

import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPool2D
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Add
#########################################
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets
from torchvision import transforms선형회귀
- activation function 걸지 않는다.
- mse(mean squared error)
raw_data = np.genfromtxt('../data/x09.txt', skip_header=36)
x_data = np.array(raw_data[:, 2:4], dtype=np.float32)
y_data = np.array(raw_data[:, 4], dtype=np.float32)
y_data = y_data.reshape((25,1))
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(1, input_shape=(2, ))
])
model.compile(optimizer='rmsprop', loss='mse')
hist = model.fit(x_data, y_data, epochs=5000)
model.predict(np.array([45,27]).reshape(1,2))분류(XOR), sigmoid
X = np.array([
[0,0],
[1,0],
[0,1],
[1,1]
])
y = np.array([[0],[1],[1],[0]])
model = tf.keras.Sequential([
tf.keras.layers.Dense(2, activation='sigmoid', input_shape=(2, )),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1), loss='mse')
hist = model.fit(X, y, epochs=5000, batch_size=1)
model.predict(X)분류(역전파), relu
from sklearn.datasets import load_iris
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
iris = load_iris()
X = iris.data
y = iris.target
enc = OneHotEncoder(sparse=False, handle_unknown='ignore')
enc.fit(y.reshape(len(y), 1))
y_onehot = enc.transform(y.reshape(len(y), 1))
### loss 함수에 sparse_categorical_crossentropy 하면 OneHotEncoding 과정 생략 가능
X_train, X_test, y_train, y_test = train_test_split(X, y_onehot, test_size=0.2, random_state=13)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(32, input_shape=(4, ), activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
hist = model.fit(X_train, y_train, epochs=100)
model.evaluate(X_test, y_test, verbose=2)
model.predict(np.array(X_test[0]).reshape(1,4))분류
minst = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = minst.load_data()
x_train, x_test = x_train/255, x_test/255
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(1000, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# sparse_categorical_crossentropy : one-hot-encoding 생략
