좋습니다. 조경 설계 종사자들을 위한 '건축 및 조경 관련 법률·판례 요약 웹서비스'를 개발하기 위해 Hugging Face 기반 LLM 동작원리, 구조, 활용 방법, 적용 가능한 프로젝트 아이디어 등을 조사하겠습니다. 이 웹서비스는 한국어와 영어를 지원하며, Hugging Face의 사전학습 모델을 우선 활용하고 AWS에서 배포할 계획에 맞춰 구성하겠습니다.
LLM 개요 및 요약에 적합한 모델 후보
트랜스포머 기반의 LLM은 기본적으로 인코더(encoder)와 디코더(decoder) 층으로 구성된다. BERT류 모델은 인코더 전용 구조로, 문장 양쪽 문맥을 모두 활용하는 마스크 언어모델링을 통해 훈련된다 (BERT). 반면 GPT류는 디코더 전용으로 이전 토큰을 보고 다음 토큰을 예측하는 자기회귀 언어모델(Auto-Regressive LM)이다 (The Transformer model family). T5나 BART, Pegasus 등은 인코더-디코더(Seq2Seq) 구조로, 입력 텍스트를 압축(인코더)한 뒤 요약문을 생성(디코더)한다 (The Transformer model family). 요약은 주로 입력 문서의 핵심 내용을 추출하거나 새롭게 생성하는 문서 요약(자연어 생성) 태스크로, 인코더-디코더 모델이 적합하다 (Summarization) (The Transformer model family).
- BERT: 사전학습된 Bidirectional Encoder. 문장 양쪽 문맥 마스킹 예측으로 언어 이해에 강점 (BERT). 단순 생성 능력은 없으므로 요약보다는 문장 이해, 분류에 활용.
- GPT-2/3: 순방향 디코더 기반. 대량 텍스트 예측으로 언어 생성에 뛰어나다 (The Transformer model family). 다만 저작권 문제나 파라미터 크기 이슈로 직접 사용은 제한적.
- T5/Flan-T5: Google의 Text-to-Text 모델(T5)은 모든 NLP를 “입력:출력” 형태로 통일하여 훈련되었다 (The Transformer model family). Flan-T5는 T5를 Instruction Fine-tuning한 버전으로, 복잡한 명령어 수행 능력이 향상되었다. 예를 들어 “Summarize:” 접두사로 요약 태스크를 지정할 수 있다 (The Transformer model family). Hugging Face 허브의
google/flan-t5-base등은 요약 및 법률 분야에 활용 가능하다 (Video: Summarizing legal documents with Hugging Face and Amazon SageMaker - Julien Simon - Medium). - BART: 페이스북의 Seq2Seq 모델. Transformer 구조에 텍스트 인필링(pretraining) 기법을 적용 (The Transformer model family). 뉴스기사 요약(CNN/DailyMail) 기반 대규모 파인튜닝 모델(
facebook/bart-large-cnn)이 제공되며, 영어 법령 요약에 활용할 수 있다. - Pegasus: 구글의 특화 요약 모델. 큰 문장(문맥)을 마스킹하고 빈칸을 문장 단위로 예측하는 Gap-Sentence-Generation 기법으로 사전학습된다 (The Transformer model family). CNN/DailyMail, XSum 등으로 fine-tune된 체크포인트(
google/pegasus-cnn_dailymail,google/pegasus-xsum)가 있어 영어 판례 요약에 적합하다. - 한글 요약 모델: 한국어 요약용으로는 KoBART, KoT5 기반 모델이 있다. 예를 들어 Gogamza의
kobart-summarization(KoBART 기반)이나lcw99/t5-base-korean-text-summary등이 있고, 인공지능허브 데이터로 파인튜닝되었다. Hugging Face 허브에서 한국어 summarization 모델을 찾을 수 있다 (gogamza/kobart-summarization · Hugging Face). - 다국어 모델: mT5, mBART-50, XLM-RoBERTa 등이 한국어·영어를 모두 지원한다. 상세는 뒤 섹션에서 설명.
