
들어가며
04미니프로젝트가 끝났다.
지금까지의 프로젝트들(01,02,03)은 AI 쪽 로직이 중심이었다. Multi-Agent, LangGraph, RAG 파이프라인 같은 프로젝트였다. 이번 프로젝트에서는 프론트엔드 개발 전체를 진행했다. React, OpenAI API 연동, 이미지 처리, 컴포넌트 설계, 그리고 팀 코드 병합까지.
이번 회고록엔 "왜 이 프로젝트가 필요한가"라는 배경부터, 실제로 내가 고민하고 결정하고 부딪혔던 기술적인 내용들까지 최대한 상세하게 남겨보려 한다.
프로젝트 배경 — 왜 이걸 만들어야 하나

책 표지, 그게 그렇게 중요한가?
프로젝트를 시작할 때 강사님이 던진 질문이 있었다.
"책 표지 디자인이 왜 중요할까요?"
처음엔 그냥 예쁘면 되는 거 아닌가 하고 시작하려고 했다. 비슷한 서비스를 개발하고 여러 사이트를 방문하고 내가 조사한 책 표지에 실제 수치를 보고 나서 생각이 바뀌었다. 표지 디자인은 CTR(Click Through Rate, 클릭률), 구매 전환율, SNS 공유율에 직접적인 영향을 준다. 독자는 내용보다 표지를 먼저 본다. 첫인상이 구매를 결정한다.
텍스트 기반 콘텐츠(책 내용)
↓
표지 디자인
"장르와 메시지를 시각적으로 전달"
↓
독자(User)
"끌리는 표지일수록 클릭하고 싶다"
↓
CTR · 구매 전환율 · SNS 공유율 증가그런데 현실적으로 개인 작가나 소규모 창작자가 전문 디자이너에게 표지를 맡기기는 어렵다. 비용도 비용이지만, 수정 피드백을 주고받는 과정도 길다. 감성적인 의도를 언어로 전달하는 것 자체가 어렵기도 하다.
서비스 컨셉 — "걷기가 서재"
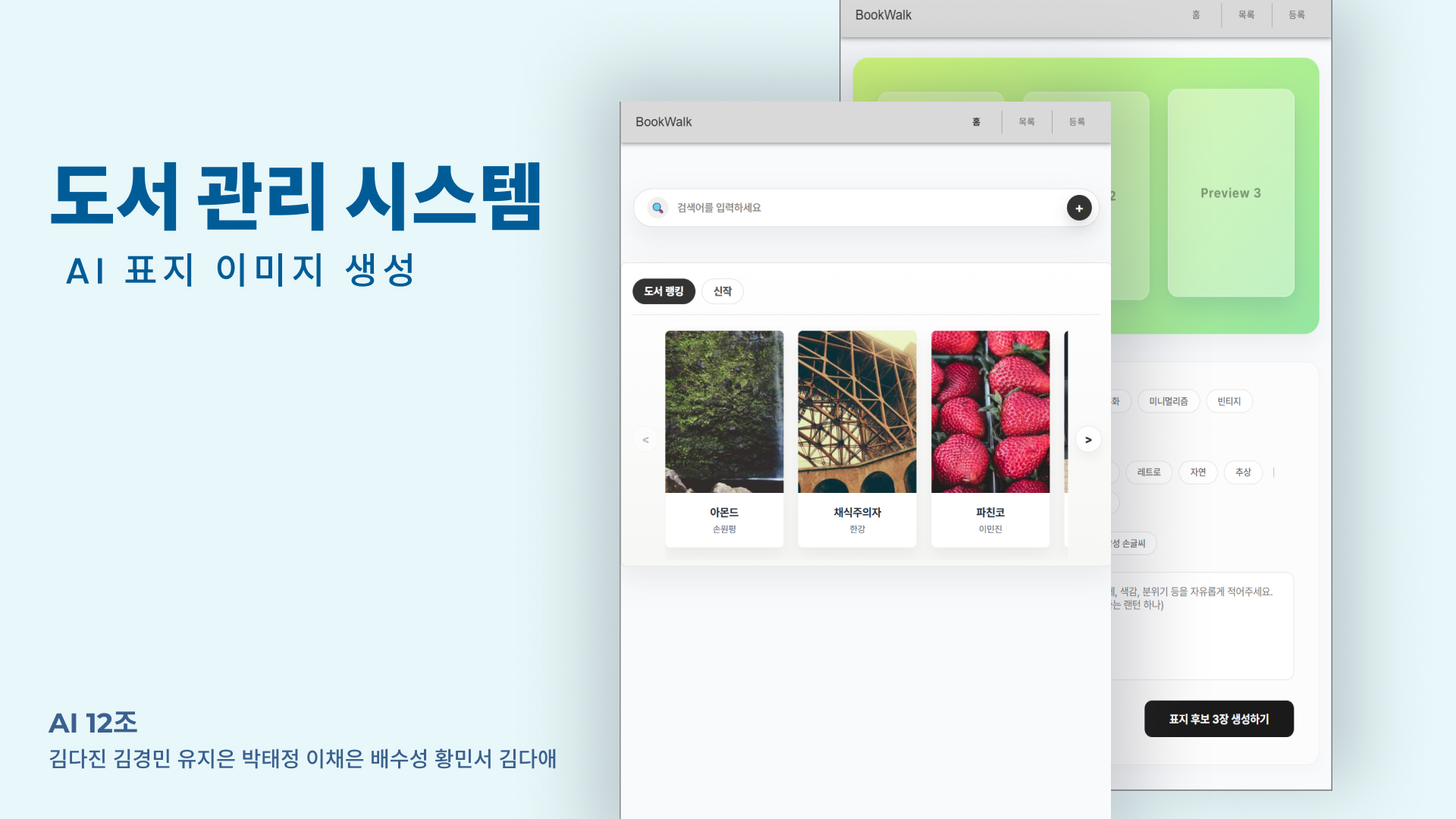
이번 프로젝트의 도메인은 "걷기가 서재" 라는 가상의 국내 최대 독서 플랫폼이다. 그 안에 있는 "작가의 산책" 서비스를 구현하는 것이 목표였다.
