
추천 시스템
콘텐츠 기반 필터링 추천 시스템(영화 추천)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from ast import literal_eval
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarity
%matplotlib inline
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/tmdb_5000_movies.csv'
movies = pd.read_csv(url)
movies_df = movies[['id','title','genres','vote_average','vote_count','popularity','keywords','overview']]
# 문자열로 된 데이터를 list와 dict로 변환
movies_df['genres'] = movies_df['genres'].apply(literal_eval)
movies_df['keywords'] = movies_df['keywords'].apply(literal_eval)
movies_df['genres'] = movies_df['genres'].apply(lambda x : [y['name'] for y in x])
movies_df['keywords'] = movies_df['keywords'].apply(lambda x : [y['name'] for y in x])
# 하나의 문장으로 변환
movies_df['genres_literal'] = movies_df['genres'].apply(lambda x : (' ').join(x))
# CountVectorizer
count_vect = CountVectorizer(min_df=0, ngram_range=(1,2))
genre_mat = count_vect.fit_transform(movies_df['genres_literal'])
# count_vect.vocabulary_ # 단어별 빈도수 확인 가능
# 코사인 유사도 측정
genre_sim = cosine_similarity(genre_mat, genre_mat)
# 높은 순으로 정렬
genre_sim_sorted_ind = genre_sim.argsort()[:, ::-1]
movies_df['weighted_vote'] = movies_df.apply(weighted_vote_average, axis=1)함수 만들기
# 비슷한 영화 찾기
def find_sim_movie(df, sorted_ind, title_name, top_n=10):
title_movie = df[df['title'] == title_name]
title_index = title_movie.index.values
similar_indexes = sorted_ind[title_index, :(top_n*2)]
similar_indexes = similar_indexes.reshape(-1)
similar_indexes = similar_indexes[similar_indexes != title_index]
return df.iloc[similar_indexes].sort_values('weighted_vote', ascending=False)[:top_n]
# 가중치
C = movies_df['vote_average'].mean()
m = movies_df['vote_count'].quantile(0.6)
def weighted_vote_average(record):
v = record['vote_count']
R = record['vote_average']
return ( (v/(v+m)) * R ) + ( (m/(m+v)) * C)테스트
similar_movies = find_sim_movie(movies_df, genre_sim_sorted_ind, 'The Godfather', 10)
similar_movies[['title','vote_average', 'vote_count', 'weighted_vote']]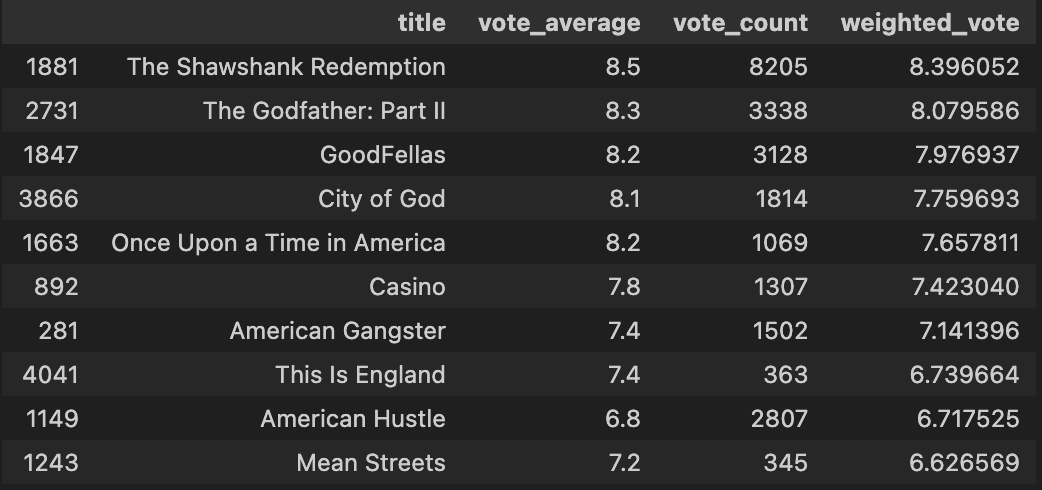
아이템기반 최근접이웃 협업필터링(Good Books)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
books = pd.read_csv('../data/goodbooks-10k/books.csv', encoding='ISO-8859-1')
ratings = pd.read_csv('../data/goodbooks-10k/ratings.csv', encoding='ISO-8859-1')
book_tags = pd.read_csv('../data/goodbooks-10k/book_tags.csv', encoding='ISO-8859-1')
tags = pd.read_csv('../data/goodbooks-10k/tags.csv')
to_read = pd.read_csv('../data/goodbooks-10k/to_read.csv')
# merge(book_tags, tags)
tags_join_df = pd.merge(book_tags, tags, left_on='tag_id', right_on='tag_id', how='inner')
# merge(books, tags_join_df)
books_with_tags = pd.merge(books, tags_join_df, left_on='book_id', right_on='goodreads_book_id', how='inner')
# merge(books, temp_df)
temp_df = books_with_tags.groupby('book_id')['tag_name'].apply(' '.join).reset_index()
books = pd.merge(books, temp_df, left_on='book_id', right_on='book_id', how='inner')
# 작가 + 태그 합친 열 추가
books['corpus'] = (pd.Series(books[['authors','tag_name_x']]
.fillna('')
.values.tolist()
).str.join(' '))작가로 본 유사 책 검색
tf = TfidfVectorizer(analyzer='word', ngram_range=(1,2), min_df=0, stop_words='english')
tfidf_matrix = tf.fit_transform(books['authors'])
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
titles = books['title']
indices = pd.Series(books.index, index=books['title'])
# 유사도 값 호출
cosine_sim[indices['The Hobbit']]
sim_scores = list(enumerate(cosine_sim[indices['The Hobbit']]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:11]
book_indices = [i[0] for i in sim_scores]
titles.iloc[book_indices]
tag로 본 유사 책 검색
tf1 = TfidfVectorizer(analyzer='word', ngram_range=(1,2), min_df=0, stop_words='english')
tfidf_matrix1 = tf1.fit_transform(books_with_tags['tag_name'].head(10000))
cosine_sim1 = linear_kernel(tfidf_matrix1, tfidf_matrix1)
titles1 = books['title']
indices1 = pd.Series(books.index, index=books['title'])
def tag_recommondations(title):
idx = indices1[title]
sim_scores = list(enumerate(cosine_sim1[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:11]
book_indices = [i[0] for i in sim_scores]
return titles1.iloc[book_indices]
# 테스트
tag_recommondations('The Hobbit')
작가 + tag(corpus)로 본 유사 책 검색
tf_corpus = TfidfVectorizer(analyzer='word', ngram_range=(1,2), min_df=0, stop_words='english')
tfidf_matrix_corpus = tf_corpus.fit_transform(books['corpus'])
cosine_sim_corpus = linear_kernel(tfidf_matrix_corpus, tfidf_matrix_corpus)
titles = books['title']
indices = pd.Series(books.index, index=books['title'])
def corpus_recommondations(title):
idx = indices[title]
sim_scores = list(enumerate(cosine_sim_corpus[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:11]
book_indices = [i[0] for i in sim_scores]
return titles.iloc[book_indices]
# 테스트
corpus_recommondations('The Hobbit')

21세기 주인공