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=10, batch_size=100, verbose=1)
model.evaluate(x_test, y_test)
# 예측
predicted_result = model.predict(x_test)
predicted_labels = np.argmax(predicted_result, axis=1)분류(CNN)
from tensorflow.keras import layers, models
minst = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = minst.load_data()
X_train, X_test = X_train/255, X_test/255
# 채널 추가
X_train = X_train.reshape((60000,28,28,1))
X_test = X_test.reshape((10000,28,28,1))
# convolution 'relu'로 해야함
model = models.Sequential([
# 특성 32개만 보겠다. (채널)
layers.Conv2D(32, kernel_size=(5,5), strides=(1,1),
padding='same', activation='relu', input_shape=(28,28,1)),
layers.MaxPooling2D(pool_size=(2,2), strides=(2,2)),
# 특성 64개만 보겠다. (채널)
layers.Conv2D(64, (2,2), activation='relu', padding='same'),
layers.MaxPooling2D(pool_size=(2,2)),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(1000, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
hist = model.fit(X_train, y_train, epochs=5, verbose=1,
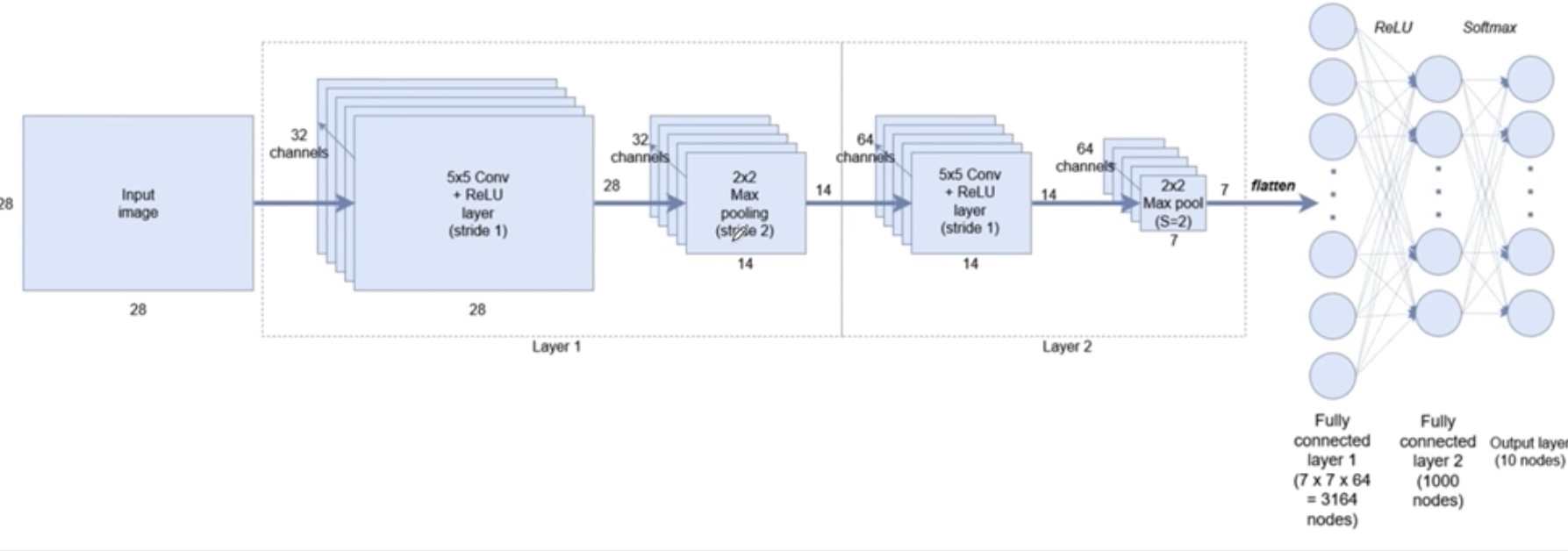
validation_data = (X_test, y_test))

- 은닉층에서는 ReLU 쓴다. (역전파)
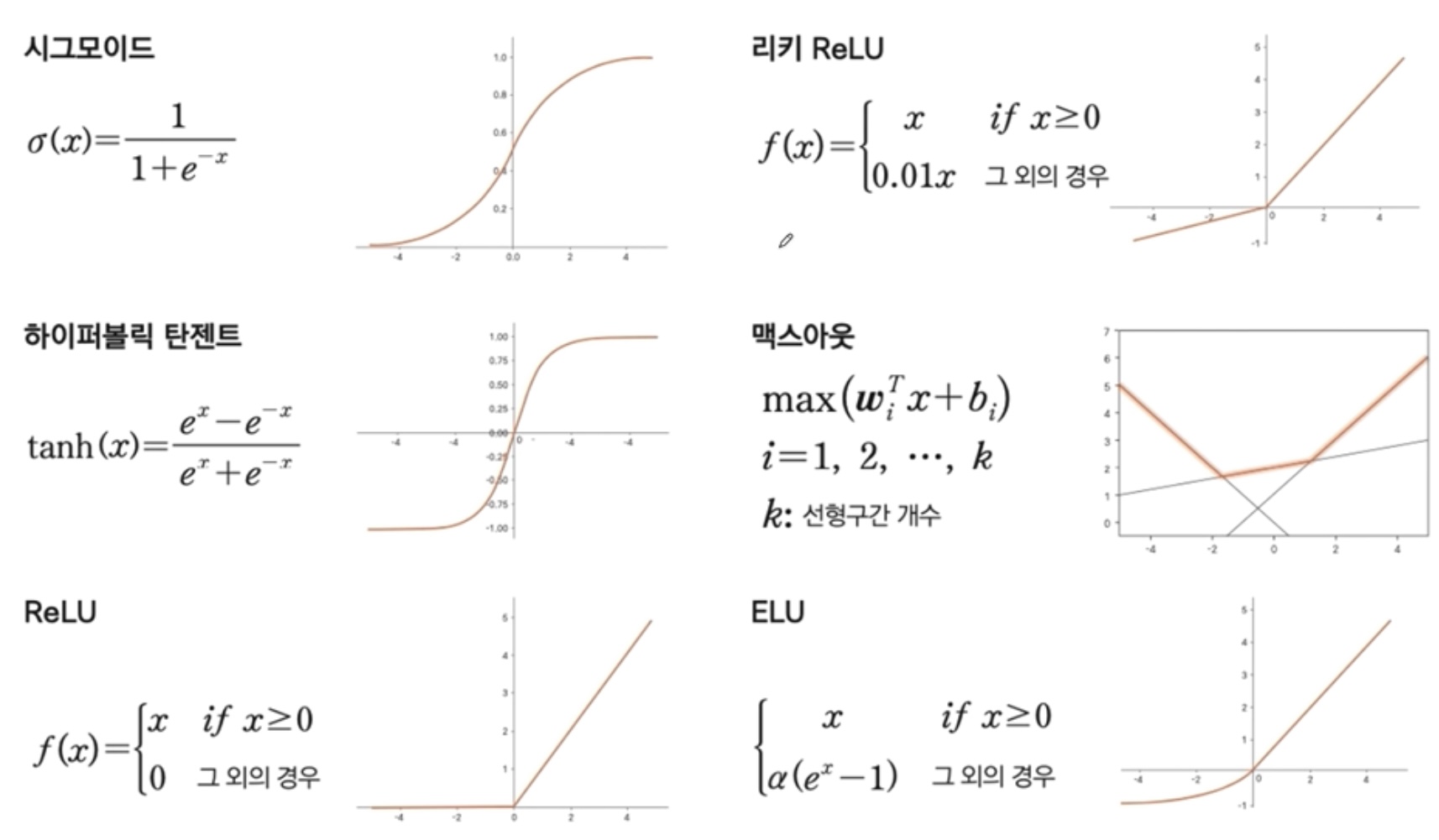
활성화 함수의 종류
- 시그모이드 / 리키 ReLU / 하이퍼블릭 탄젠트 / 맥스아웃 / ReLU / ELU
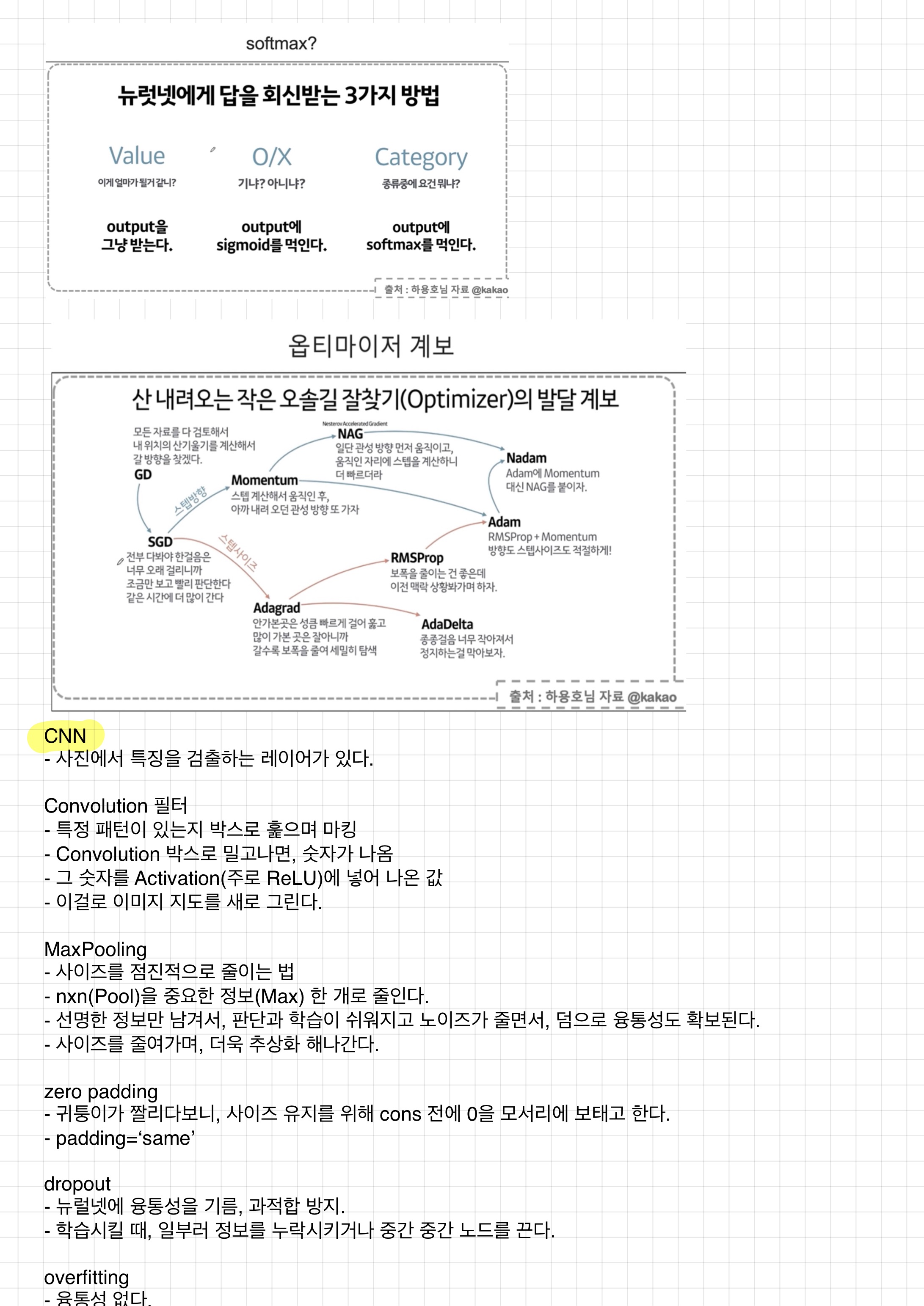
- softmax : 출력단위 합 1, 그 중 가장 큰 값을 답으로 예측
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
%matplotlib inlineraw_data = np.genfromtxt('../data/x09.txt', skip_header=36)
xs = np.array(raw_data[:,2], dtype=np.float32)
ys = np.array(raw_data[:,3], dtype=np.float32)
zs = np.array(raw_data[:,4], dtype=np.float32)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(xs, ys, zs)
ax.set_xlabel('Weight')
ax.set_ylabel('Age')
ax.set_zlabel('Blood fat')
ax.view_init(15,15)
plt.show()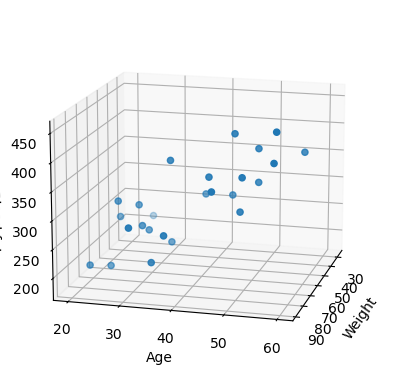
x_data = np.array(raw_data[:, 2:4], dtype=np.float32)
y_data = np.array(raw_data[:, 4], dtype=np.float32)
y_data = y_data.reshape((25,1))
x_data.shape # (25, 2)
y_data.shape # (25, 1)딥러닝
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(1, input_shape=(2, ))
])
model.compile(optimizer='rmsprop', loss='mse')