누구나 작가가 되어 자유롭게 글을 집필하고 공개할 수 있는 창작 플랫폼. 단, 기존 플랫폼과 달리 AI 표지 제작을 지원한다.
이야기가 그대로 표지에 닿도록. 작가의 감성을 AI가 시각화해준다는 컨셉이었다. 텍스트 기반 콘텐츠를 입력하면 AI가 거기에 어울리는 표지를 자동으로 만들어주는 것이다.
이 맥락을 이해하고 나서야 단순한 CRUD 앱이 아닌, 왜 이 기능이 의미 있는지 납득이 됐다. 개발하는 내내 이 목적의식이 있었기 때문에 UI 결정을 팀원들과의 소통하는데 있어 하나하나에 더 신중해질 수 있었던 것 같다.
프로젝트 개요
기술 스택
| 분류 | 기술 |
|---|---|
| Frontend | React 19 · Vite · fetch |
| 데이터 | json-server (로컬 REST API) |
| AI | OpenAI API (GPT Image 2) |
| UI 라이브러리 | MUI (Material UI) |
| 협업 | GitHub |
백엔드는 따로 없다. json-server가 db.json을 읽어서 GET/POST/PATCH/DELETE REST API를 자동으로 제공해주는 구조다. 추후 백엔드 미니프로젝트에서 이 자리를 Spring Boot로 교체할 예정이다.
전체 데이터 흐름은 아래와 같다.
브라우저(React)
│
├── GET/POST/PATCH/DELETE ──▶ json-server(localhost:3000) ──▶ db.json
│
└── POST + prompt ──────────▶ OpenAI GPT Image 2
◀── b64_json 응답 ──────────────────────
↓
React 내부에서 b64_json → Data URL 변환
↓
PATCH books/:id(coverImageUrl) ──▶ json-server내 역할
총 8명 팀이었고, 나는 전체적인 UI 개발을 담당했다. 구체적으로는:
- 프로토타입 UI 설계 및 구현 (전체 라우팅 구조)
- OpenAI LLM 호출 연결 코드 전체 설계 및 구현
- CSS 기본 틀 + 후에 만들어놓은 CSS를 받아 수정
- 팀원들이 개발한 코드를 직접 병합 (PR 없이 - main에 올려놓고 했어야지..)
- 1개 프롬프트 입력 → 3개 이미지 생성 처리 설계
- 검색바, 리스트 필터링, 정렬 디테일 관리
- json-server 예외처리 전반
구현 세부사항
1. 프로토타입 UI 설계 — 팀이 시작할 수 있는 기반 만들기
제일 먼저 한 건 팀이 개발을 시작할 수 있는 공통 기반을 만드는 것이었다. 각자가 맡은 파트를 개발하려면 라우팅 구조와 공통 레이아웃이 먼저 잡혀있어야 한다. 이 부분이 없으면 팀원들이 각자 만든 컴포넌트를 나중에 합칠 때 충돌이 훨씬 커진다.
App.jsx에 React Router 기반 라우팅을 잡았다.
function App() {
return (
<BrowserRouter>
<Header />
<Box component="main" sx={{ pt: "64px" }}>
<Routes>
<Route path="/" element={<Home />} />
<Route path="/books" element={<BookListRoute />} />
<Route path="/books/new" element={<BookFormRoute />} />
<Route path="/books/:id" element={<BookDetailRoute />} />
<Route path="/books/:id/edit" element={<BookEditRoute />} />
<Route path="/books/:id/cover-editor" element={<BookCoverEditor />} />
</Routes>
</Box>
</BrowserRouter>
)
}각 Route 컴포넌트(BookListRoute, BookDetailRoute 등)는 useNavigate와 useParams를 내부에서 처리하고, 실제 페이지 컴포넌트에는 네비게이션 콜백만 prop으로 내려주는 구조로 설계했다.
// 라우팅 로직을 래퍼에서 처리 → 페이지 컴포넌트는 라우터 의존성 없음
function BookDetailRoute() {
const navigate = useNavigate()
const { id } = useParams()
return (
<BookDetail
id={id}
onBack={() => navigate('/books')}
onEdit={() => navigate(`/books/${id}/edit`)}
onEditCover={() => navigate(`/books/${id}/cover-editor`)}
onDeleted={() => navigate('/books')}
/>
)
}이 패턴의 장점은 BookDetail 컴포넌트 자체가 react-router-dom에 의존하지 않는다는 것이다. 나중에 라우팅 구조가 바뀌어도 페이지 컴포넌트를 건드릴 필요가 없다.
MUI <Box component="main" sx={{ pt: "64px" }}> 로 고정 헤더(AppBar) 높이만큼 콘텐츠 영역을 밀어주는 방식도 여기서 잡았다. 이게 없으면 헤더 뒤에 첫 번째 콘텐츠가 숨어버린다.
2. 도서 목록 페이지 — 필터링과 정렬 설계
도서 목록에서 기대한 기능들은 생각보다 많았다.
- 장르별 사이드바 필터
- 즐겨찾기 탭
- 제목/저자 실시간 검색
- 등록순/제목순/가격순 정렬
- 그리드/리스트 뷰 전환
이 모든 걸 하나의 컴포넌트에서 처리해야 했다. 상태 설계부터 시작했다.
const [books, setBooks] = useState([]) // 전체 데이터 (서버에서 한 번만 fetch)
const [genre, setGenre] = useState('ALL') // 장르 필터
const [query, setQuery] = useState('') // 검색어
const [view, setView] = useState('grid') // 뷰 모드
const [favoriteIds, setFavoriteIds] = useState(() => readFavoriteIds()) // 즐겨찾기
const [sortBy, setSortBy] = useState('register') // 정렬 기준books는 최초 fetch 이후 서버 재요청 없이 클라이언트에서 모든 필터링/정렬을 처리한다. json-server가 쿼리 파라미터를 지원하긴 하지만, 검색어가 바뀔 때마다 API를 치는 건 비효율적이다. 전체를 한 번 받아서 useMemo로 파생 상태를 계산하는 방식이 더 낫다.
