Motivation
- Graph Collaborative Filtering 자체의 data sparisty / noise 문제
- 지금까지의 다른 메소드들만 봐도 direct U-I간 interaction만 사용하지, 정작 high-order relations (ex. user or item similarity)는 활용하지 않고 있음. SGL이나 SimGCL도 graph augmentation을 썼냐 안썼느냐만 다르지, 결국 message passing, neighbor aggregation, state updating 할 때 결국 direct U-I interaction만 활용하는 셈임 유저간의/ 아이템간의 high-order neighbor relation 또한 중요하기 때문에 이를 활용한 contrastive framework를 만들거임!
Method
Summary
- Data Augmentation: Feature Clustering
- Contrast Type: Node-Cluster
- Contrastive Objective: InfoNCE
- Training Scheme: Joint learning
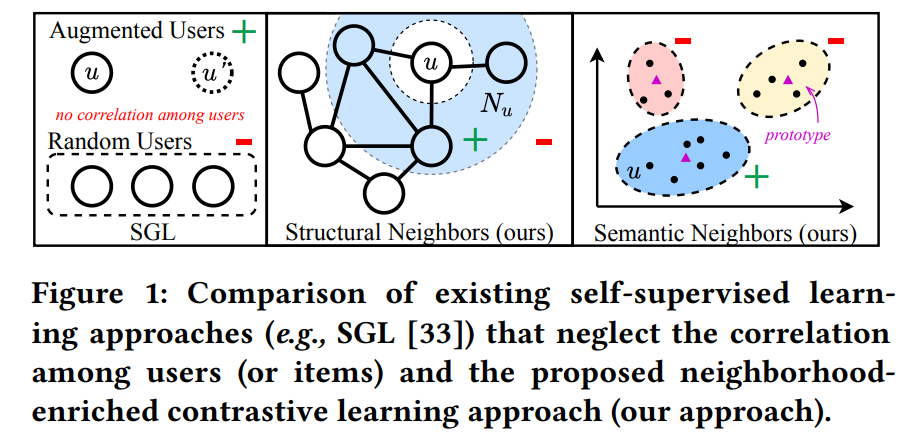
- Contrastive pairs (pos/neg) 구성
모든 graph augmentation 된 다른 그래프에 대해 GNN을 거쳐 새로운 embedding을 만들어야 하는 SGL과 달리, SimGCL과 NCL은 한번 L-layer의 GNN을 통과해서 만들어진 representation(the weighted sum of l-hop structrual neighbors of each node)을 가지고 여기에 노이즈를 가한다던가 다른 무언가를 하여 contrastive pair를 만들기 때문에 더 efficient함
-
Structure-Contrastive; Structural Neighbors
- Structrual Neighbors: 그래프상에서 high-order path로 연결된 homogeneous 노드 사이의 cluster
- Positive pair: 노드 i의 원래 임베딩과, 짝수-layer GNN을 통과한 (짝수-hop 거리에서부터 aggregation 된) 노드 i의 업데이트된 임베딩
짝수를 쓰는 이유: 짝수거리에 있는 노드들이 모두 homogeneous하기 때문에 potential neighbors within users or items를 추출하는데에 이득임 (Bipartite 그래프의 특징)
짝수를 쓰더라도 작으면 작을수록 local structure에 따라 가장 긴밀한 neighbor를 쓰기 때문에 더 좋음 - Negative pair: 짝수거리 밖에 있는 모든 homogeneous 노드들
- InfoNCE loss
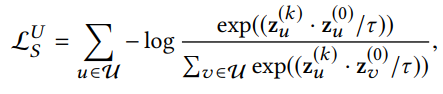
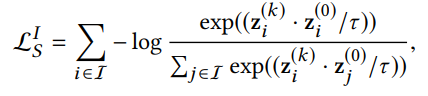
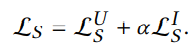 cf. 수식에서 k는 짝수이며, 는 k번째 GNN layer의 normalized output임
cf. 수식에서 k는 짝수이며, 는 k번째 GNN layer의 normalized output임
-
Prototype-Contrastive; Semantic Neighbors
- Semantic Neighbors: 그래프상에서 high-order로도 연결되어 있지 않지만, 비슷한 특성(for item nodes) 또는 비슷한 선호도(for user nodes)를 갖는 homogeneous 노드 cluster
- Positive pair: Base GNN 모델을 통과해서 나온 representation에서 homogeneous 노드끼리 K-means clustering하고 각 cluster의 centroid를 해당 노드 community의 prototype으로 간주함. 그 경우 노드 i의 임베딩과, 자기가 속한 cluster의 prototype을 positive pair로 둠
- Negative pair: 그 외 k-1개 cluster에 대한 prototypes들
- InfoNCE loss
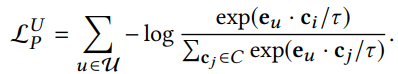
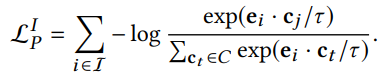
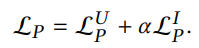 cf. 수식에서 는 user u의 prototype임
cf. 수식에서 는 user u의 prototype임 - Clustering 알고리즘은 jointly end-to-end 최적화가 되지 않으므로 EM 알고리즘을 통해 최적화함 (그냥 알고만 있으라고.. 중요하진 않음)
-
전체 학습 objective
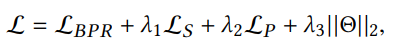 cf. 전체 학습가능한 파라미터는 Base GNN 모델의 initial node embedding 뿐이 없다는것!
cf. 전체 학습가능한 파라미터는 Base GNN 모델의 initial node embedding 뿐이 없다는것!
Experiments
-
Benchmark Datasets: MovieLens-1M(ML-1M), Yelp, Amazon Books, Gowalla, Alibaba-iFashion
-
Evaluation Metrics: Recall@K, NDCG@K (K=10,20,50), all-ranking protocol (ranks all the candidate items that the user has not interacted with)
-
Analysis
- NDCG@10, NDCG@20, NDCG#50을 봤을 때, 가장 성능 향상이 높은 메트릭이 NDCG@10인걸 보면 NCL은 상위 랭킹에서 추천 아이템을 더 잘 맞춘다는 것을 알 수 있고, 이는 실세계 추천 시나리오에서 desirable함
- NCL은 sparser한 데이터(ML-1M, Yelp)에서 더 높은 성능 향상을 이끌어내는 것을 확인할 수 있음
- 많은 interaction record가 없는 sparse한 유저에 대해 NCL이 다른 방법론들보다 더 큰 성능 향상을 보임
- InfoNCE의 temperature 는 sparse한 데이터셋에서 작을수록 더 좋음
- SimGCL에 제기되었듯이, feature 분포가 더 uniform하면 할수록 추천 성능이 좋아지는데, 이와 마찬가지로 NCL의 방법이 more uniformity를 야기하는 것으로 드러남