위 모델 중 인코더-디코더 모델(T5/BART/Pegasus/KoBART 등)이 추상적 요약(abstractive summarization)에 적합하다 (Summarization) (The Transformer model family). 예를 들어 Hugging Face의 pipeline("summarization")을 사용할 때 model="facebook/bart-large-cnn"과 같이 지정하면 쉽게 요약이 가능하다 (Summarization).
사전학습 모델 활용 전략
Hugging Face Transformers 라이브러리의 파이프라인(pipeline) 기능을 이용하면 요약 태스크를 손쉽게 구현할 수 있다. 요약용 파이프라인은 입력 텍스트를 받아 요약문을 반환한다. 예를 들어 영어 기사 요약의 경우:
from transformers import pipeline
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
text = "Long input legal or regulatory text..."
summary = summarizer(text, max_length=150, min_length=50)
print(summary[0]['summary_text'])위 예시처럼 pipeline("summarization")을 사용하면 내부적으로 적절한 토크나이저와 모델이 로드되어 추론을 수행한다 (Summarization). 결과로 summary_text에 요약 결과가 담긴다. 한글 텍스트도 마찬가지로 한국어 모델을 지정하여 파이프라인을 사용하면 된다(예: model="gogamza/kobart-summarization").
직접 코드로 제어하려면 토크나이저와 모델을 불러와 model.generate()를 사용한다 (Summarization) (Summarization). 예를 들어 KoBART 모델로 수행할 경우:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("gogamza/kobart-summarization")
model = AutoModelForSeq2SeqLM.from_pretrained("gogamza/kobart-summarization")
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=1024)
summary_ids = model.generate(inputs['input_ids'], max_length=100, no_repeat_ngram_size=3, early_stopping=True)
print(tokenizer.decode(summary_ids[0], skip_special_tokens=True))이 방식은 파이프라인보다 세부 튜닝(beam search, 길이 제한 등)이 가능하다 (Summarization) (Summarization).
토크나이저도 해당 모델에 맞춰 선택한다. 예를 들어 T5/mT5는 별도의 T5Tokenizer, BART/KoBART는 BartTokenizer, Pegasus는 PegasusTokenizer를 사용한다. Hugging Face 허브의 from_pretrained() 호출 시 모델 아티팩트에 맞는 토크나이저가 자동 로드되므로, 일반적으로 AutoTokenizer.from_pretrained(model_name) 형태로 하면 된다. 한국어의 경우 KoBART/KoT5 등은 한글 전처리를 포함하므로 별도 BPE 토크나이저를 사용해야 한다. Pipeline 사용 시 모델 이름만 바꾸면 토크나이저가 연동된다.
요약 특화 파인튜닝: 법률/판례 요약의 정확도를 높이려면 도메인 데이터로 파인튜닝해야 한다. 예를 들어 Hugging Face의 예시에서는 Google FLAN-T5를 판례 요약용 데이터로 파인튜닝한다 (Video: Summarizing legal documents with Hugging Face and Amazon SageMaker - Julien Simon - Medium). 이렇게 미리 파인튜닝된 모델을 사용할 경우 파이프라인에 모델 이름만 지정하여 적용하면 된다.
한국어·영어 다국어 모델(mT5, XLM-R 등)
한국어·영어를 모두 지원하는 다국어 모델을 쓰면 한 번의 모형으로 두 언어 요약을 처리할 수 있다. 대표적 모델로는 Google의 mT5(Multilingual T5)와 Facebook의 XLM-RoBERTa(XLM-R) 등이 있다.
-
mT5: T5의 다국어 확장판으로, Common Crawl 기반 101개 언어 코퍼스(mC4)로 사전학습되었다 (mT5). mT5도 순수한 Seq2Seq 구조(인코더-디코더)이므로 요약이 가능하다. 다만 mT5는 사전학습만 되어 있어 실제 사용 전에는 Fine-tuning이 필수이다. 단일 태스크 Fine-tuning 시에는 접두어(‘summarize:’)가 필수가 아니나, 다중 태스크 시에는 접두어를 활용할 수 있다 (mT5). Hugging Face 예시로
google/mt5-small이나google/mt5-base등이 제공된다 (mT5). 사용 예시는 다음과 같다:from transformers import AutoTokenizer, AutoModelForSeq2SeqLM tokenizer = AutoTokenizer.from_pretrained("google/mt5-small") model = AutoModelForSeq2SeqLM.from_pretrained("google/mt5-small") text = "요약할 한국어 법률 텍스트를 입력합니다." inputs = tokenizer("summarize: " + text, return_tensors="pt") summary_ids = model.generate(**inputs, max_length=80) print(tokenizer.decode(summary_ids[0], skip_special_tokens=True))영어 텍스트도 마찬가지 방식으로 요약 가능하며, Prefix를 영어로 주어도 된다. mT5는 101개 언어를 학습했기 때문에 한국어·영어 지원이 모두 가능 (mT5).