// 필터링: 장르 + 즐겨찾기 + 검색어
const filtered = useMemo(() => {
const lowerQuery = query.toLowerCase()
return books.filter((book) => {
const genreOk =
genre === 'ALL' ||
(genre === 'FAVORITES'
? favoriteIds.has(String(book.id))
: book.genre === genre)
const queryOk =
!query ||
book.title?.toLowerCase().includes(lowerQuery) ||
book.author?.toLowerCase().includes(lowerQuery)
return genreOk && queryOk
})
}, [books, genre, favoriteIds, query])
// 정렬: filtered 결과 위에서
const sorted = useMemo(() => {
const arr = [...filtered]
if (sortBy === 'title')
return arr.sort((a, b) => a.title?.localeCompare(b.title || '', 'ko'))
if (sortBy === 'price')
return arr.sort((a, b) => (a.price || 0) - (b.price || 0))
// 기본: 등록순 (최신 순)
return arr.sort(
(a, b) => toTime(b.createdAt) - toTime(a.createdAt) || Number(b.id) - Number(a.id)
)
}, [filtered, sortBy])filtered와 sorted를 useMemo 두 단계로 분리한 이유가 있다. 필터링은 books, genre, query에 의존하고, 정렬은 filtered, sortBy에만 의존한다. 한 덩어리로 합치면 sortBy만 바뀌어도 필터링 로직이 다시 실행된다. 분리하면 각각 필요한 시점에만 재계산된다.
즐겨찾기 탭 — localStorage 동기화 문제
즐겨찾기는 localStorage에 저장한다. 문제는 탭이 여러 개 열려있을 때 A탭에서 즐겨찾기를 추가하면 B탭에는 반영이 안 된다는 것이다.
useEffect(() => {
const refresh = () => setFavoriteIds(readFavoriteIds())
window.addEventListener('focus', refresh) // 탭 포커스 복귀 시
window.addEventListener('storage', refresh) // 다른 탭에서 storage 변경 시
window.addEventListener('bookFavoriteChange', refresh) // 커스텀 이벤트
return () => {
window.removeEventListener('focus', refresh)
window.removeEventListener('storage', refresh)
window.removeEventListener('bookFavoriteChange', refresh)
}
}, [])세 가지 이벤트를 구독했다.
focus: 다른 탭에서 돌아왔을 때 최신 상태로 갱신storage: 같은 브라우저 다른 탭에서 localStorage 변경 감지bookFavoriteChange: 같은 탭 내에서 즐겨찾기 토글 시 dispatchEvent로 알림
이 세 가지를 다 처리하지 않으면 어느 한 경우에서 즐겨찾기가 화면에 즉시 반영되지 않는 버그가 생긴다.
3. Main 페이지 — 검색바와 도서 랭킹 캐러셀
Main 페이지는 구조가 단순해 보이지만, 안에 들어있는 설계 결정들이 꽤 많다. SearchBar와 BookSection 두 컴포넌트로 구성됐고, 둘 다 내가 전담으로 만들었다.
SearchBar — 상태를 URL에 넘기는 이유
검색어를 입력하고 엔터를 누르면 도서 목록 페이지로 이동한다. 단순해 보이지만 구현 방식에서 한 번 고민했다.
const handleSearch = () => {
if (query.trim()) {
navigate(`/books?search=${encodeURIComponent(query)}`)
}
}검색어를 컴포넌트 상태로 넘기지 않고, URL 쿼리 파라미터로 넘긴다. 이렇게 하면 두 가지 이점이 있다.
첫째, 검색 결과 URL이 공유 가능해진다. /books?search=해리포터 를 그대로 누군가에게 주면 같은 결과를 볼 수 있다.
둘째, 도서 목록 페이지에서 useSearchParams로 읽으면 SearchBar가 어디 있든 상관없이 검색어를 받을 수 있다. 컴포넌트 간 props 연결이나 전역 상태가 필요 없다.
// BookListPage에서 URL 파라미터 수신
const [searchParams] = useSearchParams()
const [query, setQuery] = useState(searchParams.get('search') || '')
useEffect(() => {
setQuery(searchParams.get('search') || '')
}, [searchParams])Header에도 같은 검색바가 있는데, 거기서도 동일하게 URL로 넘기니까 도서 목록 페이지가 알아서 처리한다. encodeURIComponent로 한글 검색어가 URL에서 깨지지 않도록 처리한 것도 이 부분이다.
BookSection — 캐러셀과 탭 설계
도서 랭킹과 신작 탭을 제공하는 캐러셀 슬라이더다.
데이터는 이렇게 가공한다.
// 랭킹: 조회수 높은 순 최대 60권
const rankingBooks = [...data]
.sort((a, b) => (b.viewCount || 0) - (a.viewCount || 0))
.slice(0, 60)
// 신작: 최근 1개월 이내 출간, 최신 순
const now = new Date()
const oneMonthAgo = new Date()
oneMonthAgo.setMonth(now.getMonth() - 1)
const newBooks = [...data]
.filter((book) => {
if (!book.pubDate) return false
const pubDate = new Date(book.pubDate)
return pubDate >= oneMonthAgo && pubDate <= now
})
.sort((a, b) => new Date(b.pubDate) - new Date(a.pubDate))
.slice(0, 60)원본 배열을 건드리지 않도록 [...data] 스프레드로 복사한 뒤 정렬했다. 정렬은 원본을 변경하기 때문에 이걸 빠뜨리면 data가 조용히 바뀐다.
슬라이더는 CSS transform 방식으로 구현했다. 라이브러리 없이.
<div
className={styles.cardList}
style={{ transform: `translateX(calc(-${currentIndex} * (25% + 6px)))` }}
>
{currentBooks.map((book) => (...))}
</div>-${currentIndex} * (25% + 6px) — 카드 4개가 한 화면에 보이니 각 카드 너비가 25%고, 여기에 카드 간 gap(6px)을 더해서 정확히 한 칸씩 이동한다.