# model.summary()
# 학습
hist = model.fit(x_data, y_data, epochs=5000)
plt.plot(hist.history['loss']);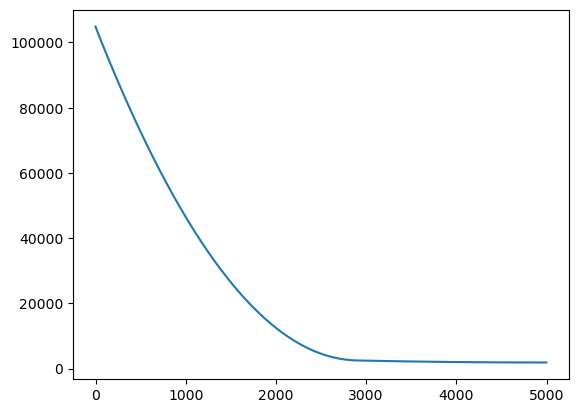
# 예측 (100kg, 44세)
model.predict(np.array([100,44]).reshape(1,2))
# array([[374.88287]], dtype=float32)# 가중치와 bias
W_, b_ = model.get_weights()
W_, b_
# (array([[1.2485238], [5.569502 ]], dtype=float32),
# array([4.9724], dtype=float32))
x = np.linspace(20,100,50).reshape(50,1)
y = np.linspace(10,70,50).reshape(50,1)
X = np.concatenate((x,y), axis=1)
Z = np.matmul(X, W_) + b_
fig = plt.figure(figsize=(12,12))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(xs, ys, zs);
ax.scatter(x, y, Z);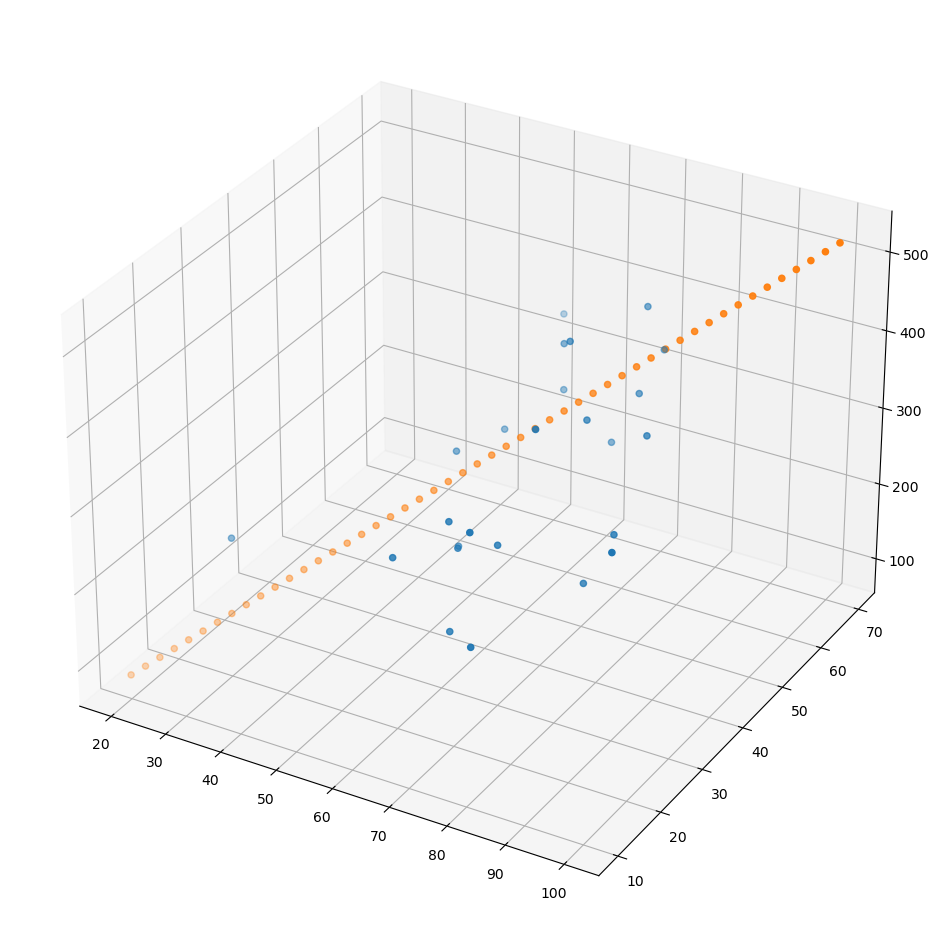
XOR
X = np.array([
[0,0],
[1,0],
[0,1],
[1,1]
])
y = np.array([[0],[1],[1],[0]])
model = tf.keras.Sequential([
tf.keras.layers.Dense(2, activation='sigmoid', input_shape=(2, )),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1), loss='mse')
hist = model.fit(X, y, epochs=5000, batch_size=1)
plt.plot(hist.history['loss']);
# model.predict(X)
# array([[0.3825005 ],
# [0.53566325],
# [0.53745383],
# [0.54743403]], dtype=float32)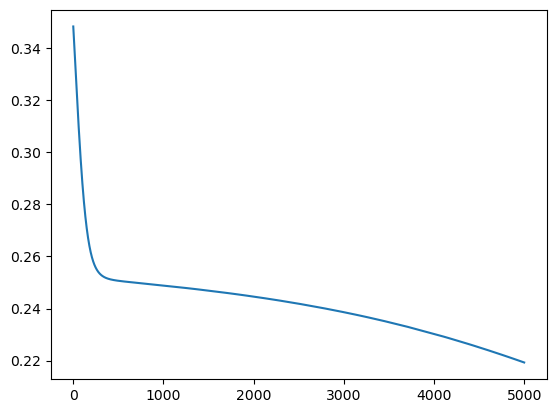
iris
from sklearn.datasets import load_iris
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
iris = load_iris()
X = iris.data
y = iris.target
# one-hot-encoding
enc = OneHotEncoder(sparse=False, handle_unknown='ignore')
enc.fit(y.reshape(len(y), 1))
y_onehot = enc.transform(y.reshape(len(y), 1))
X_train, X_test, y_train, y_test = train_test_split(X, y_onehot, test_size=0.2, random_state=13)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(32, input_shape=(4, ), activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# model.summary()
hist = model.fit(X_train, y_train, epochs=100)
# test
model.evaluate(X_test, y_test, verbose=2)
# [0.09212634712457657, 0.9666666388511658]plt.plot(hist.history['loss']);
plt.plot(hist.history['accuracy']);
plt.grid()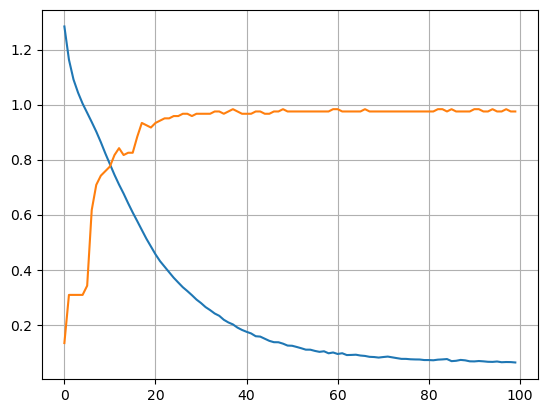
MNIST
import tensorflow as tf
import random
minst = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = minst.load_data()
x_train, x_test = x_train/255, x_test/255
