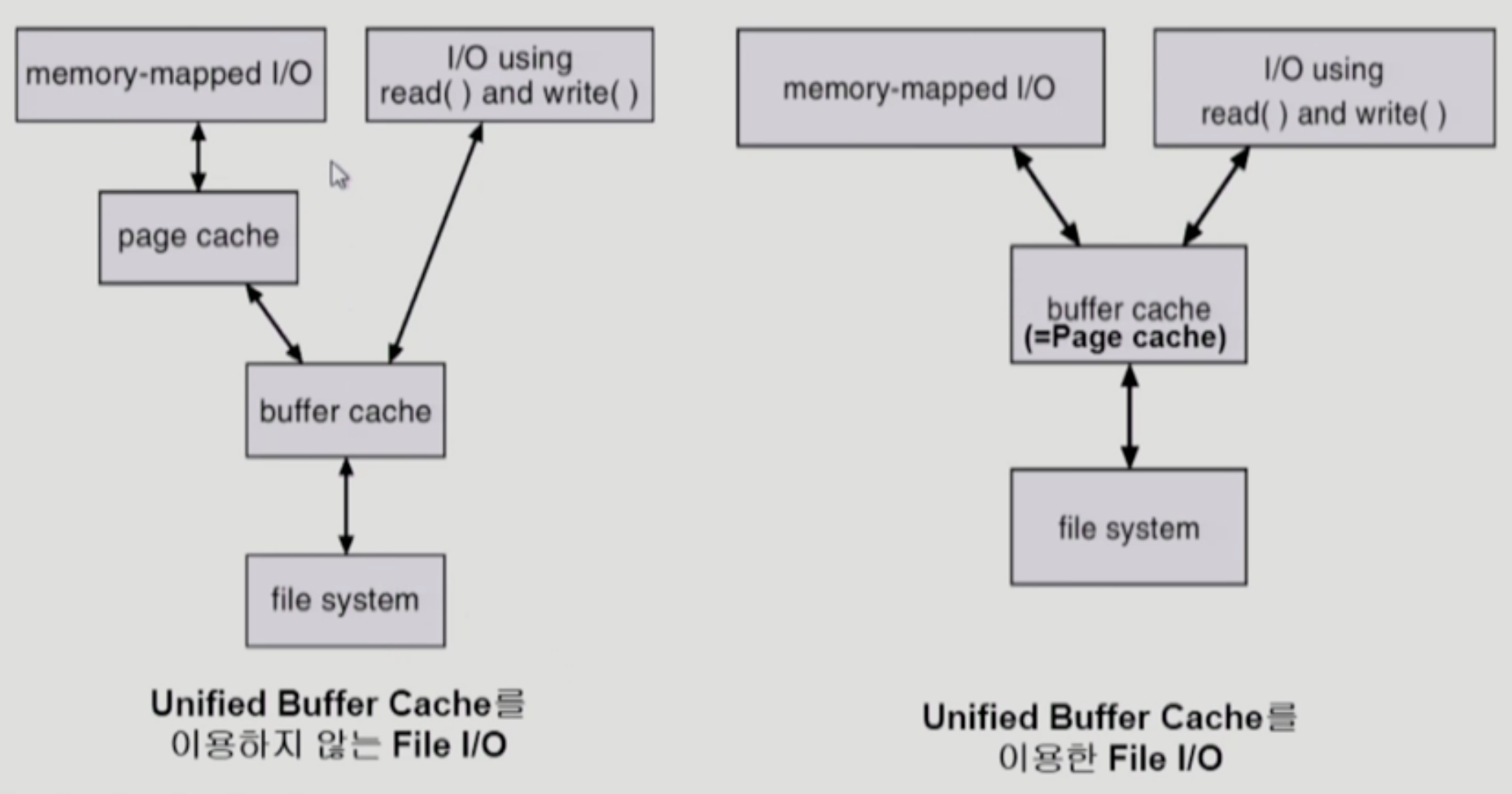
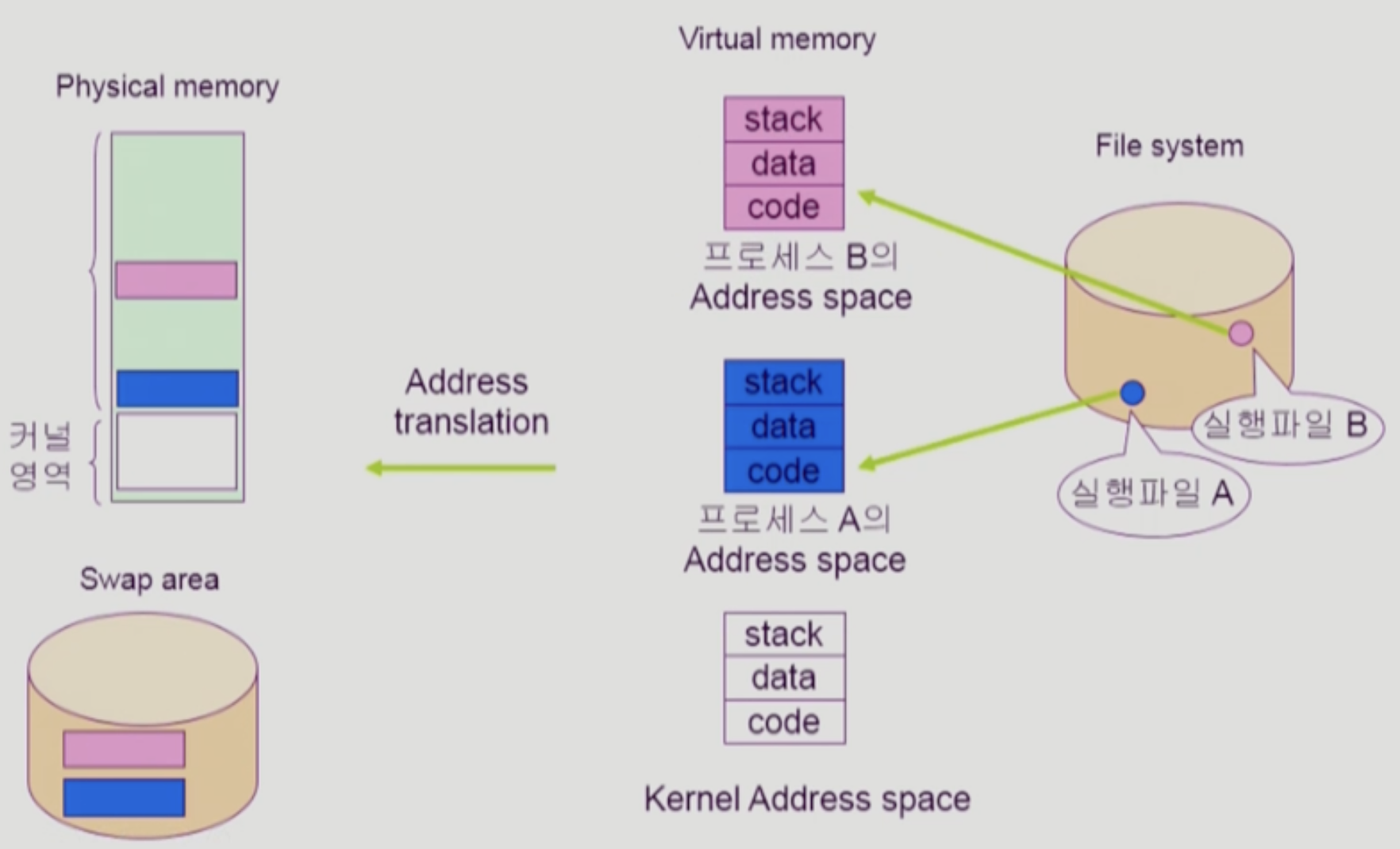
- code 세그먼트는 원래 파일로 저장되어 있었다. 따라서 접근하려고 했으나 물리 메모리에 없다면, swap area가 아니라 디스크에서 가져오게 된다.

메타몽 닮음 :) email: alohajune22@gmail.com