탭 전환 시 currentIndex를 0으로 리셋하는 것도 중요하다.
useEffect(() => {
setCurrentIndex(0)
}, [activeTab])이게 없으면 랭킹 탭에서 5번째 카드를 보다가 신작 탭으로 전환했을 때 신작이 5번째부터 시작한다. 사용자 입장에선 당황스러운 경험이다.
커버 이미지가 없는 책은 fallback으로 처리했다.
src={book.coverImageUrl || `https://picsum.photos/seed/${book.id}/200/300`}picsum.photos에 seed로 책 id를 넘기면 항상 같은 책에 같은 랜덤 이미지가 나온다. AI 표지 생성 전까지 빈 박스 대신 그럴듯한 이미지를 보여줄 수 있어서 UI가 훨씬 자연스러워 보인다.
키보드 접근성도 챙겼다.
onKeyDown={(e) => {
if (e.key === 'Enter' || e.key === ' ') {
e.preventDefault()
onBookClick?.(book)
}
}}마우스 없이 탭으로 이동해서 Enter/Space로 클릭할 수 있도록. 사소하지만 role="button" + tabIndex={0} + onKeyDown 세트가 없으면 키보드 사용자는 카드를 클릭할 수 없다.
4. Detail 페이지 — 가장 많은 설계 결정이 들어간 컴포넌트
BookDetail은 이번 프로젝트에서 코드량이 가장 많은 컴포넌트다(486줄). 그만큼 설계에서 고민한 것도 많았다.
인라인 스타일 선택 — CSS Module을 안 쓴 이유
다른 컴포넌트들은 CSS Module(.module.css)을 쓰는데, BookDetail은 인라인 스타일 객체를 썼다.
const s = {
page: { minHeight: 'calc(100vh - 64px)', background: '#eeece6' },
topbar: { background: '#fff', borderBottom: '0.5px solid rgba(0,0,0,0.12)', ... },
hero: { background: '#fff', borderRadius: 14, display: 'grid', gridTemplateColumns: '260px minmax(0, 1fr)', ... },
// ...
}선택한 이유가 있다. 이 컴포넌트는 coverColor처럼 런타임에 동적으로 결정되는 스타일이 있다. 장르에 따라 표지 배경색이 달라진다.
// 함수형 스타일 — 인자에 따라 다른 스타일 반환
coverBox: (bg) => ({
height: 360,
background: bg, // 장르별 색상이 런타임에 주입
display: 'flex',
...
}),
favoriteBtn: (active) => ({
background: active ? '#fff7e8' : '#fff',
border: `0.5px solid ${active ? '#f59e0b' : 'rgba(0,0,0,0.18)'}`,
color: active ? '#f59e0b' : '#9b9b95',
...
}),CSS Module에서 이걸 하려면 클래스를 조건부로 바꾸거나 CSS 변수를 써야 한다. 인라인 스타일로 함수형으로 처리하면 상태에 따라 스타일이 직접 바뀐다는 게 코드에서 명확하게 보인다.
<div style={s.coverBox(coverColor.bg)}>
<button style={s.favoriteBtn(favorite)}>coverColor는 useMemo로 계산한다.
const coverColor = useMemo(() => getCoverColor(book?.genre), [book?.genre])book?.genre가 바뀔 때만 재계산된다. 옵셔널 체이닝(?.)으로 book이 null인 초기 로딩 상태에서도 에러 없이 처리된다.
조회수 업데이트 — 300ms 딜레이를 넣은 이유
상세 페이지에 들어오면 조회수가 1 증가한다. 구현이 생각보다 까다로웠다.
const res = await fetch(`${API}/${id}`)
const data = await res.json()
const currentViews = Number(data.viewCount || 0)
const nextViews = currentViews + 1
setBook(data)
setViews(nextViews) // UI는 즉시 +1 반영
// 실제 PATCH는 300ms 후에
setTimeout(() => {
fetch(`${API}/${id}`, {
method: 'PATCH',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ viewCount: nextViews }),
}).catch((e) => {
console.warn('조회수 백그라운드 동기화 락 상태 우회 처리:', e)
})
}, 300)왜 바로 PATCH를 치지 않고 300ms를 기다리나?
json-server는 동시에 여러 요청이 들어오면 파일 락(lock)이 걸린다. GET 요청으로 데이터를 받아오는 것과 동시에 PATCH를 날리면 락 충돌이 생기는 경우가 있었다. 300ms를 기다렸다가 GET이 완전히 끝난 뒤 PATCH를 날리는 방식으로 이 문제를 우회했다.
UI는 setViews(nextViews)로 즉시 갱신해두니 사용자는 딜레이를 느끼지 못한다. 서버 동기화는 백그라운드에서 일어난다. 실패해도 console.warn으로 로그만 남기고 에러를 전파하지 않는다 — 조회수 업데이트 실패가 사용자 경험을 방해해선 안 된다고 판단했다.
삭제 확인 모달 — 브라우저 confirm을 안 쓴 이유
삭제 버튼을 누르면 브라우저 기본 confirm 대화상자 대신, 직접 만든 모달이 뜬다.
const [showDeleteModal, setShowDeleteModal] = useState(false){showDeleteModal && (
<div style={s.overlay}>
<div style={s.modal}>
<div style={s.modalTitle}>도서를 삭제할까요?</div>
<div style={s.modalDesc}>
<strong>{book.title}</strong> 정보가 목록에서 삭제됩니다.
<br />이 작업은 되돌릴 수 없습니다.
</div>
<div style={s.modalActions}>
<button style={s.cancelBtn} onClick={() => setShowDeleteModal(false)}>취소</button>
<button style={s.dangerBtn} onClick={handleDelete}>삭제하기</button>
</div>
</div>
</div>
)}window.confirm()은 브라우저마다 생김새가 다르고, 앱 스타일과 전혀 어울리지 않는다. 커스텀 모달을 쓰면 메시지에 책 제목을 강조(<strong>)해서 "어떤 책을 삭제하는지" 명확하게 보여줄 수 있다. 모달 overlay는 position: fixed, inset: 0으로 화면 전체를 덮고, z-index: 100으로 다른 요소 위에 올라간다.