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(1000, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=10, batch_size=100, verbose=1)
plot_target = ['loss','val_loss','accuracy','val_accuracy']
plt.figure(figsize=(12,8))
for each in plot_target:
plt.plot(hist.history[each], label=each)
plt.legend()
plt.grid()
plt.show()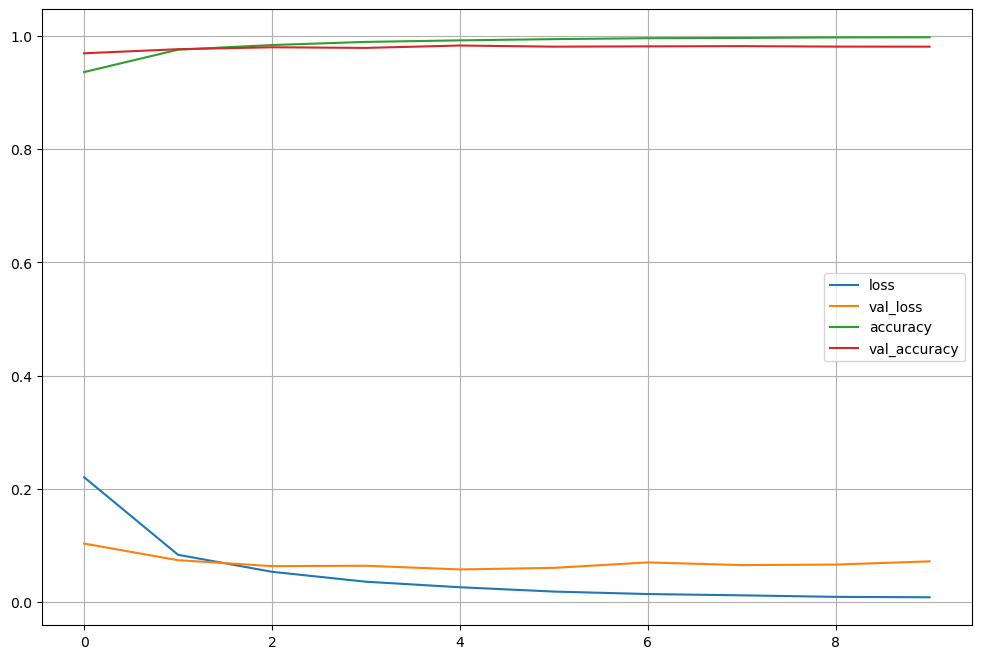
score = model.evaluate(x_test, y_test)
print('Test loss : ', score[0])
print('Test accuracy : ', score[1])
# Test loss : 0.07181849330663681
# Test accuracy : 0.9810000061988831
predicted_result = model.predict(x_test)
predicted_labels = np.argmax(predicted_result, axis=1)
wrong_result = []
for n in range(0, len(y_test)):
if predicted_labels[n] != y_test[n]:
wrong_result.append(n)
samples = random.choices(population=wrong_result, k=16)
plt.figure(figsize=(14,12))
for idx, n in enumerate(samples):
plt.subplot(4,4,idx+1)
plt.imshow(x_test[n].reshape(28,28), cmap='Greys')
plt.title('Label : ' + str(y_test[n]) + '| Predict : ' + str(predicted_labels[n]))
plt.axis('off')
MNIST(CNN)
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
minst = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = minst.load_data()
X_train, X_test = X_train/255, X_test/255
X_train = X_train.reshape((60000,28,28,1))
X_test = X_test.reshape((10000,28,28,1))
model = models.Sequential([
layers.Conv2D(32, kernel_size=(5,5), strides=(1,1),
padding='same', activation='relu', input_shape=(28,28,1)),
layers.MaxPooling2D(pool_size=(2,2), strides=(2,2)),
layers.Conv2D(64, (2,2), activation='relu', padding='same'),
layers.MaxPooling2D(pool_size=(2,2)),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(1000, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
hist = model.fit(X_train, y_train, epochs=5, verbose=1,
validation_data = (X_test, y_test))
plot_target = ['loss','val_loss','accuracy','val_accuracy']
plt.figure(figsize=(12,8))
for each in plot_target:
plt.plot(hist.history[each], label=each)
plt.legend()
plt.grid()
plt.show()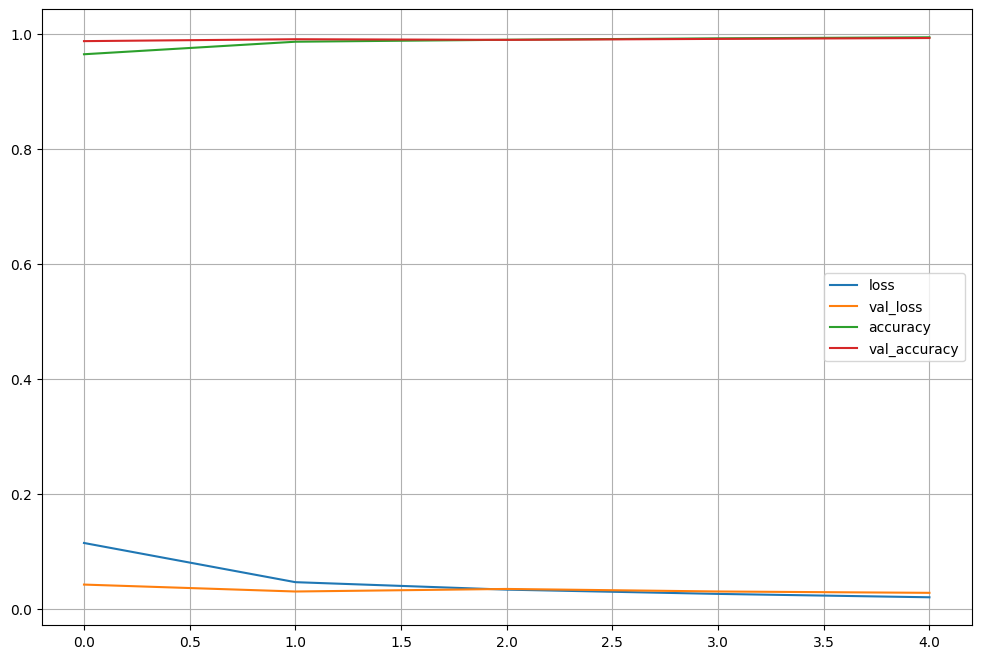
Scratch
함수
import numpy as np