-
XLM-RoBERTa (XLM-R): 100개 언어를 지원하는 다국어 인코더 전용 모델이다 (XLM-RoBERTa). 원래 Masked LM으로 훈련되어 텍스트 임베딩 생성에 강점이 있다. XLM-R은 생성 모델이 아니므로 직접 요약문을 생성하지는 못한다. 대신 요약에 필요한 특징 추출이나 유사 문장 검색 등의 전처리 작업(예: 문장 임베딩)에는 유용하다. 예를 들어 한국어·영어 혼용 데이터를 함께 처리할 때 문장 간 의미 유사도를 계산하거나, 요약 결과에 대한 질의응답의 입력 문장 인코딩 등에 활용할 수 있다. XLM-R은 별도의 언어 토큰 없이도 입력 ID로 언어를 구별할 수 있도록 훈련되었다 (XLM-RoBERTa).
-
mBART-50: Facebook의 다국어 번역용 Seq2Seq 모델. 50개 언어 지원. 요약 목적보다는 번역에 최적화되어 있으나, fine-tune하여 다국어 요약에도 사용할 수 있다. mBART-50을 이용하면 영어 판례와 한국어 법령 번역을 순차적으로 처리해 요약할 수 있다.
따라서 두 언어를 모두 처리해야 할 경우, 단일 mT5 모델로 한글/영문 요약을 모두 수행하거나, 필요에 따라 한국어 전용 모델(KoBART 등)과 영어 모델(BART/Pegasus)을 병행해도 된다. 멀티모델 대신 하나의 Hugging Face Pipeline을 유지하고 싶다면 pipeline("summarization", model="google/mt5-base")처럼 mT5 파인튜닝 모델을 지정하면 된다. 필요하면 파이프라인 호출 시 텍스트 앞에 언어별 접두어(prefix)를 붙여 언어를 명시할 수도 있다.
웹서비스 배포 아키텍처
웹서비스는 Hugging Face 모델을 서빙할 수 있는 서버 인프라 위에 구축한다. 대표적인 구조로는 서버리스(Serverless) 아키텍처와 호스티드(MaaS) 아키텍처가 있다.
-
서버리스 (FastAPI + AWS Lambda + API Gateway): FastAPI를 이용해 간단한 REST API 서버 코드를 작성한 뒤, 이를 Docker 컨테이너로 패키징하여 AWS Lambda에 배포하는 방식이다. AWS API Gateway가 외부 요청을 받아 Lambda 함수를 호출하고, Lambda에서 Transformers 모델로 추론한 결과를 반환한다 (Deploy a serverless ML inference endpoint of large language models using FastAPI, AWS Lambda, and AWS CDK | AWS Machine Learning Blog). AWS Lambda는 쿠버네티스나 서버 프로비저닝 없이 자동 확장되므로 관리 부담이 적다 (Deploy a serverless ML inference endpoint of large language models using FastAPI, AWS Lambda, and AWS CDK | AWS Machine Learning Blog). FastAPI는 비동기/고성능 웹 프레임워크로, 자동 API 문서화 등이 내장되어 있어 간편하다 (Deploy a serverless ML inference endpoint of large language models using FastAPI, AWS Lambda, and AWS CDK | AWS Machine Learning Blog) (Deploy a serverless ML inference endpoint of large language models using FastAPI, AWS Lambda, and AWS CDK | AWS Machine Learning Blog). 또한 AWS CDK를 사용하면 인프라(함수, API Gateway, IAM 역할 등)를 코드로 자동화할 수 있다 (Deploy a serverless ML inference endpoint of large language models using FastAPI, AWS Lambda, and AWS CDK | AWS Machine Learning Blog).