즐겨찾기 — localStorage와 커스텀 이벤트 연동
즐겨찾기 상태는 localStorage에 저장하고, 변경 시 커스텀 이벤트를 발행한다.
useEffect(() => {
localStorage.setItem(`bookFavorite:${id}`, String(favorite))
window.dispatchEvent(new Event('bookFavoriteChange'))
}, [favorite, id])dispatchEvent로 bookFavoriteChange 이벤트를 발행하면, 도서 목록 페이지에서 이 이벤트를 구독하고 있다가 즐겨찾기 탭을 즉시 갱신한다. BookDetail과 BookListPage가 직접 연결되지 않아도 이벤트를 통해 상태가 동기화된다.
메타 정보 그리드
출판사, 출판일, 가격, 페이지, ISBN, 조회수 6가지 메타 정보를 배열로 관리하고 map으로 렌더링한다.
const meta = [
{ icon: 'ti-building', label: '출판사', value: book.publisher || '-' },
{ icon: 'ti-calendar', label: '출판일', value: book.pubDate ? fmtDate(book.pubDate) : '-' },
{ icon: 'ti-currency-won', label: '가격', value: formatWon(book.price) },
{ icon: 'ti-book-2', label: '페이지', value: book.pages ? `${book.pages.toLocaleString()}쪽` : '-' },
{ icon: 'ti-barcode', label: 'ISBN', value: book.isbn || '-' },
{ icon: 'ti-eye', label: '조회수', value: `${views.toLocaleString()}회` },
]하드코딩으로 6개 블록을 나열하는 것보다 이 방식이 나중에 항목을 추가/제거하기 훨씬 편하다. formatWon으로 가격에 원화 포맷을 적용하고, 값이 없으면 전부 -로 fallback 처리했다.
5. BookCoverEditor — 이번 프로젝트에서 내가 가장 공들인 컴포넌트
AI 표지 생성 에디터다. 사용자가 스타일 옵션을 태그로 고르고, 자유 프롬프트를 입력하면 표지 후보 3장이 나온다. 마음에 드는 걸 선택해서 저장하는 흐름이다.
상태 설계
const [dbBookInfo, setDbBookInfo] = useState({
title: '', author: '', originalContent: '',
})
const [userPrompt, setUserPrompt] = useState('')
const [selectedOptions, setSelectedOptions] = useState({
style: 'miki', background: 'beige', lighting: 'daylight', typography: 'serif',
})
const [apiConfig, setApiConfig] = useState({
model: 'gpt-image-2', quality: 'Medium',
})
const [generatedImages, setGeneratedImages] = useState([null, null, null])
const [isGenerating, setIsGenerating] = useState(false)
const [selectedImageIndex, setSelectedImageIndex] = useState(null)generatedImages를 [null, null, null]로 초기화한 게 포인트다. 슬롯이 항상 3개 존재하고, 생성 전에는 null, 생성 중에는 로딩 스피너, 완료 후에는 이미지를 보여주는 방식이다. 배열 인덱스로 슬롯을 관리하니 UI에서 3개를 일관되게 렌더링하기 쉬웠다.
{[0, 1, 2].map((index) => (
<div
key={index}
className={`${styles.imageSlot} ${selectedImageIndex === index ? styles.activeSlot : ''}`}
onClick={() => generatedImages[index] && setSelectedImageIndex(index)}
>
{isGenerating ? (
<div className={styles.loadingSpinner}>생성 중...</div>
) : generatedImages[index] ? (
<img src={generatedImages[index]} alt={`표지 후보 ${index + 1}`} />
) : (
<span className={styles.slotText}>Preview {index + 1}</span>
)}
</div>
))}isGenerating 하나로 3개 슬롯을 동시에 제어한다. 생성 버튼을 누르는 순간 setGeneratedImages([null, null, null])로 초기화하고 setIsGenerating(true)로 전환해서 모든 슬롯이 동시에 로딩 상태로 바뀐다.
모델 선택과 퀄리티 제약
모델은 3가지를 지원하도록 만들었다.
const handleModelChange = (modelName) => {
setApiConfig({
model: modelName,
quality: modelName === 'dall-e-3' ? 'High' : prev.quality
})
}DALL-E 3는 퀄리티 옵션이 High만 지원한다. 모델 변경 시 자동으로 강제 설정하고, 퀄리티 선택 UI에서도 Low/Medium을 누르면 경고 알림이 뜨도록 처리했다.
onClick={() => {
if (apiConfig.model === 'dall-e-3' && qualityLevel !== 'High') {
alert('DALL-E 3 모델은 High 퀄리티만 선택 가능합니다.')
return
}
setApiConfig({ ...apiConfig, quality: qualityLevel })
}}사소해 보이지만, 이런 제약 처리가 없으면 사용자가 DALL-E 3 + Low 조합을 선택한 채로 API를 쏘고 400 에러를 마주친다. 실제로 처음엔 빠뜨렸다가 테스트 중에 터졌다.
6. OpenAI API 연동 — 기본 흐름 이해
API 호출 자체는 간단하다.
export async function generateBookCover(apiKey, prompt) {
if (!apiKey) throw new Error('API Key가 없습니다.')
const response = await fetch('https://api.openai.com/v1/images/generations', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${apiKey.trim()}`
},
body: JSON.stringify({
model: 'gpt-image-2',
prompt: prompt,
size: '1024x1536', // 세로형 책 표지 비율
output_format: 'png',
n: 1
})
})
if (!response.ok) {
throw new Error(`OpenAI 요청 실패 (Status: ${response.status})`)
}
const data = await response.json()
const b64Json = data.data?.[0]?.b64_json
if (!b64Json) throw new Error('이미지 데이터를 찾지 못했습니다.')
return `data:image/png;base64,${b64Json}`
}OpenAI가 응답으로 주는 건 base64 인코딩된 PNG 문자열(b64_json)이다. 이걸 data:image/png;base64,... 형태의 Data URL로 변환하면 <img src>에 바로 쓸 수 있다.
data.data?.[0]?.b64_json 이 옵셔널 체이닝이 없으면 응답 구조가 조금이라도 달라질 때 앱 전체가 크래시된다. 실제로 처음에 빠뜨렸다가 에러를 마주쳤다. 외부 API 응답은 항상 방어적으로 접근하는 게 맞다.