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
# 모델 출력
def calc_output(W, x):
v = np.matmul(W, x)
y = sigmoid(v)
return y
# 모델 출력(역전파)
def calc_output_back(W1, W2, x):
v1 = np.matmul(W1, x)
y1 = sigmoid(v1)
v = np.matmul(W2, y1)
y = sigmoid(v)
return y, y1
# 오차 계산
def calc_error(d, y):
e = d - y
delta = y * (1-y) * e
return delta
# 오차 계산(역전파)
def calc_delta(d, y):
e = d - y
delta = y * (1-y) * e
return delta
# 은닉층의 델타 계산
def calc_delta1(W2, delta, y1):
e1 = np.matmul(W2.T, delta)
delta1 = y1 * (1-y1) * e1
return delta1
# 한 epoch에 수행되는 W의 계산
def delta_GD(W, X, D, alpha):
for k in range(4):
x = X[k, :].T
d = D[k]
y = calc_output(W, x)
delta = calc_error(d, y)
dW = alpha * delta * x
W = W + dW
return W
# 역전파 코드
def backprop_XOR(W1, W2, X, D, alpha):
for k in range(4):
x = X[k, :].T
d = D[k]
y, y1 = calc_output_back(W1, W2, x)
delta = calc_delta(d, y)
delta1 = calc_delta1(W2, delta, y1)
dW1 = (alpha*delta1).reshape(4,1) * x.reshape(1,3)
W1 = W1 + dW1
dW2 = alpha * delta * y1
W2 = W2 + dW2
return W1, W2
# cross_entrophy의 델타
# cross_entrophy에서 delta는 오차와 같다.
def calcDelta_cd(d, y):
e = d - y
delta = e
return delta
# 은닉층에서
def calcDelta1_ce(W2, delta, y1):
e1 = np.matmul(W2.T, delta)
delta1 = y1 * (1-y1) * e1
return delta1
# 엔트로피 코드
def backprop_CE(W1, W2, X, D, alpha):
for k in range(4):
x = X[k, :].T
d = D[k]
y, y1 = calc_output_back(W1, W2, x)
delta = calcDelta_cd(d, y)
delta1 = calcDelta1_ce(W2, delta, y1)
dW1 = (alpha*delta1).reshape(4,1) * x.reshape(1,3)
W1 = W1 + dW1
dW2 = alpha * delta * y1
W2 = W2 + dW2
return W1, W2순방향 연산
X = np.array([
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]
])
# 정답
D = np.array([[0],[0],[1],[1]])
# 가중치(랜덤)
W = 2 * np.random.random((1,3)) - 1
alpha = 0.9
for epoch in range(10000):
W = delta_GD(W, X, D, alpha)
N = 4
for k in range(N):
x = X[k, :].T
v = np.matmul(W, x) # 가중치를 곱함
y = sigmoid(v)
print(y)
# [0.01019828]
# [0.00829351]
# [0.99324253]
# [0.99168758]XOR
X = np.array([
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]
])
# 정답
D = np.array([[0],[1],[1],[0]])
# 가중치(역전파)
W1 = 2 * np.random.random((4,3)) - 1
W2 = 2 * np.random.random((1,4)) - 1