이 아키텍처 예시는 AWS 공식 블로그에도 소개되었는데, Lambda 함수 내부에서 Hugging Face 모델을 실행하고 Amazon EFS에 모델 파일을 캐싱하여 레이턴시를 줄인다 (Hosting Hugging Face models on AWS Lambda for serverless inference | AWS Compute Blog). (그림 참조)
(Hosting Hugging Face models on AWS Lambda for serverless inference | AWS Compute Blog)*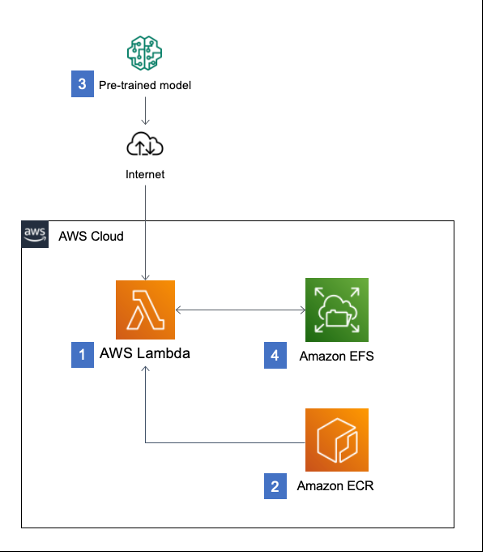
그림. AWS Lambda 기반 서버리스 요약 서비스 아키텍처 예시 (모델은 Lambda 컨테이너에서 실행되고 EFS에 캐시되어 추론 속도가 개선됨 (Hosting Hugging Face models on AWS Lambda for serverless inference | AWS Compute Blog))*
graph LR; Client-->APIGateway-->Lambda; Lambda-->ECR[모델 이미지(ECR)]; Lambda-->EFS[모델 캐시(EFS)]; -
AWS SageMaker: Hugging Face와 통합된 SageMaker도 좋은 옵션이다. SageMaker의 실시간 추론(Real-time Endpoint) 또는 서버리스 추론(Serverless Inference)을 사용하면 모델 서버를 운영할 수 있다. 예를 들어 Hugging Face 제공 DL 컨테이너(DLC)를 사용해 모델을 SageMaker에 올린 뒤,
huggingface.transformers로 추론 코드를 작성하면 된다. SageMaker는 인스턴스 프로비저닝, Autoscaling, 모니터링을 지원한다 (Host Hugging Face transformer models using Amazon SageMaker Serverless Inference | AWS Machine Learning Blog) (Host Hugging Face transformer models using Amazon SageMaker Serverless Inference | AWS Machine Learning Blog). 특히 서버리스 추론은 (사용량 예측이 어려운 경우) 자동 확장되며, 요청이 없으면 비용이 발생하지 않는다 (Host Hugging Face transformer models using Amazon SageMaker Serverless Inference | AWS Machine Learning Blog).
SageMaker로 배포할 경우 FastAPI 없이도deployAPI 호출만으로 엔드포인트를 생성할 수 있으며, API Gateway → Lambda 대신 SDK나 HTTP로 직접 호출할 수 있다. -
그 외: Hugging Face Hub Inference API, Amazon EKS/ECS 컨테이너 형태, AWS Elastic Beanstalk 등도 가능하다. 하지만 목표가 서버리스 운영이라면 Lambda/FastAPI와 SageMaker 두 가지가 대표적이다.