7. 1 프롬프트 → 3 이미지 — 핵심 설계 고민
미션 명세는 "AI 표지 생성 버튼 클릭 → 이미지 1개 생성"이었다. 그런데 내가 생각하기엔 표지 하나만 나오면 사용자가 선택권이 없다. 같은 도서 내용으로 스타일이 다른 3가지 샘플을 동시에 보여줘야 실제로 유용하다고 판단했다.
gpt-image-2는 n: 3 파라미터를 지원하지 않는다. n: 1만 된다. 그래서 요청을 3번 병렬로 보내는 방식으로 처리했다.
const handleGenerate = async () => {
// ...유효성 검사...
setIsGenerating(true)
setSelectedImageIndex(null)
setGeneratedImages([null, null, null]) // 슬롯 초기화
// 도서 정보 + 사용자 자유 프롬프트를 합쳐서 subject 구성
const combinedInfo = {
title: dbBookInfo.title,
author: dbBookInfo.author,
content: `[Book Story]: ${dbBookInfo.originalContent} / [User Design Request]: ${userPrompt}`
}
const finalPrompt = buildStructuredPrompt(combinedInfo, selectedOptions)
// 3개 동시 요청
const generatePromises = [
generateBookCover(apiKey, finalPrompt),
generateBookCover(apiKey, finalPrompt),
generateBookCover(apiKey, finalPrompt),
]
const newImages = await Promise.all(generatePromises)
setGeneratedImages(newImages)
}Promise.all을 쓰면 3개 요청이 동시에 날아가서 순차 요청(3배 시간)보다 훨씬 빠르게 결과를 받을 수 있다. 사용자는 3개 이미지를 나란히 보고 마음에 드는 걸 선택해서 저장한다.
한 가지 추가로 고민한 부분은 content 조합 방식이다.
content: `[Book Story]: ${dbBookInfo.originalContent} / [User Design Request]: ${userPrompt}`db에 저장된 도서 내용과 사용자가 직접 입력한 프롬프트를 분리해서 합쳤다. 그냥 이어 붙이면 모델이 어느 게 더 중요한 지시인지 헷갈릴 수 있다. 레이블을 붙여서 두 정보의 성격이 다름을 명시적으로 알렸더니 결과물이 더 의도에 가깝게 나왔다.
8. 프롬프트 엔지니어링 — 단순 텍스트 전달은 쓰레기를 만든다
이 부분이 이번 프로젝트에서 가장 실험이 많았던 부분이다.
처음에는 이렇게 프롬프트를 구성하려고 혼자 생각했었다. (따로 프로젝트 진행중 테스트 진행)
"A book cover for a book titled '별빛 아래의 서점'.
Content: 작은 마을 서점의 1년을 담은 에세이."결과가 처참했다. 글자가 이상하게 들어가거나, 내가 원하는 느낌에 책 표지 이미지가 나왔다. 여러 번 재생성해도 품질이 들쑥날쑥했다.
GPT Image 2 모델이 "텍스트 렌더링 성능이 개선됐다"고 하지만, 그냥 자연어로 넘기면 모델이 어디에 집중해야 할지 헤맨다는 걸 체감했다. 그렇기에 OPENAI를 사용한 이미지 만드는 깃허브를 참고해 조원에 태정님이 프롬프트를 구조화해서 모델에게 명확한 지시를 줄 수 있는 6섹션 구조를 만들었다.
[STYLE]
Oil Painting Classic (visible heavy brushstrokes, rich impasto texture,
deep color palette, classic chiaroscuro lighting, canvas texture)
[SUBJECT]
A professional book cover design.
Main theme concept: [Book Story]: 작은 마을 서점의 1년을 담은 에세이 /
[User Design Request]: 따뜻하고 고요한 느낌으로.
Title: "별빛 아래의 서점". Author: "홍길동".
[BACKGROUND]
Lush Nature background (soft-focus forest with dappled sunlight, natural textures)
[LIGHTING]
Warm Golden Hour (rich golden tones, long soft shadows, warm highlights)
[TYPOGRAPHY]
Serif Classic Typography layout
(book title written in elegant Serif typeface at top-center in large letters)
[TECHNICAL]
85mm portrait lens at f/1.8, razor-sharp focus, cinematic background bokeh.
[NEGATIVE]
low quality, blurry, distorted text, garbled letters, misspelled text, watermark.각 섹션이 하는 역할이 다르다.
[STYLE]— 전체적인 화풍, 렌더링 방식[SUBJECT]— 표지의 주제, 도서 정보[BACKGROUND]— 배경 분위기[LIGHTING]— 조명 설정[TYPOGRAPHY]— 제목 텍스트 처리 방식[TECHNICAL]— 사진 품질 관련 고정값 (렌즈/포커스/보케)[NEGATIVE]— 제거할 요소 명시
[NEGATIVE] 섹션이 생각보다 중요했다. 이걸 추가하고 나서 글자 깨짐이나 워터마크 같은 품질 문제가 눈에 띄게 줄었다.
각 옵션에는 영어 프롬프트 프리셋이 연결돼 있고, 사용자는 한국어 태그만 선택하면 된다.
export const STYLE_PRESETS = {
'수채화': 'Line Art (clean lines, delicate watercolor bleeding effects, minimalist aesthetic...)',
'3D애니메이션': '3D Animated style (vibrant colors, expressive characters, soft volumetric lighting...)',
'유화': 'Oil Painting Classic (visible heavy brushstrokes, rich impasto texture...)',
'미니멀리즘': 'Modern Minimalism (bold geometric shapes, flat design elements, high contrast...)',
'빈티지': 'vintage pulp fiction (gritty textures, bold halftone patterns, dramatic chiaroscuro...)',
'일러스트': 'Warm Anime Illustration style (soft pastel colors, whimsical character design...)',
}이렇게 태그→영어 프리셋으로 매핑하는 방식을 택한 이유는 두 가지다. 첫째, 사용자에게 복잡한 영어 프롬프트를 직접 입력하게 하면 진입 장벽이 너무 높다. 둘째, 검증된 프리셋을 쓰면 결과물 품질이 더 일관적이다. 자유 프롬프트는 [User Design Request]에 입력을 받도록 설계해 사용자가 원하는 이미지를 만들 수 있게 했다.