# 학습
alpha = 0.9
for epoch in range(10000):
W1, W2 = backprop_XOR(W1, W2, X, D, alpha)
N = 4
for k in range(N):
x = X[k, :].T
v1 = np.matmul(W1, x)
y1 = sigmoid(v1)
v = np.matmul(W2, y1) # 가중치를 곱함
y = sigmoid(v)
print(y)
# [0.00524861]
# [0.00464798]
# [0.99562214]
# [0.99539701]크로스 엔트로피
X = np.array([
[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]
])
# 정답
D = np.array([[0],[1],[1],[0]])
# 가중치
W1 = 2 * np.random.random((4,3)) - 1
W2 = 2 * np.random.random((1,4)) - 1
# 학습
alpha = 0.9
for epoch in range(10000):
W1, W2 = backprop_CE(W1, W2, X, D, alpha)
N = 4
for k in range(N):
x = X[k, :].T
v1 = np.matmul(W1, x)
y1 = sigmoid(v1)
v = np.matmul(W2, y1) # 가중치를 곱함
y = sigmoid(v)
print(y)
# [4.34428194e-05]
# [0.99972788]
# [0.99972947]
# [0.00063206]예제1
함수
- Softmax, ReLU, Dropout
def Softmax(x):
x = np.subtract(x, np.max(x))
ex = np.exp(x)
return ex / np.sum(ex)
def ReLU(x):
return np.maximum(0, x)
def calOutput_ReLU(W1, W2, W3, W4, x):
v1 = np.matmul(W1, x)
y1 = ReLU(v1)
v2 = np.matmul(W2, y1)
y2 = ReLU(v2)
v3 = np.matmul(W3, y2)
y3 = ReLU(v3)
v = np.matmul(W4, y3)
y = Softmax(v)
return y, v1, v2, v3, y1, y2, y3
def backpropagation_ReLU(d, y, W2, W3, W4, v1, v2, v3):
e = d - y
delta = e
e3 = np.matmul(W4.T, delta)
delta3 = (v3 > 0) * e3
e2 = np.matmul(W3.T, delta3)
delta2 = (v2 > 0) * e2
e1 = np.matmul(W2.T, delta2)
delta1 = (v1 > 0) * e1
return delta, delta1, delta2, delta3
def calcWs(alpha, delta, delta1, delta2, delta3, y1, y2, y3, x, W1, W2, W3, W4):
dW4 = alpha * delta * y3.T
W4 = W4 + dW4
dW3 = alpha * delta3 * y2.T
W3 = W3 + dW3
dW2 = alpha * delta2 * y1.T
W2 = W2 + dW2
dW1 = alpha * delta1 * x.T
W1 = W1 + dW1
return W1, W2, W3, W4
def DeepReLU(W1, W2, W3, W4, X, D, alpha):
for k in range(5):
x = np.reshape(X[:,:,k], (25,1))
d = D[k,:].T
y, v1, v2, v3, y1, y2, y3 = calOutput_ReLU(W1, W2, W3, W4, x)
delta, delta1, delta2, delta3 = backpropagation_ReLU(d, y, W2, W3, W4, v1, v2, v3)
W1, W2, W3, W4 = calcWs(alpha, delta, delta1, delta2, delta3, y1, y2, y3, x, W1, W2, W3, W4)
return W1, W2, W3, W4
def verify_algorithm(x, W1, W2, W3, W4):