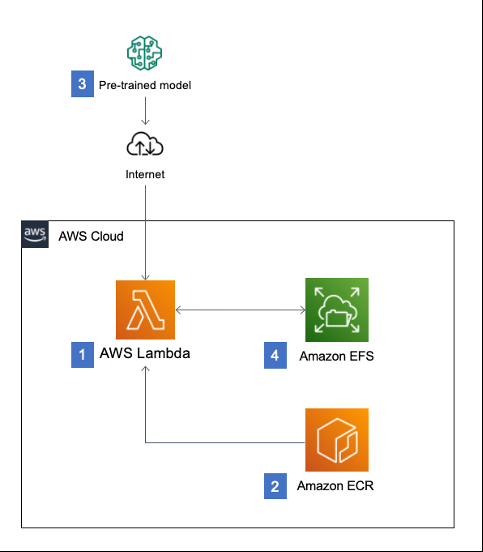
종합하면, 클라우드 배포 구성 예시는 다음과 같다:
| 구성 요소 | 기능 설명 |
|---|---|
| FastAPI (Python) | REST API 서버 구현. 경량이며 문서화 지원 ([Deploy a serverless ML inference endpoint of large language models using FastAPI, AWS Lambda, and AWS CDK |
| AWS API Gateway | 외부 요청 엔드포인트. Lambda 트리거. |
| AWS Lambda | Hugging Face Transformers 모델 구동. 컨테이너 이미지(모델 포함) 사용. 최초 호출 시 모델 로딩, 이후 EFS 캐시에 저장 ([Hosting Hugging Face models on AWS Lambda for serverless inference |
| Amazon EFS (옵션) | 모델 파일 캐시. Lambda 함수에 장착하여 재사용. |
| Amazon SageMaker | 대안: 모델을 SageMaker endpoint에 배포하여 안정적인 실시간 추론 제공 ([Host Hugging Face transformer models using Amazon SageMaker Serverless Inference |
| CI/CD (AWS CDK 등) | 인프라 프로비저닝 자동화. 테라폼/CloudFormation/CDK 사용 권장. |
AWS 블로그에서는 FastAPI+Lambda+CDK 예시를 상세히 안내하며, 시작된 Lambda 함수가 모델을 다운받아 EFS에 저장하는 방식을 제시했다 (Hosting Hugging Face models on AWS Lambda for serverless inference | AWS Compute Blog). 또한 SageMaker 블로그에 따르면 서버리스 엔드포인트 구축은 인프라 관리 부담을 줄여주며, 비용 최적화에 유리하다 (Host Hugging Face transformer models using Amazon SageMaker Serverless Inference | AWS Machine Learning Blog).
확장 가능한 고급 기능 제안
기본 요약 서비스 외에 다음과 같은 고급 기능을 제안할 수 있다:
- 판례/법령 검색 엔진: 축적된 판례 및 법령 텍스트를 문장 임베딩(예:
sentence-transformers)으로 벡터화하여 Elasticsearch나 FAISS에 색인한다. 사용자 쿼리와 임베딩 유사도를 계산해 관련 판례를 검색・제시한다. Hugging Face의sentence-transformers/all-mpnet-base-v2같은 모델로 문서 유사도를 구할 수 있다. 예:semantic-search또는feature-extraction파이프라인을 활용해 문장 유사도를 계산하고, 상위 결과를 리턴한다. - 유사 판례 연결: 특정 판례 요약 시, 유사 판례 목록이나 인용된 판례 링크를 함께 제공한다. 예를 들어 요약된 판례의 주요 키워드를 파싱하여, 관련 판례 데이터베이스를 쿼리하거나 문장 임베딩 검색으로 유사 판례를 찾아준다.
- 법령 비교 분석: 개정 전후의 법령 조문이나 유사 법률 조항을 비교하여 차이점을 강조해준다. 예를 들어 두 텍스트를 입력으로 받아 문장별 diff를 계산하거나, 두 텍스트를 모두 입력으로 요약시켜 주요 변경사항만 도출한다. 또는
pipeline("question-answering")으로 “이 두 법령의 주요 차이는?” 같은 질문을 생성할 수 있다. - 질의응답 기반 안내: 요약문과 관련해 사용자가 질문할 수 있는 대화형 질문응답(Q&A) 기능을 제공한다. Hugging Face
pipeline("question-answering")에 판례 전문을 넣어, 요약에 대한 구체적 질의(예: “이 판례의 판결 이유는 무엇인가?”)에 답할 수 있다. 또는 RAG(Retrieval-Augmented Generation) 기법을 적용해 요약 결과 및 관련 법령을 참고하여 구체적 답변을 생성한다. - 법률 피드백 생성: 요약 내용과 관련한 조언·권고 사항을 생성한다. 예를 들어 “위 판례 요약을 바탕으로 우리 설계안이 법적 요건을 충족하는지” 묻는 경우, 사전 학습된 LLM(예: GPT-3/4 API 또는 Llama-2 기반)으로 요약에 근거한 조언을 생성할 수 있다. Hugging Face Transformers의 causalLM을 활용하거나, Fine-tuning된 요약+피드백 모델을 구현할 수도 있다.