9. 이미지 압축 — 예상 못했던 병목
Data URL은 생각보다 훨씬 크다. 실제로 OpenAI에서 받은 원본 Data URL 하나가 1~2MB 가까이 됐다. 이걸 그대로 json-server에 PATCH로 저장하면 db.json 파일이 순식간에 수십 MB가 된다. 로딩이 느려지고 심하면 json-server가 불안정해진다.
그래서 Canvas API를 활용한 이미지 압축 함수를 직접 만들었다.
export async function compressImageDataUrl(dataUrl, maxBytes = 75000) {
if (!dataUrl?.startsWith('data:image/')) return dataUrl || ''
if (dataUrl.length <= maxBytes) return dataUrl // 이미 충분히 작으면 패스
const image = await new Promise((resolve, reject) => {
const img = new Image()
img.onload = () => resolve(img)
img.onerror = () => reject(new Error('이미지를 압축할 수 없습니다.'))
img.src = dataUrl
})
const canvas = document.createElement('canvas')
const ctx = canvas.getContext('2d')
const aspect = image.height / image.width || 1.5 // 비율 유지
const widths = [360, 320, 280, 240, 200, 180]
const qualities = [0.72, 0.62, 0.52, 0.42, 0.34]
for (const width of widths) {
canvas.width = width
canvas.height = Math.round(width * aspect)
ctx.clearRect(0, 0, canvas.width, canvas.height)
ctx.drawImage(image, 0, 0, canvas.width, canvas.height)
for (const quality of qualities) {
const compressed = canvas.toDataURL('image/jpeg', quality)
if (compressed.length <= maxBytes) return compressed
}
}
return canvas.toDataURL('image/jpeg', 0.28) // 최후 수단
}핵심 로직은 이렇다.
- 이미 목표 크기(75KB) 이하면 바로 반환
- Canvas로 이미지 그리기 →
toDataURL('image/jpeg', quality)로 압축 - 너비 360px부터 180px까지 단계적으로 줄이면서, 각 너비에서 품질도 0.72부터 0.34까지 낮춤
- 목표 크기 이하가 되는 첫 조합을 반환
- 모두 실패하면
quality: 0.28로 강제 반환
PNG(원본) → JPEG(압축)로 포맷도 바뀐다. 표지 미리보기용으로는 충분한 품질이 나왔고, 저장 용량은 원본 대비 95% 이상 줄었다.
aspect ratio를 image.height / image.width || 1.5 로 계산하는 이유도 있다. 이미지 로딩이 실패하거나 width가 0인 경우 나누기 0이 되는데, || 1.5로 fallback해서 책 표지 기본 비율(세로형)을 유지하도록 했다.
10. 예외처리 — 사용자에게 무슨 일이 일어났는지 알려줘야 한다
OpenAI API를 다루면서 예외처리가 생각보다 많이 필요하다는 걸 깨달았다. 처리하지 않으면 화면이 그냥 멈추거나 흰 화면이 뜬다. 사용자 입장에서 가장 당황스러운 경험이다.
API Key 관련
if (!apiKey) throw new Error('API Key가 없습니다.')
// → .env 파일에 VITE_OPENAI_API_KEY 설정 필요 안내HTTP 응답 실패
if (!response.ok) {
throw new Error(`OpenAI 요청 실패 (Status: ${response.status})`)
// 401 → API Key 오류
// 429 → Rate Limit 초과
// 500 → OpenAI 서버 오류
}응답 데이터 누락
const b64Json = data.data?.[0]?.b64_json
if (!b64Json) throw new Error('이미지 데이터를 찾지 못했습니다.')이미지 압축 실패
img.onerror = () => reject(new Error('이미지를 압축할 수 없습니다.'))
// → 압축 실패 시 원본 반환으로 fallback저장 실패
if (response.ok) {
alert('표지가 성공적으로 수정되었습니다!')
navigate(-1)
} else {
throw new Error('저장 실패')
}try-catch 안에서 에러를 잡고 alert로 사용자에게 알리는 방식이다. 실제 서비스라면 toast 알림이나 에러 상태 UI로 더 세련되게 처리하겠지만, 프로젝트 범위 안에서는 이 정도로 충분하다고 판단했다.
11. 코드 병합 — 가장 힘든 작업이었다
팀에서 PR을 제대로 진행하지 못했다. 각자 로컬에서 개발한 코드를 파일로 공유하는 방식이었는데, 이걸 내가 직접 하나씩 합쳤다. (처음 개발 진행시 틀을 잡지 못하고 시작하게 크다.. 나의 잘못이라고 생각한다.)
병합하면서 실제로 마주친 문제들:
- 변수명 충돌
한 쪽은book, 다른 쪽은bookData, 또 다른 쪽은currentBook. 어느 게 맞는지 기준이 없어서 일일이 읽어가며 통일했다. - 상태 관리 불일치
A는useState로 직접 관리, B는 props로 내려받는 구조가 혼용됐다. 데이터 흐름이 섞이면 어디서 상태를 갱신해야 하는지 판단하기 어렵다. - API 호출 방식 혼재
fetch를 컴포넌트 안에서 직접 쓴 곳, 별도 함수로 분리한 곳이 섞였다. 에러 처리 방식도 다 달랐다. - CSS 클래스 중복
같은 클래스명인데 스타일이 다른 경우가 있었다. CSS Module을 쓴 곳과 일반 클래스를 쓴 곳이 혼재했다.
이걸 하나하나 읽으면서 충돌 없이 합치고, 라우팅 흐름이 끊기지 않는지 확인하면서 전체 앱이 돌아가게 만드는 과정이 생각보다 훨씬 오래 걸렸다. 검색바 동작 방식(useMemo + 클라이언트 사이드 필터링), 리스트 카드 클릭 → 상세 전환 흐름, 등록/수정 폼의 상태 초기화 타이밍 같은 디테일도 이 과정에서 직접 정리했다.