v1 = np.matmul(W1, x)
y1 = ReLU(v1)
v2 = np.matmul(W2, y1)
y2 = ReLU(v2)
v3 = np.matmul(W3, y2)
y3 = ReLU(v3)
v = np.matmul(W4, y3)
y = Softmax(v)
return y
def Dropout(y, ratio):
ym = np.zeros_like(y)
num = round(y.size * (1-ratio))
idx = np.random.choice(y.size, num, replace=False)
ym[idx] = 1.0 / (1.0-ratio)
return ym
def calOutput_Dropout(W1, W2, W3, W4, x):
v1 = np.matmul(W1, x)
y1 = sigmoid(v1)
y1 = y1 * Dropout(y1, 0.2)
v2 = np.matmul(W2, y1)
y2 = sigmoid(v2)
y2 = y2 * Dropout(y2, 0.2)
v3 = np.matmul(W3, y2)
y3 = sigmoid(v3)
y3 = y3 * Dropout(y3, 0.2)
v = np.matmul(W4, y3)
y = Softmax(v)
return y, v1, v2, v3, y1, y2, y3
def backpropagation_Dropout(d, y, y1, y2, y3, W2, W3, W4, v1, v2, v3):
e = d - y
delta = e
e3 = np.matmul(W4.T, delta)
delta3 = y3 * (1-y3) * e3
e2 = np.matmul(W3.T, delta3)
delta2 = y2 * (1-y2) * e2
e1 = np.matmul(W2.T, delta2)
delta1 = y1 * (1-y1) * e1
return delta, delta1, delta2, delta3
def DeepDropout(W1, W2, W3, W4, X, D, alpha):
for k in range(5):
x = np.reshape(X[:,:,k], (25,1))
d = D[k,:].T
y, v1, v2, v3, y1, y2, y3 = calOutput_Dropout(W1, W2, W3, W4, x)
delta, delta1, delta2, delta3 = backpropagation_Dropout(d, y, y1, y2, y3, W2, W3, W4, v1, v2, v3)
W1, W2, W3, W4 = calcWs(alpha, delta, delta1, delta2, delta3, y1, y2, y3, x, W1, W2, W3, W4)
return W1, W2, W3, W4X = np.zeros((5,5,5))
X[:, :, 0] = [ [0,1,1,0,0], [0,0,1,0,0], [0,0,1,0,0], [0,0,1,0,0], [0,1,1,1,0] ]
X[:, :, 1] = [ [1,1,1,1,0], [0,0,0,0,1], [0,1,1,1,0], [1,0,0,0,0], [1,1,1,1,1] ]
X[:, :, 2] = [ [1,1,1,1,0], [0,0,0,0,1], [0,1,1,1,0], [0,0,0,0,1], [1,1,1,1,0] ]
X[:, :, 3] = [ [0,0,0,1,0], [0,0,1,1,0], [0,1,0,1,0], [1,1,1,1,1], [0,0,0,1,0] ]
X[:, :, 4] = [ [1,1,1,1,1], [1,0,0,0,0], [1,1,1,1,0], [0,0,0,0,1], [1,1,1,1,0] ]
D = np.array([
[[1,0,0,0,0]], [[0,1,0,0,0]], [[0,0,1,0,0]], [[0,0,0,1,0]], [[0,0,0,0,1]]
])
plt.figure(figsize=(12,4))
for n in range(5):
plt.subplot(1,5,n+1)
plt.imshow(X[:,:,n])
plt.show()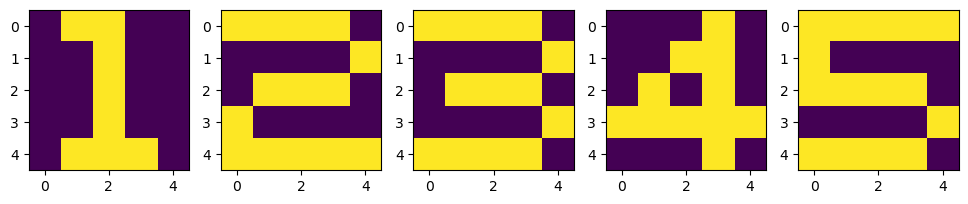
ReLU
# 학습
# 가중치
W1 = 2 * np.random.random((20,25)) - 1
W2 = 2 * np.random.random((20,20)) - 1
W3 = 2 * np.random.random((20,20)) - 1