이외에도 자동 태깅(법조문 번호 태그), 키워드 하이라이트, 유사 법률 조문 매핑 등 도메인 특화 기능을 추가하면 서비스 가치를 높일 수 있다.
결론
위와 같이 Hugging Face의 다양한 LLM과 파이프라인을 활용하여 건축·조경 법률·판례 요약 웹서비스를 구성할 수 있다. 먼저 BERT/GPT/T5 계열 모델의 구조를 이해하고, 요약에 적합한 인코더-디코더 모델(Pegasus, BART, T5 계열 등)을 선택한다 (The Transformer model family) (Summarization). 파이프라인 코드를 예시로 도입하여 실제 텍스트 요약을 구현하고 (Summarization), 한국어·영어 지원을 위해 mT5나 XLM-R 같은 다국어 모델을 적절히 활용한다 (mT5) (XLM-RoBERTa). 서비스 배포는 FastAPI+AWS Lambda(또는 SageMaker)를 통해 서버리스로 구현하고 (Deploy a serverless ML inference endpoint of large language models using FastAPI, AWS Lambda, and AWS CDK | AWS Machine Learning Blog) (Hosting Hugging Face models on AWS Lambda for serverless inference | AWS Compute Blog), 확장 기능(검색·비교·Q&A 등)을 추가하면 실무 활용도가 높은 시스템이 될 것이다.
참고문헌:
📘 LLM 모델별 원리 및 구조
| 출처 | 내용 요약 |
|---|---|
| Hugging Face - BERT | BERT는 bidirectional Transformer로, 마스킹된 단어를 예측하며 양방향 문맥을 학습하고 문장 관계 추론에도 사용됨 |
| Hugging Face - GPT-2 | GPT-2는 decoder-only 구조로 다음 단어 예측에 특화. 미래 토큰을 마스킹하여 자연어 생성에 사용됨 |
| Hugging Face - The Transformer model family | BART, Pegasus, T5 등 다양한 트랜스포머 모델들의 구조 및 사전학습 기법 설명 (in-filling, gap sentence generation 등) |
| Hugging Face - mT5 | mT5는 101개 언어를 지원하는 multilingual T5. 사전학습만 되어 있어 파인튜닝이 필요하며, 다국어 요약에 적합 |
| Hugging Face - XLM-R | XLM-R은 100개 언어에 대해 학습된 다국어 인코더 기반 모델로, 문장 임베딩이나 유사도 추출에 적합 |
📝 요약 기능과 사용 예시
| 출처 | 내용 요약 |
|---|---|
| Hugging Face - Summarization 파이프라인 | pipeline("summarization")을 이용한 요약 구현 방법 제공. 다양한 모델(BART, T5 등)에서 사용 가능 |
| Hugging Face - KoBART 요약 모델 | 한국어 요약에 특화된 사전학습 모델로, BART 구조 기반. 실무 예제 코드 제공 |
🧠 법률 요약 파인튜닝 예시
| 출처 | 내용 요약 |
|---|---|
| Julien Simon - FLAN-T5 법률 요약 실습 | FLAN-T5 모델을 법률 데이터로 파인튜닝한 실제 예시. Hugging Face 모델을 SageMaker에서 배포 및 평가하는 과정 포함 |
☁️ AWS 서버리스 배포 (FastAPI, Lambda, SageMaker)
| 출처 | 내용 요약 |
|---|---|
| AWS Machine Learning Blog - FastAPI + Lambda + CDK 배포 | FastAPI 서버를 Docker로 구성하여 AWS Lambda에 배포하고, API Gateway로 외부 접근 처리. CDK를 통한 자동화 |
| AWS Compute Blog - Hugging Face 모델을 Lambda에 배포 | Lambda + EFS 구조로 모델 캐싱. Hugging Face 모델을 Lambda에서 빠르게 구동하기 위한 구조 제안 |
| AWS ML Blog - SageMaker Serverless Inference | 서버리스 추론 환경을 통해 자동 확장 및 비용 최적화 가능. Hugging Face DLC를 SageMaker에 바로 배포 가능 |