생각정리
이번 04miniproject를 진행하며 어려웠던 점, 느낀점, 다음계획(프로젝트가 끝난후 따로 진행하고 있다)에 대해 정리해보자구..
어려웠던 점
b64_json이란?
OpenAI 응답에서 이미지가 URL이 아니라 base64 문자열로 온다는건 알았지만 dn.json에서는 큰 용량을 처리하는데에 한계가 있었다. 응답 JSON을 콘솔에 찍어봤더니 data[0].b64_json 에 엄청 긴 문자열이 들어있었다. db.json 서버를 사용할떄는 data:image/png;base64,...로 변환해야 <img src>에 쓸 수 있다는 것도 직접 해보고 나서야 자연스럽게 이해됐다.
Promise.all에서 하나가 Rate Limit에 걸리면?
3개 이미지 동시 생성에서 Promise.all을 쓰면 하나라도 실패하면 전체가 reject된다. Rate Limit(429)이 걸릴 때 이 문제가 생겼다. 3개 요청 중 1개만 실패해도 나머지 2개 결과가 다 날아간다. 나중에 Promise.allSettled로 바꿔서 실패한 것만 null 처리하는 방식을 검토했다. 이렇게 하면 2개는 성공, 1개는 null 슬롯으로 보여줄 수 있다.
이미지가 json-server에 저장은 됐는데 목록에 안 보임
PATCH 요청이 성공했는데 도서 목록으로 돌아오면 표지가 안 나왔다. 원인은 books 상태가 최초 fetch 이후 갱신이 안 된 것이었다. navigate(-1) 로 뒤로 가면 컴포넌트가 언마운트/리마운트되는데, 이때 useEffect의 fetch가 다시 실행돼야 한다. 의존성 배열을 확인하고 재fetch 트리거를 명시적으로 추가해서 해결했다.
Data URL이 너무 커서 json-server가 느려짐
앞서 언급한 이미지 압축 문제다. 처음엔 원본 Data URL을 그대로 저장했더니 db.json이 수십 MB가 됐고, json-server의 응답 속도가 눈에 띄게 느려졌다. 압축 함수를 만들고 나서 해결됐다.
느낀 점
UI 개발은 그리는 게 아니라 설계하는 것이다
이번 전까지 UI 개발은 "화면을 예쁘게 만드는 것"이라고 생각했다. 실제로 해보니 완전히 달랐다.
라우팅 설계, 컴포넌트 인터페이스 정의, 상태 흐름 설계, API 연동, 예외처리, 사용자 피드백 처리까지 전부 UI 개발의 영역이었다. 화면을 만드는 건 그 중 일부일 뿐이다. 가장 먼저 해야 할 것이 "어떻게 생겼는가"가 아니라 "데이터가 어떻게 흐르는가"라는 걸 이번에 확실히 배웠다.
"1 프롬프트 → 3 이미지"는 기술 문제가 아니라 UX 문제였다
교안에서 요구한 건 이미지 1개였다. 그걸 3개로 늘린 건 기술적 도전이 아니라 "사용자가 실제로 이걸 어떻게 쓸까" 를 생각한 우리조의 토론 결과였다. 표지를 딱 하나만 주면 선택의 여지가 없다. 마음에 안 들면 재생성 버튼을 계속 누르게 된다. 처음부터 3가지를 주면 그 중 하나는 마음에 들 가능성이 높다. API 비용은 3배 들지만 사용자 경험은 훨씬 낫다. 기능 구현보다 사용 맥락을 먼저 생각하는 습관이 이번에 좀 생긴 것 같다.
프롬프트 엔지니어링은 확실히 기술이다
"좋은 표지 그려줘" 와 [STYLE] Oil Painting Classic... [NEGATIVE] low quality, blurry... 는 결과물이 완전히 다르다. 언어를 구조화해서 모델이 집중할 지점을 명확하게 만드는 것, 제거할 요소를 NEGATIVE로 명시하는 것 — 이게 다 기술이다. 이전 프로젝트들에서 Multi-Agent나 LangGraph를 다뤘을 때도 프롬프트가 중요했지만, 이미지 생성에서는 그 차이가 훨씬 직관적으로 느껴졌다.
협업은 처음부터 규칙이 있어야 한다
이번 프로젝트에서 제일 힘든 작업이 코드 병합이었다. 사람마다 코딩 스타일이 다르고 변수명도 다르다. PR도 없이 파일로 코드를 주고받으면 충돌이 생길 수밖에 없다. 다음에는 처음부터 브랜치 전략, PR 규칙, 컨벤션(변수명, 컴포넌트 구조) 을 팀 안에서 먼저 합의하고 시작해야겠다. 이걸 나중에 맞추려고 하면 이미 늦다는 걸 뼈저리게 느꼈다. 아이러니하게도, 병합 작업 덕분에 팀 전체 코드를 가장 잘 아는 사람이 됐다. 모든 파일을 다 읽었으니까. 나쁘지 않은걸까..?
다음 목표 (후에 Spring도 연결 예정이니)
- Git 협업 플로우 제대로 경험하기 — 브랜치 전략, PR, 코드 리뷰
- React 상태 관리 깊이 파기 — React Query로 서버 상태와 클라이언트 상태 분리
- 실제 백엔드 연결 — json-server → Spring Boot 교체 (백엔드 미니프로젝트 예정)
- Promise.allSettled 패턴 — 일부 실패해도 나머지 결과는 보여주기
3일이라는 짧은 기간 동안 진행한 프로젝트였기에, 더 많은 시간을 투자했다면 더욱 완성도 높은 결과물을 만들 수 있었을 것이다. 하지만 제한된 시간 속에서도 모든 조원이 각자의 역할에 최선을 다해 주었기에 의미 있는 결과물을 만들어낼 수 있었다고 생각한다. 이번 프로젝트는 단순히 결과물을 완성하는 것에서 끝나지 않고, 프로젝트가 끝난 이후에도 더 공부하고 배워야 할 점들과 부족했던 부분을 채울 수 있는 프로젝트였다. 9주차 프로젝트를 마무리한다.
12조 파이팅!