W4 = 2 * np.random.random((5,20)) - 1
alpha = 0.01
for each in tqdm(range(10000)):
W1, W2, W3, W4 = DeepReLU(W1, W2, W3, W4, X, D, alpha)
N = 5
for k in range(N):
x = np.reshape(X[:,:,k], (25,1))
y = verify_algorithm(x, W1, W2, W3, W4)
print('y = {}'.format(k+1))
print(np.argmax(y, axis=0) + 1)
print(y)
print('---------------')
# 테스트
X_test = np.zeros((5,5,5))
X_test[:, :, 0] = [ [0,0,1,0,0], [0,0,1,0,0], [0,0,1,0,0], [0,0,1,0,0], [0,0,1,0,0] ]
X_test[:, :, 1] = [ [1,1,1,1,1], [0,0,0,0,1], [0,1,1,1,0], [1,0,0,0,0], [1,1,1,1,1] ]
X_test[:, :, 2] = [ [1,1,1,1,0], [0,0,0,0,1], [0,1,1,1,0], [0,0,0,0,1], [0,0,1,0,0] ]
X_test[:, :, 3] = [ [0,0,0,1,0], [0,0,1,1,0], [0,1,0,1,0], [1,1,1,1,0], [0,0,0,1,0] ]
X_test[:, :, 4] = [ [1,1,0,0,0], [1,0,0,0,0], [1,1,1,1,0], [0,0,0,0,1], [0,0,0,1,0] ]
plt.figure(figsize=(12,4))
for n in range(5):
plt.subplot(1,5,n+1)
plt.imshow(X_test[:,:,n])
plt.show()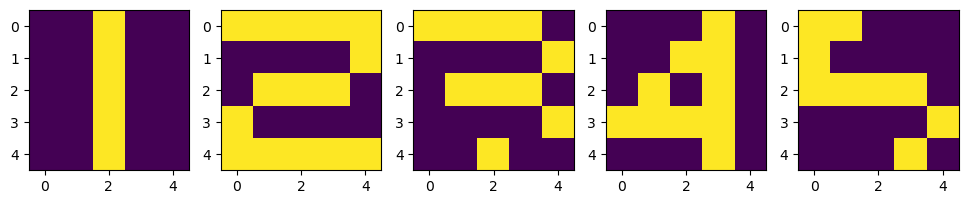
learning_result = [0,0,0,0,0]
for k in range(N):
x = np.reshape(X_test[:,:,k], (25,1))
y = verify_algorithm(x, W1, W2, W3, W4)
learning_result[k] = np.argmax(y, axis=0) + 1
print('y = {}'.format(k+1))
print(np.argmax(y, axis=0) + 1)
print(y)
print('---------------')plt.figure(figsize=(12,4))
for k in range(5):
plt.subplot(2,5,k+1)
plt.imshow(X_test[:,:,k])
plt.subplot(2,5,k+6)
plt.imshow(X[:,:,learning_result[k][0]-1])
plt.show()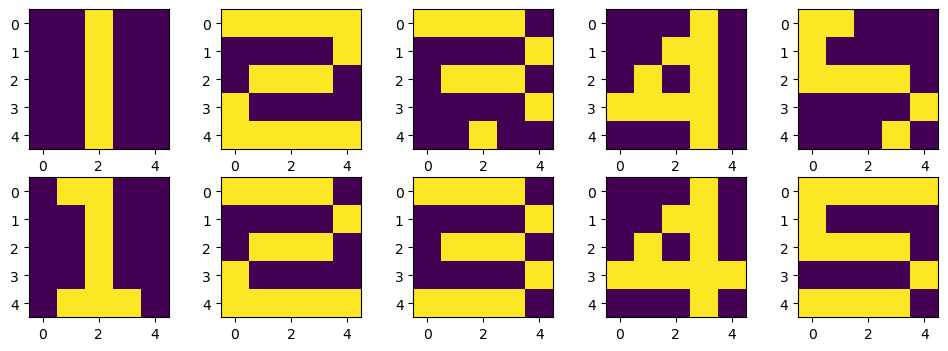
Dropout
# 학습
W1 = 2 * np.random.random((20,25)) - 1
W2 = 2 * np.random.random((20,20)) - 1
W3 = 2 * np.random.random((20,20)) - 1
W4 = 2 * np.random.random((5,20)) - 1
alpha = 0.01
for each in tqdm(range(10000)):
W1, W2, W3, W4 = DeepDropout(W1, W2, W3, W4, X, D, alpha)
N = 5
for k in range(N):
x = np.reshape(X[:,:,k], (25,1))
y = verify_algorithm(x, W1, W2, W3, W4)
print('y = {}'.format(k+1))
print(np.argmax(y, axis=0) + 1)
print(y)
print('---------------')
plt.figure(figsize=(12,4))
for k in range(5):
plt.subplot(2,5,k+1)
plt.imshow(X_test[:,:,k])
plt.subplot(2,5,k+6)
plt.imshow(X[:,:,learning_result[k][0]-1])
plt.show()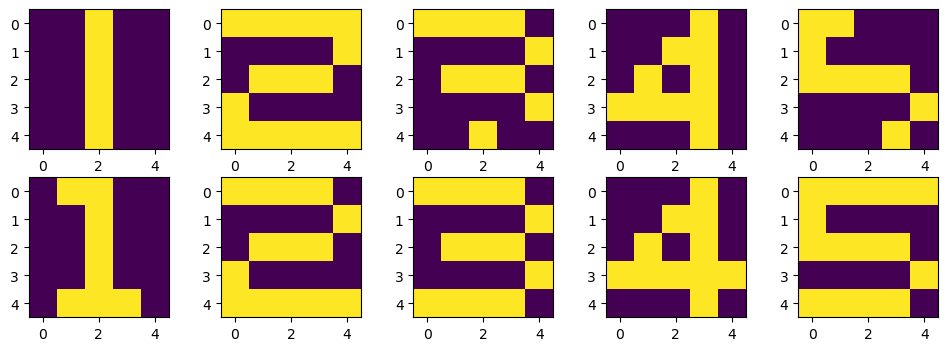

21세기 주인공